Flying by Inference: Active Inference World Models for Adaptive UAV Swarms
Pith reviewed 2026-05-07 06:44 UTC · model grok-4.3
The pith
A hierarchical active inference model learned from expert demonstrations lets UAV swarms adapt trajectories online by minimizing KL divergence to reference behaviors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By abstracting expert demonstrations into Mission, Route, and Motion dictionaries and learning a probabilistic world model, the UAV swarm evaluates actions through posterior beliefs over symbolic states and minimizes KL-divergence-based abnormality indicators against expert-derived reference distributions. This process supports mission allocation, route insertion, motion adaptation, and collision-aware replanning without rerunning the offline optimizer. Extended Kalman filter and particle filter modules at the motion level correct trajectories when observations are noisy or non-smooth.
What carries the argument
The hierarchical probabilistic world model built from Mission, Route, and Motion dictionaries, which carries the argument by enabling belief updating and KL-divergence minimization to expert reference distributions.
If this is right
- The framework preserves expert-like planning structure while producing smoother and more stable trajectories than modified Q-learning in simulation.
- The learned world model corrects symbolic predictions when validated on real-flight UAV trajectory data under noisy and non-smooth observations.
- Mission allocation, route insertion, and collision-aware replanning occur without requiring the offline optimizer to rerun.
- Bayesian state estimators at the motion level improve trajectory accuracy under uncertainty.
Where Pith is reading between the lines
- If the expert demonstrations cover a broad enough set of conditions, the same inference process could support larger swarms facing frequent environmental changes.
- The symbolic abstraction layers might allow the method to combine with higher-level mission planners in other multi-agent robotic systems.
- Deployment would need direct checks that divergence minimization alone prevents unsafe actions in situations outside the original demonstration set.
Load-bearing premise
The offline genetic-algorithm demonstrations with repulsive-force avoidance represent the desirable behaviors well enough that the learned model will generalize to safe adaptations when online actions minimize KL divergence to the references.
What would settle it
A concrete test in which the swarm enters a scenario absent from the expert demonstrations and produces a collision or incomplete mission while still minimizing the KL-divergence indicator would falsify the generalization claim.
Figures

















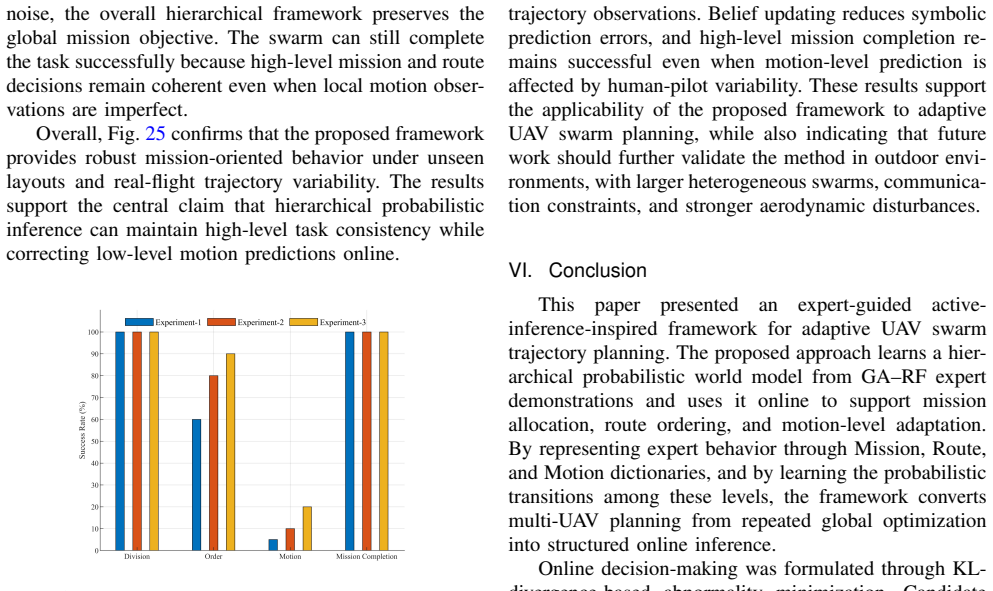
read the original abstract
This paper presents an expert-guided active-inference-inspired framework for adaptive UAV swarm trajectory planning. The proposed method converts multi-UAV trajectory design from a repeated combinatorial optimization problem into a hierarchical probabilistic inference problem. In the offline phase, a genetic-algorithm planner with repulsive-force collision avoidance (GA--RF) generates expert demonstrations, which are abstracted into Mission, Route, and Motion dictionaries. These dictionaries are used to learn a probabilistic world model that captures how expert mission allocations induce route orders and how route orders induce motion-level behaviors. During online operation, the UAV swarm evaluates candidate actions by forming posterior beliefs over symbolic states and minimizing KL-divergence-based abnormality indicators with respect to expert-derived reference distributions. This enables mission allocation, route insertion, motion adaptation, and collision-aware replanning without rerunning the offline optimizer. Bayesian state estimators, including EKF and PF modules, are integrated at the motion level to improve trajectory correction under uncertainty. Simulation results show that the proposed framework preserves expert-like planning structure while producing smoother and more stable behavior than modified Q-learning. Additional validation using real-flight UAV trajectory data demonstrates that the learned world model can correct symbolic predictions under noisy and non-smooth observations, supporting its applicability to adaptive UAV swarm autonomy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an expert-guided active-inference framework for adaptive UAV swarm trajectory planning. Offline, a GA-RF planner generates expert demonstrations abstracted into Mission, Route, and Motion dictionaries used to learn a hierarchical probabilistic world model. Online, the swarm forms posterior beliefs over symbolic states and minimizes KL-divergence to expert-derived reference distributions to enable mission allocation, route insertion, motion adaptation, and collision-aware replanning without re-running the optimizer; Bayesian estimators (EKF/PF) handle motion-level uncertainty. Simulation results claim preservation of expert-like structure with smoother, more stable behavior than modified Q-learning, while real-flight UAV trajectory data is used to show correction of symbolic predictions under noisy observations.
Significance. If the central claims hold, the work could meaningfully advance real-time adaptive autonomy for UAV swarms by recasting repeated combinatorial optimization as efficient hierarchical inference, offering a bridge between symbolic expert planning and probabilistic online adaptation that may improve stability and responsiveness in dynamic settings. The hierarchical dictionary structure and integration of active-inference KL minimization represent a distinctive technical contribution, though the absence of quantitative metrics and generalization tests currently limits the assessed significance.
major comments (4)
- [Abstract] Abstract: The claim that the framework produces 'smoother and more stable behavior than modified Q-learning' is unsupported by any quantitative metrics (e.g., trajectory smoothness, collision rates, stability indices), error bars, statistical tests, or ablation studies, leaving the comparative performance assertion without measurable evidence.
- [Method] Method (offline-to-online conversion): Reference distributions are constructed directly from the same GA-RF expert demonstrations used to train the world model, creating dependence that may undermine the independence of the online KL-minimization step and the claim of producing expert-like adaptations without re-optimization.
- [Validation] Validation and generalization: No out-of-distribution test cases, demonstration coverage analysis, or safety metrics (e.g., collision rates under unseen obstacle densities or mission changes) are reported, so the central claim that KL minimization yields safe, collision-free adaptations in novel online conditions lacks supporting evidence.
- [Hierarchical Model] Hierarchical model: The three-level decomposition into Mission, Route, and Motion dictionaries is asserted to be sufficient to capture swarm dynamics without justification, ablation studies, or analysis of completeness, yet this decomposition is load-bearing for the entire inference pipeline.
minor comments (2)
- [Abstract] Abstract and method: The precise mathematical form of the 'KL-divergence-based abnormality indicators' and the weighting factors across hierarchy levels should be stated explicitly, as these appear to be free parameters whose tuning affects the inference behavior.
- [Method] Overall presentation: Clarify how the learned probabilistic world model is trained (e.g., exact likelihoods, optimization procedure) and how posterior beliefs over symbolic states are computed, as these steps are central but described at a high level.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. The comments identify important areas for improvement, particularly regarding quantitative evidence, validation, and justification of design choices. We provide point-by-point responses to the major comments below and describe the revisions we intend to make in the updated version of the paper to strengthen the presentation and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] The claim that the framework produces 'smoother and more stable behavior than modified Q-learning' is unsupported by any quantitative metrics (e.g., trajectory smoothness, collision rates, stability indices), error bars, statistical tests, or ablation studies, leaving the comparative performance assertion without measurable evidence.
Authors: We agree that the current presentation of results relies primarily on qualitative observations and trajectory visualizations. To address this, we will augment the simulation results section with quantitative metrics, including measures of trajectory smoothness (such as integrated jerk), collision avoidance rates, and stability indices (e.g., variance in inter-agent distances). These will be presented with error bars across multiple runs and accompanied by statistical significance tests against the modified Q-learning baseline. Additionally, we will include ablation studies to isolate the contributions of the hierarchical inference components. revision: yes
-
Referee: [Method] Reference distributions are constructed directly from the same GA-RF expert demonstrations used to train the world model, creating dependence that may undermine the independence of the online KL-minimization step and the claim of producing expert-like adaptations without re-optimization.
Authors: The reference distributions encode the expert-derived priors over symbolic states at each level, while the world model learns the conditional probabilities linking these levels from the demonstrations. During online operation, the swarm performs Bayesian inference to update beliefs based on current observations and then minimizes the KL divergence to these references to select actions. This process allows for adaptive replanning in response to environmental changes without invoking the full GA-RF optimizer. The dependence is intentional as it transfers expert knowledge, but the inference mechanism enables generalization to unseen configurations. We will revise the method section to more explicitly delineate the roles of the world model and reference distributions to clarify this point. revision: partial
-
Referee: [Validation] No out-of-distribution test cases, demonstration coverage analysis, or safety metrics (e.g., collision rates under unseen obstacle densities or mission changes) are reported, so the central claim that KL minimization yields safe, collision-free adaptations in novel online conditions lacks supporting evidence.
Authors: We acknowledge the need for stronger evidence on generalization. In the revised manuscript, we will add out-of-distribution experiments involving novel obstacle configurations and mission alterations not present in the training demonstrations. We will report safety metrics such as collision rates and mission success rates under these conditions, along with an analysis of the demonstration coverage. The existing real-flight validation already shows the model's ability to correct predictions under noisy observations, which serves as a preliminary robustness test. These additions will better support the claims of safe adaptations in dynamic settings. revision: yes
-
Referee: [Hierarchical Model] The three-level decomposition into Mission, Route, and Motion dictionaries is asserted to be sufficient to capture swarm dynamics without justification, ablation studies, or analysis of completeness, yet this decomposition is load-bearing for the entire inference pipeline.
Authors: The hierarchical decomposition is grounded in the standard structure of multi-UAV planning problems, where mission-level decisions (e.g., task allocation) influence route-level sequencing, which in turn determines motion-level trajectories. This mirrors approaches in hierarchical task networks and symbolic planning. To provide justification, we will expand the manuscript with a dedicated subsection explaining the rationale, supported by references to related literature. Furthermore, we will conduct and report ablation studies that compare the three-level model against reduced hierarchies to demonstrate its completeness and performance benefits for the inference pipeline. revision: yes
Circularity Check
KL minimization to expert-derived references from training data makes online adaptations reproduce fitted expert behaviors by construction
specific steps
-
fitted input called prediction
[Abstract (online operation paragraph)]
"These dictionaries are used to learn a probabilistic world model that captures how expert mission allocations induce route orders and how route orders induce motion-level behaviors. During online operation, the UAV swarm evaluates candidate actions by forming posterior beliefs over symbolic states and minimizing KL-divergence-based abnormality indicators with respect to expert-derived reference distributions. This enables mission allocation, route insertion, motion adaptation, and collision-aware replanning without rerunning the offline optimizer."
The expert-derived reference distributions are built from the identical GA-RF demonstrations used to train the world model. Consequently the online KL-minimization step is constructed to reproduce the statistical structure of the training input, rendering the claimed 'expert-like planning structure' equivalent to the fitted data by design rather than an independent prediction or derivation.
full rationale
The paper's core conversion of combinatorial optimization into hierarchical inference rests on learning a probabilistic world model and reference distributions directly from the same GA-RF expert demonstrations. Online posterior formation and KL minimization are then performed with respect to those references, so preservation of expert-like structure is statistically forced by the training input rather than independently derived. Bayesian estimators and the Q-learning comparison supply some independent empirical content, preventing a higher score, but the load-bearing claim of safe adaptations without re-running the optimizer reduces to matching the fitted distribution. No self-citation chains, uniqueness theorems, or ansatz smuggling appear in the abstract or described method.
Axiom & Free-Parameter Ledger
free parameters (2)
- KL-divergence weighting factors across hierarchy levels
- parameters of the learned probabilistic world model
axioms (3)
- domain assumption Expert demonstrations generated by GA-RF represent desirable or near-optimal swarm behavior
- ad hoc to paper The three-level decomposition into Mission, Route, and Motion dictionaries is sufficient to capture relevant swarm dynamics
- domain assumption Minimizing KL divergence to expert-derived distributions produces adaptive, stable, and collision-aware behavior
invented entities (1)
-
Mission, Route, and Motion dictionaries
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Active Inference-Driven World Modeling for Adaptive UA V Swarm Trajectory Design,
K. Arshid, A. Krayani, L. Marcenaro, D. M. Gomez, and C. Regaz- zoni, “Active Inference-Driven World Modeling for Adaptive UA V Swarm Trajectory Design,” inICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2026, pp. 22 147–22 151
work page 2026
-
[2]
F. Ahmad, M. Y . Mirza, I. Hussain, and K. Arshid, “A Multi-Ray Channel Modelling Approach to Enhance UA V Communica- 18 IEEE TRANSACTIONS VOL. XX, No. XX XXXXX 2020 tions in Networked Airspace,”Inventions, vol. 10, no. 4, p. 51, July 2025
work page 2020
-
[3]
Toward autonomous uav swarm navigation: A review of trajectory design paradigms,
K. Arshid, A. Krayani, L. Marcenaro, D. M. Gomez, and C. Regaz- zoni, “Toward autonomous uav swarm navigation: A review of trajectory design paradigms,”Sensors, vol. 25, no. 18, p. 5877, Sep. 2025
work page 2025
-
[4]
Car: A cutting and repulsion-based evolutionary framework for mixed-integer programming problems,
J. Liu, Y . Wang, P.-Q. Huang, and S. Jiang, “Car: A cutting and repulsion-based evolutionary framework for mixed-integer programming problems,”IEEE Transactions on Cybernetics, vol. 52, no. 12, pp. 13 129–13 141, 2021
work page 2021
-
[5]
Y . Chai, Z. Zhang, H. Yu, J. Han, Y . Fang, and X. Liang, “A tra- jectory planning scheme for collaborative aerial transportation systems by graph-based searching and cable tension optimiza- tion,”IEEE/ASME Transactions on Mechatronics, 2025
work page 2025
-
[6]
An improved genetic algorithm for constrained optimization problems,
F. Wang, G. Xu, and M. Wang, “An improved genetic algorithm for constrained optimization problems,”IEEE Access, vol. 11, pp. 10 032–10 044, 2023
work page 2023
-
[7]
Particle swarm optimization algorithm and its applica- tions: a systematic review,
A. G. Gad, “Particle swarm optimization algorithm and its applica- tions: a systematic review,”Archives of computational methods in engineering, vol. 29, no. 5, pp. 2531–2561, 2022
work page 2022
-
[8]
M. J. C. Manullang, K. Priandana, and M. K. D. Hardhienata, “Op- timum trajectory of multi-uav for fertilization of paddy fields using ant colony optimization (aco) and 2-opt algorithms,” in AIP conference proceedings, vol. 2482, no. 1. AIP Publishing, 2023
work page 2023
-
[9]
B. Shi, Z. Chen, and Z. Xu, “A deep reinforcement learning based approach for optimizing trajectory and frequency in energy constrained multi-uav assisted mec system,”IEEE Transactions on Network and Service Management, 2024
work page 2024
-
[10]
X. Li, Y . Qin, J. Huo, and W. Huangfu, “Computation of- floading and trajectory planning of multi-uav-enabled mec: A knowledge-assisted multiagent reinforcement learning ap- proach,”IEEE Transactions on Vehicular Technology, vol. 73, no. 5, pp. 7077–7088, 2023
work page 2023
-
[11]
Active inference as a theory of sentient behavior,
G. Pezzulo, T. Parr, and K. Friston, “Active inference as a theory of sentient behavior,”Biological Psychology, vol. 186, p. 108741, 2024
work page 2024
-
[12]
Incremental learning through probabilistic behavior predic- tion,
S. Nozari, A. Krayani, L. Marcenaro, D. Martin, and C. Regazzoni, “Incremental learning through probabilistic behavior predic- tion,” in2022 30th European Signal Processing Conference (EUSIPCO). IEEE, 2022, pp. 1502–1506
work page 2022
-
[13]
Uav swarm trajectory design for wireless networks using genetic algorithm-driven repulsion forces,
K. Arshid, A. Krayani, L. Marcenaro, D. M. Gomez, and C. Regaz- zoni, “Uav swarm trajectory design for wireless networks using genetic algorithm-driven repulsion forces,”IEEE Access, Sep. 2025
work page 2025
-
[14]
Path planning for uavs for max- imum information collection,
H. Ergezer and K. Leblebicioglu, “Path planning for uavs for max- imum information collection,”IEEE Transactions on Aerospace and Electronic Systems, vol. 49, no. 1, pp. 502–520, Jan 2013
work page 2013
-
[15]
A hybrid offline optimization method for reconfiguration of multi-uav formations,
B. Li, J. Zhang, L. Dai, K. L. Teo, and S. Wang, “A hybrid offline optimization method for reconfiguration of multi-uav formations,”IEEE Transactions on Aerospace and Electronic Systems, vol. 57, no. 1, pp. 506–520, Feb 2021
work page 2021
-
[16]
Y . Chen, D. Yang, and J. Yu, “Multi-uav task assignment with pa- rameter and time-sensitive uncertainties using modified two-part wolf pack search algorithm,”IEEE Transactions on Aerospace and Electronic Systems, vol. 54, no. 6, pp. 2853–2872, Dec 2018
work page 2018
-
[17]
Dynamic mission planning algorithm for uav formation in battlefield environment,
J. Zhang, Y . Cui, and J. Ren, “Dynamic mission planning algorithm for uav formation in battlefield environment,”IEEE Transac- tions on Aerospace and Electronic Systems, vol. 59, no. 4, pp. 3750–3765, Aug 2023
work page 2023
-
[18]
W. Wu, L. Zhang, J. Le, and Z. Lu, “Integrated method for multi- uav task assignment and trajectory planning with deadlock based on three-dimensional dubins path,”Scientific Reports, vol. 15, pp. 1–13, 2025
work page 2025
-
[19]
Fast genetic algorithm path planner for fixed-wing military uav using gpu,
V . Roberge, M. Tarbouchi, and G. Labont ´e, “Fast genetic algorithm path planner for fixed-wing military uav using gpu,”IEEE Transactions on Aerospace and Electronic Systems, vol. 54, no. 5, pp. 2105–2117, Oct 2018
work page 2018
-
[20]
A survey on uav control with multi-agent reinforcement learning,
C. C. Ekechi, T. Elfouly, A. Alouani, and T. Khattab, “A survey on uav control with multi-agent reinforcement learning,”Drones, vol. 9, no. 7, p. 484, 2025
work page 2025
-
[21]
A survey on reinforcement learning methods for uav systems,
H. Chen, Y . Lin, M. Fu, L. Yao, and M. Sheng, “A survey on reinforcement learning methods for uav systems,”ACM Computing Surveys, 2025
work page 2025
-
[22]
Z. Peng, G. Wu, B. Luo, and L. Wang, “Multi-uav cooperative pursuit strategy with limited visual field in urban airspace: A multi-agent reinforcement learning approach,”IEEE/CAA Journal of Automatica Sinica, vol. 12, no. 7, pp. 1350–1367, July 2025
work page 2025
-
[23]
Neural network-based path planning for fixed-wing uavs with constraints on terminal roll angle,
Q. Xu, F. Wu, and Z. Chen, “Neural network-based path planning for fixed-wing uavs with constraints on terminal roll angle,” Drones, vol. 9, no. 5, p. 378, 2025
work page 2025
-
[24]
Neural network-based trajectory optimization for unmanned aerial vehicles,
J. F. Horn, E. M. Schmidt, B. R. Geiger, and M. P. DeAngelo, “Neural network-based trajectory optimization for unmanned aerial vehicles,”Journal of Guidance, Control, and Dynamics, vol. 35, no. 2, pp. 548–562, 2012
work page 2012
-
[25]
Intelligent resource allocation for uav-based cognitive noma networks: An active inference approach,
F. Obite, A. Krayani, A. S. Alam, L. Marcenaro, A. Nallanathan, and C. Regazzoni, “Intelligent resource allocation for uav-based cognitive noma networks: An active inference approach,” in 2023 IEEE Future Networks World Forum (FNWF), Nov 2023, pp. 1–7
work page 2023
-
[26]
A goal-directed trajectory planning using active inference in uav-assisted wireless networks,
A. Krayani, K. Khan, L. Marcenaro, M. Marchese, and C. Regazzoni, “A goal-directed trajectory planning using active inference in uav-assisted wireless networks,”Sensors, vol. 23, no. 15, 2023. [Online]. Available: https://www.mdpi. com/1424-8220/23/15/6873 Kaleem Arshid(Member, IEEE) currently a Ph.D student in a joint doctoral program at Department of El...
work page 2023
-
[27]
He is currently a Professor at the Carlos III University of Madrid. In 2014, he was awarded with the VII Barreiros Foundation Award to the best research in the automotive field. In 2015, the IEEE Society has awarded him as the Best Reviewer of the 18th IEEE International Conference on Intelligent Transportation Systems. Carlo Regazzoni(Senior Member, IEEE...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.