Beyond Semantics: Measuring Fine-Grained Emotion Preservation in Small Language Model-Based Machine Translation
Pith reviewed 2026-05-07 04:59 UTC · model grok-4.3
The pith
Small language models preserve fine-grained emotions during backtranslation and improve with emotion-aware prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
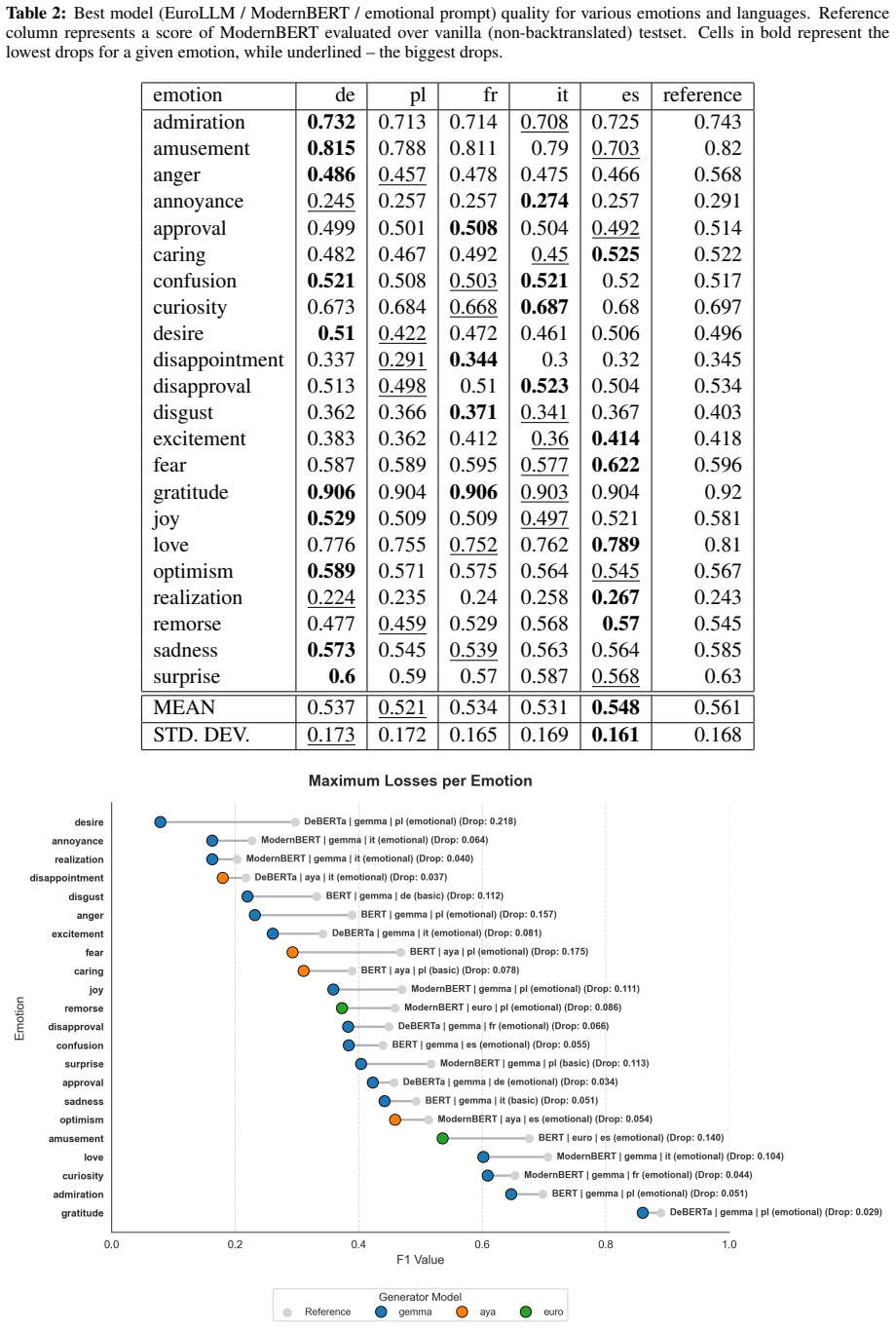
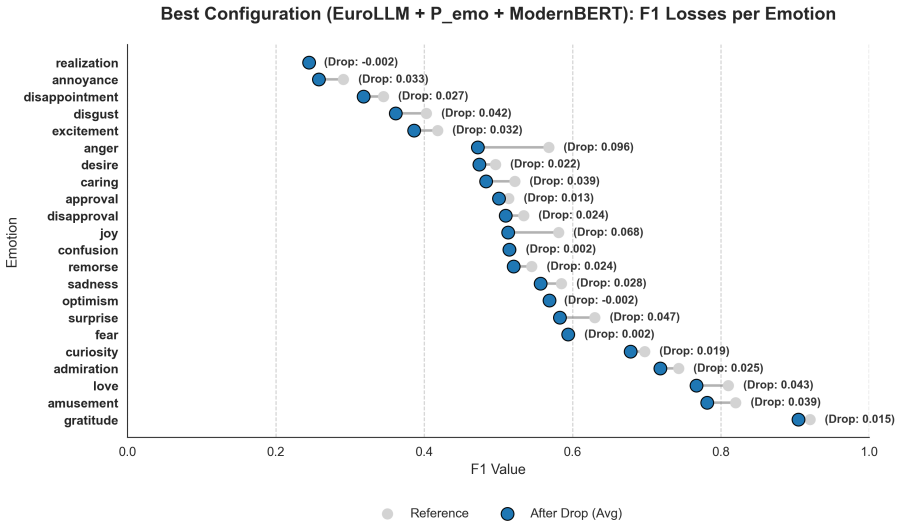
The three small language models exhibit an inherent capability to retain emotional sentiment during backtranslation. This capability can be enhanced via emotion-aware prompting. ModernBERT serves as an effective alternative to BERT for emotion classification in the context of machine translation evaluation.
What carries the argument
Backtranslation on the GoEmotions dataset combined with emotion classification using BERT and ModernBERT to quantify fine-grained emotion preservation.
Load-bearing premise
Backtranslation serves as a reliable stand-in for one-directional translation without round-trip effects that change the emotional content.
What would settle it
Performing the same emotion preservation tests using direct translation to a target language and back-comparing to original would show substantially different preservation rates.
Figures

read the original abstract
Preserving affective nuance remains a challenge in Machine Translation (MT), where semantic equivalence often takes precedence over emotional fidelity. This paper evaluates the performance of three state-of-the-art Small Language Models (SLMs) -- EuroLLM, Aya Expanse, and Gemma -- in maintaining fine-grained emotions during backtranslation. Using the GoEmotions dataset, which comprises Reddit comments across 28 distinct categories, we assess emotional preservation across five European languages: German, French, Spanish, Italian, and Polish. Specifically, we investigate (i) the inherent capability of these SLMs to retain emotional sentiment, (ii) the efficacy of emotion-aware prompting in improving preservation, and (iii) the performance of ModernBERT as a contemporary alternative to BERT for emotion classification in MT evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that three small language models (EuroLLM, Aya Expanse, and Gemma) inherently preserve fine-grained emotions across 28 GoEmotions categories during backtranslation to and from German, French, Spanish, Italian, and Polish; that emotion-aware prompting improves this preservation; and that ModernBERT serves as an effective alternative to BERT for emotion classification in MT evaluation contexts.
Significance. If the results hold after methodological validation, the work would contribute to MT evaluation by shifting focus from semantic equivalence to affective fidelity, particularly for SLMs handling user-generated content. It could guide prompting strategies for emotion retention and demonstrate ModernBERT's utility in classification pipelines. The multi-language, multi-category setup using GoEmotions adds empirical breadth to the field.
major comments (2)
- [Experimental Design / Methods] The experimental protocol uses backtranslation (source to target to source) as the sole proxy for measuring emotion preservation in one-directional MT. No control arm is reported that performs direct forward translation to the target language and then classifies emotions on the target-side output. This is load-bearing for the central claims about inherent SLM capabilities and prompting gains, because round-trip artifacts (information loss, model-specific reconstruction biases, or language-pair asymmetries) are not isolated and could confound attribution of results to MT fidelity rather than backtranslation dynamics.
- [Abstract / Results] The abstract supplies no quantitative results, preservation rates, statistical tests, or error analysis for the three SLMs, prompting conditions, or language pairs. Without these data or details on how ModernBERT was applied for classification, the magnitude and reliability of the reported capabilities cannot be assessed.
minor comments (2)
- [Abstract / Methodology] The abstract does not specify the exact emotion-aware prompting templates, any preprocessing steps for GoEmotions, or implementation details for the SLMs and ModernBERT (e.g., temperature, decoding strategy, or fine-tuning).
- [Experimental Setup] Potential language-specific effects or asymmetries across the five target languages are not discussed as a factor in the evaluation design or results interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us identify areas for improvement in clarity and methodological transparency. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Experimental Design / Methods] The experimental protocol uses backtranslation (source to target to source) as the sole proxy for measuring emotion preservation in one-directional MT. No control arm is reported that performs direct forward translation to the target language and then classifies emotions on the target-side output. This is load-bearing for the central claims about inherent SLM capabilities and prompting gains, because round-trip artifacts (information loss, model-specific reconstruction biases, or language-pair asymmetries) are not isolated and could confound attribution of results to MT fidelity rather than backtranslation dynamics.
Authors: We appreciate this observation on the choice of backtranslation as our evaluation proxy. Our design deliberately uses round-trip translation to enable consistent application of the same English-trained ModernBERT classifier to both original and reconstructed texts, avoiding the introduction of new biases from training or adapting separate fine-grained emotion classifiers for German, French, Spanish, Italian, and Polish. Direct forward translation with target-side classification is not feasible within the current scope without developing comparable multilingual models for all 28 GoEmotions categories, which would itself confound cross-lingual comparisons. We acknowledge that backtranslation can introduce reconstruction artifacts and language-pair asymmetries. In the revised manuscript we will add an explicit justification subsection in Methods, expand the error analysis to quantify reconstruction effects where possible, discuss observed language-pair variations, and clearly delimit the scope of our claims to the backtranslation setting. These changes will strengthen transparency without altering the core experimental protocol. revision: partial
-
Referee: [Abstract / Results] The abstract supplies no quantitative results, preservation rates, statistical tests, or error analysis for the three SLMs, prompting conditions, or language pairs. Without these data or details on how ModernBERT was applied for classification, the magnitude and reliability of the reported capabilities cannot be assessed.
Authors: We agree that the abstract would be more informative with key quantitative details. We will revise the abstract to report average emotion preservation rates across the 28 GoEmotions categories for each of the three SLMs, the magnitude of improvement from emotion-aware prompting, ModernBERT's classification performance relative to BERT, and reference to the statistical tests employed. We will also ensure the Methods section includes additional specifics on ModernBERT's application (e.g., fine-tuning details and inference procedure). These updates will allow readers to immediately assess effect sizes and reliability while remaining within abstract length constraints. revision: yes
Circularity Check
No circularity: purely empirical evaluation relying on external datasets and models
full rationale
The paper conducts an empirical study evaluating three SLMs (EuroLLM, Aya Expanse, Gemma) on fine-grained emotion preservation (28 GoEmotions categories) during backtranslation across five languages, plus tests of emotion-aware prompting and ModernBERT as a classifier. No mathematical derivations, equations, fitted parameters, predictions, or ansatzes are present. All measurements derive from direct application of public datasets (GoEmotions) and off-the-shelf pre-trained models; results are reported as experimental outcomes rather than any self-referential construction. The backtranslation protocol is a chosen measurement method whose validity can be critiqued on external grounds but does not reduce any claimed result to the inputs by definition or self-citation. No self-citations are load-bearing, and the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption The GoEmotions dataset provides accurate and reliable fine-grained emotion labels for Reddit comments across 28 categories.
- domain assumption Backtranslation is a suitable proxy for assessing emotion preservation in standard machine translation.
- domain assumption Emotion-aware prompting can be applied to the SLMs without fundamentally altering their translation behavior in unintended ways.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION fin.entry add.period write newline FUNCTION new.block output.state before.all = 'skip after.block 'output.state := if FUNCTION new.sentence output.state after.block = 'skip output.state before.all = 'skip after.sentence 'output.state := if if FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 if FUNCTIO...
-
[2]
Aho, Alfred V. and Jeffrey D. Ullman. 1972. The Theory of Parsing, Translation and Compiling , volume 1. Prentice- Hall , Englewood Cliffs, NJ
work page 1972
-
[3]
American Psychological Association . 1983. Publications Manual . American Psychological Association, Washington, DC
work page 1983
-
[4]
Association for Computing Machinery . 1983. Computing Reviews , 24(11):503--512
work page 1983
-
[5]
Chandra, Ashok K., Dexter C. Kozen, and Larry J. Stockmeyer. 1981. Alternation. Journal of the Asso\-ciation for Computing Machinery , 28(1):114--133
work page 1981
-
[6]
Gledson, Anne, and John Keane. 2008a. Measuring Topic Homogeneity and its Application to Dictionary-Based Word-Sense Disambiguation. Coling 2008, 22nd International Conference on Computational Linguistics , Manchester, UK. 273--280
work page 2008
-
[7]
Gledson, Anne, and John Keane. 2008b. Using Web-Search Results to Measure Word-group Similarity. Coling 2008, 22nd International Conference on Computational Linguistics , Manchester, UK. 281--288
work page 2008
-
[8]
Gusfield, Dan. 1997. Algorithms on Strings, Trees and Sequences . Cambridge University Press, Cambridge, UK
work page 1997
-
[9]
Tam, Yik-Cheung and Tanja Schultz. 2006. Unsupervised Language Model Adaptation Using Latent Semantic Marginals. Interspeech 2006 -- ICSLP, Ninth International Conference on Spoken Language Processing , Pittsburgh, Pennsylvania, paper 1705-Thu1A2O.2
work page 2006
-
[10]
Tam, Yik-Cheung and Tanja Schultz. 2007. Correlated Latent Semantic Model for Unsupervised Language Model Adaptation. Proceedings of ICASSP 2007, International Conference on Acoustics, Speech, and Signal Processing , Honolulu, Hawaii, Vol. IV, 41--44
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.