PPO guided Agentic Pipeline for Adaptive Prompt Selection and Test Case Generation
Pith reviewed 2026-05-09 19:13 UTC · model grok-4.3
The pith
A PPO policy adaptively selects among eight prompting techniques for an LLM to generate test cases that achieve higher branch and line coverage than static or baseline methods on benchmark programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
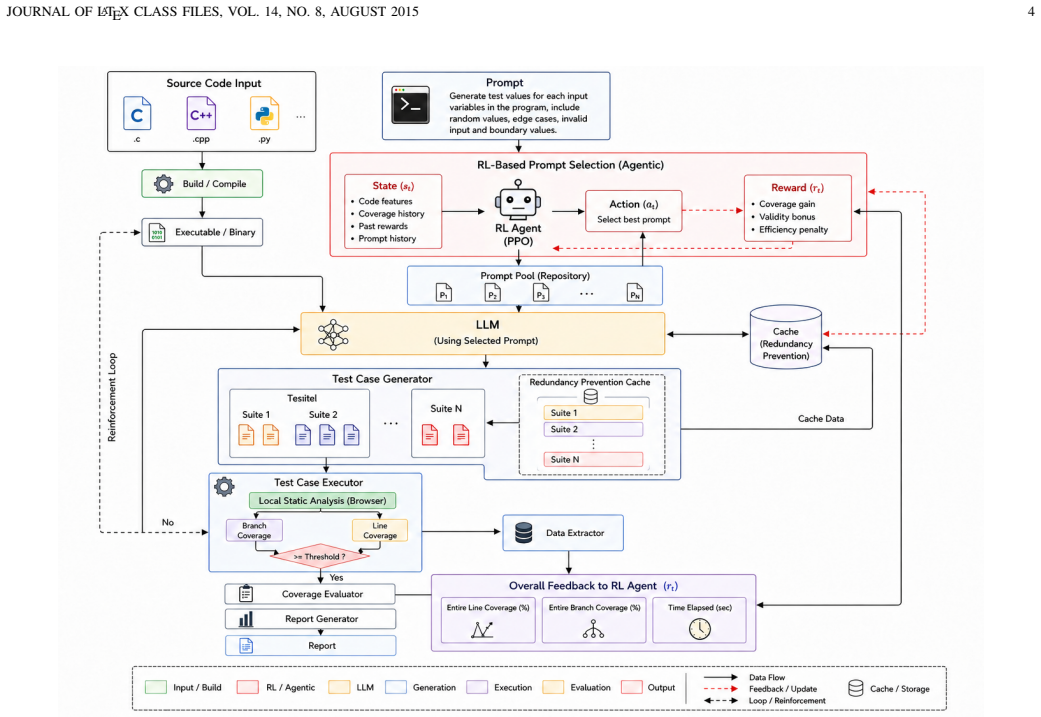
The central claim is that training a PPO policy network on an 11-dimensional state of static complexity and live coverage metrics to select among eight prompting techniques directs an LLM to produce test cases with superior branch and line coverage compared to CBMC, kS-LLM, and kS-LLM++ across twenty benchmark programs and loop bounds ranging from 1 to 2000, with the PALS suite reaching 100 percent branch coverage at bound 1 versus 86.8 percent for the next best method.
What carries the argument
The PPO policy network that maps the 11-dimensional input vector of code complexity and coverage metrics to a choice among eight prompting techniques such as boundary value analysis and random fuzzing, guided by a composite reward of coverage increases minus penalties for unexplored branches and long code.
If this is right
- The method reaches 100 percent branch coverage on the PALS suite at bound 1 where kS-LLM++ reaches only 86.8 percent.
- Coverage gains hold in most cases as loop bounds increase from 1 to 2000.
- The initial code minimization phase removes redundancies while preserving behavior to support later test generation.
- The reward design simultaneously encourages path exploration and shorter test code.
Where Pith is reading between the lines
- The same policy structure could be repurposed to adapt prompts for LLM tasks such as automated repair or documentation generation.
- Adding dynamic metrics like data-flow information to the state vector might extend effective coverage to programs with data-dependent branches.
- Evaluating the pipeline on industrial-scale codebases would reveal whether the current metric set scales without retraining.
- Hybridizing the agent with symbolic execution could handle cases where pure coverage rewards leave deep constraints unsolved.
Load-bearing premise
That an 11-dimensional vector of static complexity metrics plus live coverage metrics is sufficient for the PPO policy to select prompts that systematically explore unvisited paths and that the composite reward produces policies that generalize beyond the twenty benchmarks without overfitting.
What would settle it
Running PPO-LLM on a fresh collection of programs with structures absent from the original twenty benchmarks and observing no consistent coverage advantage over kS-LLM++ across loop bounds from 1 to 2000 would disprove the superiority result.
Figures
read the original abstract
Developing effective test cases capable of thoroughly exercising large-scale software systems is inherently difficult, especially if such systems have voluminous, complex, and deeply nested source codes. In this work, we present a novel approach for generating test cases using a reinforcement learning-driven agentic framework where Proximal Policy Optimization (PPO) is coupled with an LLM engine to guide prompt selection during test generation. Our approach consists of two phases. In Phase I, the ToT-guided optimization agent partitions and minimizes the source code by removing redundancies without changing the functional behavior of the source code. In Phase II, a PPO-based policy network is trained to solve the problem of selecting prompts among eight different prompting techniques, such as Boundary Value Analysis, Random Fuzzing, etc., based on the inputted 11-dimensional state vector representing the source code complexity metrics and live coverage metrics to direct the LLM engine towards exploring unvisited paths in the program. The PPO agent receives rewards based on a combination of increases in line and branch coverages, penalties for unexplored branches, and rewards for reducing source code length. From experiments conducted on twenty benchmark programs, it is evident that the proposed approach, PPO-LLM, outperforms CBMC, kS-LLM, and kS-LLM++ in terms of branch and line coverage in almost all cases, for various loop bound values ranging from BOUND~1 to BOUND~2000. While at BOUND~1, the coverage of branches is 100\% using PPO-LLM on the PALS suite, in comparison, it is around 86.8\% using kS-LLM++. This confirms that adaptive prompt selection driven by PPO substantially outperforms static prompting strategies on PALS type programs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PPO-LLM, a two-phase agentic framework for test case generation. Phase I uses Tree-of-Thoughts (ToT) to partition and minimize the source code. Phase II trains a PPO policy to select among eight prompting strategies based on an 11-dimensional state vector of static complexity and live coverage metrics, with rewards derived from coverage improvements, branch penalties, and code length reduction. On 20 benchmark programs, PPO-LLM is reported to achieve superior branch and line coverage compared to CBMC, kS-LLM, and kS-LLM++ for loop bounds from 1 to 2000, including 100% branch coverage on the PALS suite at BOUND=1 versus 86.8% for the best baseline.
Significance. If the reported coverage improvements hold under scrutiny and the learned policy generalizes beyond the training benchmarks, this work would represent a meaningful advance in LLM-assisted software testing by showing that reinforcement learning can dynamically adapt prompt selection to program characteristics. The integration of live coverage feedback into the state space is a promising direction for overcoming limitations of static prompting methods.
major comments (4)
- [Phase II description] The exact composition of the 11-dimensional state vector (static complexity metrics plus live coverage metrics) is not specified, preventing assessment of whether it provides sufficient information for the policy to learn generalizable prompt-selection heuristics.
- [Reward function] The composite reward is described qualitatively (coverage gains minus penalties for missed branches and long code), but the specific coefficients or weighting scheme are not provided, making the training objective non-reproducible and the source of performance gains unclear.
- [Experiments] The PPO agent is trained and evaluated on the same twenty benchmark programs with no mention of hold-out sets, cross-validation, or external test programs. This setup risks the policy memorizing program-specific sequences rather than learning transferable strategies, undermining the claim of substantial outperformance on PALS-type programs.
- [Results on PALS suite] The headline result of 100% branch coverage at BOUND=1 for PPO-LLM versus 86.8% for kS-LLM++ lacks accompanying details on number of runs, variance, or statistical significance tests, which are necessary to establish that the difference is reliable rather than due to stochasticity in LLM outputs or prompt execution.
minor comments (2)
- [Abstract] The notation 'BOUND~1' and 'BOUND~2000' should be clarified as BOUND=1 and BOUND=2000 for precision.
- [Phase II description] The paper would benefit from a brief description or reference to how the eight prompting techniques (e.g., Boundary Value Analysis, Random Fuzzing) are implemented within the LLM engine.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Phase II description] The exact composition of the 11-dimensional state vector (static complexity metrics plus live coverage metrics) is not specified, preventing assessment of whether it provides sufficient information for the policy to learn generalizable prompt-selection heuristics.
Authors: We agree that the precise composition of the 11-dimensional state vector is not explicitly enumerated in the current manuscript. In the revised version, we will expand the Phase II description to list all 11 components in detail. These comprise static complexity metrics (cyclomatic complexity, nesting depth, number of loops, number of conditional statements, number of functions, lines of code, and number of variables) together with live coverage metrics (current line coverage, current branch coverage, number of uncovered branches, number of uncovered lines, and a coverage delta from the previous step). This addition will allow readers to evaluate the information available to the policy and assess its potential for learning generalizable heuristics. revision: yes
-
Referee: [Reward function] The composite reward is described qualitatively (coverage gains minus penalties for missed branches and long code), but the specific coefficients or weighting scheme are not provided, making the training objective non-reproducible and the source of performance gains unclear.
Authors: We acknowledge that the reward function is described only qualitatively in the manuscript. We will revise the relevant section to provide the exact mathematical formulation, including the specific coefficients and weighting scheme applied to coverage gains, branch penalties, and code-length reduction. This will render the training objective fully reproducible and clarify the relative contributions to the observed performance improvements. revision: yes
-
Referee: [Experiments] The PPO agent is trained and evaluated on the same twenty benchmark programs with no mention of hold-out sets, cross-validation, or external test programs. This setup risks the policy memorizing program-specific sequences rather than learning transferable strategies, undermining the claim of substantial outperformance on PALS-type programs.
Authors: The referee correctly notes the absence of explicit hold-out sets or cross-validation. While the twenty benchmarks are standard and span diverse structures, we recognize the risk of program-specific memorization. In the revision we will add a dedicated discussion of generalization, including either results on additional hold-out programs or k-fold cross-validation where computationally feasible, along with any regularization steps already employed during PPO training. revision: yes
-
Referee: [Results on PALS suite] The headline result of 100% branch coverage at BOUND=1 for PPO-LLM versus 86.8% for kS-LLM++ lacks accompanying details on number of runs, variance, or statistical significance tests, which are necessary to establish that the difference is reliable rather than due to stochasticity in LLM outputs or prompt execution.
Authors: We agree that statistical details are essential to substantiate the headline result. The reported 100% branch coverage for PPO-LLM on the PALS suite at BOUND=1 was obtained across multiple independent runs to mitigate LLM stochasticity. In the revised manuscript we will report the exact number of runs, variance measures (standard deviation across runs), and the outcomes of statistical significance tests (paired t-tests) comparing PPO-LLM against the baselines. revision: yes
Circularity Check
No significant circularity; empirical coverage results measured externally
full rationale
The paper's core claim is an empirical comparison of PPO-LLM coverage against baselines on 20 benchmarks. Rewards are computed from external line/branch coverage tools rather than any internally fitted quantity renamed as a prediction. The PPO update follows the standard algorithm with no self-definitional reduction or load-bearing self-citation chain. The 11-dimensional state vector and composite reward are defined independently of the final reported numbers. While training and evaluation occur on the same programs (raising generalization questions), this does not make the reported outperformance equivalent to its inputs by construction. No quoted step reduces the result to a tautology.
Axiom & Free-Parameter Ledger
free parameters (2)
- Reward coefficients for line/branch coverage gain, unexplored-branch penalty, and code-length reduction
- Exact composition of the 11-dimensional state vector
axioms (2)
- domain assumption An LLM prompted with one of the eight listed techniques will produce test inputs that exercise the intended program paths when the prompt is chosen appropriately.
- domain assumption The PPO policy gradient update will converge to a useful prompt-selection policy from the 11-dimensional state.
Reference graph
Works this paper leans on
-
[1]
A3test: Assertion-augmented automated test case generation.Informa- tion and Software Technology, 176:107565, 2024
Saranya Alagarsamy, Chakkrit Tantithamthavorn, and Aldeida Aleti. A3test: Assertion-augmented automated test case generation.Informa- tion and Software Technology, 176:107565, 2024
2024
-
[2]
Chatunitest: A framework for llm-based test generation
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. Chatunitest: A framework for llm-based test generation. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, FSE 2024, page 572–576, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[3]
Deeprest: Automated test case generation for rest apis exploiting deep reinforcement learning
Davide Corradini, Zeno Montolli, Michele Pasqua, and Mariano Cec- cato. Deeprest: Automated test case generation for rest apis exploiting deep reinforcement learning. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ASE ’24, page 1383–1394, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[4]
Llm-tg: Towards automated test case generation for processors using large language models
Yifei Deng, Renzhi Chen, Chao Xiao, Zhijie Yang, Yuanfeng Luo, Jingyue Zhao, Na Li, Zhong Wan, Yongbao Ai, Huadong Dai, et al. Llm-tg: Towards automated test case generation for processors using large language models. In2024 IEEE 42nd International Conference on Computer Design (ICCD), pages 389–396. IEEE, 2024
2024
-
[5]
Automation of software test data generation using genetic algorithm and reinforcement learning
Mehdi Esnaashari and Amir Hossein Damia. Automation of software test data generation using genetic algorithm and reinforcement learning. Expert Systems with Applications, 183:115446, 2021
2021
-
[6]
Shuzheng Gao, Chaozheng Wang, Cuiyun Gao, Xiaoqian Jiao, Chun Yong Chong, Shan Gao, and Michael Lyu. The prompt alchemist: Automated llm-tailored prompt optimization for test case generation. arXiv preprint arXiv:2501.01329, 2025
-
[7]
Ashraful Islam, Junaed Younus Khan, Sanjida Senjik, and Anindya Iqbal
Navid Bin Hasan, Md. Ashraful Islam, Junaed Younus Khan, Sanjida Senjik, and Anindya Iqbal. Automatic high-level test case generation using large language models. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR), pages 674–685, 2025
2025
-
[8]
Preparation method in automated test case generation using machine learning
Kazuhiro Kikuma, Takeshi Yamada, Koki Sato, and Kiyoshi Ueda. Preparation method in automated test case generation using machine learning. InProceedings of the 10th International Symposium on Information and Communication Technology, SoICT ’19, page 393–398, New York, NY , USA, 2019. Association for Computing Machinery
2019
-
[9]
Pyse: Automatic worst-case test generation by reinforcement learning
Jinkyu Koo, Charitha Saumya, Milind Kulkarni, and Saurabh Bagchi. Pyse: Automatic worst-case test generation by reinforcement learning. In2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST), pages 136–147, 2019
2019
-
[10]
Test case generation for requirements in natural language-an llm comparison study
Brahma Reddy Korraprolu, Pavitra Pinninti, and Y Raghu Reddy. Test case generation for requirements in natural language-an llm comparison study. InProceedings of the 18th Innovations in Software Engineering Conference, pages 1–5, 2025
2025
-
[11]
Automated control logic test case generation using large language models
Heiko Koziolek, Virendra Ashiwal, Soumyadip Bandyopadhyay, and Chandrika K R. Automated control logic test case generation using large language models. In2024 IEEE 29th International Conference on Emerging Technologies and Factory Automation (ETFA), pages 1–8, 2024
2024
-
[12]
Automated test case generation for safety-critical software in scade
Elson Kurian, Pietro Braione, Daniela Briola, Dario D’Avino, Matteo Modonato, and Giovanni Denaro. Automated test case generation for safety-critical software in scade. In2023 IEEE/ACM 45th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 483–494, 2023
2023
-
[13]
Automated test cases generation from requirements specification
Mohammed Lafi, Thamer Alrawashed, and Ahmad Munir Hammad. Automated test cases generation from requirements specification. In 2021 International Conference on Information Technology (ICIT), pages 852–857, 2021
2021
-
[14]
Nnsmith: Generating diverse and valid test cases for deep learning compilers
Jiawei Liu, Jinkun Lin, Fabian Ruffy, Cheng Tan, Jinyang Li, Aurojit Panda, and Lingming Zhang. Nnsmith: Generating diverse and valid test cases for deep learning compilers. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS 2023, page 530–543, New York, NY , US...
2023
-
[15]
Pynguin: automated unit test generation for python
Stephan Lukasczyk and Gordon Fraser. Pynguin: automated unit test generation for python. InProceedings of the ACM/IEEE 44th Interna- tional Conference on Software Engineering: Companion Proceedings, ICSE ’22, page 168–172, New York, NY , USA, 2022. Association for Computing Machinery
2022
-
[16]
Automated test case generation using t5 and gpt-3
Alok Mathur, Shreyaan Pradhan, Prasoon Soni, Dhruvil Patel, and Rajeshkannan Regunathan. Automated test case generation using t5 and gpt-3. In2023 9th International Conference on Advanced Computing and Communication Systems (ICACCS), volume 1, pages 1986–1992, 2023
1986
-
[17]
A cascaded pipeline for self-directed, model-agnostic unit test generation via llms
Chao Ni, Xiaoya Wang, Xin Yin, Liushan Chen, and Guojun Ma. A cascaded pipeline for self-directed, model-agnostic unit test generation via llms. In2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE), pages 276–287, 2025
2025
-
[18]
Automated test case generation using machine learning and natural language processing
Arya Devi M R and Abdul Jabbar P. Automated test case generation using machine learning and natural language processing. In2025 In- ternational Conference on Intelligent and Secure Engineering Solutions (CISES), pages 345–350, 2025
2025
-
[19]
Abdul Malik Sami, Zeeshan Rasheed, Muhammad Waseem, Zheying Zhang, Herda Tomas, and Pekka Abrahamsson. A tool for test case scenarios generation using large language models.arXiv preprint arXiv:2406.07021, 2024
-
[20]
Automatic test case generation using unified modeling language (uml) state diagrams.IET software, 2(2):79–93, 2008
Philip Samuel, Rajib Mall, and Ajay Kumar Bothra. Automatic test case generation using unified modeling language (uml) state diagrams.IET software, 2(2):79–93, 2008
2008
-
[21]
An empirical evaluation of using large language models for automated unit test generation.IEEE Transactions on Software Engineering, 50(1):85–105, 2024
Max Sch ¨afer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. An empirical evaluation of using large language models for automated unit test generation.IEEE Transactions on Software Engineering, 50(1):85–105, 2024
2024
-
[22]
Reinforcement learning from automatic feedback for high-quality unit test generation
Benjamin Steenhoek, Michele Tufano, Neel Sundaresan, and Alexey Svyatkovskiy. Reinforcement learning from automatic feedback for high-quality unit test generation. In2025 IEEE/ACM International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest), pages 37–44, 2025
2025
-
[23]
Unit test case generation with transformers and focal context
Michele Tufano, Dawn Drain, Alexey Svyatkovskiy, Shao Kun Deng, and Neel Sundaresan. Unit test case generation with transformers and focal context.arXiv preprint arXiv:2009.05617, 2020
-
[24]
Simulation-based adversarial test generation for autonomous vehicles with machine learning components
Cumhur Erkan Tuncali, Georgios Fainekos, Hisahiro Ito, and James Kapinski. Simulation-based adversarial test generation for autonomous vehicles with machine learning components. In2018 IEEE Intelligent Vehicles Symposium (IV), pages 1555–1562, 2018
2018
-
[25]
Requirements-driven test generation for JOURNAL OF LATEX CLASS FILES, VOL
Cumhur Erkan Tuncali, Georgios Fainekos, Danil Prokhorov, Hisahiro Ito, and James Kapinski. Requirements-driven test generation for JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 11 autonomous vehicles with machine learning components.IEEE Trans- actions on Intelligent Vehicles, 5(2):265–280, 2020
2015
-
[26]
Llm4fin: Fully automat- ing llm-powered test case generation for fintech software acceptance testing
Zhiyi Xue, Liangguo Li, Senyue Tian, Xiaohong Chen, Pingping Li, Liangyu Chen, Tingting Jiang, and Min Zhang. Llm4fin: Fully automat- ing llm-powered test case generation for fintech software acceptance testing. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 1643–1655, 2024
2024
-
[27]
Llm-enhanced evolutionary test generation for untyped languages.Automated Software Engineering, 32(1):20, 2025
Ruofan Yang, Xianghua Xu, and Ran Wang. Llm-enhanced evolutionary test generation for untyped languages.Automated Software Engineering, 32(1):20, 2025
2025
-
[28]
Automatic test cases generation from business process models.Requirements engineering, 24(1):119–132, 2019
Arezoo Yazdani Seqerloo, Mohammad Javad Amiri, Saeed Parsa, and Mahnaz Koupaee. Automatic test cases generation from business process models.Requirements engineering, 24(1):119–132, 2019
2019
-
[29]
Rtcm: a natural language based, automated, and practical test case generation framework
Tao Yue, Shaukat Ali, and Man Zhang. Rtcm: a natural language based, automated, and practical test case generation framework. InProceedings of the 2015 International Symposium on Software Testing and Analysis, ISSTA 2015, page 397–408, New York, NY , USA, 2015. Association for Computing Machinery
2015
-
[30]
Quanjun Zhang, Ye Shang, Chunrong Fang, Siqi Gu, Jianyi Zhou, and Zhenyu Chen. Testbench: Evaluating class-level test case generation capability of large language models.arXiv preprint arXiv:2409.17561, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.