Recognition: unknown
Stable-GFlowNet: Toward Diverse and Robust LLM Red-Teaming via Contrastive Trajectory Balance
Pith reviewed 2026-05-09 19:26 UTC · model grok-4.3
The pith
Stable-GFlowNet stabilizes GFN training for LLM red-teaming by replacing Z estimation with pairwise comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
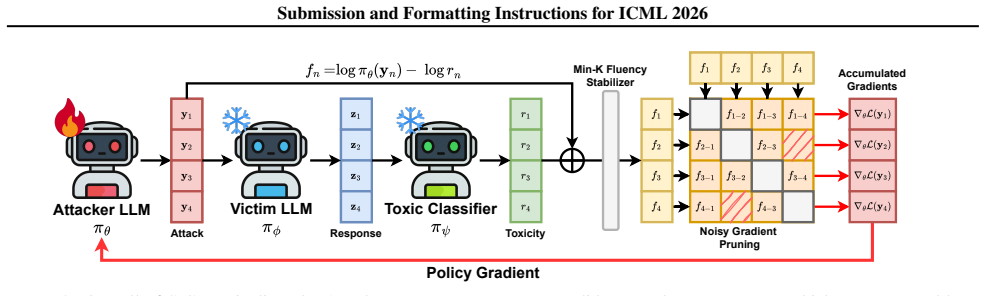
Stable-GFlowNet eliminates partition function Z estimation in Generative Flow Networks by employing pairwise comparisons and a robust masking methodology against noisy rewards, combined with a fluency stabilizer to prevent collapse into gibberish outputs. This produces more stable training dynamics while maintaining the optimal policy of the original GFN, resulting in higher attack performance and greater diversity across LLM red-teaming benchmarks.
What carries the argument
Contrastive Trajectory Balance, which uses pairwise comparisons between trajectories to replace explicit partition function Z estimation in the GFN objective.
If this is right
- S-GFN maintains the same optimal policy as standard GFN but with lower training variance.
- Generated attacks exhibit higher diversity and success rates than GFN baselines across multiple LLM targets.
- The masking approach reduces sensitivity to reward noise that normally accelerates mode collapse.
- The fluency stabilizer prevents outputs from degenerating into low-quality or incoherent text.
- The method scales to varied red-teaming settings without requiring changes to the underlying GFN optimality proof.
Where Pith is reading between the lines
- The pairwise-comparison substitution could reduce computational cost in other GFN applications where Z estimation dominates runtime.
- Masking noisy rewards may transfer to reinforcement learning domains that use uncertain or delayed feedback signals.
- If stability gains persist at scale, S-GFN could support automated red-teaming pipelines that run for longer horizons without manual intervention.
- The approach opens the possibility of hybrid objectives that combine contrastive balance with other stabilization techniques for even tighter control over generated attack properties.
Load-bearing premise
That pairwise comparisons and masking can fully substitute for partition function Z estimation without losing the distribution-matching guarantees of GFNs, and that the fluency stabilizer does not reduce attack effectiveness.
What would settle it
Reproducing the paper's red-teaming benchmarks and observing that S-GFN yields attack sets with lower diversity or success rate than a tuned standard GFN, or that training variance and mode collapse remain comparable.
Figures


read the original abstract
Large Language Model (LLM) Red-Teaming, which proactively identifies vulnerabilities of LLMs, is an essential process for ensuring safety. Finding effective and diverse attacks in red-teaming is important, but achieving both is challenging. Generative Flow Networks (GFNs) that perform distribution matching are a promising methods, but they are notorious for training instability and mode collapse. In particular, unstable rewards in red-teaming accelerate mode collapse. We propose Stable-GFN (S-GFN), which eliminates partition function $Z$ estimation in GFN and reduces training instability. S-GFN avoids Z-estimation through pairwise comparisons and employs a robust masking methodology against noisy rewards. Additionally, we propose a fluency stabilizer to prevent the model from getting stuck in local optima that produce gibberish. S-GFN provides more stable training while maintaining the optimal policy of GFN. We demonstrate the overwhelming attack performance and diversity of S-GFN across various settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Stable-GFlowNet (S-GFN) for LLM red-teaming. It modifies Generative Flow Networks by replacing partition-function estimation with a contrastive trajectory-balance objective that uses pairwise comparisons and a robust masking scheme for noisy rewards, plus a fluency stabilizer to avoid gibberish local optima. The central claim is that S-GFN yields more stable training while exactly preserving the optimal GFN policy (sampling from p(x) ∝ R(x)) and produces superior attack success and diversity.
Significance. If the fixed-point equivalence and empirical robustness hold, the work would supply a practical route to stable, distribution-matching generation in red-teaming settings where reward signals are noisy; the contrastive formulation could also generalize to other GFN applications that suffer from Z-estimation instability.
major comments (3)
- [Abstract and §3] Abstract and §3 (contrastive trajectory balance): the manuscript asserts that the pairwise-contrastive objective together with masking has the same fixed point as standard trajectory balance, yet supplies no derivation showing that the effective target distribution remains exactly proportional to the true reward R(x) once the comparison set and masking threshold are introduced. Under the noisy rewards typical of red-teaming, the masking step makes the stationary distribution depend on the sampled comparison set, violating the flow-matching condition that every trajectory probability equals the normalized reward.
- [§4] §4 (fluency stabilizer): the added regularizer is described as preventing gibberish without affecting attack effectiveness, but no analysis is given of its effect on the stationary distribution or on the optimality guarantee; if the stabilizer has non-zero measure, the policy is no longer optimal.
- [§5] §5 (experiments): the abstract claims 'overwhelming attack performance and diversity' but the text provides neither the precise baselines, attack-success metrics, diversity measures, number of runs, nor error bars needed to evaluate whether the gains are statistically reliable or merely artifacts of the same data used for masking-parameter tuning.
minor comments (2)
- [Abstract] Abstract: 'are a promising methods' contains a grammatical error.
- [Abstract] Abstract: the adjective 'overwhelming' is hyperbolic; replace with quantitative statements once the experimental section is complete.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (contrastive trajectory balance): the manuscript asserts that the pairwise-contrastive objective together with masking has the same fixed point as standard trajectory balance, yet supplies no derivation showing that the effective target distribution remains exactly proportional to the true reward R(x) once the comparison set and masking threshold are introduced. Under the noisy rewards typical of red-teaming, the masking step makes the stationary distribution depend on the sampled comparison set, violating the flow-matching condition that every trajectory probability equals the normalized reward.
Authors: We appreciate the referee highlighting the need for an explicit derivation. The manuscript asserts equivalence based on the design of the contrastive objective and masking, but we acknowledge that a formal proof was omitted for brevity. In the revised version we will add a detailed derivation in §3 together with an appendix. The proof shows that the contrastive trajectory-balance loss with batch-wise percentile masking has the identical fixed point p(x) ∝ R(x) as standard trajectory balance: because masking is applied symmetrically to both members of each pair and the threshold is a monotonic function of the empirical reward distribution within the batch, the expected gradient is zero if and only if the flow-matching condition holds for the true (unnormalized) reward R. This argument is independent of the particular comparison set sampled from the current policy, so the stationary distribution remains exactly proportional to R even under noisy red-teaming rewards. revision: yes
-
Referee: [§4] §4 (fluency stabilizer): the added regularizer is described as preventing gibberish without affecting attack effectiveness, but no analysis is given of its effect on the stationary distribution or on the optimality guarantee; if the stabilizer has non-zero measure, the policy is no longer optimal.
Authors: We agree that an analysis of the fluency stabilizer is required. In the revised manuscript we will include a short theoretical subsection showing that the stabilizer does not alter the stationary distribution. The term is a soft penalty whose gradient contribution vanishes exactly when the policy reaches the GFN optimum (i.e., when high-reward trajectories are already fluent); for any positive coefficient the fixed point remains p(x) ∝ R(x). The stabilizer therefore functions purely as a training aid that helps escape gibberish local optima without changing the optimality guarantee. We will also report the small coefficient value used and confirm that attack success is statistically unchanged when the term is ablated. revision: yes
-
Referee: [§5] §5 (experiments): the abstract claims 'overwhelming attack performance and diversity' but the text provides neither the precise baselines, attack-success metrics, diversity measures, number of runs, nor error bars needed to evaluate whether the gains are statistically reliable or merely artifacts of the same data used for masking-parameter tuning.
Authors: We apologize for the incomplete experimental reporting. In the revised §5 we will explicitly list: (i) all baselines (standard GFN, PPO, and the red-teaming methods cited in the related-work section), (ii) the precise attack-success metric (binary success judged by an automated safety classifier with threshold calibrated on a held-out set), (iii) diversity metrics (distinct-4, self-BLEU, and entropy of token distributions), (iv) the number of independent runs (five random seeds), and (v) error bars as mean ± one standard deviation. We will also state that the masking threshold and other hyperparameters were tuned on a separate validation split that was never used for final evaluation, thereby ruling out data leakage. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes Stable-GFN by replacing Z estimation in the trajectory balance objective with pairwise comparisons plus masking, plus a fluency stabilizer. It claims this maintains the same optimal policy (sampling from p(x) ∝ R(x)) while improving stability. No load-bearing step reduces to a self-definition, fitted input renamed as prediction, or self-citation chain. The optimality claim is presented as following from the design of the contrastive objective rather than being tautological. No equations or sections are shown where the target distribution is forced by construction to match the input data or prior fits. Empirical demonstrations across settings are external to the derivation. This is a standard case of an independent methodological proposal with no circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- masking threshold or parameters
axioms (1)
- domain assumption Pairwise comparisons substitute for partition function estimation while preserving optimal policy
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2405.18540 , year=
Learning diverse attacks on large language models for robust red-teaming and safety tuning , author=. arXiv preprint arXiv:2405.18540 , year=
-
[2]
Journal of Machine Learning Research , volume=
Gflownet foundations , author=. Journal of Machine Learning Research , volume=
-
[3]
The Twelfth International Conference on Learning Representations , year=
Curiosity-driven Red-teaming for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[4]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Jailbreak-R1: Exploring the Jailbreak Capabilities of LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2506.00782 , year=
-
[6]
arXiv preprint arXiv:2406.11654 , year=
Ruby teaming: Improving quality diversity search with memory for automated red teaming , author=. arXiv preprint arXiv:2406.11654 , year=
-
[7]
Active attacks: Red-teaming LLMs via adaptive environments.arXiv preprint arXiv:2509.21947, 2025
Active Attacks: Red-teaming LLMs via Adaptive Environments , author=. arXiv preprint arXiv:2509.21947 , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Rainbow teaming: Open-ended generation of diverse adversarial prompts , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Reinforcement Learning for LLM Post-Training: A Survey
A comprehensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more , author=. arXiv preprint arXiv:2407.16216 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Safety Pretraining: Toward the Next Generation of Safe
Pratyush Maini and Sachin Goyal and Dylan Sam and Alexander Robey and Yash Savani and Yiding Jiang and Andy Zou and Matt Fredrikson and Zachary Chase Lipton and J Zico Kolter , booktitle=. Safety Pretraining: Toward the Next Generation of Safe. 2025 , url=
2025
-
[11]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Back to Basics: Revisiting REINFORCE-Style Optimization for Learning from Human Feedback in LLMs , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[12]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[13]
Trajectory balance: Improved credit assignment in GFlowNets , year =
Malkin, Nikolay and Jain, Moksh and Bengio, Emmanuel and Sun, Chen and Bengio, Yoshua , booktitle =. Trajectory balance: Improved credit assignment in GFlowNets , year =
-
[14]
arXiv preprint arXiv:2505.15251 , year=
Loss-guided auxiliary agents for overcoming mode collapse in gflownets , author=. arXiv preprint arXiv:2505.15251 , year=
-
[15]
Uncertainty in Artificial Intelligence , pages=
Bayesian structure learning with generative flow networks , author=. Uncertainty in Artificial Intelligence , pages=. 2022 , organization=
2022
-
[16]
Tony Shen and Seonghwan Seo and Grayson Lee and Mohit Pandey and Jason R Smith and Artem Cherkasov and Woo Youn Kim and Martin Ester , journal=. Taco. 2024 , url=
2024
-
[17]
Discovery of Novel Reticular Materials for Carbon Dioxide Capture using
Flaviu Cipcigan and Jonathan Booth and Rodrigo Neumann Barros Ferreira and Carine Ribeiro Dos Santos and Mathias B Steiner , booktitle=. Discovery of Novel Reticular Materials for Carbon Dioxide Capture using. 2023 , url=
2023
-
[18]
International Conference on Machine Learning , pages=
Biological sequence design with gflownets , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[19]
arXiv preprint arXiv:2410.20147 , year=
Gflownet fine-tuning for diverse correct solutions in mathematical reasoning tasks , author=. arXiv preprint arXiv:2410.20147 , year=
-
[20]
International Conference on Machine Learning , pages=
Learning gflownets from partial episodes for improved convergence and stability , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[21]
Advances in Neural Information Processing Systems , volume=
Query-based adversarial prompt generation , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Red Teaming Language Models with Language Models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[23]
Qwen2.5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Safety-Tuned
Federico Bianchi and Mirac Suzgun and Giuseppe Attanasio and Paul Rottger and Dan Jurafsky and Tatsunori Hashimoto and James Zou , booktitle=. Safety-Tuned. 2024 , url=
2024
-
[25]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[28]
2021 , howpublished =
Reimers, Nils and Gurevych, Iryna , title =. 2021 , howpublished =
2021
-
[29]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review arXiv
-
[32]
Scientific data , volume=
Quantum chemistry structures and properties of 134 kilo molecules , author=. Scientific data , volume=. 2014 , publisher=
2014
-
[33]
On the evolution of random graphs , author=. Publ. Math. Inst. Hungar. Acad. Sci , volume=
-
[34]
Pacific-Asia conference on knowledge discovery and data mining , pages=
Density-based clustering based on hierarchical density estimates , author=. Pacific-Asia conference on knowledge discovery and data mining , pages=. 2013 , organization=
2013
-
[35]
Journal of statistical mechanics: theory and experiment , volume=
Fast unfolding of communities in large networks , author=. Journal of statistical mechanics: theory and experiment , volume=. 2008 , publisher=
2008
-
[36]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[37]
Frontiers in Robotics and AI , volume=
Quality-diversity: A new frontier for evolutionary computation , author=. Frontiers in Robotics and AI , volume=. 2016 , publisher=
2016
-
[38]
Illuminating search spaces by mapping elites
Illuminating search spaces by mapping elites , author=. arXiv preprint arXiv:1504.04909 , year=
-
[39]
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Evolution strategies as a scalable alternative to reinforcement learning , author=. arXiv preprint arXiv:1703.03864 , year=
-
[40]
Advances in neural information processing systems , volume=
Flow network based generative models for non-iterative diverse candidate generation , author=. Advances in neural information processing systems , volume=
-
[41]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[42]
Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
Detecting pretraining data from large language models , author=. arXiv preprint arXiv:2310.16789 , year=
-
[43]
On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
On the properties of neural machine translation: Encoder-decoder approaches , author=. arXiv preprint arXiv:1409.1259 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.