Recognition: 2 theorem links
· Lean TheoremLiteVLA-H: Dual-Rate Vision-Language-Action Inference for Onboard Aerial Guidance and Semantic Perception
Pith reviewed 2026-05-12 02:38 UTC · model grok-4.3
The pith
A compact drone VLA model separates fast guidance actions from slower semantic descriptions by showing that input processing dominates latency on edge hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
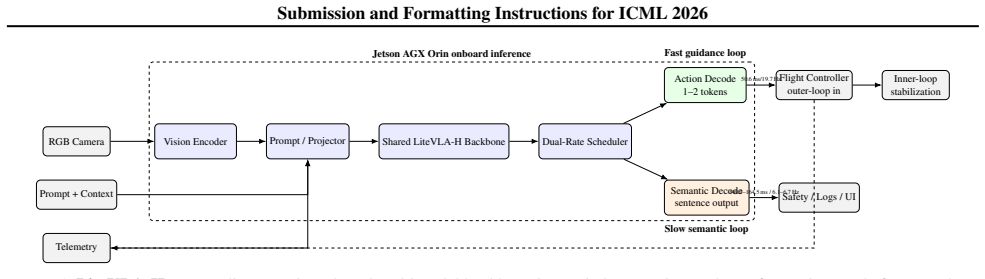
LiteVLA-H is a compact VLA system designed for dual-rate operation on an NVIDIA Jetson AGX Orin: a fast outer-loop guidance mode for short action-token outputs and a slower semantic mode for scene understanding, hazard description, and operator-facing narration. The central empirical observation is that, in this compact edge regime, end-to-end latency is dominated by multimodal pre-fill rather than by the marginal cost of decoding a few extra tokens. This motivates a scheduler that issues reactive action tokens at 50.65 ms (19.74 Hz) while still supporting sentence-level semantic outputs at 149.90--164.57 ms (6.08--6.67 Hz) on the same embedded platform. To specialize the model without loss,
What carries the argument
The dual-rate scheduler that issues short action-token outputs at high frequency while inserting occasional full-sentence semantic outputs, made possible by the dominance of multimodal pre-fill latency over token decoding cost.
If this is right
- The action branch reaches a higher edge inference rate than recent architectures including AnywhereVLA, FutureVLA, and ReMem-VLA under the reported deployment conditions.
- Periodic semantic awareness is retained alongside reactive control without requiring separate models or hardware.
- The system supports closed-loop aerial guidance under strict onboard compute and communication limits.
- Knowledge-preserving specialization allows the model to handle both short-term flight actions and longer-term scene narration from the same weights.
Where Pith is reading between the lines
- The pre-fill dominance finding suggests similar schedulers could improve efficiency in other compact multimodal systems on embedded hardware.
- The dual-rate approach may generalize to ground robots or manipulators that need both immediate control and explanatory outputs.
- Future tests could check whether the latency pattern persists when model size or input resolution increases.
Load-bearing premise
The mixed fine-tuning recipe of reactive flight data, aerial semantic data, and generic caption/VQA supervision keeps both guidance competence and descriptive ability intact.
What would settle it
A direct measurement on the same platform showing that generating a full semantic sentence adds latency far beyond the pre-fill time, or an evaluation showing that the fine-tuned model no longer produces accurate aerial scene descriptions.
Figures
read the original abstract
Vision-language-action (VLA) models have shown strong semantic grounding and task generalization in manipulation, but aerial deployment remains difficult because drones require low-latency closed-loop guidance under strict onboard compute and communication constraints. We present LiteVLA-H, a compact 256M-parameter VLA system designed for dual-rate operation on an NVIDIA Jetson AGX Orin: a fast outer-loop guidance mode for short action-token outputs and a slower semantic mode for scene understanding, hazard description, and operator-facing narration. The central empirical observation is that, in this compact edge regime, end-to-end latency is dominated by multimodal pre-fill rather than by the marginal cost of decoding a few extra tokens. This motivates a scheduler that issues reactive action tokens at 50.65,ms (19.74,Hz) while still supporting sentence-level semantic outputs at 149.90--164.57\ms (6.08--6.67,Hz) on the same embedded platform. To specialize the model without collapsing its descriptive competence, we use a knowledge-preserving fine-tuning recipe that mixes reactive flight data, aerial semantic data, and generic caption/VQA supervision. Beyond reporting current latency measurements, we position the system against recent state-of-the-art architectures, including AnywhereVLA, FutureVLA, and ReMem-VLA, showing that the measured action branch reaches a higher edge inference rate under our deployment conditions while retaining periodic semantic awareness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LiteVLA-H, a compact 256M-parameter vision-language-action model for dual-rate inference on the NVIDIA Jetson AGX Orin platform targeting aerial drone guidance. It claims that end-to-end latency in this edge regime is dominated by multimodal pre-fill rather than marginal decoding cost, motivating a scheduler that delivers reactive action tokens at 50.65 ms (19.74 Hz) while supporting sentence-level semantic outputs at 149.90-164.57 ms (6.08-6.67 Hz). The model is specialized via a knowledge-preserving fine-tuning recipe that mixes reactive flight data, aerial semantic data, and generic caption/VQA supervision, and is positioned as achieving higher edge action inference rates than baselines such as AnywhereVLA, FutureVLA, and ReMem-VLA while retaining semantic competence.
Significance. If the latency measurements and fine-tuning effectiveness are substantiated, the work provides a practical contribution to onboard VLA deployment in compute-constrained aerial systems by demonstrating a dual-rate architecture that reconciles low-latency control with periodic semantic perception. The empirical observation that pre-fill dominates latency offers a transferable design insight for edge VLA systems. The comparative positioning against recent architectures adds context, though the overall significance depends on the reproducibility and statistical robustness of the reported hardware results.
major comments (2)
- [Abstract] Abstract: the central performance claims rest on specific hardware latency numbers (50.65 ms action branch, 149.90-164.57 ms semantic branch) and a comparative claim of higher edge inference rate, yet the abstract provides no description of the measurement methodology, baseline re-implementations, statistical significance testing, or hardware configuration details; these are load-bearing for the dual-rate scheduler claim and must be supplied with full experimental protocols.
- [Abstract] The knowledge-preserving fine-tuning recipe is presented as successfully retaining descriptive competence while specializing for aerial guidance, but without reported ablations, semantic metrics (e.g., captioning or VQA scores before/after fine-tuning), or failure cases showing collapse risk, the assumption that mixing reactive flight, aerial semantic, and generic data suffices remains unverified and central to the specialization claim.
minor comments (2)
- [Abstract] Abstract contains typographical artifacts in latency reporting (e.g., '50.65,ms', '19.74,Hz', '149.90--164.57,ms', and stray backslash in '164.57,ms'); these should be corrected for clarity.
- The positioning against AnywhereVLA, FutureVLA, and ReMem-VLA would benefit from a dedicated comparison table or section that explicitly states the deployment conditions under which the higher edge rate is measured.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will revise the abstract and related sections to improve transparency on experimental details and the fine-tuning approach.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims rest on specific hardware latency numbers (50.65 ms action branch, 149.90-164.57 ms semantic branch) and a comparative claim of higher edge inference rate, yet the abstract provides no description of the measurement methodology, baseline re-implementations, statistical significance testing, or hardware configuration details; these are load-bearing for the dual-rate scheduler claim and must be supplied with full experimental protocols.
Authors: We agree that the abstract would benefit from additional context on the experimental setup to support the latency and rate claims. In the revised version, we will incorporate a concise summary of the hardware (NVIDIA Jetson AGX Orin), the measurement protocol (end-to-end latency averaged over repeated runs with standardized input sizes and batch configurations), and confirmation that baselines were re-implemented and evaluated under identical onboard conditions. Statistical robustness is reported via standard deviations in the main experimental section; we will reference this briefly in the abstract. Full protocols remain detailed in the methods and experiments sections. revision: yes
-
Referee: [Abstract] The knowledge-preserving fine-tuning recipe is presented as successfully retaining descriptive competence while specializing for aerial guidance, but without reported ablations, semantic metrics (e.g., captioning or VQA scores before/after fine-tuning), or failure cases showing collapse risk, the assumption that mixing reactive flight, aerial semantic, and generic data suffices remains unverified and central to the specialization claim.
Authors: We acknowledge that the abstract does not include explicit ablations, before/after semantic metrics, or failure-case analysis. The manuscript demonstrates retention of descriptive competence through the reported semantic output rates and comparative positioning, but to strengthen the claim we will revise the abstract to summarize the mixed-supervision strategy and its observed outcomes on semantic tasks. We will also add a brief reference to training observations regarding stability in the revised text. If space and data permit, we will include a short ablation summary or point to supplementary results. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper presents its core results as direct empirical measurements of end-to-end latency on Jetson AGX Orin hardware, with the dual-rate scheduler motivated by the observed dominance of multimodal pre-fill over token decoding cost. Reported values (50.65 ms / 19.74 Hz for action tokens; 149.90–164.57 ms / 6.08–6.67 Hz for semantic outputs) are framed as hardware benchmarks rather than quantities derived from internal equations or fitted parameters. The knowledge-preserving fine-tuning recipe is described as an empirical data-mixing procedure whose success is asserted without any self-referential derivation or uniqueness theorem. No load-bearing self-citations, ansatzes smuggled via prior work, or renamings of known results appear in the provided text; the argument chain remains externally falsifiable via replication on the stated platform.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLA models can be specialized for aerial tasks via mixed fine-tuning without loss of general descriptive capabilities
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Breath1024.leanperiod8 / 8-tick periodic micro-structure unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
end-to-end latency is dominated by multimodal pre-fill rather than by the marginal cost of decoding a few extra tokens... scheduler that issues reactive action tokens at 50.65 ms (19.74 Hz) while still supporting sentence-level semantic outputs at 149.90–164.57 ms (6.08–6.67 Hz)
-
IndisputableMonolith/Cost/FunctionalEquation.leanJ(x) = ½(x + x⁻¹) − 1 uniqueness unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L(n) = P(I_t, x_t, m_t) + sum D_i ... P ≫ D_i for small n
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
- [4]
-
[5]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M. J., Finn, C., and Liang, P. Fine-tuning vision- language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645, 2025a. Kim, M. J. et al. Openvla: An open-source vision-language- action model. InProceedings of the Conference on Robot 7 Submission and Formatting Instructions for ICML 2026 Learning, volume 270 ofPMLR, pp. 2679–...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Lu, Y . et al. Faster: Rethinking real-time flow vlas.arXiv preprint arXiv:2603.19199,
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
- [8]
- [9]
-
[10]
Williams, J., Gupta, K. D., George, R., and Sarkar, M. Litevla-edge: Quantized on-device multimodal control for embedded robotics.arXiv preprint arXiv:2603.03380,
- [11]
-
[12]
Xu, P. et al. Aerialvla: A vision-language-action model for uav navigation.arXiv preprint arXiv:2603.14363, 2026a. Xu, X. et al. Futurevla: Joint visuomotor predic- tion for vision-language-action model.arXiv preprint arXiv:2603.10712, 2026b. 1Department of Cyber Physical Systems, Clark Atlanta Uni- versity, Atlanta, GA, USA 2Siemens. Correspondence to: K...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.