Semantic Context-aware mOdality fUsion Transformer (SCOUT): A Context-Aware Multimodal Transformer for Concept-Grounded Pathology Report Generation
Pith reviewed 2026-05-09 18:50 UTC · model grok-4.3
The pith
SCOUT integrates local histological patterns, whole-slide context, and expert semantic descriptors to generate clinically coherent pathology reports from whole-slide images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
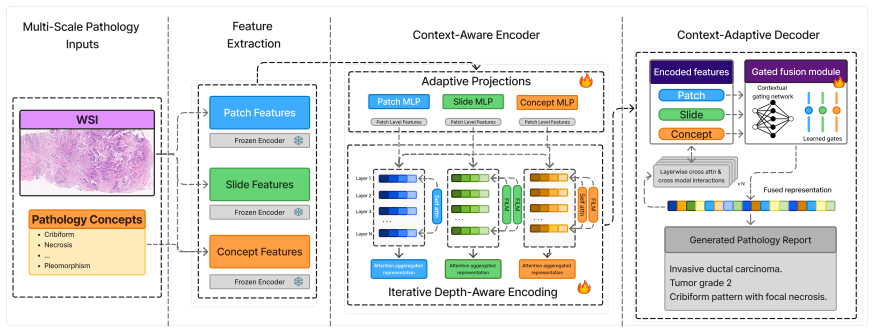
SCOUT is a context-aware concept-grounded multimodal framework that enables progressive conditioning of image representations by global slide information and explicit diagnostic concepts. The method integrates local histological patterns, whole-slide context, and expert-curated semantic descriptors within a unified learning paradigm, allowing visual features to be dynamically refined throughout the encoding process. By combining depth-aware contextual modulation with adaptive multimodal fusion during text generation, the framework produces clinically coherent reports while preserving complementarity across representational scales. Using CONCH1.5 features, SCOUT achieves the best BLEU-1 to 4,
What carries the argument
The SCOUT transformer, which performs progressive conditioning of visual features using global slide context and semantic descriptors through depth-aware contextual modulation and adaptive multimodal fusion during encoding and generation.
Where Pith is reading between the lines
- The same progressive conditioning pattern could be tested in other medical imaging domains that require both fine detail and high-level interpretation.
- If semantic descriptors can be extracted automatically rather than curated by experts, the method would scale to larger unlabeled archives.
- The approach highlights that explicit concept grounding may be more important than raw model scale for producing interpretable medical text.
Load-bearing premise
Expert-curated semantic descriptors are available, accurate, and sufficient to ground visual features without introducing new biases or hallucinations.
What would settle it
A head-to-head evaluation on a held-out set of cases where generated reports are scored by pathologists for factual accuracy and clinical utility, or where performance is measured after removing the semantic descriptor input.
Figures

read the original abstract
Whole-slide images (WSIs) present a fundamental challenge for computational pathology due to their extreme resolution, multi-scale heterogeneity, and the requirement for clinically reliable interpretation. Although recent pathology foundation models have enabled fluent report generation, they often lack clinical grounding, failing to accurately represent key diagnostic concepts and relationships observed by pathologists. This limitation arises from the difficulty of integrating heterogeneous visual evidence spanning fine-grained cellular patterns, slide-level tissue architecture, and high-level diagnostic concepts, while maintaining interpretability and clinical coherence. Here we present SCOUT: Semantic Context-aware mOdality fUsion Transformer, a context-aware concept-grounded multimodal framework for pathology report generation that enables progressive conditioning of image representations by global slide information and explicit diagnostic concepts. The method integrates local histological patterns, whole-slide context, and expert-curated semantic descriptors within a unified learning paradigm, allowing visual features to be dynamically refined throughout the encoding process. By combining depth-aware contextual modulation with adaptive multimodal fusion during text generation, the framework produces clinically coherent reports while preserving complementarity across representational scales. Using CONCH1.5 features, we evaluate SCOUT against WSI-Caption, HistGen, and BiGen on TCGA-BRCA, MICCAI REG, and HistAI. SCOUT achieves the best BLEU-1 to BLEU-4 and METEOR scores on all datasets, plus the best ROUGE-L on TCGA-BRCA and MICCAI REG. On TCGA-BRCA, it reaches 0.436/0.303/0.202/0.156 BLEU-1/2/3/4 and 0.204 METEOR; on REG 2025, it achieves 0.865/0.834/0.805/0.780 and 0.568. These results support progressive contextual conditioning for grounded pathology report generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SCOUT, a Semantic Context-aware mOdality fUsion Transformer for pathology report generation from whole-slide images. It proposes progressive conditioning of visual features using global slide context and expert-curated semantic descriptors, combined with adaptive multimodal fusion. Using CONCH1.5 features, SCOUT reports state-of-the-art BLEU-1/2/3/4 and METEOR scores on TCGA-BRCA (0.436/0.303/0.202/0.156 and 0.204), MICCAI REG 2025 (0.865/0.834/0.805/0.780 and 0.568), and HistAI, outperforming WSI-Caption, HistGen, and BiGen, with best ROUGE-L on two datasets.
Significance. If the central claims hold after proper validation, the work could advance multimodal report generation in computational pathology by addressing multi-scale heterogeneity through explicit concept grounding. The emphasis on progressive contextual modulation and complementarity across scales is a potentially useful direction, though its impact depends on whether metric gains translate to clinically meaningful improvements.
major comments (2)
- [Abstract] Abstract and Results: The central claim that SCOUT produces 'clinically coherent' and 'concept-grounded' reports is not supported by the presented evidence. Performance is evaluated solely via n-gram metrics (BLEU, METEOR, ROUGE-L) that measure surface overlap with reference text; no human evaluation by pathologists, concept-level precision/recall, hallucination analysis, or diagnostic accuracy assessment is reported to substantiate grounding or coherence.
- [Abstract] Abstract and Methods: No training details, ablation studies, hyperparameter sensitivity analysis, or statistical significance tests are supplied to establish that the reported gains arise from the proposed progressive conditioning and fusion rather than dataset-specific fitting or post-hoc choices. This undermines assessment of robustness across the three datasets.
minor comments (1)
- [Abstract] The abstract mentions evaluation on TCGA-BRCA, MICCAI REG, and HistAI but does not clarify whether the expert-curated semantic descriptors are dataset-specific or how they are obtained and validated.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and outline revisions to improve the manuscript's rigor and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract and Results: The central claim that SCOUT produces 'clinically coherent' and 'concept-grounded' reports is not supported by the presented evidence. Performance is evaluated solely via n-gram metrics (BLEU, METEOR, ROUGE-L) that measure surface overlap with reference text; no human evaluation by pathologists, concept-level precision/recall, hallucination analysis, or diagnostic accuracy assessment is reported to substantiate grounding or coherence.
Authors: We agree that n-gram metrics provide only indirect evidence for clinical coherence and concept grounding. SCOUT's architecture explicitly incorporates expert-curated semantic descriptors and progressive conditioning to promote these properties, and the consistent gains across three datasets support improved alignment with pathologist-written references. However, we acknowledge that automatic metrics alone cannot fully validate clinical utility. In the revision we will (1) temper the abstract and introduction claims to focus on metric improvements, (2) add a dedicated limitations paragraph discussing the gap between automatic and clinical evaluation, and (3) include qualitative report examples illustrating concept usage. We will also outline a concrete plan for future pathologist studies. revision: partial
-
Referee: [Abstract] Abstract and Methods: No training details, ablation studies, hyperparameter sensitivity analysis, or statistical significance tests are supplied to establish that the reported gains arise from the proposed progressive conditioning and fusion rather than dataset-specific fitting or post-hoc choices. This undermines assessment of robustness across the three datasets.
Authors: The full manuscript contains training details (optimizer, learning-rate schedule, batch size, and CONCH1.5 feature extraction) and ablation studies isolating the contributions of progressive conditioning and adaptive fusion. To strengthen the submission we will add (1) statistical significance testing (bootstrap confidence intervals and paired tests) for all reported metric improvements, (2) a hyperparameter sensitivity table or supplementary figure, and (3) expanded discussion of cross-dataset robustness. These additions will be placed in the Experiments and Ablation sections. revision: yes
Circularity Check
No derivation chain present; purely empirical model evaluation
full rationale
The paper describes a multimodal transformer architecture (SCOUT) and reports its BLEU/METEOR/ROUGE scores on TCGA-BRCA, MICCAI REG, and HistAI after training with CONCH1.5 features. No equations, first-principles derivations, uniqueness theorems, or parameter-fitting steps are presented that could reduce to self-definition or self-citation. Performance figures are direct empirical outcomes of supervised training and held-out evaluation, not predictions forced by construction from the inputs. Standard self-citation risks in deep learning (e.g., dataset-specific fitting) are noted by the reader but fall outside the circularity criteria, which require explicit reduction of a claimed derivation to its own fitted values or prior self-work.
Axiom & Free-Parameter Ledger
free parameters (1)
- transformer hyperparameters and fusion weights
Reference graph
Works this paper leans on
-
[1]
S. Banerjee and A. Lavie. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, 2005
work page 2005
- [2]
-
[3]
H. Che, H. Jin, Z. Gu, Y . Lin, C. Jin, and H. Chen. Llm-driven medical report generation via communication- efficient heterogeneous federated learning.IEEE Transactions on Medical Imaging, 2025
work page 2025
- [4]
- [5]
- [6]
-
[7]
T. Ding, S. J. Wagner, A. H. Song, R. J. Chen, M. Y . Lu, A. Zhang, A. J. Vaidya, G. Jaume, M. Shaban, A. Kim, et al. A multimodal whole-slide foundation model for pathology.Nature medicine, pages 1–13, 2025
work page 2025
-
[8]
J. Gamper and N. Rajpoot. Multiple instance captioning: Learning representations from histopathology textbooks and articles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16549–16559, 2021
work page 2021
- [9]
- [10]
-
[11]
D. Hu, Z. Jiang, J. Shi, F. Xie, K. Wu, K. Tang, M. Cao, J. Huai, and Y . Zheng. Pathology report generation from whole slide images with knowledge retrieval and multi-level regional feature selection.Computer Methods and Programs in Biomedicine, 263:108677, 2025
work page 2025
- [12]
-
[13]
K. Jin, Q. Sun, D. Kang, Z. Luo, T. Yu, W. Han, Y . Zhang, M. Wang, D. Shi, and A. Grzybowski. Grounded report generation for enhancing ophthalmic ultrasound interpretation using vision-language segmentation models.npj Digital Medicine, 2026
work page 2026
- [14]
- [15]
- [16]
-
[17]
C.-Y . Lin. Rouge: A package for automatic evaluation of summaries. InText Summarization Branches Out, pages 74–81, 2004
work page 2004
-
[18]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov and F. Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review arXiv 2016
-
[19]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
M. Y . Lu, B. Chen, A. Zhang, D. F. Williamson, R. J. Chen, T. Ding, L. P. Le, Y .-S. Chuang, and F. Mahmood. Visual language pretrained multiple instance zero-shot transfer for histopathology images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19764–19775, 2023
work page 2023
-
[21]
M. Y . Lu, B. Chen, D. F. Williamson, R. J. Chen, I. Liang, T. Ding, G. Jaume, I. Odintsov, L. P. Le, G. Gerber, et al. A visual-language foundation model for computational pathology.Nature medicine, 30(3):863–874, 2024
work page 2024
-
[22]
R. T. Lucassen, S. P. Moonemans, T. van de Luijtgaarden, G. E. Breimer, W. A. Blokx, and M. Veta. Pathology report generation and multimodal representation learning for cutaneous melanocytic lesions. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 502–511. Springer, 2025. 15
work page 2025
-
[23]
D. Ma, J. Pang, M. B. Gotway, and J. Liang. A fully open ai foundation model applied to chest radiography. Nature, 643(8071):488–498, 2025. doi: 10.1038/s41586-025-09079-8
-
[24]
Miccai 2025 workshop on computational pathology: Report generation challenge, 2025
MICCAI COMPAY Workshop Organizers. Miccai 2025 workshop on computational pathology: Report generation challenge, 2025. Challenge website and dataset description
work page 2025
-
[25]
A. Nicolson, J. Dowling, and B. Koopman. Improving chest x-ray report generation by leveraging warm starting. Artificial intelligence in medicine, 144:102633, 2023
work page 2023
-
[26]
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, 2002
work page 2002
- [27]
-
[28]
S. Sengupta and D. E. Brown. Automatic report generation for histopathology images using pre-trained vision transformers and bert. In2024 IEEE International Symposium on Biomedical Imaging (ISBI), pages 1–5. IEEE, 2024
work page 2024
-
[29]
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan. Show and tell: A neural image caption generator. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3156–3164, 2015
work page 2015
-
[30]
X. Wang, F. Wang, H. Wang, B. Jiang, C. Li, Y . Wang, Y . Tian, and J. Tang. Activating associative disease-aware vision token memory for llm-based x-ray report generation.IEEE Transactions on Medical Imaging, 2025
work page 2025
-
[31]
L. Zhang, B. Yun, Q. Li, and Y . Wang. Historical report guided bi-modal concurrent learning for pathology report generation. In J. C. Gee, D. C. Alexander, J. Hong, J. E. Iglesias, C. H. Sudre, A. Venkataraman, P. Golland, J. H. Kim, and J. Park, editors,Medical Image Computing and Computer Assisted Intervention – MICCAI 2025, pages 343–352, Cham, 2026. ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.