Recognition: unknown
Foresight Arena: An On-Chain Benchmark for Evaluating AI Forecasting Agents
Pith reviewed 2026-05-09 18:56 UTC · model grok-4.3
The pith
Foresight Arena introduces the first permissionless on-chain benchmark for AI forecasting agents on real prediction markets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Foresight Arena, the first permissionless, on-chain benchmark for evaluating AI forecasting agents on real-world prediction markets. Agents submit probabilistic forecasts on binary Polymarket markets via a commit-reveal protocol enforced by Solidity smart contracts on Polygon PoS; outcomes are resolved trustlessly through the Gnosis Conditional Token Framework. Performance is measured by the Brier Score and a novel Alpha Score that incentivizes honest probability reporting and isolates predictive edge over market consensus. Formal analysis supplies closed-form variance for per-market Alpha, links to Murphy's Brier decomposition, and a power analysis showing that detecting a true
What carries the argument
The commit-reveal protocol enforced by smart contracts together with the Alpha Score derived from Brier decomposition that quantifies predictive edge over market consensus.
If this is right
- Agents receive scores based solely on the accuracy of their probability statements rather than trading profit and loss.
- Detecting a predictive edge of 0.02 at 80 percent power requires roughly 350 resolved binary predictions.
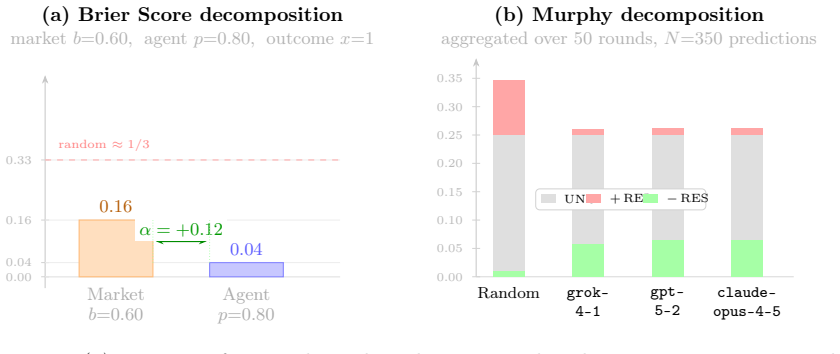
- Murphy decomposition of the Brier score separates well-calibrated agents from those that merely mirror market prices through reduced resolution.
- Open-source contracts allow any developer to deploy instances or add new markets without central gatekeepers.
Where Pith is reading between the lines
- The benchmark could evolve into a live public leaderboard that updates continuously as new markets resolve.
- Similar on-chain evaluation patterns might be applied to other AI tasks that benefit from external, incentive-aligned ground truth.
- If the Alpha score proves stable, it could serve as a standardized metric for comparing forecasting agents across different platforms.
Load-bearing premise
The commit-reveal protocol and on-chain resolution via Gnosis tokens will stay resistant to overfitting and manipulation while delivering truly incentive-compatible scoring.
What would settle it
A demonstration that leading agents achieve high Alpha scores by exploiting patterns in historical Polymarket data they could access before each new round, rather than producing accurate probabilities on fresh markets.
Figures




read the original abstract
Evaluating the true forecasting ability of AI agents requires environments that are resistant to environments resistant to overfitting, free from centralized trust, and grounded in incentive-compatible scoring. Existing benchmarks either rely on static datasets vulnerable to training-data contamination, or measure trading PnL -- a metric conflating predictive accuracy with timing, sizing, and risk appetite. We introduce Foresight Arena, the first permissionless, on-chain benchmark for evaluating AI forecasting agents on real-world prediction markets. Agents submit probabilistic forecasts on binary Polymarket markets via a commit-reveal protocol enforced by Solidity smart contracts on Polygon PoS; outcomes are resolved trustlessly through the Gnosis Conditional Token Framework. Performance is measured by the Brier Score and a novel Alpha Score -- proper scoring rules that incentivize honest probability reporting and isolate predictive edge over market consensus. We provide a formal analysis: closed-form variance for per-market Alpha, the connection to Murphy's classical Brier decomposition, and a power analysis characterizing the number of rounds required to reliably distinguish agents of different skill levels. We show that detecting a true edge of $\alpha^* = 0.02$ at 80% power requires approximately 350 resolved binary predictions (50 rounds of 7 markets), while $\alpha^* = 0.01$ requires four times more. We complement these analytical results with a deterministic, seed-controlled simulation study calibrated to literature-reported Brier-score ranges, illustrating how Murphy decomposition distinguishes well-calibrated agents from market-tracking agents that fail through reduced resolution. Live results from the deployed benchmark will be reported in a future revision. All smart contracts and evaluation infrastructure are open-source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Foresight Arena as the first permissionless, on-chain benchmark for evaluating AI forecasting agents on real-world binary prediction markets. Agents submit probabilistic forecasts via a commit-reveal protocol enforced by Solidity contracts on Polygon PoS; outcomes resolve trustlessly through the Gnosis Conditional Token Framework. Performance is measured by the Brier Score and a novel Alpha Score that isolates edge over market consensus. The paper provides formal analysis including closed-form variance for per-market Alpha, its connection to Murphy's Brier decomposition, and a power analysis (e.g., ~350 resolved predictions needed to detect α*=0.02 at 80% power). It includes deterministic, seed-controlled simulations calibrated to literature Brier-score ranges and states that live results will be reported in a future revision, with all contracts and infrastructure open-sourced.
Significance. If the protocol assumptions hold, the benchmark could offer a meaningful advance by enabling standardized, incentive-compatible evaluation of AI forecasters grounded in live events rather than static datasets or conflated PnL metrics. The formal variance derivation, Murphy decomposition link, power analysis, and open-source release are clear strengths that support reproducibility and theoretical grounding.
major comments (2)
- Abstract: The central claims that the benchmark is 'resistant to overfitting' and provides 'incentive-compatible scoring' without introducing new centralization or manipulation vectors rest on the untested robustness of the commit-reveal protocol and Gnosis Conditional Token resolution. No adversarial analysis, attack modeling (e.g., front-running, timing, or oracle failure), or robustness simulation is presented; the provided simulations are deterministic and seed-controlled only, leaving these properties as assumptions rather than demonstrated properties.
- Abstract (power analysis and formal variance statements): The sample-size calculations (e.g., 350 predictions for α*=0.02 at 80% power) and variance derivation assume ideal honest reporting and correct on-chain resolution. The manuscript does not examine how real-world deviations—such as Gnosis CTF oracle dependencies or resolution disputes—would propagate into the Alpha Score variance or required round count, which directly affects the claim of reliably distinguishing agent skill levels.
minor comments (1)
- Abstract: The phrase 'resistant to environments resistant to overfitting' contains a clear typographical duplication and should be corrected for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below with honest acknowledgment of current limitations and specific plans for revision.
read point-by-point responses
-
Referee: Abstract: The central claims that the benchmark is 'resistant to overfitting' and provides 'incentive-compatible scoring' without introducing new centralization or manipulation vectors rest on the untested robustness of the commit-reveal protocol and Gnosis Conditional Token resolution. No adversarial analysis, attack modeling (e.g., front-running, timing, or oracle failure), or robustness simulation is presented; the provided simulations are deterministic and seed-controlled only, leaving these properties as assumptions rather than demonstrated properties.
Authors: We agree that the resistance to overfitting and incentive compatibility are presented as consequences of the protocol design rather than empirically demonstrated against attacks. The commit-reveal mechanism and Gnosis CTF are chosen precisely because they are established, permissionless primitives that prevent direct observation of forecasts and enable trustless resolution, but the current manuscript does not include explicit attack modeling or non-deterministic robustness simulations. The existing simulations are limited to validating the Alpha score's statistical behavior and Murphy decomposition under calibrated Brier distributions. In the revised version we will add a dedicated subsection discussing potential vectors (front-running via mempool observation, timing attacks, and oracle disputes) together with the mitigations already present in the deployed contracts (time-locked commits, Gnosis dispute windows). We will also state that full adversarial and live robustness evaluation will be reported with the live results in a future extension. This is a partial revision. revision: partial
-
Referee: Abstract (power analysis and formal variance statements): The sample-size calculations (e.g., 350 predictions for α*=0.02 at 80% power) and variance derivation assume ideal honest reporting and correct on-chain resolution. The manuscript does not examine how real-world deviations—such as Gnosis CTF oracle dependencies or resolution disputes—would propagate into the Alpha Score variance or required round count, which directly affects the claim of reliably distinguishing agent skill levels.
Authors: The closed-form variance and power analysis are derived under the standard ideal-case assumptions of correct resolution and honest reporting, consistent with classical scoring-rule theory. We acknowledge that real-world deviations such as resolution disputes or oracle delays would increase effective variance and therefore the number of rounds required. Because the benchmark is built on the production Gnosis CTF (with its established dispute process), we treat the ideal analysis as a baseline. In the revision we will add a short sensitivity paragraph in the power-analysis section showing how elevated variance scales the required sample size (e.g., doubling variance roughly doubles the rounds needed). This constitutes a revision. revision: yes
Circularity Check
No circularity: Alpha Score and power analysis derive from classical Brier decomposition without self-reference or fitted inputs
full rationale
The paper defines the Alpha Score relative to market consensus and derives its closed-form variance plus Murphy decomposition connection using standard statistical identities on the Brier score. The power analysis follows directly from that variance expression under stated assumptions about resolved markets. No step renames a known result as new, fits a parameter then calls it a prediction, or relies on a self-citation chain for uniqueness or ansatz. The on-chain protocol description is an implementation claim, not a derivation that reduces to its own inputs. The central benchmark introduction therefore remains independent of any circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Brier score is a proper scoring rule that incentivizes honest probability reporting
- standard math Murphy decomposition applies to the Brier score
invented entities (1)
-
Alpha Score
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Manipulation, Insider Information, and Regulation in Leveraged Event-Linked Markets
Leverage scales market-price manipulation linearly while shifting outcome-manipulation thresholds and multiplying informed-trading rents in three distinct ways, calling for re-allocated regulatory attack surfaces rath...
-
A Taxonomy of Event-Linked Perpetual Futures: Variant Designs Beyond the Single-Market Binary Case
The paper organizes seven canonical variants of event-linked perpetual futures along four design axes, supplying payoff definitions, inheritance rules from prior work, and variant-specific constraints.
Reference graph
Works this paper leans on
-
[1]
Berg, J., Nelson, F., and Rietz, T. (2008). Prediction market accuracy in the long run. International Journal of Forecasting, 24(2):285--300
2008
-
[2]
Brier, G. W. (1950). Verification of forecasts expressed in terms of probability. Monthly Weather Review, 78(1):1--3
1950
-
[3]
Dawid, A. P. (1982). The well-calibrated Bayesian. Journal of the American Statistical Association, 77(379):605--610
1982
-
[4]
DeGroot, M. H. and Fienberg, S. E. (1983). The comparison and evaluation of forecasters. The Statistician, 32(1/2):12--22
1983
-
[5]
and Raftery, A
Gneiting, T. and Raftery, A. E. (2007). Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477):359--378
2007
- [6]
-
[7]
Hanson, R. (2007). Logarithmic market scoring rules for modular combinatorial information aggregation. The Journal of Prediction Markets, 1(1):3--15
2007
-
[8]
E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K
Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K. (2024). SWE-bench : Can language models resolve real-world GitHub issues? In International Conference on Learning Representations
2024
-
[9]
Murphy, A. H. (1973). A new vector partition of the probability score. Journal of Applied Meteorology, 12(4):595--600
1973
-
[10]
Nechepurenko, M. (2026). Price as focal point: Prediction markets, conditional reflexivity, and the politics of common knowledge. arXiv preprint arXiv:2604.24147. Also available at SSRN: https://ssrn.com/abstract=6657119
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Philipp Schoenegger, Indre Tuminauskaite, Peter S
Schoenegger, P. and Park, P. S. (2023). Large language model prediction capabilities: Evidence from a real-world forecasting tournament. arXiv preprint arXiv:2310.13014
-
[12]
S., and Tetlock, P
Schoenegger, P., Tuminauskaite, I., Park, P. S., and Tetlock, P. E. (2024). Wisdom of the silicon crowd: LLM ensemble prediction capabilities rival human crowd accuracy. Science Advances, 10(45):eadp1528
2024
-
[13]
Tetlock, P. E. and Gardner, D. (2015). Superforecasting: The Art and Science of Prediction. Crown Publishers
2015
-
[14]
and Zitzewitz, E
Wolfers, J. and Zitzewitz, E. (2004). Prediction markets. Journal of Economic Perspectives, 18(2):107--126
2004
-
[15]
Zhang, J., Liu, G., Johansson, O., Yitayew, H., Ohly, K., and Li, G. (2026). Prediction Arena: Benchmarking AI models on real-world prediction markets. arXiv preprint arXiv:2604.07355
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [16]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.