On the Learning Curves of Revenue Maximization
Pith reviewed 2026-05-07 10:34 UTC · model grok-4.3
The pith
Revenue maximization algorithms from samples can approach the optimal revenue for any valuation distribution, yet this improvement can be arbitrarily slow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
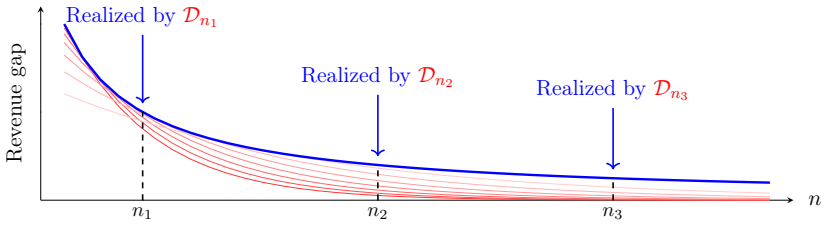
In the absence of any restriction on the valuation distribution, we show that there exists a Bayes-consistent algorithm whose learning curve converges to zero for any arbitrary valuation distribution as the number of samples n tends to infinity. However, this convergence must be arbitrarily slow, even if the optimal revenue is finite. In contrast, if the optimal revenue is achieved by a finite price, then the optimal rate of decay is roughly 1/sqrt(n). Finally, for distributions supported on discrete sets of values, we show that learning curves decay almost exponentially fast.
What carries the argument
The learning curve of a revenue-maximizing algorithm, which tracks the decay of the gap between achieved and optimal revenue for a fixed valuation distribution as the sample size n grows.
If this is right
- There exists at least one algorithm that eventually achieves near-optimal revenue no matter what the fixed distribution is.
- No single convergence rate applies uniformly to all possible valuation distributions.
- When the optimal mechanism posts a single price the revenue gap decays at rate roughly 1 over square root of n.
- When values are drawn from a finite discrete set the revenue gap decays almost exponentially in the number of samples.
Where Pith is reading between the lines
- In applications where the distribution class is unknown in advance, rapid improvement in revenue with added data cannot be expected without further assumptions.
- Identifying whether the optimal revenue comes from a single price or whether support is discrete could allow selection of faster-converging methods in practice.
- The same case distinctions on distribution structure may determine achievable rates in related mechanism-design learning problems.
Load-bearing premise
Valuation distributions are allowed to be completely arbitrary with no restrictions on their shape, support, or moments.
What would settle it
A specific family of valuation distributions together with an algorithm whose revenue gap decays faster than every possible slow function of n, or an algorithm whose gap fails to reach zero for some distribution with finite optimal revenue.
Figures



read the original abstract
Learning curves are a fundamental primitive in supervised learning, describing how an algorithm's performance improves with more data and providing a quantitative measure of its generalization ability. Formally, a learning curve plots the decay of an algorithm's error for a fixed underlying distribution as a function of the number of training samples. Prior work on revenue-maximizing learning algorithms, starting with the seminal work of Cole and Roughgarden [STOC, 2014], adopts a distribution-free perspective, which parallels the PAC learning framework in learning theory. This approach evaluates performance against the hardest possible sequence of valuation distributions, one for each sample size, effectively defining the upper envelope of learning curves over all possible distributions, thus leading to error bounds that do not capture the shape of the learning curves. In this work we initiate the study of learning curves for revenue maximization and provide a near-complete characterization of their rate of decay in the basic setting of a single item and a single buyer. In the absence of any restriction on the valuation distribution, we show that there exists a Bayes-consistent algorithm, meaning that its learning curve converges to zero for any arbitrary valuation distribution as the number of samples $n \to \infty$. However, this convergence must be arbitrarily slow, even if the optimal revenue is finite. In contrast, if the optimal revenue is achieved by a finite price, then the optimal rate of decay is roughly $1/\sqrt{n}$. Finally, for distributions supported on discrete sets of values, we show that learning curves decay almost exponentially fast, a rate unattainable under the PAC framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript initiates the study of learning curves for revenue maximization in the single-item single-buyer setting. It shows that there exists a Bayes-consistent algorithm whose expected revenue loss converges to zero for any valuation distribution F as n→∞, but that this convergence can be arbitrarily slow even when OPT(F) is finite. In contrast, when OPT is achieved by a finite price the optimal rate is roughly 1/√n, and when the support is discrete the decay is almost exponential.
Significance. If the central claims hold, the work supplies a distribution-dependent refinement of learning rates that goes beyond the worst-case PAC-style bounds of prior revenue-maximization literature. The explicit separation into three regimes (unrestricted, finite-price, discrete) is a clear conceptual contribution and could inform algorithm design when distributional structure is known. The paper correctly credits the contrast with the PAC framework as its main novelty.
major comments (2)
- [Abstract / existence theorem] Abstract and the existence result: the manuscript asserts the existence of a Bayes-consistent algorithm A such that E[OPT(F) − Rev(A(S_n), F)] → 0 for every F, yet provides no explicit construction or selection rule for the posted price from the n samples. This is load-bearing because the subsequent claim that convergence must be arbitrarily slow is proved via an adversarial family of distributions; without a concrete A it is impossible to verify that the same algorithm remains consistent on those hard instances while exhibiting the stated slow rate.
- [Finite-price regime] 1/√n rate claim: the statement that the optimal rate is roughly 1/√n when a finite price attains OPT requires an explicit matching upper and lower bound together with the precise assumptions on the valuation family under which the rate is tight. The current sketch does not indicate whether the lower bound holds uniformly or only for a subclass of distributions.
minor comments (1)
- [Abstract] The abstract uses the term 'Bayes-consistent' without a one-sentence definition; a brief parenthetical gloss would help readers outside mechanism design.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We appreciate the recognition of the conceptual contribution in refining learning rates for revenue maximization beyond PAC bounds. We address the major comments point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / existence theorem] Abstract and the existence result: the manuscript asserts the existence of a Bayes-consistent algorithm A such that E[OPT(F) − Rev(A(S_n), F)] → 0 for every F, yet provides no explicit construction or selection rule for the posted price from the n samples. This is load-bearing because the subsequent claim that convergence must be arbitrarily slow is proved via an adversarial family of distributions; without a concrete A it is impossible to verify that the same algorithm remains consistent on those hard instances while exhibiting the stated slow rate.
Authors: We acknowledge that the existence proof in the current manuscript is non-constructive, relying on a compactness argument in the space of algorithms to guarantee a single A that is consistent for every F. The referee correctly identifies that this makes verification of the slow-rate claim on the adversarial family difficult. In the revision we will add an explicit construction: the algorithm discretizes the price space at resolution 1/n and selects the empirical revenue maximizer over the grid. We will prove that this A is Bayes-consistent for all F (by standard uniform convergence arguments on the revenue curve) and that, on the specific adversarial family used for the lower bound, its revenue loss decays arbitrarily slowly. This makes the entire argument self-contained. revision: yes
-
Referee: [Finite-price regime] 1/√n rate claim: the statement that the optimal rate is roughly 1/√n when a finite price attains OPT requires an explicit matching upper and lower bound together with the precise assumptions on the valuation family under which the rate is tight. The current sketch does not indicate whether the lower bound holds uniformly or only for a subclass of distributions.
Authors: We agree that the finite-price regime needs a more precise statement. In the revision we will expand the section to state the exact assumptions (continuous revenue curve at the optimum and finite second moment of the valuation distribution) and supply matching upper and lower bounds up to constants. The upper bound holds uniformly over the entire class of distributions with finite optimal price. The lower bound is established only for a subclass (distributions with a unique optimal price and Lipschitz revenue curve), which is sufficient to show that 1/√n is the best possible rate in the worst case within the regime. We will clarify this distinction explicitly and move the full proofs to the appendix. revision: yes
Circularity Check
No significant circularity; claims rest on independent distribution properties and learning-theoretic arguments
full rationale
The derivation establishes existence of a Bayes-consistent algorithm whose convergence rate can be arbitrarily slow for general distributions, with faster rates under finite-price optimality or discrete support. These results are obtained by analyzing the worst-case behavior over families of valuation distributions and applying standard consistency and rate bounds from statistical learning theory. No step reduces a claimed prediction or rate to a fitted parameter, self-citation, or definitional equivalence; the abstract and described claims cite external prior work (Cole-Roughgarden) only for context and derive the new characterizations directly from the problem primitives without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard measure-theoretic probability and convergence in probability for learning algorithms
- domain assumption Existence of optimal revenue for any valuation distribution (finite or infinite)
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems30 (2017)
Submultiplicative Glivenko-Cantelli and uniform convergence of revenues. Advances in Neural Information Processing Systems30 (2017). András Antos. 1999.Performance limits of nonparametric estimators. Ph.D. Dissertation. Budapest University of Technology and Economics (Hungary). András Antos, László Györfi, and Michael Kohler
2017
-
[2]
András Antos and Ioannis Kontoyiannis
Lower bounds on the rate of convergence of nonparametric regression estimates.Journal of statistical planning and inference83, 1 (2000), 91–100. András Antos and Ioannis Kontoyiannis
2000
-
[3]
András Antos and Gábor Lugosi
Convergence properties of functional estimates for discrete distributions.Random Structures & Algorithms19, 3-4 (2001), 163–193. András Antos and Gábor Lugosi
2001
-
[4]
Reducing mechanism design to algorithm design via machine learning.J. Comput. System Sci.74, 8 (2008), 1245–1270. Maria-Florina Balcan, Travis Dick, and Ellen Vitercik. 2018a. Dispersion for data-driven algorithm design, online learning, and private optimization. In2018 IEEE 59th Annual Symposium on Foundations of Computer Science (FOCS). IEEE, 603–614. M...
2008
-
[5]
Sandeep Baliga and Rakesh Vohra
Sample complexity of automated mechanism design.Advances in Neural Information Processing Systems29 (2016). Sandeep Baliga and Rakesh Vohra
2016
-
[6]
Shalev Ben-David and Eric Blais
Market research and market design.Advances in theoretical Economics3, 1 (2003). Shalev Ben-David and Eric Blais
2003
-
[7]
ACM70, 6 (2023), 1–58
A new minimax theorem for randomized algorithms.J. ACM70, 6 (2023), 1–58. Olivier Bousquet, Steve Hanneke, Shay Moran, Jonathan Shafer, and Ilya Tolstikhin
2023
-
[8]
Johannes Brustle, Yang Cai, and Constantinos Daskalakis
Lower bounds for nonparametric density estimation rates.The Annals of Statistics(1978), 932–934. Johannes Brustle, Yang Cai, and Constantinos Daskalakis
1978
-
[9]
L Devroye and László Györfi
On arbitrarily slow rates of global convergence in density estimation.Zeitschrift für Wahrscheinlichkeitstheorie und verwandte Gebiete62, 4 (1983), 475–483. L Devroye and László Györfi
1983
-
[10]
Luc Devroye, László Györfi, and Gábor Lugosi
Distribution and density estimation.Principles of nonparametric learning(2002), 211–270. Luc Devroye, László Györfi, and Gábor Lugosi. 2013.A probabilistic theory of pattern recognition. Vol
2002
-
[11]
Peerapong Dhangwatnotai, Tim Roughgarden, and Qiqi Yan
Distribution-free lower bounds in density estimation.The Annals of Statistics(1984), 1250–1262. Peerapong Dhangwatnotai, Tim Roughgarden, and Qiqi Yan
1984
-
[12]
Designing and learning optimal finite support auctions. (2007). Yannai A Gonczarowski and Noam Nisan
2007
-
[13]
Chenghao Guo, Zhiyi Huang, and Xinzhi Zhang
The sample complexity of up-to-ε multi- dimensional revenue maximization.Journal of the ACM (JACM)68, 3 (2021), 1–28. Chenghao Guo, Zhiyi Huang, and Xinzhi Zhang
2021
-
[14]
Steve Hanneke, Amin Karbasi, Shay Moran, and Grigoris Velegkas
Universal rates for interactive learning.Advances in Neural Information Processing Systems35 (2022), 28657–28669. Steve Hanneke, Amin Karbasi, Shay Moran, and Grigoris Velegkas
2022
-
[15]
Zhiyi Huang, Yishay Mansour, and Tim Roughgarden
Universal Rates of Empirical Risk Minimization.arXiv preprint arXiv:2412.02810(2024). Zhiyi Huang, Yishay Mansour, and Tim Roughgarden
-
[16]
Making the Most of Your Samples. SIAM J. Comput.47, 3 (2018), 651–674. Alkis Kalavasis, Anay Mehrotra, and Grigoris Velegkas
2018
-
[17]
Alkis Kalavasis, Grigoris Velegkas, and Amin Karbasi
On the limits of language generation: Trade-offs between hallucination and mode collapse.arXiv preprint arXiv:2411.09642(2024). Alkis Kalavasis, Grigoris Velegkas, and Amin Karbasi
-
[18]
Jamie Morgenstern and Tim Roughgarden
Multiclass learnability beyond the pac framework: Universal rates and partial concept classes.Advances in Neural Information Processing Systems35 (2022), 20809–20822. Jamie Morgenstern and Tim Roughgarden
2022
-
[19]
Zvika Neeman
On the pseudo-dimension of nearly optimal auctions.Advances in Neural Information Processing Systems28 (2015). Zvika Neeman
2015
-
[20]
Tim Roughgarden and Okke Schrijvers
The effectiveness of English auctions.Games and economic Behavior43, 2 (2003), 214–238. Tim Roughgarden and Okke Schrijvers
2003
-
[21]
InProceedings of the 2016 ACM Conference on Economics and Computation
Ironing in the dark. InProceedings of the 2016 ACM Conference on Economics and Computation. 1–18. Dale Schuurmans
2016
-
[22]
Ilya Segal
Characterizing rational versus exponential learning curves.journal of computer and system sciences55, 1 (1997), 140–160. Ilya Segal
1997
-
[23]
Charles J Stone
Optimal pricing mechanisms with unknown demand.American Economic Review 93, 3 (2003), 509–529. Charles J Stone
2003
-
[24]
Vasilis Syrgkanis
Consistent nonparametric regression.The annals of statistics(1977), 595–620. Vasilis Syrgkanis
1977
-
[25]
Advances in Neural Information Processing Systems30 (2017)
A sample complexity measure with applications to learning optimal auctions. Advances in Neural Information Processing Systems30 (2017). Leslie G Valiant
2017
-
[26]
ACM27, 11 (1984), 1134–1142
A theory of the learnable.Commun. ACM27, 11 (1984), 1134–1142. AW van der Vaart and Jon A Wellner. 2023.Weak Convergence and Empirical Processes: With Applications to Statistics. Springer Nature. Vladimir Vapnik. 2013.The nature of statistical learning theory. Springer science & business media. 45 A Omitted Details from Section 1 A.1 Additive vs. Multipli...
1984
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.