Recognition: unknown
From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills
Pith reviewed 2026-05-08 04:01 UTC · model grok-4.3
The pith
An explicit Scheduling-Structural-Logical representation disentangles skill text into scheduling, structure, and logic for better machine use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
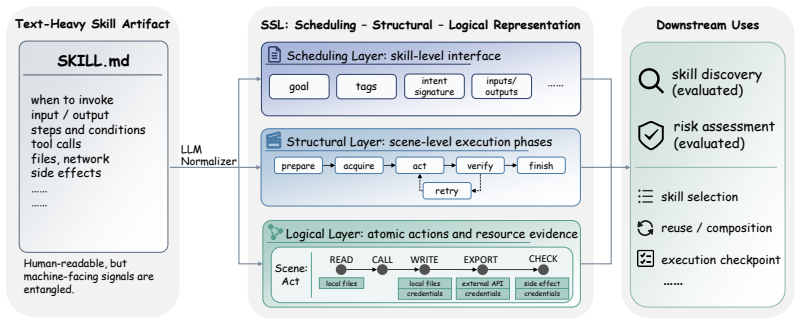
The Scheduling-Structural-Logical (SSL) representation disentangles skill-level scheduling signals, scene-level execution structure, and logic-level action/resource-use evidence from text-heavy skill artifacts. Instantiated with an LLM-based normalizer, SSL yields MRR@50 of 0.729 on Skill Discovery (up from 0.649) and macro F1 of 0.509 on Risk Assessment (up from 0.409), showing that source-grounded structure improves search and review over text-only methods.
What carries the argument
The Scheduling-Structural-Logical (SSL) representation, which separates scheduling signals, execution structure, and action logic from skill text using principles from Memory Organization Packets, Script Theory, and Conceptual Dependency to make capabilities easier for machines to acquire and leverage.
If this is right
- Agent skill collections become searchable by explicit interfaces and constraints rather than full-text similarity.
- Risk assessment gains precision because reviewers can examine scheduling, structure, and logic separately.
- Skill reuse in execution becomes more reliable since control flow and side effects are no longer hidden in prose.
- Skill management systems can support inspection and auditing without requiring full natural-language reasoning at every step.
- The approach positions skills as operationally actionable packages rather than static documents.
Where Pith is reading between the lines
- SSL structures could support automated composition of skills into larger workflows by matching scheduling and logic components.
- The separation may help detect conflicts or redundancies across skill libraries that text similarity alone misses.
- Classical cognitive representations might be combined with modern LLM agents to create hybrid systems that retain inspectability.
- Extending the normalizer to live execution traces could test whether SSL remains stable when skills are applied in real environments.
Load-bearing premise
The LLM-based normalizer accurately and consistently extracts scheduling, structural, and logical components from text skill descriptions without introducing hallucinations, biases, or loss of critical information.
What would settle it
Apply the normalizer to a benchmark set of skills that have manually annotated ground-truth SSL structures, then measure extraction fidelity and check whether the reported performance lifts disappear when using noisy or incomplete extractions.
Figures
read the original abstract
Large language model (LLM) agents increasingly rely on reusable skills: capability packages that combine instructions, control flow, constraints, and tool calls. In current agent systems, however, skills are still represented by text-heavy artifacts, mainly SKILL{.}md-style documents whose machine-usable evidence remains embedded largely in natural-language descriptions. As a result, skill-centered agent systems face a representation problem: both managing skill collections and using skills during agent execution require reasoning over invocation interfaces, execution structure, and concrete side effects, but these signals are often entangled in a single textual surface. An explicit representation of skill knowledge may therefore help make these artifacts easier for machines to acquire and leverage. Drawing on Memory Organization Packets, Script Theory, and Conceptual Dependency from Schank and Abelson's classical work on cognitive linguistic representation, we introduce what is, to our knowledge, the first structured representation for agent skill artifacts that disentangles skill-level scheduling signals, scene-level execution structure, and logic-level action/resource-use evidence: the Scheduling-Structural-Logical (SSL) representation. We instantiate SSL with an LLM-based normalizer and evaluate SSL-derived representations in two tasks, Skill Discovery and Risk Assessment. The experiment shows that SSL significantly outperforms the text-only baselines: in Skill Discovery, MRR@50 improves from 0.649 to 0.729; in Risk Assessment, macro F1 improves from 0.409 to 0.509. These findings suggest that an explicit, source-grounded structure can make agent skills easier to search and review, positioning SSL as a practical step toward more inspectable, reusable, and operationally actionable skill representations, rather than a finished standard or end-to-end skill-management mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Scheduling-Structural-Logical (SSL) representation for agent skills, drawing on Schank and Abelson's Memory Organization Packets, Script Theory, and Conceptual Dependency. Skills are converted from text (e.g., SKILL.md) to this disentangled form via an LLM-based normalizer. The representation is evaluated on Skill Discovery (MRR@50 improves from 0.649 to 0.729) and Risk Assessment (macro F1 improves from 0.409 to 0.509), outperforming text-only baselines. The authors position SSL as a practical step toward more inspectable and reusable skill artifacts for LLM agents.
Significance. If the results hold after proper validation, SSL offers a principled, source-grounded structure that could improve skill search, review, and operational use in agent systems. The explicit grounding in classical cognitive representations is a notable strength, providing external theoretical grounding rather than ad-hoc invention. The quantitative gains on two distinct tasks suggest potential for broader applicability in skill management. However, the significance is limited by the absence of controls that would confirm the gains arise from the SSL disentanglement itself.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation: The headline improvements (MRR@50 0.649→0.729; macro F1 0.409→0.509) are reported without details on experimental setup, baseline implementations, skill data sources, statistical significance testing, or controls for LLM variability. This is load-bearing for the central claim that SSL outperforms text-only baselines, as unstated factors could explain the modest deltas.
- [SSL Instantiation] SSL Instantiation via LLM Normalizer: No quantitative validation (accuracy, hallucination rate, information loss) of the LLM normalizer is provided. Because SSL representations are generated by this normalizer, any systematic augmentation, rephrasing of constraints, or addition of scheduling cues would make the downstream comparisons non-equivalent; the performance delta cannot be attributed to the Scheduling-Structural-Logical disentanglement.
minor comments (2)
- [Introduction] The abstract and introduction could more explicitly define the three SSL components (scheduling signals, scene-level structure, logic-level evidence) with a small illustrative example to aid reader comprehension.
- [Evaluation] Notation for the SSL tuple or components is introduced but not consistently referenced in the evaluation sections; a table mapping original text elements to SSL fields would improve traceability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [Experimental Evaluation] The headline improvements (MRR@50 0.649→0.729; macro F1 0.409→0.509) are reported without details on experimental setup, baseline implementations, skill data sources, statistical significance testing, or controls for LLM variability. This is load-bearing for the central claim that SSL outperforms text-only baselines, as unstated factors could explain the modest deltas.
Authors: We agree that additional experimental details are necessary to substantiate the reported gains. In the revised manuscript we will expand the Experimental Evaluation section with: a complete description of the setup including LLM prompting strategies and hyperparameters; explicit implementation details and code references for all baselines; characteristics and provenance of the skill datasets; results of statistical significance testing (e.g., bootstrap confidence intervals or paired tests); and controls for LLM variability such as repeated runs across seeds and temperatures with reported variance. These additions will allow readers to evaluate the robustness of the MRR@50 and macro-F1 improvements. revision: yes
-
Referee: [SSL Instantiation] No quantitative validation (accuracy, hallucination rate, information loss) of the LLM normalizer is provided. Because SSL representations are generated by this normalizer, any systematic augmentation, rephrasing of constraints, or addition of scheduling cues would make the downstream comparisons non-equivalent; the performance delta cannot be attributed to the Scheduling-Structural-Logical disentanglement.
Authors: We acknowledge the importance of validating the normalizer to isolate the contribution of the SSL structure. The current manuscript does not contain such quantitative checks. In revision we will add an evaluation subsection that measures normalizer fidelity on a human-annotated subset of skills, reporting accuracy, hallucination rate, and information-preservation metrics (semantic similarity and manual review of scheduling, structural, and logical elements). We will also clarify that text-only baselines operate directly on the original skill documents without LLM processing, ensuring the comparison isolates the effect of the disentangled representation rather than any incidental augmentation by the normalizer. revision: yes
Circularity Check
SSL representation grounded in external classical work; no derivation reduces to self-inputs
full rationale
The paper defines the Scheduling-Structural-Logical (SSL) representation by explicit reference to Schank and Abelson's Memory Organization Packets, Script Theory, and Conceptual Dependency, which are independent external sources. No equations, fitted parameters, or predictions are present; the LLM normalizer is described as an instantiation method rather than a learned component whose outputs are then re-used as evidence. Downstream evaluations (Skill Discovery MRR@50 and Risk Assessment F1) compare against text baselines without any self-citation chain or renaming of known results as novel derivations. The central claim therefore remains non-circular and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memory Organization Packets, Script Theory, and Conceptual Dependency from Schank and Abelson provide a suitable foundation for representing agent skills
invented entities (1)
-
Scheduling-Structural-Logical (SSL) representation
no independent evidence
Forward citations
Cited by 1 Pith paper
-
ObjectGraph: From Document Injection to Knowledge Traversal -- A Native File Format for the Agentic Era
ObjectGraph is a Markdown superset file format that represents documents as traversable knowledge graphs, achieving up to 95.3% token reduction for agents with no significant accuracy loss.
Reference graph
Works this paper leans on
-
[1]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
doi: 10.48550/arXiv.2410.09024. URLhttps://arxiv.org/abs/2410.09024. Anthropic. Introducing Claude Sonnet 4.5,
work page internal anchor Pith review doi:10.48550/arxiv.2410.09024
-
[2]
SkillAttack: Automated Red Teaming of Agent Skills through Attack Path Refinement
doi: 10.52202/ 079017-2636. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 97091a5177d8dc64b1da8bf3e1f6fb54-Abstract-Datasets_and_Benchmarks_Track.html. Zenghao Duan, Yuxin Tian, Zhiyi Yin, Liang Pang, Jingcheng Deng, Zihao Wei, Shicheng Xu, Yuyao Ge, and Xueqi Cheng. SkillAttack: Automated red teaming of agent skills through attack path ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
SkillAttack: Automated Red Teaming of Agent Skills through Attack Path Refinement
doi: 10.48550/arXiv.2604.04989. URL https://arxiv.org/abs/2604.04989. Charles J. Fillmore. Frame semantics. InLinguistics in the Morning Calm, pages 111–137. Hanshin Publishing Company, Seoul,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.04989
-
[4]
URLhttps://doi.org/10.1016/j.csi.2022.103657
doi: 10.1016/j.csi.2022.103657. URLhttps://doi.org/10.1016/j.csi.2022.103657. Google. Gemini 3 developer guide,
-
[5]
URL https://ai.google.dev/gemini-api/docs/ gemini-3. Official documentation forgemini-3.1-pro-preview. Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection.arXiv preprint arXiv:2302.12173,
work page internal anchor Pith review arXiv
-
[6]
doi: 10.48550/arXiv.2302. 12173. URLhttps://arxiv.org/abs/2302.12173. Yinghan Hou and Zongyou Yang. SkillSieve: A hierarchical triage framework for detecting malicious AI agent skills.arXiv preprint arXiv:2604.06550,
work page internal anchor Pith review doi:10.48550/arxiv.2302
-
[7]
SkillSieve: A Hierarchical Triage Framework for Detecting Malicious AI Agent Skills
doi: 10.48550/arXiv.2604.06550. URL https://arxiv.org/abs/2604.06550. Zimo Ji, Daoyuan Wu, Wenyuan Jiang, Pingchuan Ma, Zongjie Li, Yudong Gao, Shuai Wang, and Yingjiu Li. Taming various privilege escalation in LLM-based agent systems: A mandatory access control framework.arXiv preprint arXiv:2601.11893,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.06550
-
[8]
Preprint at https://arxiv.org/abs/ 2601.11893
doi: 10.48550/arXiv.2601.11893. URLhttps://arxiv.org/abs/2601.11893. Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781...
-
[9]
18653/v1/2020.emnlp-main.550. URLhttps://aclanthology.org/2020.emnlp-main.550/. 10 Juhee Kim, Woohyuk Choi, and Byoungyoung Lee. Prompt flow integrity to prevent privilege escalation in LLM agents.arXiv preprint arXiv:2503.15547,
-
[10]
doi: 10.48550/arXiv.2503. 15547. URLhttps://arxiv.org/abs/2503.15547. Koren Lazar, Matan Vetzler, Kiran Kate, Jason Tsay, David Boaz, Himanshu Gupta, Avraham Shinnar, Rohith D. Vallam, David Amid, Esther Goldbraich, Guy Uziel, Jim Laredo, and Ateret Anaby Tavor. Generating OpenAPI specifications from online API documentation with large language models. In...
-
[11]
Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis
URL https://aclanthology.org/2025. acl-industry.18/. Zhiyuan Li, Jingzheng Wu, Xiang Ling, Xing Cui, and Tianyue Luo. Towards secure agent skills: Architecture, threat taxonomy, and security analysis.arXiv preprint arXiv:2604.02837,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis
doi: 10.48550/arXiv.2604.02837. URLhttps://arxiv.org/abs/2604.02837. Yuan Liang, Ruobin Zhong, Haoming Xu, Chen Jiang, Yi Zhong, Runnan Fang, Jia-Chen Gu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Xin Xu, Tongtong Wu, Kun Wang, Yang Liu, Zhen Bi, Jungang Lou, Yuchen Eleanor Jiang, Hangcheng Zhu, Gang Yu, Haiwen Hong, Longtao Huang, Hui Xue, Chen...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.02837
-
[13]
Skillnet: Create, evaluate, and connect ai skills.arXiv preprint arXiv:2603.04448,
doi: 10.48550/arXiv.2603.04448. URL https://arxiv.org/abs/2603.04448. Jianghao Lin, Xinyuan Wang, Xinyi Dai, Menghui Zhu, Bo Chen, Ruiming Tang, Yong Yu, and Weinan Zhang. MassTool: A multi-task search-based tool retrieval framework for large language models.arXiv preprint arXiv:2507.00487,
-
[14]
URL https: //arxiv.org/abs/2507.00487
doi: 10.48550/arXiv.2507.00487. URL https: //arxiv.org/abs/2507.00487. Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. DeepSeek-V3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556,
-
[15]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
doi: 10.48550/arXiv.2512.02556. URL https://arxiv.org/abs/2512.02556. Dawei Liu, Zongxia Li, Hongyang Du, Xiyang Wu, Shihang Gui, Yongbei Kuang, and Lichao Sun. Graph of skills: Dependency-aware structural retrieval for massive agent skills.arXiv preprint arXiv:2604.05333, 2026a. doi: 10.48550/arXiv.2604.05333. URL https://arxiv.org/abs/ 2604.05333. Yi Li...
work page internal anchor Pith review doi:10.48550/arxiv.2512.02556
-
[16]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
doi: 10.48550/arXiv.2503.21460. URLhttps://arxiv.org/abs/2503.21460. Marvin Minsky. A framework for representing knowledge. In Patrick H. Winston, editor,The Psychology of Computer Vision, pages 211–277. McGraw-Hill, New York,
-
[17]
Gorilla: Large Language Model Connected with Massive APIs
URL https://openai.com/index/gpt-5-system-card/ . Official system card. Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334,
work page internal anchor Pith review arXiv
-
[18]
doi: 10.48550/arXiv.2305. 15334. URLhttps://arxiv.org/abs/2305.15334. Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 1600...
-
[19]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
doi: 10.48550/arXiv.2307.16789. URLhttps://arxiv.org/abs/2307.16789. Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pages 3982...
-
[20]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Association for Computational Linguistics. doi: 10.18653/v1/D19-1410. URLhttps://aclanthology.org/D19-1410/. Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox. InInternational Conference on Learning Representations,
-
[21]
URL https://arxiv.org/abs/2309.15817. Roger C. Schank. Conceptual dependency: A theory of natural language understanding.Cognitive Psychology, 3(4):552–631,
work page internal anchor Pith review arXiv
-
[22]
doi: 10.1016/0010-0285(72)90022-9. Roger C. Schank. Language and memory.Cognitive Science, 4(3):243–284,
-
[23]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761,
work page internal anchor Pith review arXiv
-
[24]
Toolformer: Language Models Can Teach Themselves to Use Tools
doi: 10.48550/arXiv.2302.04761. URL https://arxiv.org/abs/2302.04761. Zhengliang Shi, Yuhan Wang, Lingyong Yan, Pengjie Ren, Shuaiqiang Wang, Dawei Yin, and Zhaochun Ren. Retrieval models aren’t tool-savvy: Benchmarking tool retrieval for large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 24497– 24524, Vien...
work page internal anchor Pith review doi:10.48550/arxiv.2302.04761 2025
-
[25]
Association for Computational Linguistics. doi: 10.18653/v1/2025. findings-acl.1258. URLhttps://aclanthology.org/2025.findings-acl.1258/. Nandan Thakur, Nils Reimers, Andreas Rucklé, Abhishek Srivastava, and Iryna Gurevych. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. InThirty-fifth Conference on Neural Informa...
-
[26]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
URLhttps://openreview.net/forum?id=wCu6T5xFjeJ. Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shuofei Qiao, Kexin Cao, Guozhou Zheng, Xiang Qi, Peng Zhang, and Shumin Deng. SkillX: Automatically constructing skill knowledge bases for agents.arXiv preprint arXiv:2604.04804,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
doi: 10.48550/arXiv. 2604.04804. URLhttps://arxiv.org/abs/2604.04804. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[28]
Voyager: An Open-Ended Embodied Agent with Large Language Models
doi: 10.48550/arXiv.2305.16291. URLhttps://arxiv.org/ abs/2305.16291. Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Jun- zhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wensen Ch...
work page internal anchor Pith review doi:10.48550/arxiv.2305.16291
-
[29]
The Rise and Potential of Large Language Model Based Agents: A Survey
doi: 10.48550/arXiv.2309.07864. URL https://arxiv.org/abs/2309.07864. Haoyuan Xu, Chang Li, Xinyan Ma, Xianhao Ou, Zihan Zhang, Tao He, Xiangyu Liu, Zixiang Wang, Jiafeng Liang, Zheng Chu, Runxuan Liu, Rongchuan Mu, Dandan Tu, Ming Liu, and Bing Qin. The evolution of tool use in llm agents: From single-tool call to multi-tool orchestration.arXiv preprint ...
work page internal anchor Pith review doi:10.48550/arxiv.2309.07864
-
[30]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430,
work page internal anchor Pith review arXiv
-
[31]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
doi: 10.48550/arXiv.2602.12430. URLhttps://arxiv.org/abs/2602.12430. Lifan Yuan, Yangyi Chen, Xingyao Wang, Yi R. Fung, Hao Peng, and Heng Ji. CRAFT: Customizing LLMs by creating and retrieving from specialized toolsets. InInternational Conference on Learning Representations,
work page internal anchor Pith review doi:10.48550/arxiv.2602.12430
-
[32]
doi: 10.48550/arXiv.2309.17428. URL https://arxiv.org/abs/2309. 17428. Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Yongliang Shen, Kan Ren, Dongsheng Li, and Deqing Yang. EASYTOOL: Enhancing LLM-based agents with concise tool instruction. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational L...
-
[33]
Association for Computational Linguistics. doi: 10.18653/v1/2025.naacl-long.44. URLhttps://aclanthology.org/2025.naacl-long.44/. Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (ASB): Formalizing and benchmarking attacks and defenses in LLM-based agents. InInternational ...
-
[34]
doi: 10.48550/arXiv.2603.22455. URL https://arxiv.org/abs/2603.22455. Yuanhang Zheng, Peng Li, Wei Liu, Yang Liu, Jian Luan, and Bin Wang. ToolRerank: Adaptive and hierarchy-aware reranking for tool retrieval. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages ...
-
[35]
URL https://aclanthology
ELRA and ICCL. URL https://aclanthology. org/2024.lrec-main.1413/. A Definition of SSL Schema This appendix gives the field-level realization of the SSL representation defined in Eq
2024
-
[36]
skill": {
The scene_type field is likewise drawn from a closed inventory so that phase categories remain comparable across skills; as listed in Table 5, these types are PREPARE, ACQUIRE,REASON,ACT,VERIFY,RECOVER, andFINALIZE. A.4 Logical Layer The logical layer represents the operations that implement each scene. It is defined over source- grounded atomic actions, ...
2025
-
[37]
The source-outline controls in Table 1 are constructed without SSL fields. They deterministically extract headings, short bullet items, interface- or resource-looking lines, and short prose spans from the original SKILL.md. This provides a deterministic non-SSL document-enrichment control for testing whether the SSL improvement can be explained by generic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.