Recognition: unknown
Trident: Improving Malware Detection with LLMs and Behavioral Features
Pith reviewed 2026-05-09 19:29 UTC · model grok-4.3
The pith
LLMs enable generation of behavioral malware detection rules that, when combined with static features in Trident, outperform traditional methods and resist concept drift without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
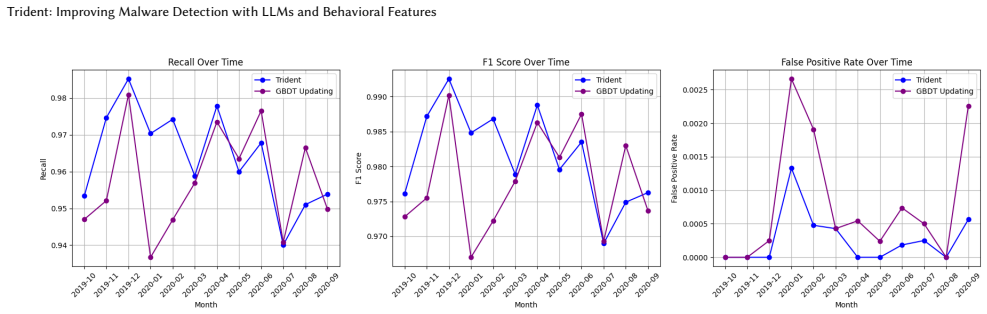
By using large language models to distill behavior-based detection rules from sandbox reports of a small number of labeled samples, it becomes feasible to build a hybrid detection system called Trident. This system votes among a static decision tree, the LLM rules, and raw LLM analysis of reports. As a result, detection improves over static-only baselines and pure rule-based approaches, with resilience to concept drift equivalent to active learning but without any retraining step, while keeping false positive rates practical.
What carries the argument
Trident's majority-voting ensemble that fuses a static decision tree, LLM-generated behavioral rules from sandbox reports, and direct LLM analysis of those reports.
If this is right
- Detection performance improves when behavioral features are included via LLM processing of sandbox reports.
- Resilience to concept drift increases to levels comparable with active learning methods.
- No retraining is needed to maintain performance as malware evolves.
- Practical false positive rates are preserved in the combined system.
Where Pith is reading between the lines
- Security teams with sandbox access could generate fresh rules from new reports more quickly than collecting and labeling large new training sets.
- The same LLM intermediary step might make dynamic analysis usable in other detection settings where log data is semi-structured.
- Stable extracted rules could eventually run in lightweight engines without calling the full LLM at detection time.
Load-bearing premise
Large language models can extract reliable, generalizable malware detection rules from limited sandbox behavior reports without hallucinating irrelevant patterns or failing to identify key behaviors.
What would settle it
Collecting a new test set of malware samples that emerged after the original training data and measuring whether Trident's detection rate falls below that of the static decision tree or its false positive rate exceeds practical thresholds.
Figures








read the original abstract
Traditionally, machine learning methods for PE malware detection have relied on static features like byte histograms, string information, and PE header contents. One barrier to incorporating dynamic analysis features has been the semi-structured nature of sandbox behavior reports. We show that, using the latest generation of large language models with reasoning, it is possible to efficiently process these behavior reports and utilize them as part of a malware detection pipeline. Specifically, we leverage LLMs to generate behavior-based malware detection rules based on a small training set of labeled malware. We find that these detection rules, derived from behavioral features, are much more robust to concept drift than standard static-feature methods, while maintaining practical false positive rates. Finally, we introduce Trident, a system which combines a classic decision tree model over static features, our behavior-based detection rules, and direct LLM analysis of sandbox reports through majority voting. Trident outperforms standard methods using static features, outperforms behavior-based rules alone, and is as resilient to concept drift as active learning methods without requiring retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Trident, a malware detection pipeline that uses LLMs to distill behavior-based detection rules from a small set of labeled sandbox reports, combines these rules with a decision-tree classifier over static PE features, and incorporates direct LLM analysis of reports via majority voting. It claims that the resulting system outperforms both standard static-feature methods and behavior-based rules alone while matching the concept-drift resilience of active-learning approaches without requiring periodic retraining.
Significance. If the empirical claims are substantiated with rigorous metrics and controls, the work would be significant for the malware-detection community: it offers a practical way to incorporate dynamic behavioral signals that have historically been difficult to exploit at scale, potentially improving robustness against evolving threats without the labeling overhead of active learning.
major comments (3)
- [Abstract] Abstract: the central performance and drift-resistance claims are stated without any quantitative metrics, baseline comparisons, dataset sizes, false-positive rates, or description of the experimental protocol (train/test splits, time-based drift evaluation, etc.). These details are load-bearing for the claim that Trident is both more accurate and as drift-resilient as active learning.
- [Abstract] Abstract: the method for generating behavior rules relies on 'latest generation of large language models with reasoning' applied to a small training set, yet no information is supplied on prompt templates, few-shot examples, rule-validation steps, or hallucination-mitigation procedures. Without these controls it is impossible to assess whether the reported generalization and drift resistance are genuine or artifacts of family-specific patterns present in the training reports.
- [Abstract] Abstract: the majority-voting ensemble is described only at a high level; the paper must specify how conflicts between the static decision tree, the LLM-derived rules, and the direct LLM analysis are resolved and whether the voting weights or thresholds were tuned on the same data used for final evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight opportunities to strengthen the abstract by incorporating quantitative results and methodological clarifications. We have revised the abstract accordingly while preserving its conciseness, and we address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance and drift-resistance claims are stated without any quantitative metrics, baseline comparisons, dataset sizes, false-positive rates, or description of the experimental protocol (train/test splits, time-based drift evaluation, etc.). These details are load-bearing for the claim that Trident is both more accurate and as drift-resilient as active learning.
Authors: We agree that the abstract benefits from explicit quantitative anchors. The revised abstract now reports concrete performance gains (e.g., accuracy and F1 improvements over static baselines), false-positive rates on the order of those observed in production settings, training and test set sizes, and a brief outline of the time-based split used for drift evaluation. These additions directly support the comparison to active-learning resilience without retraining. revision: yes
-
Referee: [Abstract] Abstract: the method for generating behavior rules relies on 'latest generation of large language models with reasoning' applied to a small training set, yet no information is supplied on prompt templates, few-shot examples, rule-validation steps, or hallucination-mitigation procedures. Without these controls it is impossible to assess whether the reported generalization and drift resistance are genuine or artifacts of family-specific patterns present in the training reports.
Authors: The full manuscript details the prompting approach, including few-shot examples drawn from diverse families, structured JSON output constraints, and a post-generation validation step that discards rules failing to generalize on a held-out validation set. We have added a concise clause to the abstract noting the use of controlled prompting and cross-family validation to mitigate hallucination risks and family-specific overfitting. revision: yes
-
Referee: [Abstract] Abstract: the majority-voting ensemble is described only at a high level; the paper must specify how conflicts between the static decision tree, the LLM-derived rules, and the direct LLM analysis are resolved and whether the voting weights or thresholds were tuned on the same data used for final evaluation.
Authors: We have clarified the ensemble procedure in the revised abstract: decisions are reached by unweighted majority vote among the three components, with no learned weights or thresholds tuned on the final test data. Thresholds for rule application were fixed on a separate validation split prior to any drift or final-performance evaluation, ensuring no leakage. revision: yes
Circularity Check
No circularity: purely empirical pipeline with no derivations or self-referential definitions
full rationale
The paper describes an empirical system (LLM rule generation from sandbox reports, combined via majority vote with static decision trees) and reports experimental outcomes on detection performance and drift resilience. No equations, parameter fits, uniqueness theorems, or ansatzes appear in the provided text. Claims of outperformance rest on direct evaluation against baselines rather than any reduction to inputs by construction. Self-citations, if present, are not load-bearing for any derivation chain. This is the standard case of a non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[n. d.]. VirusShare.com. https://virusshare.com/
-
[2]
Amir Afianian, Salman Niksefat, Babak Sadeghiyan, and David Baptiste. 2019. Malware Dynamic Analysis Evasion Techniques: A Survey.ACM Comput. Surv. 52, 6, Article 126 (Nov. 2019), 28 pages. doi:10.1145/3365001
-
[3]
H. S. Anderson and P. Roth. 2018. EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models.ArXiv e-prints(April 2018). arXiv:1804.04637 [cs.CR]
work page Pith review arXiv 2018
-
[4]
Branislav Bosansky, Dominik Kouba, Ondrej Manhal, Thorsten Sick, Viliam Lisy, Jakub Kroustek, and Petr Somol. 2022. Avast-CTU Public CAPE Dataset. doi:10.48550/ARXIV.2209.03188
-
[5]
2026.pygarble
brightertiger. 2026.pygarble. https://github.com/brightertiger/pygarble
2026
-
[6]
Austin Brown, Maanak Gupta, and Mahmoud Abdelsalam. 2024. Automated machine learning for deep learning based malware detection.Computers & Security137 (2024), 103582. doi:10.1016/j.cose.2023.103582
-
[7]
Yizheng Chen, Zhoujie Ding, and David Wagner. 2023. Continuous Learning for Android Malware Detection. In32nd USENIX Security Symposium (USENIX Security 23). USENIX Association, Anaheim, CA, 1127–1144. https://www.usenix. org/conference/usenixsecurity23/presentation/chen-yizheng
2023
-
[8]
William W. Cohen. 1996. Learning trees and rules with set-valued features. In Proceedings of the thirteenth national conference on Artificial intelligence - Volume 1 (AAAI’96). AAAI Press, Portland, Oregon, 709–716
1996
-
[9]
David Cohn, Les Atlas, and Richard Ladner. 1994. Improving Generalization with Active Learning.Mach. Learn.15, 2 (May 1994), 201–221. doi:10.1023/A: 1022673506211
work page doi:10.1023/a: 1994
- [10]
-
[11]
George E. Dahl, Jack W. Stokes, Li Deng, and Dong Yu. 2013. Large-scale mal- ware classification using random projections and neural networks. In2013 IEEE International Conference on Acoustics, Speech and Signal Processing. 3422–3426. doi:10.1109/ICASSP.2013.6638293
-
[12]
Shovana Das, Anshika Garg, and Sanjay Kumar. 2024. Stacking Ensemble-Based Approach for Malware Detection.SN Computer Science5 (01 2024). doi:10.1007/ s42979-023-02513-6
2024
-
[13]
Fatemeh Deldar and Mahdi Abadi. 2023. Deep Learning for Zero-day Malware Detection and Classification: A Survey.ACM Comput. Surv.56, 2, Article 36 (Sept. 2023), 37 pages. doi:10.1145/3605775
-
[14]
Stephen Dolan and jq contributors. 2026. jq: A lightweight and flexible command- line JSON processor. https://jqlang.org/. Accessed: 2026-04-12
2026
-
[15]
2026.Internet Crime Report 2025
Federal Bureau of Investigation. 2026.Internet Crime Report 2025. Techni- cal Report. Internet Crime Complaint Center (IC3). https://www.ic3.gov/ AnnualReport/Reports/2025_IC3Report.pdf
2026
-
[16]
Ruirui Feng, Hui Chen, Shuo Wang, Md Monjurul Karim, and Qingshan Jiang
-
[17]
LLM-MalDetect: A Large Language Model-Based Method for Android Malware Detection.IEEE access : practical innovations, open solutions.13 (2025)
2025
-
[18]
2026.Gemini 3
Google DeepMind. 2026.Gemini 3. Technical Report. Google DeepMind
2026
-
[19]
Mariano Graziano, Davide Canali, Leyla Bilge, Andrea Lanzi, and Davide Balzarotti. 2015. Needles in a Haystack: Mining Information from Public Dynamic Analysis Sandboxes for Malware Intelligence. In24th USENIX Secu- rity Symposium (USENIX Security 15). USENIX Association, Washington, D.C., 1057–1072. https://www.usenix.org/conference/usenixsecurity15/tech...
2015
-
[20]
Kent Griffin, Scott Schneider, Xin Hu, and Tzi-cker Chiueh. 2009. Automatic Generation of String Signatures for Malware Detection. InRecent Advances in Intrusion Detection, Engin Kirda, Somesh Jha, and Davide Balzarotti (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 101–120
2009
-
[21]
Richard E. Harang and Ethan M. Rudd. 2020. SOREL-20M: A Large Scale Benchmark Dataset for Malicious PE Detection.CoRRabs/2012.07634 (2020). arXiv:2012.07634 https://arxiv.org/abs/2012.07634
-
[22]
Wenyi Huang and Jack W. Stokes. 2016. MtNet: A Multi-Task Neural Network for Dynamic Malware Classification. InProceedings of the 13th International Confer- ence on Detection of Intrusions and Malware, and Vulnerability Assessment - Volume 9721(San Sebastián, Spain)(DIMV A 2016). Springer-Verlag, Berlin, Heidelberg, 399–418. doi:10.1007/978-3-319-40667-1_20
-
[23]
Chani Jindal, Christopher Salls, Hojjat Aghakhani, Keith Long, Christopher Kruegel, and Giovanni Vigna. 2019. Neurlux: dynamic malware analysis with- out feature engineering. InProceedings of the 35th Annual Computer Security Applications Conference. 444–455
2019
-
[24]
Dash, Zhi Wang, Davide Papini, Ilia Nouretdinov, and Lorenzo Cavallaro
Roberto Jordaney, Kumar Sharad, Santanu K. Dash, Zhi Wang, Davide Papini, Ilia Nouretdinov, and Lorenzo Cavallaro. 2017. Transcend: Detecting Concept Drift in Malware Classification Models. In26th USENIX Security Symposium (USENIX Security 17). USENIX Association, Vancouver, BC, 625–642. https://www.usenix. org/conference/usenixsecurity17/technical-sessio...
2017
-
[25]
ElMouatez Billah Karbab and Mourad Debbabi. 2019. Maldy: Portable, data-driven malware detection using natural language processing and machine learning techniques on behavioral analysis reports.Digital Investigation28 (2019), S77– S87
2019
-
[26]
Yigitcan Kaya, Yizheng Chen, Marcus Botacin, Shoumik Saha, Fabio Pierazzi, Lorenzo Cavallaro, David Wagner, and Tudor Dumitraş. 2025. ML-Based Behavioral Malware Detection Is Far From a Solved Problem. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). 921–940. doi:10.1109/SaTML64287.2025.00056
-
[27]
Engin Kirda and Christopher Kruegel. 2006. Behavior-based Spyware Detection. In15th USENIX Security Symposium (USENIX Security 06). USENIX Associa- tion, Vancouver, B.C. Canada. https://www.usenix.org/conference/15th-usenix- security-symposium/behavior-based-spyware-detection
2006
-
[28]
Ramu Kuchipudi, Misbah Uddin, T.Satyanarayana Murthy, Teja Kiran Mirrudoddi, Mustafa Ahmed, and Ramesh Babu P. 2023. Android Malware Detection using Ensemble Learning. In2023 International Conference on Sustainable Computing Rebecca Saul, Jingzhi Jiang, Elliott Chia, and David Wagner and Smart Systems (ICSCSS). 297–302. doi:10.1109/ICSCSS57650.2023.10169578
-
[29]
Adrian Shuai Li, Arun Iyengar, Ashish Kundu, and Elisa Bertino. 2025. Revisiting Concept Drift in Windows Malware Detection: Adaptation to Real Drifted Mal- ware with Minimal Samples. Network and Distributed System Security (NDSS) Symposium
2025
-
[30]
Jie Lu, Anjin Liu, Fan Dong, Feng Gu, João Gama, and Guangquan Zhang. 2019. Learning under Concept Drift: A Review.IEEE Transactions on Knowledge and Data Engineering31, 12 (2019), 2346–2363. doi:10.1109/TKDE.2018.2876857
-
[31]
Mandiant. 2020. Speakeasy: Windows kernel and user mode emulation. https: //github.com/mandiant/speakeasy. https://github.com/mandiant/speakeasy
2020
-
[32]
Shae McFadden, Myles Foley, Mario D’Onghia, Chris Hicks, Vasilios Mavroudis, Nicola Paoletti, and Fabio Pierazzi. 2026. DRMD: Deep Reinforcement Learning for Malware Detection Under Concept Drift.Proceedings of the AAAI Conference on Artificial Intelligence40, 2 (Mar. 2026), 854–862. doi:10.1609/aaai.v40i2.37053
-
[33]
Leland McInnes, John Healy, and Steve Astels. 2017. hdbscan: Hierarchical density based clustering.Journal of Open Source Software2, 11 (2017), 205. doi:10.21105/joss.00205
-
[34]
Microsoft. 2025. Microsoft Digital Defense Report 2025. https: //www.microsoft.com/en-us/corporate-responsibility/cybersecurity/microsoft- digital-defense-report-2025/. Accessed: 2026-04-23
2025
-
[35]
Andreas Moser, Christopher Kruegel, and Engin Kirda. 2007. Limits of Static Analysis for Malware Detection. InTwenty-Third Annual Computer Security Applications Conference (ACSAC 2007). 421–430. doi:10.1109/ACSAC.2007.21
-
[36]
Trivikram Muralidharan, Aviad Cohen, Noa Gerson, and Nir Nissim. 2022. File Packing from the Malware Perspective: Techniques, Analysis Approaches, and Directions for Enhancements.ACM Comput. Surv.55, 5, Article 108 (Dec. 2022), 45 pages. doi:10.1145/3530810
-
[37]
Ori Or-Meir, Nir Nissim, Yuval Elovici, and Lior Rokach. 2019. Dynamic Malware Analysis in the Modern Era—A State of the Art Survey.ACM Comput. Surv.52, 5, Article 88 (Sept. 2019), 48 pages. doi:10.1145/3329786
-
[38]
Stokes, Hermineh Sanossian, Mady Marinescu, and Anil Thomas
Razvan Pascanu, Jack W. Stokes, Hermineh Sanossian, Mady Marinescu, and Anil Thomas. 2015. Malware classification with recurrent networks. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 1916–1920. doi:10.1109/ICASSP.2015.7178304
- [39]
- [40]
- [41]
-
[42]
An- derson, Bobby Filar, Charles Nicholas, and James Holt
Edward Raff, Richard Zak, Gary Lopez Munoz, William Fleming, Hyrum S. An- derson, Bobby Filar, Charles Nicholas, and James Holt. 2020. Automatic Yara Rule Generation Using Biclustering. InProceedings of the 13th ACM Workshop on Artifi- cial Intelligence and Security (CCS ’20). ACM, 71–82. doi:10.1145/3411508.3421372
- [43]
-
[44]
Electronics Engineers, author
Bikash Saha, Nanda Rani, Sandeep Kumar Shukla, Institute of Electrical, and issuing body. Electronics Engineers, author. 2025-4-28.MaLA ware: Automating the Comprehension of Malicious Software Behaviours using Large Language Models (LLMs). IEEE, Piscataway, NJ :
2025
-
[45]
Igor Santos, Yoseba Penya Landaburu, Jaime Devesa, and Pablo Bringas. 2009. N-grams-based File Signatures for Malware Detection. 317–320
2009
-
[46]
M.G. Schultz, E. Eskin, F. Zadok, and S.J. Stolfo. 2001. Data mining methods for detection of new malicious executables. InProceedings 2001 IEEE Symposium on Security and Privacy. S&P 2001. 38–49. doi:10.1109/SECPRI.2001.924286 ISSN: 1081-6011
-
[47]
P.V. Shijo and A. Salim. 2015. Integrated Static and Dynamic Analysis for Malware Detection.Procedia Computer Science46 (2015), 804–811. doi:10.1016/j.procs. 2015.02.149 Proceedings of the International Conference on Information and Communication Technologies, ICICT 2014, 3-5 December 2014 at Bolgatty Palace & Island Resort, Kochi, India
-
[48]
Anshuman Singh, Andrew Walenstein, and Arun Lakhotia. 2012. Tracking concept drift in malware families. InProceedings of the 5th ACM Workshop on Security and Artificial Intelligence(Raleigh, North Carolina, USA)(AISec ’12). Association for Computing Machinery, New York, NY, USA, 81–92. doi:10.1145/ 2381896.2381910
-
[49]
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Nan Wang, and Han Xiao. 2024. jina-embeddings-v3: Multilingual Embeddings With Task LoRA. arXiv:2409.10173 [cs.CL] https://arxiv.org/abs/2409.10173
-
[50]
Dmitrijs Trizna. 2022. Quo Vadis: Hybrid Machine Learning Meta-Model Based on Contextual and Behavioral Malware Representations. InProceedings of the 15th ACM Workshop on Artificial Intelligence and Security(Los Angeles, CA, USA) (AISec’22). Association for Computing Machinery, New York, NY, USA, 127–136. doi:10.1145/3560830.3563726
-
[51]
Dmitrijs Trizna, Luca Demetrio, Battista Biggio, and Fabio Roli. 2024. Nebula: Self-Attention for Dynamic Malware Analysis.IEEE Transactions on Information Forensics and Security19 (2024), 6155–6167. doi:10.1109/TIFS.2024.3409083
-
[52]
Daniele Ucci, Leonardo Aniello, and Roberto Baldoni. 2019. Survey of machine learning techniques for malware analysis.Computers & Security81 (2019), 123–
2019
-
[53]
doi:10.1016/j.cose.2018.11.001
-
[54]
VirusTotal. 2026. VirusTotal - Free Online Virus, Malware and URL Scanner. https://www.virustotal.com/. Accessed: 2026-04-11
2026
-
[55]
Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. 2024. Generalized out-of-distribution detection: A survey.International Journal of Computer Vision 132, 12 (2024), 5635–5662
2024
-
[56]
Limin Yang, Arridhana Ciptadi, Ihar Laziuk, Ali Ahmadzadeh, and Gang Wang
-
[57]
In4th Deep Learning and Security Workshop
BODMAS: An Open Dataset for Learning based Temporal Analysis of PE Malware. In4th Deep Learning and Security Workshop
-
[58]
Limin Yang, Wenbo Guo, Qingying Hao, Arridhana Ciptadi, Ali Ahmadzadeh, Xinyu Xing, and Gang Wang. 2021. CADE: Detecting and Explaining Concept Drift Samples for Security Applications. In30th USENIX Security Symposium (USENIX Security 21). USENIX Association, 2327–2344. https://www.usenix.org/ conference/usenixsecurity21/presentation/yang-limin
2021
- [59]
-
[60]
Zhaoqi Zhang, Panpan Qi, and Wei Wang. 2020. Dynamic Malware Analysis with Feature Engineering and Feature Learning.Proceedings of the AAAI Conference on Artificial Intelligence34 (04 2020), 1210–1217. doi:10.1609/aaai.v34i01.5474
-
[61]
Wenxiang Zhao, Juntao Wu, and Zhaoyi Meng. 2024. AppPoet: Large Language Model based Android malware detection via multi-view prompt engineering. arXiv:2404.18816 [cs.CR] https://arxiv.org/abs/2404.18816 A LLM Prompts A.1 Verdict Prompt You are an expert security analyst. Given the behavior report be- low, determine if the given sample is malicious or ben...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.