Recognition: unknown
EmoMM: Benchmarking and Steering MLLM for Multimodal Emotion Recognition under Conflict and Missingness
Pith reviewed 2026-05-09 19:21 UTC · model grok-4.3
The pith
Multimodal LLMs marginalize video input in emotion recognition under modality conflicts, but a new inference-time attention steering method counters this bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In evaluations on EmoMM, MLLMs show Video Contribution Collapse, marginalizing video due to high token redundancy and modality preferences. Conflict-aware Head-level Attention Steering detects conflicts and steers attention heads to balance contributions, mitigating bias in decision making.
What carries the argument
Conflict-aware Head-level Attention Steering (CHASE), a mechanism that identifies modality conflicts and adjusts attention at the head level during inference to reduce bias from over-reliance on certain modalities.
If this is right
- CHASE improves MLLM accuracy on emotion recognition tasks involving conflicts and missing modalities.
- Performance gains occur without any retraining of the underlying model.
- The method applies across different MLLM architectures and settings.
- It increases the reliability of affective computing in scenarios with imperfect data.
Where Pith is reading between the lines
- Similar modality collapse issues could affect MLLMs in other multimodal applications like video captioning or visual question answering.
- CHASE might be extended to steer attention based on other types of conflicts beyond emotion recognition.
- The benchmark subsets could serve as a testbed for evaluating future methods that address modality imbalances in large models.
Load-bearing premise
The EmoMM benchmark's conflict and missing subsets accurately capture the kinds of modality issues that occur in actual real-world multimodal interactions.
What would settle it
Running CHASE on an MLLM with the EmoMM conflict subsets and finding no significant improvement in emotion classification accuracy compared to the unsteered baseline, or no increase in attention weights on video tokens.
Figures








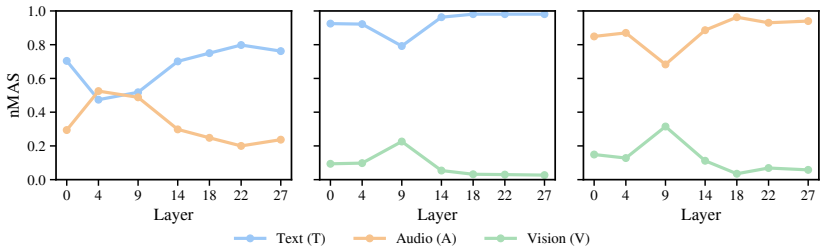



read the original abstract
Multimodal Emotion Recognition (MER) is critical for interpreting real-world interactions. While Multimodal Large Language Models (MLLM) have shown promise in MER, their internal decision-making mechanisms under modality conflict and missingness remain largely underexplored. In this paper, to systematically investigate these behaviors, we introduce EmoMM, a comprehensive benchmark featuring modality-aligned, conflict, and missing subsets. Through extensive evaluation, we uncover a Video Contribution Collapse (VCC) phenomenon, where MLLM marginalize video evidence due to high token redundancy and modality preferences. To address this, we propose Conflict-aware Head-level Attention Steering (CHASE), a lightweight mechanism that detects modality conflicts and performs inference-time attention steering, effectively mitigating decision bias without retraining the backbone. Experimental results demonstrate that CHASE consistently improves performance across various settings, significantly enhancing the reliability of MLLM in complex affective scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EmoMM, a benchmark for multimodal emotion recognition (MER) with modality-aligned, conflict, and missing subsets. It identifies a Video Contribution Collapse (VCC) phenomenon in which MLLMs marginalize video evidence due to token redundancy and modality preferences. To address this, the authors propose Conflict-aware Head-level Attention Steering (CHASE), a lightweight inference-time attention steering mechanism that detects modality conflicts and mitigates decision bias without retraining the backbone, claiming consistent performance gains across settings.
Significance. If the VCC phenomenon and CHASE gains are substantiated on natural data with full quantitative validation, the work would be significant for multimodal affective computing by providing a targeted benchmark for conflict/missingness scenarios and a practical, training-free intervention that improves MLLM reliability. The inference-time, head-level design is a clear strength, as it avoids retraining costs and could generalize to other MLLM applications.
major comments (2)
- [§3] §3 (EmoMM Benchmark Construction): The conflict and missing subsets must be validated as containing naturally contradictory affective signals across modalities (e.g., via human annotation or comparison to real-world data) rather than being generated through synthetic operations such as label swapping or forced misalignment; without this demonstration, the VCC phenomenon risks being an artifact of benchmark construction instead of an intrinsic MLLM property, which is load-bearing for both the diagnosis and the CHASE intervention claims.
- [§5] §5 (Experiments): The manuscript states that 'extensive evaluation' was performed and CHASE 'consistently improves performance,' yet provides no quantitative metrics, baseline comparisons, ablation studies, statistical tests, or effect sizes for either VCC or CHASE gains; this absence prevents assessment of whether the data support the central claims about mitigating decision bias.
minor comments (2)
- [Abstract] Abstract: The term 'Video Contribution Collapse (VCC)' is introduced without prior expansion, and the abstract references performance improvements without any numerical values or baseline names, reducing immediate clarity.
- [§4] Notation: The description of CHASE as 'head-level attention steering' would benefit from an explicit equation or pseudocode in the method section to clarify how conflict detection triggers the steering operation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We have carefully considered the major comments regarding the validation of the EmoMM benchmark subsets and the presentation of experimental results. Below, we provide point-by-point responses and indicate the revisions we will implement.
read point-by-point responses
-
Referee: [§3] §3 (EmoMM Benchmark Construction): The conflict and missing subsets must be validated as containing naturally contradictory affective signals across modalities (e.g., via human annotation or comparison to real-world data) rather than being generated through synthetic operations such as label swapping or forced misalignment; without this demonstration, the VCC phenomenon risks being an artifact of benchmark construction instead of an intrinsic MLLM property, which is load-bearing for both the diagnosis and the CHASE intervention claims.
Authors: We fully agree that demonstrating the natural occurrence of conflicting affective signals is essential for the validity of our findings on VCC. While the EmoMM conflict and missing subsets were designed to reflect plausible real-world scenarios of modality misalignment and absence (drawing from prior work in multimodal affective computing), we recognize the need for explicit validation. In the revised manuscript, we will add a human annotation study in §3, where independent annotators evaluate samples from the conflict subset for the presence of contradictory emotional cues across modalities. We will report inter-annotator agreement and compare to real-world examples where possible. This will substantiate that the observed VCC is not merely an artifact of synthetic construction. revision: yes
-
Referee: [§5] §5 (Experiments): The manuscript states that 'extensive evaluation' was performed and CHASE 'consistently improves performance,' yet provides no quantitative metrics, baseline comparisons, ablation studies, statistical tests, or effect sizes for either VCC or CHASE gains; this absence prevents assessment of whether the data support the central claims about mitigating decision bias.
Authors: We apologize for any insufficiency in the quantitative reporting in the submitted version. Our experiments do include detailed evaluations across multiple MLLMs and settings, with metrics demonstrating the VCC phenomenon (e.g., reduced video attention weights under conflict) and CHASE gains (improvements in emotion recognition accuracy). To fully address this, we will revise §5 to prominently feature all quantitative results, including comprehensive tables with baseline comparisons, ablation studies on head selection and conflict detection, statistical significance tests (e.g., paired t-tests), and effect sizes. Additional figures will illustrate the performance improvements under different conflict levels. This will allow readers to fully assess the support for our claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the EmoMM benchmark (with modality-aligned, conflict, and missing subsets) and the CHASE inference-time steering mechanism as new contributions. The VCC phenomenon is presented as an empirical observation from evaluations on this benchmark, and CHASE is described as a lightweight detection-and-steering procedure without retraining. No equations, parameter fits, or derivations are shown that reduce by construction to the inputs (e.g., no fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations). The derivation chain is self-contained in its empirical claims and new constructs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modality conflicts and missingness can be systematically and representatively simulated via benchmark subset construction
invented entities (1)
-
Video Contribution Collapse (VCC)
no independent evidence
Reference graph
Works this paper leans on
-
[3]
Hauptmann
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, and Alexander G. Hauptmann. 2024 a . https://proceedings.neurips.cc/paper_files/paper/2024/hash/c7f43ada17acc234f568dc66da527418-Abstract-Conference.html Emotion-LLaMA : Multimodal emotion recognition and reasoning with instruction tuning . Advances in...
2024
-
[4]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. 2024 b . https://arxiv.org/abs/2406.07476 VideoLLaMA 2 : Advancing spatial-temporal modeling and audio understanding in video- LLM s . arXiv preprint arXiv:2406.07476
work page internal anchor Pith review arXiv 2024
-
[5]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. 2024. https://arxiv.org/abs/2407.10759 Qwen2-Audio technical report . arXiv preprint arXiv:2407.10759
work page internal anchor Pith review arXiv 2024
-
[7]
Yiyang Fang, Jian Liang, Wenke Huang, He Li, Kehua Su, and Mang Ye. 2025. https://proceedings.mlr.press/v267/fang25h.html Catch your emotion: Sharpening emotion perception in multimodal large language models . In Proceedings of the 42nd International Conference on Machine Learning (ICML), pages 16029--16039. PMLR
2025
-
[8]
Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Yuhang Dai, Meng Zhao, Yi-Fan Zhang, Shaoqi Dong, Yangze Li, Xiong Wang, Haoyu Cao, Di Yin, Long Ma, Xiawu Zheng, Rongrong Ji, Yunsheng Wu, Ran He, Caifeng Shan, and Xing Sun. 2024. https://arxiv.org/abs/2408.05211 VITA : Towards open-source interactive omni multimodal LLM . arXiv preprint arXiv:2408.05211...
-
[9]
Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yunhang Shen, Xiaoyu Liu, Haoyu Cao, Zuwei Long, Heting Gao, Ke Li, Long Ma, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, and Ran He. 2025 a . https://arxiv.org/abs/2501.01957 VITA-1.5 : Towards GPT-4o level real-time vision and speech interaction . arXiv preprint arXiv:2501.01957
-
[12]
Google DeepMind . 2025. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf Gemini 3 pro model card . Technical report, Google DeepMind
2025
-
[17]
Chuangqi Li, Xinying Weng, Yifan Li, and Tianxin Zhang. 2025. https://doi.org/10.1080/10447318.2024.2338616 Multimodal learning engagement assessment system: An innovative approach to optimizing learning engagement . International Journal of Human--Computer Interaction, 41(5):3474--3490
-
[18]
Zheng Lian, Haoyu Chen, Lan Chen, Haiyang Sun, Licai Sun, Yong Ren, Zebang Cheng, Bin Liu, Rui Liu, Xiaojiang Peng, Jiangyan Yi, and Jianhua Tao. 2025. https://proceedings.mlr.press/v267/lian25a.html AffectGPT : A new dataset, model, and benchmark for emotion understanding with multimodal large language models . In Proceedings of the 42nd International Co...
2025
-
[20]
Jiquan Ngiam, Aditya Khosla, Minjae Kim, Juhan Nam, Honglak Lee, and Andrew Y. Ng. 2011. https://dl.acm.org/doi/10.5555/3104482.3104569 Multimodal deep learning . In Proceedings of the 28th International Conference on Machine Learning (ICML), pages 689--696
-
[22]
OpenAI . 2025. https://openai.com/index/introducing-gpt-5/ Introducing GPT-5 . Product announcement
2025
-
[23]
OpenBMB . 2025. https://huggingface.co/openbmb/MiniCPM-o-2_6 MiniCPM-o 2.6 : A GPT-4o -level MLLM for vision, speech and live streaming . Technical blog and model card
2025
-
[24]
Vittorio Pipoli, Alessia Saporita, Federico Bolelli, Marcella Cornia, Lorenzo Baraldi, Costantino Grana, Rita Cucchiara, and Elisa Ficarra. 2025. https://openaccess.thecvf.com/content/ICCV2025/html/Pipoli_MissRAG_Addressing_the_Missing_Modality_Challenge_in_Multimodal_Large_Language_ICCV_2025_paper.html MissRAG : Addressing the missing modality challenge ...
2025
-
[26]
Misha Sadeghi, Robert Richer, Bernhard Egger, Lena Schindler-Gmelch, Lydia Helene Rupp, Farnaz Rahimi, Matthias Berking, and Bjoern M. Eskofier. 2024. https://doi.org/10.1038/s44184-024-00112-8 Harnessing multimodal approaches for depression detection using large language models and facial expressions . npj Mental Health Research, 3:66
-
[29]
THUIAR . 2022. https://github.com/thuiar/ch-sims-v2 CH-SIMS v2.0 project page . Project page
2022
-
[31]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. 2025 a . https://arxiv.org/abs/2503.20215 Qwen2.5-Omni technical report . arXiv preprint arXiv:2503.20215
work page internal anchor Pith review arXiv 2025
-
[32]
Zhenrong Xu, Yuan Gao, Fang Wang, Longqian Zhang, Li Zhang, Junke Wang, and Jie Shu. 2025 b . https://doi.org/10.1038/s41598-025-03524-4 Depression detection methods based on multimodal fusion of voice and text . Scientific Reports, 15:21907
-
[33]
Lijuan Yan, Xiaotao Wu, and Yi Wang. 2025. https://doi.org/10.1371/journal.pone.0325377 Student engagement assessment using multimodal deep learning . PLOS ONE, 20(6):e0325377
-
[37]
Amir Zadeh, Rowan Zellers, Eli Pincus, and Louis-Philippe Morency. 2016. https://doi.org/10.1109/MIS.2016.94 MOSI : Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos . IEEE Intelligent Systems, 31(6):82--88
-
[39]
Fan Zhang, Zebang Cheng, Chong Deng, Haoxuan Li, Zheng Lian, Qian Chen, Huadai Liu, Wen Wang, Yi-Fan Zhang, Renrui Zhang, Ziyu Guo, Zhihong Zhu, Hao Wu, Haixin Wang, Yefeng Zheng, Xiaojiang Peng, Xian Wu, Kun Wang, Xiangang Li, and 2 others. 2025. https://arxiv.org/abs/2508.09210 MME-Emotion : A holistic evaluation benchmark for emotional intelligence in ...
-
[40]
Hang Zhang, Xin Li, and Lidong Bing. 2023. https://aclanthology.org/2023.emnlp-demo.49/ Video-LLaMA : An instruction-tuned audio-visual language model for video understanding . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 543--553. Association for Computational Linguistics
2023
-
[41]
Busso, Carlos and Bulut, Murtaza and Lee, Chi-Chun and Kazemzadeh, Abe and Mower, Emily and Kim, Samuel and Chang, Jeannette N. and Lee, Sungbok and Narayanan, Shrikanth S. , journal=. 2008 , publisher=. doi:10.1007/s10579-008-9076-6 , url=
-
[42]
2016 , doi=
Zadeh, Amir and Zellers, Rowan and Pincus, Eli and Morency, Louis-Philippe , journal=. 2016 , doi=
2016
-
[43]
Multimodal Language Analysis in the Wild: CMU - MOSEI Dataset and Interpretable Dynamic Fusion Graph
Zadeh, AmirAli Bagher and Liang, Paul Pu and Poria, Soujanya and Cambria, Erik and Morency, Louis-Philippe , booktitle=. Multimodal Language Analysis in the Wild:. 2018 , organization=. doi:10.18653/v1/P18-1208 , url=
-
[44]
Poria, Soujanya and Hazarika, Devamanyu and Majumder, Navonil and Naik, Gautam and Cambria, Erik and Mihalcea, Rada , booktitle=. 2019 , organization=. doi:10.18653/v1/P19-1050 , url=
-
[45]
Yu, Wenmeng and Xu, Hua and Meng, Fanyang and Zhu, Yilin and Ma, Yixiao and Wu, Jiele and Zou, Jiyun and Yang, Kaicheng , booktitle=. 2020 , organization=. doi:10.18653/v1/2020.acl-main.343 , url=
-
[46]
Make Acoustic and Visual Cues Matter:
Liu, Yihe and Yuan, Ziqi and Mao, Huisheng and Liang, Zhiyun and Yang, Wanqiuyue and Qiu, Yuanzhe and Cheng, Tie and Li, Xiaoteng and Xu, Hua and Gao, Kai , booktitle=. Make Acoustic and Visual Cues Matter:. 2022 , organization=. doi:10.1145/3536221.3556630 , url=
-
[47]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
Castro, Santiago and Hazarika, Devamanyu and P. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=. 2019 , organization=. doi:10.18653/v1/P19-1455 , url=
-
[48]
2024 , address=
Yue, Tan and Shi, Xuzhao and Mao, Rui and Hu, Zonghai and Cambria, Erik , booktitle=. 2024 , address=
2024
-
[49]
Fu, Yao and Liu, Qiong and Song, Qing and Zhang, Pengzhou and Liao, Gongdong , journal=. 2025 , publisher=. doi:10.3390/app15084509 , url=
-
[50]
Multimodal machine learning: A survey and taxonomy
Multimodal Machine Learning: A Survey and Taxonomy , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2019 , publisher=. doi:10.1109/TPAMI.2018.2798607 , url=
-
[51]
A Survey on Multimodal Large Language Models,
A Survey on Multimodal Large Language Models , author=. National Science Review , volume=. 2024 , publisher=. doi:10.1093/nsr/nwae403 , url=
-
[52]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages=
Tensor Fusion Network for Multimodal Sentiment Analysis , author=. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages=. 2017 , organization=. doi:10.18653/v1/D17-1115 , url=
-
[53]
Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov
Multimodal Transformer for Unaligned Multimodal Language Sequences , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=. 2019 , organization=. doi:10.18653/v1/P19-1656 , url=
-
[54]
Proceedings of the 28th International Conference on Machine Learning (ICML) , pages=
Multimodal Deep Learning , author=. Proceedings of the 28th International Conference on Machine Learning (ICML) , pages=. 2011 , url=
2011
-
[55]
Analyzing Modality Robustness in Multimodal Sentiment Analysis , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=. 2022 , organization=. doi:10.18653/v1/2022.naacl-main.50 , url=
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Are Multimodal Transformers Robust to Missing Modality? , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2022 , doi=
2022
-
[57]
arXiv preprint arXiv:2310.03986 , year=
Robust Multimodal Learning with Missing Modalities via Parameter-Efficient Adaptation , author=. arXiv preprint arXiv:2310.03986 , year=
-
[58]
Proceedings of the European Conference on Computer Vision (ECCV) , year=
Robust Multimodal Learning via Representation Decoupling , author=. Proceedings of the European Conference on Computer Vision (ECCV) , year=
-
[59]
Multimodal Prompt Learning with Missing Modalities for Sentiment Analysis and Emotion Recognition , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , organization=. doi:10.18653/v1/2024.acl-long.94 , url=
-
[60]
2025 , url=
Pipoli, Vittorio and Saporita, Alessia and Bolelli, Federico and Cornia, Marcella and Baraldi, Lorenzo and Grana, Costantino and Cucchiara, Rita and Ficarra, Elisa , booktitle=. 2025 , url=
2025
-
[61]
arXiv preprint arXiv:2410.02804 , year=
Leveraging Retrieval Augment Approach for Multimodal Emotion Recognition Under Missing Modalities , author=. arXiv preprint arXiv:2410.02804 , year=
-
[62]
Advances in Neural Information Processing Systems , volume=
Visual Instruction Tuning , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[63]
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , year=
-
[64]
2024 , url=
Zhang, Renrui and Han, Jiaming and Liu, Chris and Gao, Peng and Zhou, Aojun and Hu, Xiangfei and Yan, Shilin and Lu, Pan and Li, Hongsheng and Qiao, Yu , booktitle=. 2024 , url=
2024
-
[65]
2023 , url=
Gao, Peng and Han, Jiaming and Zhang, Renrui and Lin, Ziyi and Geng, Shijie and Zhou, Aojun and Zhang, Wei and Lu, Pan and He, Conghui and Yue, Xiangyu and Li, Hongsheng and Qiao, Yu , journal=. 2023 , url=
2023
-
[66]
2024 , address=
Lin, Bin and Ye, Yang and Zhu, Bin and Cui, Jiaxi and Ning, Munan and Jin, Peng and Yuan, Li , booktitle=. 2024 , address=
2024
-
[67]
2023 , url=
Li, KunChang and He, Yinan and Wang, Yi and Li, Yizhuo and Wang, Wenhai and Luo, Ping and Wang, Yali and Wang, Limin and Qiao, Yu , journal=. 2023 , url=
2023
-
[68]
Zhang, Yuanhan and Li, Bo and Liu, Haotian and Lee, Yong Jae and Gui, Liangke and Fu, Di and Feng, Jiashi and Liu, Ziwei and Li, Chunyuan , year=
-
[69]
2024 , url=
Zhu, Deyao and Chen, Jun and Shen, Xiaoqian and Li, Xiang and Elhoseiny, Mohamed , booktitle=. 2024 , url=
2024
-
[70]
2023 , organization=
Zhang, Hang and Li, Xin and Bing, Lidong , booktitle=. 2023 , organization=
2023
-
[71]
2024 , url=
Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong , journal=. 2024 , url=
2024
-
[72]
2023 , url=
Tang, Changli and Yu, Wenyi and Sun, Guangzhi and Chen, Xianzhao and Tan, Tian and Li, Wei and Lu, Lu and Ma, Zejun and Zhang, Chao , journal=. 2023 , url=
2023
-
[73]
Tang, Changli and others , journal=. video-. 2025 , url=
2025
-
[74]
video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models , author=. arXiv preprint arXiv:2406.15704 , year=
-
[75]
2023 , url=
Chu, Yunfei and Xu, Jin and Zhou, Xiaohuan and Yang, Qian and Zhang, Shiliang and Yan, Zhijie and Zhou, Chang and Zhou, Jingren , journal=. 2023 , url=
2023
-
[76]
2024 , url=
Chu, Yunfei and Xu, Jin and Yang, Qian and Wei, Haojie and Wei, Xipin and Guo, Zhifang and Leng, Yichong and Lv, Yuanjun and He, Jinzheng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , journal=. 2024 , url=
2024
-
[77]
Proceedings of the 40th International Conference on Machine Learning , series=
Robust Speech Recognition via Large-Scale Weak Supervision , author=. Proceedings of the 40th International Conference on Machine Learning , series=. 2023 , publisher=
2023
-
[78]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=. 2024 , address=. doi:10.18653/v1/2024.findings-acl.931 , note=
-
[79]
arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
2025 , url=
Introducing. 2025 , url=
2025
-
[81]
2025 , month=
Gemini 3 Pro Model Card , author=. 2025 , month=
2025
-
[82]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review arXiv
-
[83]
A new era of intelligence with
Hassabis, Demis and Kavukcuoglu, Koray and. A new era of intelligence with. 2025 , month=
2025
-
[84]
2025 , url=
Jin Xu and Zhifang Guo and Jinzheng He and Hangrui Hu and Ting He and Shuai Bai and Keqin Chen and Jialin Wang and Yang Fan and Kai Dang and Bin Zhang and Xiong Wang and Yunfei Chu and Junyang Lin , journal=. 2025 , url=
2025
-
[85]
2024 , url=
Chaoyou Fu and Haojia Lin and Zuwei Long and Yunhang Shen and Yuhang Dai and Meng Zhao and Yi-Fan Zhang and Shaoqi Dong and Yangze Li and Xiong Wang and Haoyu Cao and Di Yin and Long Ma and Xiawu Zheng and Rongrong Ji and Yunsheng Wu and Ran He and Caifeng Shan and Xing Sun , journal=. 2024 , url=
2024
-
[86]
2025 , url=
Fu, Chaoyou and Lin, Haojia and Wang, Xiong and Zhang, Yi-Fan and Shen, Yunhang and Liu, Xiaoyu and Cao, Haoyu and Long, Zuwei and Gao, Heting and Li, Ke and Ma, Long and Zheng, Xiawu and Ji, Rongrong and Sun, Xing and Shan, Caifeng and He, Ran , journal=. 2025 , url=
2025
-
[87]
Zhan, Jun and Dai, Junqi and Ye, Jiasheng and Zhou, Yunhua and Zhang, Dong and Liu, Zhigeng and Zhang, Xin and Yuan, Ruibin and Zhang, Ge and Li, Linyang and Yan, Hang and Fu, Jie and Gui, Tao and Sun, Tianxiang and Jiang, Yu-Gang and Qiu, Xipeng , booktitle=. 2024 , address=. doi:10.18653/v1/2024.acl-long.521 , note=
-
[88]
2024 , url=
Deitke, Matt and Clark, Christopher and Lee, Sangho and Tripathi, Rohun and Yang, Yue and Park, Jae Sung and Salehi, Mohammadreza and Muennighoff, Niklas and Lo, Kyle and Soldaini, Luca and Lu, Jiasen and Anderson, Taira and Ehsani, Kiana and Kembhavi, Aniruddha and Farhadi, Ali , journal=. 2024 , url=
2024
-
[89]
2024 , note=
Wu, Shengqiong and Fei, Hao and Qu, Leigang and Ji, Wei and Chua, Tat-Seng , booktitle=. 2024 , note=
2024
-
[90]
, journal=
Cheng, Zebang and Cheng, Zhi-Qi and He, Jun-Yan and Sun, Jingdong and Wang, Kai and Lin, Yuxiang and Lian, Zheng and Peng, Xiaojiang and Hauptmann, Alexander G. , journal=. 2024 , url=
2024
-
[91]
2025 , organization=
Lian, Zheng and Chen, Haoyu and Chen, Lan and Sun, Haiyang and Sun, Licai and Ren, Yong and Cheng, Zebang and Liu, Bin and Liu, Rui and Peng, Xiaojiang and Yi, Jiangyan and Tao, Jianhua , booktitle=. 2025 , organization=
2025
-
[92]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , pages=
Catch Your Emotion: Sharpening Emotion Perception in Multimodal Large Language Models , author=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , pages=. 2025 , organization=
2025
-
[93]
2025 , url=
Zhang, Fan and Cheng, Zebang and Deng, Chong and Li, Haoxuan and Lian, Zheng and Chen, Qian and Liu, Huadai and Wang, Wen and Zhang, Yi-Fan and Zhang, Renrui and Guo, Ziyu and Zhu, Zhihong and Wu, Hao and Wang, Haixin and Zheng, Yefeng and Peng, Xiaojiang and Wu, Xian and Wang, Kun and Li, Xiangang and Ye, Jieping and Heng, Pheng-Ann , journal=. 2025 , url=
2025
-
[94]
Proceedings of the 33rd ACM International Conference on Multimedia (MM '25) , year=
Benchmarking and Bridging Emotion Conflicts for Multimodal Emotion Reasoning , author=. Proceedings of the 33rd ACM International Conference on Multimedia (MM '25) , year=. doi:10.1145/3746027.3754856 , url=
-
[95]
Proceedings of the 26th International Conference on Multimodal Interaction (ICMI '24) , pages=
On Multimodal Emotion Recognition for Human-Chatbot Interaction in the Wild , author=. Proceedings of the 26th International Conference on Multimodal Interaction (ICMI '24) , pages=. 2024 , organization=. doi:10.1145/3678957.3685759 , url=
-
[96]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Multi-modal Preference Alignment Remedies Degradation of Visual Instruction Tuning on Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , address=
2024
-
[97]
Advances in Neural Information Processing Systems , volume=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[98]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review arXiv
-
[99]
Advances in Neural Information Processing Systems , volume=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.