Recognition: unknown
ObjectGraph: From Document Injection to Knowledge Traversal -- A Native File Format for the Agentic Era
Pith reviewed 2026-05-07 04:59 UTC · model grok-4.3
The pith
ObjectGraph models documents as typed directed knowledge graphs that agents traverse selectively instead of injecting full texts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
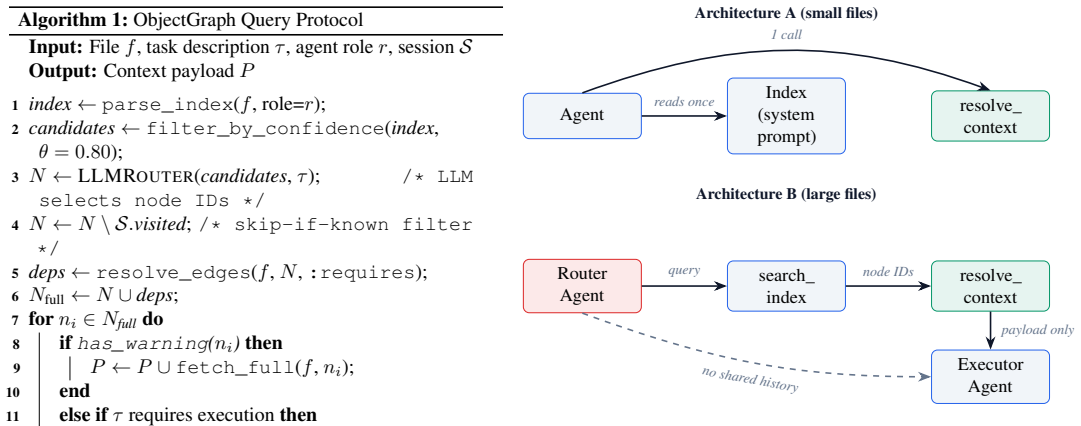
The central discovery is that the Document Consumption Problem can be solved by shifting from linear string injection to knowledge graph traversal. OBJECTGRAPH is defined as a strict superset of Markdown that encodes documents as typed directed graphs. It natively supports the Progressive Disclosure Model for layered information release, the Role-Scoped Access Protocol for permissioned retrieval, and Executable Assertion Nodes for embedded logic. This design is shown to satisfy the six required structural properties where no existing format does.
What carries the argument
OBJECTGRAPH (.og), the typed directed knowledge graph file format that serves as a strict superset of Markdown and provides a two-primitive query protocol along with built-in support for progressive disclosure, role-scoped access, and executable assertions to enable selective traversal.
If this is right
- Agents achieve up to 95.3 percent reduction in tokens used for document consumption across the evaluated tasks with no statistically significant accuracy loss.
- Transpilers convert existing documents to OBJECTGRAPH while preserving 98.7 percent of content on held-out benchmarks.
- The format remains readable by humans without tooling because it is a strict superset of Markdown.
- Multi-turn agent loops avoid context compounding through native role-scoped and progressive access mechanisms.
- A two-primitive query protocol suffices for all traversal needs without additional infrastructure.
Where Pith is reading between the lines
- Agent systems could shift from managing large context windows to operating on graph query primitives for better scalability in extended sessions.
- The six properties could serve as an evaluation standard for any new document format intended for autonomous agents.
- Executable assertion nodes suggest documents that embed verification logic or trigger external actions directly within the format.
- The graph model might extend beyond text to unify access to code, data tables, or other structured artifacts in agent workflows.
Load-bearing premise
The six structural properties fully capture the requirements for effective document consumption by autonomous agents and the evaluation across five document classes and eight task types generalizes to real-world deployments.
What would settle it
An experiment on a new agent task type or document class where using OBJECTGRAPH produces a statistically significant drop in task accuracy compared to full document injection.
Figures



read the original abstract
Every document format in existence was designed for a human reader moving linearly through text. Autonomous LLM agents do not read - they retrieve. This fundamental mismatch forces agents to inject entire documents into their context window, wasting tokens on irrelevant content, compounding state across multi-turn loops, and broadcasting information indiscriminately across agent roles. We argue this is not a prompt engineering problem, not a retrieval problem, and not a compression problem: it is a format problem. We introduce OBJECTGRAPH (.og), a file format that reconceives the document as a typed, directed knowledge graph to be traversed rather than a string to be injected. OBJECTGRAPH is a strict superset of Markdown - every .md file is a valid .og file - requires no infrastructure beyond a two-primitive query protocol, and is readable by both humans and agents without tooling. We formalize the Document Consumption Problem, characterise six structural properties no existing format satisfies simultaneously, and prove OBJECTGRAPH satisfies all six. We further introduce the Progressive Disclosure Model, the Role-Scoped Access Protocol, and Executable Assertion Nodes as native format primitives. Empirical evaluation across five document classes and eight agent task types demonstrates up to 95.3 percent token reduction with no statistically significant degradation in task accuracy (p > 0.05). Transpiler fidelity reaches 98.7 percent content preservation on a held-out document benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current document formats are mismatched to autonomous LLM agents, which retrieve rather than read linearly, leading to wasteful full-document injection. It introduces OBJECTGRAPH (.og) as a strict Markdown superset that models documents as typed directed knowledge graphs traversable via a minimal two-primitive query protocol. The authors formalize the Document Consumption Problem, characterize six structural properties no existing format satisfies simultaneously, prove OBJECTGRAPH meets all six, and introduce three native primitives (Progressive Disclosure Model, Role-Scoped Access Protocol, Executable Assertion Nodes). Empirical evaluation across five document classes and eight agent task types reports up to 95.3% token reduction with no statistically significant task accuracy degradation (p > 0.05) and 98.7% transpiler fidelity on a held-out benchmark.
Significance. If the formalization, proofs, and results hold under scrutiny, the work could meaningfully advance agentic systems by providing a native format that reduces context bloat, enables role-scoped access, and supports progressive disclosure without extra infrastructure. Treating the document as a traversable graph rather than injectable text is a substantive conceptual shift, and the Markdown superset design aids adoption. The explicit formalization of the consumption problem and the reported token savings offer a concrete baseline for future agent-document research. Significance is limited by the narrow evaluation scope and the absence of external grounding for the six properties as the minimal necessary set.
major comments (4)
- [Abstract] Abstract: The claim that the six structural properties are necessary and that 'no existing format satisfies [them] simultaneously' is load-bearing for the entire contribution, yet the properties are presented as author-characterized without citation to agent interaction logs, framework analyses, or prior literature identifying these exact bottlenecks. This leaves open whether the properties are complete or whether the proof that OBJECTGRAPH is the first to satisfy all six rests on an ad-hoc characterization.
- [Abstract] Abstract (empirical evaluation): The statement of 'no statistically significant degradation in task accuracy (p > 0.05)' only indicates failure to reject the null hypothesis of no difference; it does not demonstrate equivalence, absence of degradation, or practical non-inferiority. No effect sizes, confidence intervals, or power analysis are referenced, undermining the central claim that token reduction is achieved without performance cost.
- [Abstract] Abstract: The headline result of 'up to 95.3 percent token reduction' reports the best-case outcome across the five document classes and eight task types. Without average or median reductions, standard deviations, or per-class/per-task breakdowns, it is impossible to judge whether the savings are typical or confined to favorable cases.
- [Abstract] Abstract: The 98.7 percent transpiler fidelity is reported on a 'held-out document benchmark' whose size, selection criteria, document classes, and construction method are unspecified. Because fidelity is a core supporting claim for the format's practicality, the lack of benchmark details makes the result non-reproducible from the abstract alone.
minor comments (2)
- [Abstract] The abstract introduces the Progressive Disclosure Model, Role-Scoped Access Protocol, and Executable Assertion Nodes without even one-sentence definitions, forcing readers to reach later sections to understand the primitives that are presented as native to the format.
- [Abstract] The assertion that OBJECTGRAPH 'requires no infrastructure beyond a two-primitive query protocol' is repeated but the two primitives themselves are not named or briefly described in the abstract, reducing immediate clarity for readers evaluating the 'no tooling' claim.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the six structural properties are necessary and that 'no existing format satisfies [them] simultaneously' is load-bearing for the entire contribution, yet the properties are presented as author-characterized without citation to agent interaction logs, framework analyses, or prior literature identifying these exact bottlenecks. This leaves open whether the properties are complete or whether the proof that OBJECTGRAPH is the first to satisfy all six rests on an ad-hoc characterization.
Authors: The six structural properties are derived directly from our formalization of the Document Consumption Problem, which captures the core mismatches between linear document formats and the retrieval-oriented behavior of autonomous agents. While the properties are author-characterized, they synthesize established issues documented in the RAG, context-window, and multi-agent systems literature. In the revised manuscript we will add a dedicated subsection that explicitly traces each property back to the formal problem definition and includes additional citations to prior analyses of agent-document interactions. We will also clarify that the properties constitute a minimal sufficient set for the demonstrated benefits rather than an exhaustive or universally necessary characterization; the proof shows that no existing format satisfies all six simultaneously. revision: partial
-
Referee: [Abstract] Abstract (empirical evaluation): The statement of 'no statistically significant degradation in task accuracy (p > 0.05)' only indicates failure to reject the null hypothesis of no difference; it does not demonstrate equivalence, absence of degradation, or practical non-inferiority. No effect sizes, confidence intervals, or power analysis are referenced, undermining the central claim that token reduction is achieved without performance cost.
Authors: We agree that failure to reject the null hypothesis does not establish equivalence or the absence of degradation. In the revised manuscript we will expand the results section to report effect sizes, 95% confidence intervals on accuracy differences, and a post-hoc power analysis for the statistical tests performed. We will also present per-task and per-document-class accuracy comparisons to allow readers to assess practical non-inferiority directly from the data. revision: yes
-
Referee: [Abstract] Abstract: The headline result of 'up to 95.3 percent token reduction' reports the best-case outcome across the five document classes and eight task types. Without average or median reductions, standard deviations, or per-class/per-task breakdowns, it is impossible to judge whether the savings are typical or confined to favorable cases.
Authors: The phrase 'up to 95.3 percent' in the abstract is intended to highlight the maximum observed reduction. The full manuscript already contains tables and figures that report mean, median, and standard-deviation token reductions broken down by document class and task type. To address the concern, we will revise the abstract to reference these detailed breakdowns (e.g., 'token reductions reaching up to 95.3% with full per-class and per-task distributions provided in Section 4') so that the headline figure is placed in context. revision: partial
-
Referee: [Abstract] Abstract: The 98.7 percent transpiler fidelity is reported on a 'held-out document benchmark' whose size, selection criteria, document classes, and construction method are unspecified. Because fidelity is a core supporting claim for the format's practicality, the lack of benchmark details makes the result non-reproducible from the abstract alone.
Authors: The size, selection criteria, document-class coverage, and construction method of the held-out benchmark are fully specified in the Experimental Setup subsection of the manuscript. We acknowledge that the abstract would benefit from a concise qualifier. In the revision we will update the abstract to include a brief description of the benchmark (e.g., 'on a held-out benchmark spanning the five document classes') while directing readers to the methods section for complete reproducibility details. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper formalizes the Document Consumption Problem, characterizes six structural properties, and proves OBJECTGRAPH satisfies them all while introducing native primitives like Progressive Disclosure and Role-Scoped Access. This is a standard requirements-definition followed by design-verification approach, not a reduction of any claimed result to its own inputs by construction. Empirical claims (token reduction, accuracy p-values, transpiler fidelity) are presented as separate evaluations on held-out benchmarks rather than fitted quantities renamed as predictions. No self-citation chains, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear as load-bearing steps in the abstract or context. The derivation is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Document Consumption Problem is defined by six structural properties that no existing format satisfies simultaneously.
invented entities (3)
-
Progressive Disclosure Model
no independent evidence
-
Role-Scoped Access Protocol
no independent evidence
-
Executable Assertion Nodes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Model Context Protocol (MCP): An open standard for connecting AI assistants to tools and data sources, 2024
Anthropic. Model Context Protocol (MCP): An open standard for connecting AI assistants to tools and data sources, 2024. https://modelcontextprotocol.io
2024
-
[2]
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, and J. Larson. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Fat-Cat: Document-driven metacognitive multi-agent system for complex reasoning
Anonymous. Fat-Cat: Document-driven metacognitive multi-agent system for complex reasoning. arXiv preprint arXiv:2602.02206, 2025
- [4]
-
[5]
J. Gruber. Markdown, 2004. https://daringfireball.net/projects/markdown/
2004
-
[6]
Active context compression: Autonomous memory management in LLM agents
Anonymous. Active context compression: Autonomous memory management in LLM agents. arXiv preprint arXiv:2601.07190, 2025
-
[7]
Anonymous. From skill text to skill structure: The Scheduling-Structural-Logical representation for agent skills. arXiv preprint arXiv:2604.24026, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
u ttler, M. Lewis, W.-T. Yih, T. Rockt\
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. K\" u ttler, M. Lewis, W.-T. Yih, T. Rockt\" a schel, S. Riedel, and D. Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[9]
J. Howard. A proposed standard for using Markdown in LLM context, 2024. https://llmstxt.org
2024
- [10]
-
[11]
Schopplich
J. Schopplich. TOON: Token-Oriented Object Notation, 2025. https://toonformat.dev
2025
-
[12]
Structured context engineering for file-native agentic systems
Anonymous. Structured context engineering for file-native agentic systems. arXiv preprint arXiv:2602.05447, 2025
-
[13]
Codebase-Memory: Tree-Sitter-based knowledge graphs for LLM code exploration via MCP
Anonymous. Codebase-Memory: Tree-Sitter-based knowledge graphs for LLM code exploration via MCP. arXiv preprint arXiv:2603.27277, 2026
-
[14]
Y.-A. Xiao, P. Gao, C. Peng, and Y. Xiong. Reducing cost of LLM agents with trajectory reduction. Proc.\ ACM Softw.\ Eng., 3(FSE):FSE056, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.