Recognition: unknown
When LLMs Stop Following Steps: A Diagnostic Study of Procedural Execution in Language Models
Pith reviewed 2026-05-09 18:48 UTC · model grok-4.3
The pith
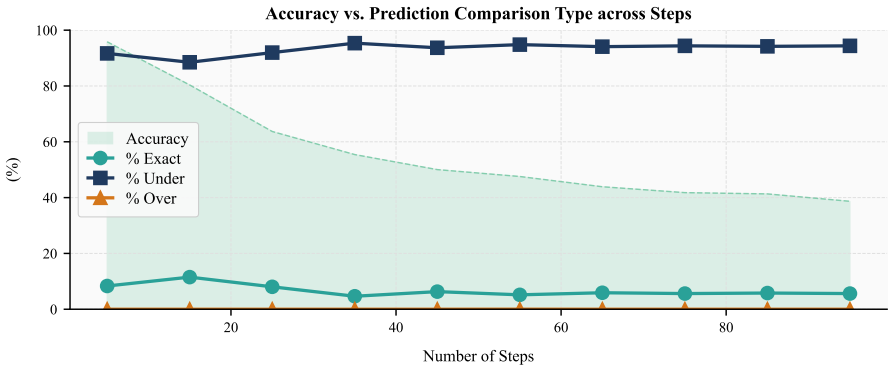
LLMs lose accuracy on following multi-step arithmetic procedures as length grows from 5 to 95 steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
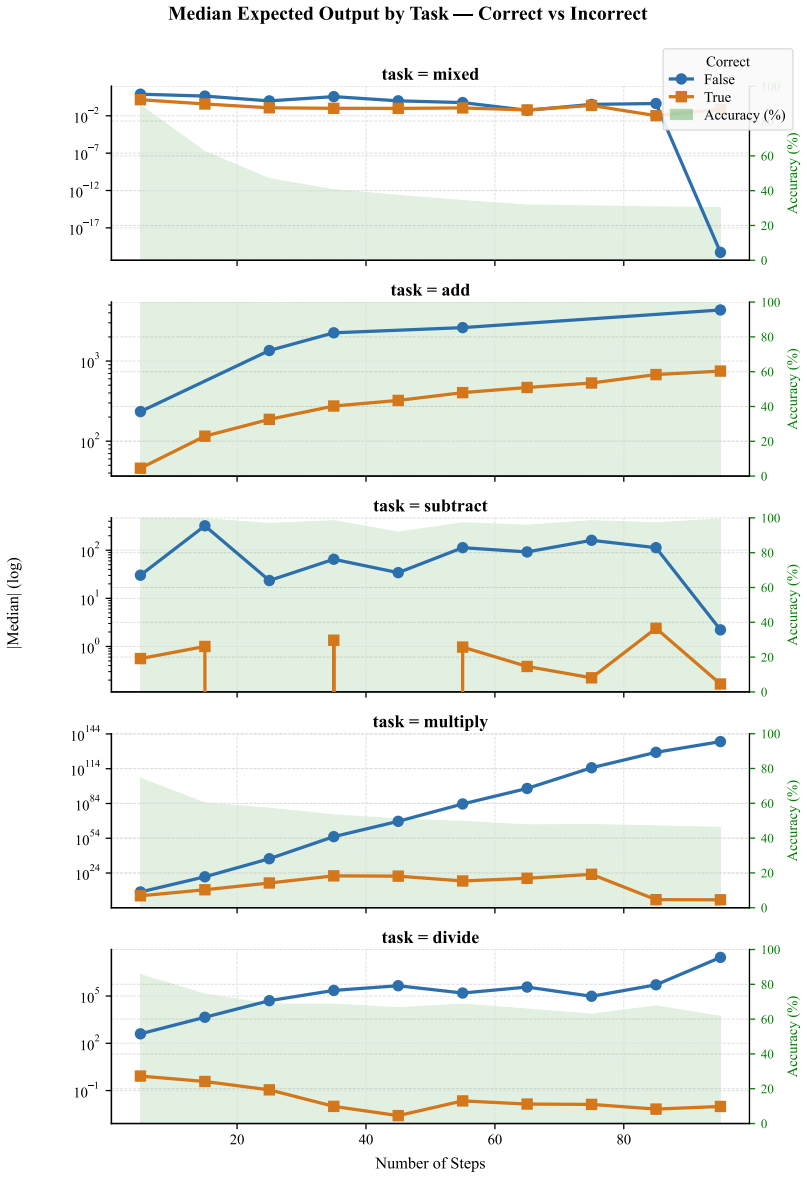
The central claim is that when models receive explicit step-wise arithmetic procedures, their first-answer accuracy averages 61 percent on 5-step versions but falls to 20 percent on 95-step versions across 14 models and 55 datasets. Generation analysis reveals recurring errors including missing final answers, premature termination, self-correction after mistakes, under-executed step traces, and hallucinated extra operations.
What carries the argument
A controlled diagnostic benchmark that supplies a step-wise arithmetic algorithm defined over intermediate variables together with two numeric inputs and requires the model to return only the final computed value.
If this is right
- Models that succeed on short procedures frequently fail on longer ones due to incomplete step execution.
- Apparent reasoning performance on benchmarks can hide substantial shortfalls in faithful instruction following.
- Common error types include early termination, under-execution of traces, and insertion of unprompted steps.
- Final-answer accuracy alone is insufficient to certify that a model has carried out the full procedure.
Where Pith is reading between the lines
- Training that rewards only final answers may discourage faithful step-by-step adherence.
- The same benchmark pattern could be applied to non-arithmetic domains such as code generation or logical deduction sequences.
- Adding explicit verification prompts at each step might reduce the observed accuracy gap on long procedures.
Load-bearing premise
The measured accuracy decline is produced by breakdowns in following the instructed procedure rather than by context-window limits, arithmetic skill gaps, or prompt formatting differences.
What would settle it
If models maintain high accuracy on the 95-step procedures once every intermediate result is explicitly requested and verified before the next step, the drop would be shown to stem from something other than procedural execution failure.
Figures





























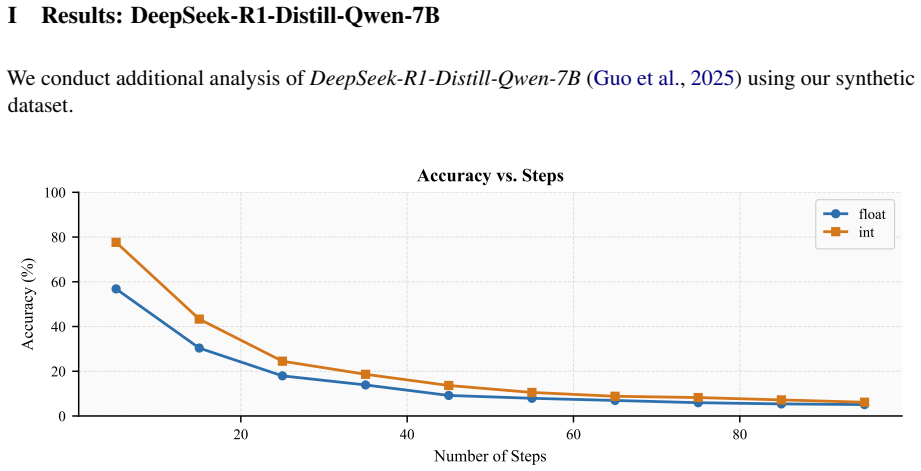













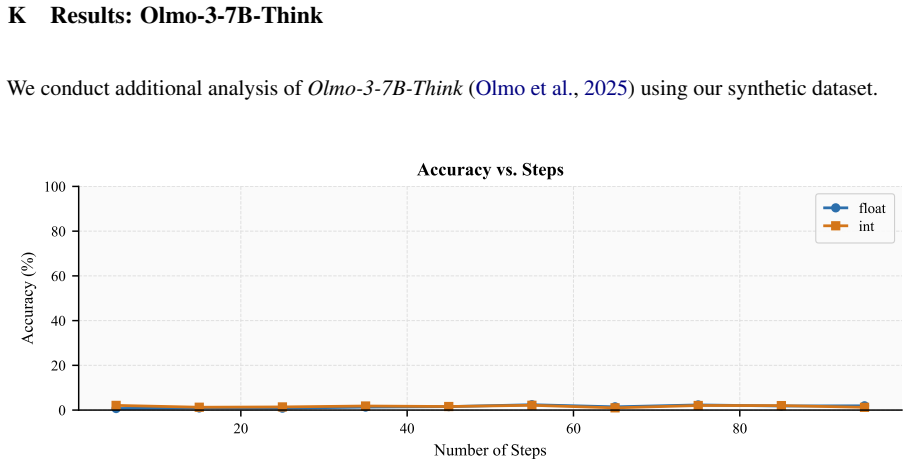
















































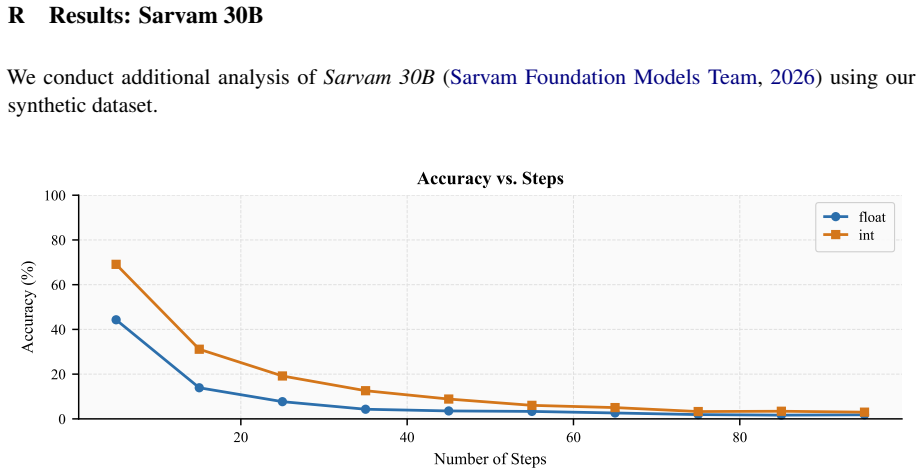







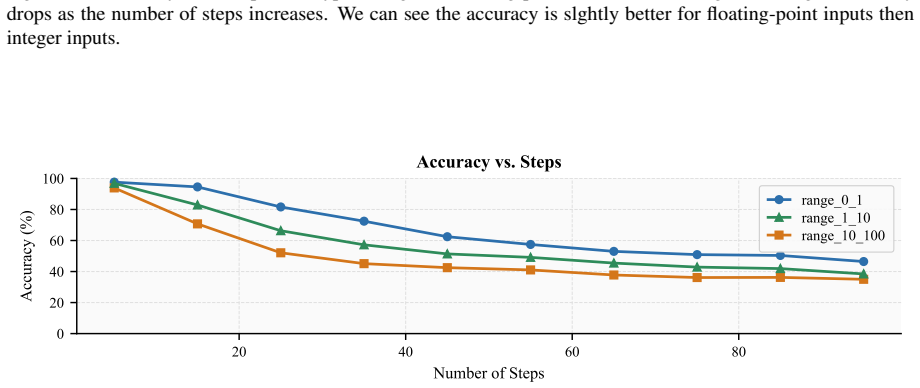










read the original abstract
Large language models (LLMs) often achieve strong performance on reasoning benchmarks, but final-answer accuracy alone does not show whether they faithfully execute the procedure specified in a prompt. We study this question through a controlled diagnostic benchmark for procedural execution, where models are given a step-wise arithmetic algorithm and two numeric inputs, and must return the final computed value. The benchmark uses simple arithmetic operations but increases complexity through algorithm length and look-back dependencies over intermediate variables. Across 14 models and 55 datasets, average first-answer accuracy drops from 61% on 5-step procedures to 20% on 95-step procedures. Generation-level analysis shows that failures often involve missing answers, premature answers, self-correction after an initial error, under-executed traces, and hallucinated extra steps. These findings suggest that apparent reasoning ability can mask substantial weaknesses in faithful instruction execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a diagnostic benchmark for procedural execution in LLMs consisting of step-wise arithmetic algorithms of increasing length (5 to 95 steps) with look-back dependencies over intermediate variables. Using two numeric inputs per procedure, it evaluates 14 models across 55 datasets and reports that first-answer accuracy falls from 61% (5 steps) to 20% (95 steps). Generation analysis identifies recurring failure modes including missing answers, premature answers, self-correction after initial errors, under-executed traces, and hallucinated extra steps, arguing that final-answer accuracy on reasoning tasks can conceal substantial deficits in faithful instruction following.
Significance. If the accuracy decline can be attributed specifically to breakdowns in step-by-step fidelity, the work supplies a scalable diagnostic that separates procedural execution from final-answer correctness. The evaluation scale (14 models, 55 datasets) and explicit failure taxonomy offer concrete, falsifiable observations that could guide improvements in instruction-following reliability.
major comments (1)
- [Abstract] Abstract: The central claim attributes the accuracy drop from 61% to 20% to failures of procedural fidelity (missing steps, premature termination, hallucinated operations). However, the description provides no evidence that prompt length, total token count, or arithmetic-operation count were held constant while varying only the number of steps and look-back dependencies. Without such controls, the observed trend is consistent with general context-length degradation or operation-count scaling and does not isolate the intended phenomenon.
minor comments (1)
- The abstract refers to '55 datasets' and 'simple arithmetic operations' but does not indicate whether the procedures are generated programmatically or manually curated; a brief methods paragraph clarifying construction would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our diagnostic study of procedural execution in LLMs. The primary concern is the lack of explicit controls for prompt length, token count, and operation count in the abstract. We address this point directly below and outline revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the accuracy drop from 61% to 20% to failures of procedural fidelity (missing steps, premature termination, hallucinated operations). However, the description provides no evidence that prompt length, total token count, or arithmetic-operation count were held constant while varying only the number of steps and look-back dependencies. Without such controls, the observed trend is consistent with general context-length degradation or operation-count scaling and does not isolate the intended phenomenon.
Authors: We agree that the abstract does not provide evidence of such controls. The benchmark design intentionally scales procedural complexity by increasing the number of steps (from 5 to 95) and introducing look-back dependencies on intermediate variables, which necessarily lengthens the prompt as each step adds fixed descriptive text and variable references. We did not hold total prompt length or token count constant across conditions (e.g., via padding or alternative constructions), nor did we isolate arithmetic-operation count independently of step count. The generation-level analysis, however, identifies failure modes—such as skipped steps, premature termination, and hallucinated operations—that are tied to the procedural structure and dependencies rather than generic length effects. To address the referee's valid point, we will revise the abstract to note the design trade-offs and add a dedicated paragraph in the Methods or Limitations section discussing potential confounds with context length and operation scaling, while retaining the core claim that the observed failure taxonomy suggests deficits in faithful instruction following beyond final-answer accuracy. revision: yes
Circularity Check
No circularity: purely empirical measurement study with direct accuracy reporting
full rationale
The paper constructs a diagnostic benchmark consisting of step-wise arithmetic procedures of increasing length and measures first-answer accuracy across models and datasets. All reported results (e.g., 61% to 20% accuracy drop) are direct empirical observations from model generations, not derived quantities, fitted parameters renamed as predictions, or quantities obtained via self-referential definitions. No equations, uniqueness theorems, ansatzes, or load-bearing self-citations appear in the core claims; the study contains no derivation chain that reduces to its inputs by construction. The central measurements are therefore self-contained and falsifiable by replication on the same benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[2]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Math neurosurgery: Isolating language models’ math reasoning abilities using only forward passes , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
arXiv preprint arXiv:1811.01157 , year=
Identifying and controlling important neurons in neural machine translation , author=. arXiv preprint arXiv:1811.01157 , year=
-
[4]
International Conference on Machine Learning , pages=
Task-specific skill localization in fine-tuned language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[5]
Back attention: Understanding and enhancing multi-hop reasoning in large language models
Back attention: Understanding and enhancing multi-hop reasoning in large language models , author=. arXiv preprint arXiv:2502.10835 , year=
-
[6]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small , author=. arXiv preprint arXiv:2211.00593 , year=
work page internal anchor Pith review arXiv
-
[7]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Rethinking the role of scale for in-context learning: An interpretability-based case study at 66 billion scale , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[8]
Advances in neural information processing systems , volume=
Are sixteen heads really better than one? , author=. Advances in neural information processing systems , volume=
-
[9]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Do not think that much for 2+ 3=? on the overthinking of o1-like llms , author=. arXiv preprint arXiv:2412.21187 , year=
work page internal anchor Pith review arXiv
-
[10]
IEEE transactions on emerging topics in computational intelligence , volume=
A survey on neural network interpretability , author=. IEEE transactions on emerging topics in computational intelligence , volume=. 2021 , publisher=
2021
-
[11]
arXiv preprint arXiv:2205.10487 , year=
Scaling laws and interpretability of learning from repeated data , author=. arXiv preprint arXiv:2205.10487 , year=
-
[12]
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
work page internal anchor Pith review arXiv
-
[13]
Transformer Circuits Thread , year=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , year=
-
[14]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review arXiv
-
[15]
2020 , month = Aug, note =
nostalgebraist , title =. 2020 , month = Aug, note =
2020
-
[16]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Analyzing transformers in embedding space , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
arXiv preprint arXiv:2305.13417 , year=
VISIT: Visualizing and interpreting the semantic information flow of transformers , author=. arXiv preprint arXiv:2305.13417 , year=
-
[18]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[19]
Emergent Abilities of Large Language Models
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
work page internal anchor Pith review arXiv
-
[20]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Large language models are better reasoners with self-verification , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[21]
arXiv preprint arXiv:2502.01839 , year=
Sample, scrutinize and scale: Effective inference-time search by scaling verification , author=. arXiv preprint arXiv:2502.01839 , year=
-
[22]
Teaching algorithmic reasoning via in-context learning , author=. arXiv preprint arXiv:2211.09066 , year=
-
[23]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity , author=. arXiv preprint arXiv:2506.06941 , year=
-
[26]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Stop overthinking: A survey on efficient reasoning for large language models , author=. arXiv preprint arXiv:2503.16419 , year=
work page internal anchor Pith review arXiv
-
[27]
Deepseek-r1 thoughtology: Let's think about llm reasoning
DeepSeek-R1 Thoughtology: Let's think about LLM Reasoning , author=. arXiv preprint arXiv:2504.07128 , year=
-
[28]
The Relationship Between Reasoning and Performance in Large Language Models--o3 (mini) Thinks Harder, Not Longer , author=. arXiv preprint arXiv:2502.15631 , year=
-
[29]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Principled Understanding of Generalization for Generative Transformer Models in Arithmetic Reasoning Tasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
Factual Shortcuts with Attribute Rate Ratio , author=
Unveiling Internal Reasoning Modes in LLMs: A Deep Dive into Latent Reasoning vs. Factual Shortcuts with Attribute Rate Ratio , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[31]
International Conference on Innovative Techniques and Applications of Artificial Intelligence , pages=
Rethinking the illusion of thinking , author=. International Conference on Innovative Techniques and Applications of Artificial Intelligence , pages=. 2025 , organization=
2025
-
[32]
Dissecting recall of factual associations in auto-regressive language models , author=. arXiv preprint arXiv:2304.14767 , year=
-
[33]
Advances in neural information processing systems , volume=
Investigating gender bias in language models using causal mediation analysis , author=. Advances in neural information processing systems , volume=
-
[34]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[35]
How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
How to use and interpret activation patching , author=. arXiv preprint arXiv:2404.15255 , year=
-
[36]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[37]
2025 , eprint=
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity , author=. 2025 , eprint=
2025
-
[38]
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
2024 , howpublished =
Mistral-7B-Instruct-v0.3 , author =. 2024 , howpublished =
2024
-
[41]
Ministral 3 , author=. arXiv preprint arXiv:2601.08584 , year=
work page internal anchor Pith review arXiv
-
[42]
Jiang, Andy Lo, Gabrielle Berrada, Guillaume Lample, et al
Magistral , author=. arXiv preprint arXiv:2506.10910 , year=
-
[43]
2026 , howpublished =
Introducing Sarvam's Sovereign Models , author =. 2026 , howpublished =
2026
-
[44]
Nvidia nemotron 3: Efficient and open intelligence, 2025
NVIDIA Nemotron 3: Efficient and Open Intelligence , author=. arXiv preprint arXiv:2512.20856 , year=
-
[45]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review arXiv
-
[46]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=
-
[47]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review arXiv
-
[48]
OpenThoughts: Data Recipes for Reasoning Models
Openthoughts: Data recipes for reasoning models , author=. arXiv preprint arXiv:2506.04178 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.