Recognition: unknown
TT4D: A Pipeline and Dataset for Table Tennis 4D Reconstruction From Monocular Videos
Pith reviewed 2026-05-09 15:11 UTC · model grok-4.3
The pith
Lifting 2D ball tracks to 3D before segmentation enables reliable table tennis reconstruction from monocular videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that inverting the usual order—lifting the full unsegmented 2D ball detections to 3D trajectories and spin estimates first, then performing segmentation—yields accurate 3D ball paths and enables reconstruction of complete table tennis gameplay from monocular broadcast videos, including cases of high occlusion, and produces a multimodal dataset with time segmentation, 3D human meshes, and calibrations that supports downstream tasks such as racket impact estimation and generative modeling of rallies.
What carries the argument
The learned lifting network that converts the entire unsegmented 2D ball track into 3D positions and spin estimates, which then supports reliable time segmentation and full 4D reconstruction.
If this is right
- Racket pose and velocity at impact can be estimated directly from the reconstructed 3D trajectories.
- Generative models of competitive rallies can be trained on the high-fidelity 4D data.
- Virtual replays and detailed player analysis become feasible using existing broadcast footage.
- Gameplay reconstruction succeeds on general-view videos where 2D-based segmentation previously failed.
Where Pith is reading between the lines
- The lift-first order may extend to other fast ball sports with frequent occlusions, such as tennis or volleyball.
- Inferred spin values could support quantitative studies of technique differences across players.
- Large 4D sports datasets of this kind could accelerate simulation-based training for robotic athletes.
Load-bearing premise
The learned lifting network can produce accurate 3D ball positions and spin from noisy 2D detections even under high occlusion and varied camera viewpoints.
What would settle it
A multi-view capture of a real match with known 3D ball ground truth where the single-video pipeline outputs positions that deviate substantially or produces incorrect shot segmentations during occluded periods.
Figures






read the original abstract
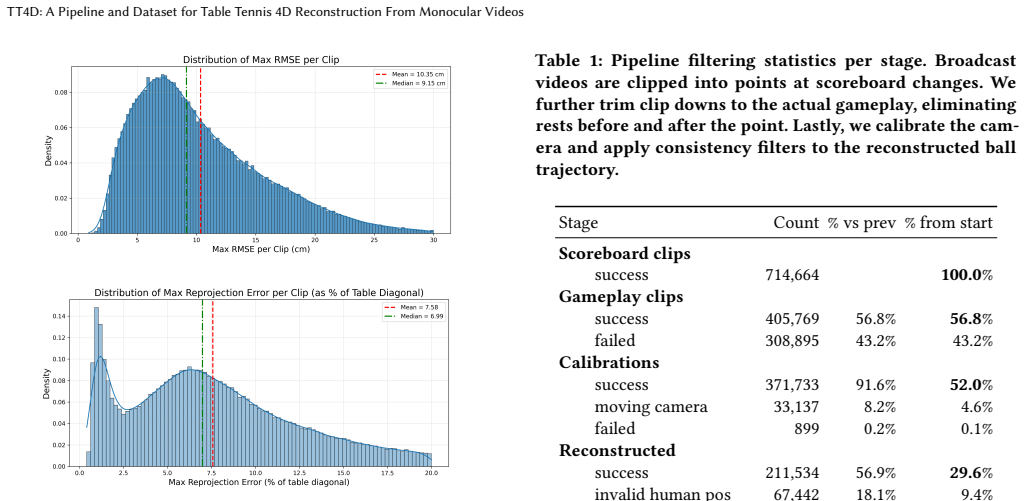
We present TT4D, a large-scale, high-fidelity table tennis dataset. It provides $140+$ hours of reconstructed singles and doubles gameplay from monocular broadcast videos, featuring multimodal annotations like high-quality camera calibrations, precise 3D ball positions, ball spin, time segmentation, and 3D human meshes over time. This rich data provides a new foundation for virtual replay, in-depth player analysis, and robot learning. The dataset's combination of scale and precision is achieved through a novel reconstruction pipeline. Prior methods first partition a game sequence into individual shot segments based on the 2D ball track, and only then attempt reconstruction. However, 2D-based time segmentation collapses under occlusion and varied camera viewpoints, preventing reliable reconstruction. We invert this paradigm by first lifting the entire unsegmented 2D ball track to 3D through a learned lifting network. This 3D trajectory then allows us to reliably perform time segmentation. The learned lifting network also infers the ball's spin, handles unreliable ball detections, and successfully reconstructs the ball trajectory in cases of high occlusion. This lift-first design is necessary, as our pipeline is the only method capable of reconstructing table tennis gameplay from general-view broadcast monocular videos. We demonstrate the dataset's fidelity through two downstream tasks: estimating the racket's pose \& velocity at impact, and training a generative model of competitive rallies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TT4D, a large-scale dataset of over 140 hours of 4D table tennis reconstructions from monocular broadcast videos, with multimodal annotations including camera calibrations, 3D ball positions, ball spin, time segmentation, and 3D human meshes. It introduces a lift-first pipeline that uses a learned network to lift unsegmented 2D ball tracks to 3D before performing time segmentation, spin estimation, and handling occlusions, claiming this is the only approach that works for general-view broadcast videos. The dataset is validated indirectly through two downstream tasks: racket pose and velocity estimation at impact, and training a generative model of competitive rallies.
Significance. If the reconstruction fidelity holds, the work would deliver a substantial new resource for computer vision in sports, supporting virtual replay, player analysis, and robot learning applications. The scale and precision of the annotations represent a clear advance over existing table tennis datasets, and the empirical, data-driven pipeline avoids parameter-fitting circularity.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claim that the learned lifting network reliably produces accurate 3D ball positions and spin from noisy 2D detections under occlusion and viewpoint variation lacks any quantitative support such as 3D position RMSE, spin error, or ablation on occlusion levels. This directly undermines the assertion that the lift-first design is necessary and that the pipeline is the only viable method for general broadcast videos.
- [Methods] Methods section: No details are provided on the lifting network architecture, training procedure, loss functions, or dataset splits used to learn 3D lifting and spin inference, making it impossible to assess robustness to the weakest assumption of reliable performance on held-out broadcast sequences.
minor comments (2)
- [Abstract] The abstract claims '140+ hours' but does not report the exact number of videos, games, or total frames, which would better contextualize the dataset scale.
- [Figures] Figure captions and text could more explicitly distinguish between qualitative visualizations of the pipeline and any indirect evidence from downstream tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for strengthening the presentation of our lift-first pipeline and its validation. We address each major comment below and commit to revisions that improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central claim that the learned lifting network reliably produces accurate 3D ball positions and spin from noisy 2D detections under occlusion and viewpoint variation lacks any quantitative support such as 3D position RMSE, spin error, or ablation on occlusion levels. This directly undermines the assertion that the lift-first design is necessary and that the pipeline is the only viable method for general broadcast videos.
Authors: We agree that direct quantitative metrics would provide stronger support for the claims regarding the lifting network. The current manuscript demonstrates fidelity indirectly via two downstream tasks (racket pose/velocity estimation at impact and training a generative model of rallies), which rely on the accuracy of the 3D reconstructions. However, to directly address this point, we will add quantitative evaluations in the revised manuscript, including 3D position RMSE, spin estimation errors, and ablations on occlusion levels using available ground-truth subsets from controlled multi-view captures. These additions will be placed in the Evaluation section and referenced in the abstract to better justify the lift-first design. revision: yes
-
Referee: [Methods] Methods section: No details are provided on the lifting network architecture, training procedure, loss functions, or dataset splits used to learn 3D lifting and spin inference, making it impossible to assess robustness to the weakest assumption of reliable performance on held-out broadcast sequences.
Authors: We acknowledge this omission and will expand the Methods section in the revision to include complete details on the lifting network architecture, training procedure, loss functions for 3D lifting and spin inference, and the dataset splits used. This will enable assessment of robustness on held-out sequences and improve reproducibility. revision: yes
Circularity Check
No circularity; empirical pipeline without derivations or self-referential fits
full rationale
The paper describes a data-driven pipeline that trains a lifting network on 2D-to-3D ball data and then uses the resulting 3D trajectories for downstream segmentation and reconstruction. No equations, uniqueness theorems, or first-principles derivations are presented that reduce to fitted parameters or self-citations by construction. The claim that 2D segmentation fails under occlusion is an external empirical observation, not a self-defined loop, and the lift-first ordering is justified by that observation rather than by re-using the network's own outputs as its inputs. The work remains self-contained as an empirical dataset and pipeline contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard pinhole camera model and basic ball physics hold for lifting 2D detections to 3D trajectories.
Reference graph
Works this paper leans on
-
[1]
Joel A E Andersson, Joris Gillis, Greg Horn, James B Rawlings, and Moritz Diehl
-
[2]
CasADi – A software framework for nonlinear optimization and optimal control.Mathematical Programming Computation11, 1 (2019), 1–36
2019
-
[3]
Joao Pedro Araujo, Yanjie Ze, Pei Xu, Jiajun Wu, and C Karen Liu. 2026. Retar- geting matters: General motion retargeting for humanoid motion tracking. In IEEE International Conference on Robotics and Automation (ICRA)
2026
-
[4]
Jiang Bian, Xuhong Li, Tao Wang, Qingzhong Wang, Jun Huang, Chen Liu, Jun Zhao, Feixiang Lu, Dejing Dou, and Haoyi Xiong. 2024. P2ANet: a large-scale benchmark for dense action detection from table tennis match broadcasting videos.ACM Transactions on Multimedia Computing, Communications and Appli- cations20, 4 (2024), 1–23
2024
-
[5]
Yu-Jou Chen and Yu-Shuen Wang. 2024. TrackNetV3: Enhancing ShuttleCock Tracking with Augmentations and Trajectory Rectification. InProceedings of the 5th ACM International Conference on Multimedia in Asia(Tainan, Taiwan) (MMAsia ’23). Article 1, 7 pages
2024
-
[6]
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. 2025. PaddleOCR 3.0 Technical Report. arXiv:2507.05595 [cs.CV]
work page internal anchor Pith review arXiv 2025
-
[7]
D’Ambrosio, Saminda Abeyruwan, Laura Graesser, et al
David B. D’Ambrosio, Saminda Abeyruwan, Laura Graesser, et al. 2025. Achieving human level competitive robot table tennis. InIEEE International Conference on Robotics and Automation (ICRA). 74–82
2025
-
[8]
Alexander Dittrich, Jan Schneider, Simon Guist, Nico Gürtler, Heiko Ott, Thomas Steinbrenner, Bernhard Schölkopf, and Dieter Büchler. 2023. AIMY: An Open- source Table Tennis Ball Launcher for Versatile and High-fidelity Trajectory Generation.IEEE International Conference on Robotics and Automation (ICRA)
2023
-
[9]
Moritz Einfalt, Katja Ludwig, and Rainer Lienhart. 2023. Uplift and Upsample: Efficient 3D Human Pose Estimation with Uplifting Transformers. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)
2023
-
[10]
Morten Holck Ertner, Sofus Schou Konglevoll, Magnus Ibh, and Stella Graßhof
-
[11]
InProceedings of the 7th ACM International Workshop on Multimedia Content Analysis in Sports
SynthNet: Leveraging Synthetic Data for 3D Trajectory Estimation from Monocular Video. InProceedings of the 7th ACM International Workshop on Multimedia Content Analysis in Sports. 51–58
-
[12]
Shankar Sastry
Daniel Etaat, Dvij Kalaria, Nima Rahmanian, and S. Shankar Sastry. 2025. LATTE- MV: Learning to Anticipate Table Tennis Hits from Monocular Videos. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[13]
Yuta Fujihara, Tomoyasu Shimada, Xiangbo Kong, Ami Tanaka, Hiroki Nishikawa, and Hiroyuki Tomiyama. 2025. Stroke Classification in Table Tennis as a Multi-Label Classification Task with Two Labels Per Stroke.Sensors25, 3 (2025)
2025
-
[14]
Yapeng Gao, Jonas Tebbe, Julian Krismer, and Andreas Zell. 2019. Markerless Racket Pose Detection and Stroke Classification Based on Stereo Vision for Table Tennis Robots. In2019 Third IEEE International Conference on Robotic Computing (IRC). 189–196
2019
-
[15]
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. 2023. Humans in 4D: Reconstructing and Tracking Humans with Transformers. InIEEE/CVF International Conference on Computer Vision (ICCV)
2023
-
[16]
Thomas Gossard, Julian Krismer, Andreas Ziegler, Jonas Tebbe, and Andreas Zell. 2024. Table tennis ball spin estimation with an event camera. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 3347–3356
2024
-
[17]
Thomas Gossard, Filip Radovic, Andreas Ziegler, and Andrea Zell. 2026. Blurball: Joint ball and motion blur estimation for table tennis ball tracking. InInternational Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
2026
-
[18]
Thomas Gossard, Jonas Tebbe, Andreas Ziegler, and Andreas Zell. 2023. Spindoe: A ball spin estimation method for table tennis robot. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 5744–5750
2023
-
[19]
Thomas Gossard, Andreas Ziegler, and Andreas Zell. 2025. TT3D: Table Tennis 3D Reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
2025
-
[20]
Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 7132–7141
2018
-
[21]
Huang, I
Y. Huang, I. Liao, C. Chen, T. İk, and W. Peng. 2019. TrackNet: A Deep Learning Network for Tracking High-speed and Tiny Objects in Sports Applications. In 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (A VSS). 1–8
2019
-
[22]
Daniel Kienzle, Marco Kantonis, Robin Schön, and Rainer Lienhart. 2024. Seg- former++: Efficient token-merging strategies for high-resolution semantic seg- mentation. InIEEE International Conference on Multimedia Information Processing and Retrieval (MIPR)
2024
-
[23]
Daniel Kienzle, Katja Ludwig, Julian Lorenz, Shin’ichi Satoh, and Rainer Lienhart
-
[24]
InIEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)
Uplifting Table Tennis: A Robust, Real-World Application for 3D Trajectory and Spin Estimation. InIEEE/CVF Winter Conference on Applications of Computer Vision (W ACV)
-
[25]
Daniel Kienzle, Robin Schön, Rainer Lienhart, and Shin’ichi Satoh. 2025. Towards Ball Spin and Trajectory Analysis in Table Tennis Broadcast Videos via Physically Grounded Synthetic-to-Real Transfer. InIEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
2025
-
[26]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Opti- mization. InInternational Conference on Learning Representations ICLR, Yoshua Bengio and Yann LeCun (Eds.)
2015
-
[27]
Komorowski, G
J. Komorowski, G. Kurzejamski, and G. Sarwas. 2019. DeepBall: Deep Neural- Network Ball Detector. InProceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019) - Volume 5: VISAPP. 297–304
2019
-
[28]
Kaustubh Milind Kulkarni and Sucheth Shenoy. 2021. Table tennis stroke recog- nition using two-dimensional human pose estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4576–4584
2021
- [29]
- [30]
-
[31]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. 2023. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations
2023
-
[32]
Chunfang Liu, Yoshikazu Hayakawa, and Akira Nakashima. 2012. Racket control and its experiments for robot playing table tennis. In2012 IEEE International Conference on Robotics and Biomimetics (ROBIO). 241–246
2012
-
[33]
Liu and J
P. Liu and J. Wang. 2022. MonoTrack: Shuttle Trajectory Reconstruction from Monocular Badminton Video. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 3512–3521
2022
-
[34]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. 2015. SMPL: A Skinned Multi-Person Linear Model.ACM Trans. Graphics (Proc. SIGGRAPH Asia)34, 6 (Oct. 2015), 248:1–248:16
2015
-
[35]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. International Conference on Learning Representations(2019)
2019
-
[36]
Katharina Muelling, Abdeslam Boularias, Betty Mohler, Bernhard Schölkopf, and Jan Peters. 2014. Learning strategies in table tennis using inverse reinforcement learning.Biol. Cybern.108, 5 (Oct. 2014), 603–619
2014
-
[37]
Takuya Nakabayashi, Kyota Higa, Masahiro Yamaguchi, Ryo Fujiwara, and Hideo Saito. 2024. Event-based ball spin estimation in sports. InProceedings of the 7th ACM International Workshop on Multimedia Content Analysis in Sports. 3367– 3375
2024
-
[38]
Akira Nakashima, Yuki Ogawa, Yosuke Kobayashi, and Yoshikazu Hayakawa
-
[39]
InProceedings of the 2010 American Control Conference
Modeling of rebound phenomenon of a rigid ball with friction and elastic effects. InProceedings of the 2010 American Control Conference. 1410–1415
2010
-
[40]
Puntawat Ponglertnapakorn and Supasorn Suwajanakorn. 2025. Where is the ball: 3d ball trajectory estimation from 2d monocular tracking. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR) Workshops. 6122–6131
2025
-
[41]
Arjun Raj, Lei Wang, and Tom Gedeon. 2025. TrackNetV4: Enhancing Fast Sports Object Tracking with Motion Attention Maps. InICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
2025
-
[42]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. RoFormer: Enhanced transformer with Rotary Position Embedding. Neurocomputing568 (2024), 127063
2024
- [43]
-
[44]
N. Sun, Y. Lin, S. Chuang, T. Hsu, D. Yu, H. Chung, and T. İk. 2020. TrackNetV2: Efficient Shuttlecock Tracking Network. In2020 International Conference on Pervasive Artificial Intelligence (ICPAI). 86–91
2020
-
[45]
Mingxing Tan and Quoc V Le. 2019. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. InProceedings of the 36th International Conference on Machine Learning (ICML), Vol. 97. 6105–6114
2019
-
[46]
Shuhei Tarashima, Muhammad Abdul Haq, Yushan Wang, and Norio Tagawa
-
[47]
In 34th British Machine Vision Conference 2023, BMVC 2023
Widely applicable strong baseline for sports ball detection and tracking. In 34th British Machine Vision Conference 2023, BMVC 2023
2023
-
[48]
Antti Tarvainen and Harri Valpola. 2017. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. InProceedings of the 31st International Conference on Neural Information Processing Systems. 1195–1204
2017
-
[49]
Jonas Tebbe, Lukas Klamt, Yapeng Gao, and Andreas Zell. 2020. Spin Detection in Robotic Table Tennis. In2020 IEEE International Conference on Robotics and Automation (ICRA). 9694–9700
2020
-
[50]
Emanuel Todorov, Tom Erez, and Yuval Tassa. 2012. MuJoCo: A physics engine for model-based control. In2012 IEEE/RSJ International Conference on Intelligent Rahmanian, Kienzle, Gossard et al. Robots and Systems. 5026–5033
2012
-
[51]
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector-Brooks, Guy Wolf, and Yoshua Bengio. 2024. Improving and gener- alizing flow-based generative models with minibatch optimal transport.Trans- actions on Machine Learning Research(2024)
2024
-
[52]
Alexander Tong, Nikolay Malkin, Kilian Fatras, Lazar Atanackovic, Yanlei Zhang, Guillaume Huguet, Guy Wolf, and Yoshua Bengio. 2024. Simulation-Free Schrödinger Bridges via Score and Flow Matching.International Conference on Artificial Intelligence and Statistics(2024)
2024
-
[53]
Rejin Varghese and Sambath M. 2024. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS). 1–6
2024
-
[54]
Roman Voeikov, Nikolay Falaleev, and Ruslan Baikulov. 2020. TTNet: Real-time temporal and spatial video analysis of table tennis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 884–885
2020
-
[55]
Andreas Wächter and Lorenz T. Biegler. 2006. On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. Mathematical Programming106 (2006), 25–57
2006
-
[56]
Qizhi Wang and Luyan Shi. 2013. Pose estimation based on PnP algorithm for the racket of table tennis robot. In2013 25th Chinese Control and Decision Conference (CCDC). 2642–2647
2013
-
[57]
Zhikun Wang, Abdeslam Boularias, Katharina Mülling, Bernhard Schölkopf, and Jan Peters. 2017. Anticipatory action selection for human–robot table tennis. Artificial Intelligence247 (2017), 399–414. Special Issue on AI and Robotics
2017
-
[58]
Zhou Wang, Alan Bovik, Hamid Sheikh, and Eero Simoncelli. 2004. Image Quality Assessment: From Error Visibility to Structural Similarity.Image Processing, IEEE Transactions on13 (05 2004), 600–612
2004
-
[59]
Wang, M Deisenroth, H
Z. Wang, M Deisenroth, H. Ben Amor, D. Vogt, B. Schoelkopf, and J. Peters
-
[60]
In Proceedings of Robotics: Science and Systems (R:SS)
Probabilistic Modeling of Human Movements for Intention Inference. In Proceedings of Robotics: Science and Systems (R:SS)
- [61]
-
[62]
Van Zandycke and C
G. Van Zandycke and C. De Vleeschouwer. 2019. Real-Time CNN-based Seg- mentation Architecture for Ball Detection in a Single View Setup. InProceedings Proceedings of the 2nd International Workshop on Multimedia Content Analysis in Sports (MMSports ’19). 51–58
2019
- [63]
-
[64]
Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. 2018. Unet++: A Nested U-Net Architecture for Medical Image Segmenta- tion. InDeep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. 3–11. TT4D: A Pipeline and Dataset for Table Tennis 4D Reconstruction From Monocular Videos TT4D: A Pipe...
2018
-
[65]
near-zero
Note that this stage may fail and produce clips that do not exhibit any gameplay. This is not a problem, however, since these clips are removed in the filtering stage. Duplicated Frame RemovalWhile processing online table-tennis footage, we observed that certain frames were duplicated within the video stream. This phenomenon typically arises when the fram...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.