Recognition: 2 theorem links
· Lean TheoremMultiBreak: A Scalable and Diverse Multi-turn Jailbreak Benchmark for Evaluating LLM Safety
Pith reviewed 2026-05-10 15:56 UTC · model grok-4.3
The pith
MultiBreak builds a benchmark of over ten thousand multi-turn jailbreak prompts that exposes higher LLM vulnerabilities than single-turn tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
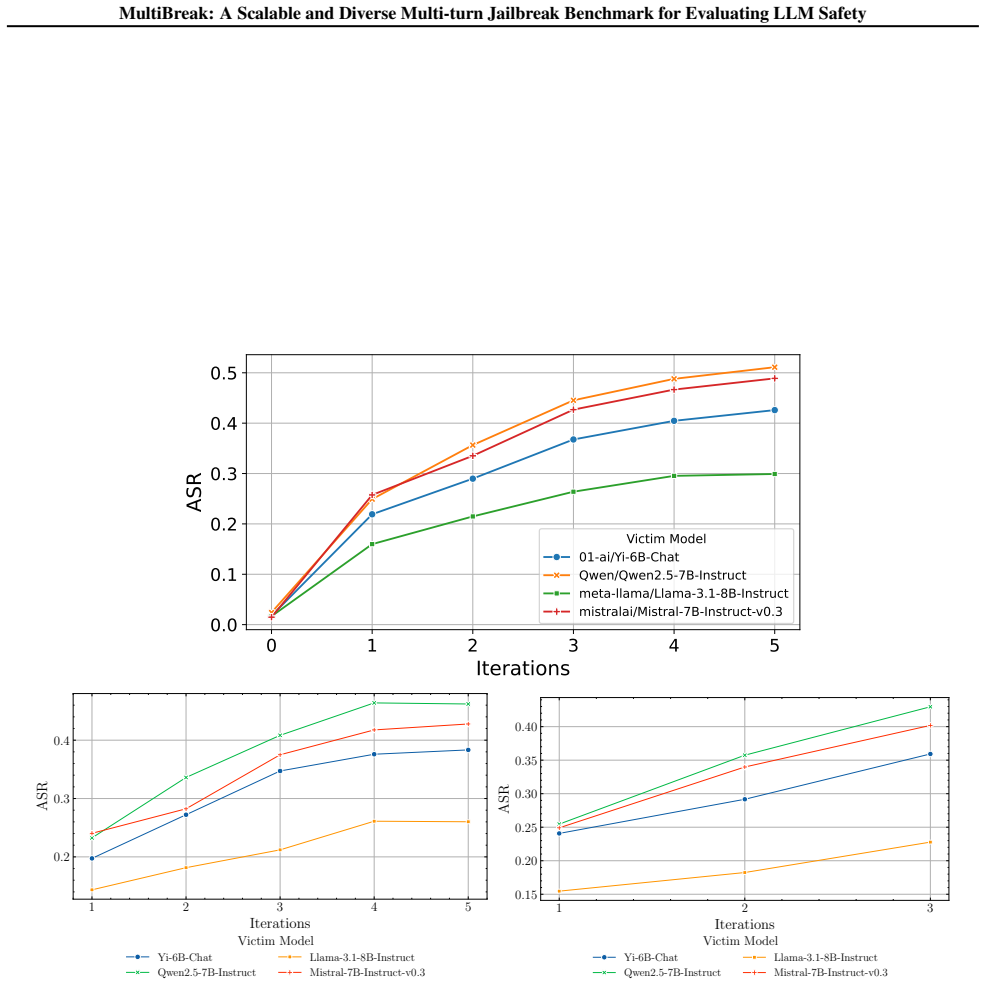
MultiBreak supplies 10,389 multi-turn adversarial prompts that cover 2,665 distinct harmful intents and the widest range of topics in any such benchmark to date. The prompts are produced by an iterative active learning pipeline in which a generator is fine-tuned on uncertainty-selected candidates to increase attack strength. When tested, the benchmark records attack success rates up to 54 points higher on DeepSeek-R1-7B and 34.6 points higher on GPT-4.1-mini than the next-best existing dataset. The results also show that categories rated low-risk in single-turn settings become substantially more effective when delivered across multiple turns.
What carries the argument
An active learning pipeline that iteratively fine-tunes a prompt generator using uncertainty-based refinement to expand a set of multi-turn jailbreak examples.
If this is right
- Attack categories that look safe in single-turn evaluations can become effective when spread over several conversation turns.
- Diverse topic coverage in a benchmark is required to surface fine-grained weaknesses that narrower datasets miss.
- Current safety alignments leave models open to realistic multi-turn attacks at higher rates than previously measured.
- Scaling up the number and variety of test prompts improves the ability to detect and address specific vulnerabilities.
- Multi-turn benchmarks provide a more accurate picture of safety performance under conditions that match actual use.
Where Pith is reading between the lines
- The generation method could be run on new base models to create safety-training data that targets the weaknesses it uncovers.
- Comparing results across model sizes or training regimes might show which design choices reduce multi-turn susceptibility.
- Extending the same pipeline to include image or tool-use turns could test whether vulnerabilities grow in richer interaction settings.
- Organizations building chat systems might adopt similar benchmarks to set measurable thresholds for deployment readiness.
Load-bearing premise
The prompts produced by the iterative generator truly represent natural harmful user intents and do not carry detectable generation artifacts that would alter how models respond to them.
What would settle it
Measuring attack success rates on the same models using an equal number of multi-turn prompts written by humans without any automated generation or refinement process and checking whether those rates remain comparably high.
Figures










read the original abstract
We present MultiBreak, a scalable and diverse multi-turn jailbreak benchmark to evaluate large language model (LLM) safety. Multi-turn jailbreaks mimic natural conversational settings, making them easier to bypass safety-aligned LLM than single-turn jailbreaks. Existing multi-turn benchmarks are limited in size or rely heavily on templates, which restrict their diversity. To address this gap, we unify a wide range of harmful jailbreak intents, and introduce an active learning pipeline for expanding high-quality multi-turn adversarial prompts, where a generator is iteratively fine-tuned to produce stronger attack candidates, guided by uncertainty-based refinement. Our MultiBreak includes 10,389 multi-turn adversarial prompts, spans 2,665 distinct harmful intents, and covers the most diverse set of topics to date. Empirical evaluation shows that our benchmark achieves up to a 54.0 and 34.6 higher attack success rate (ASR)} than the second-best dataset on DeepSeek-R1-7B and GPT-4.1-mini, respectively. More importantly, safety evaluations suggest that diverse attack categories uncover fine-grained LLM vulnerabilities}, and categories that appear benign under single-turn can exhibit substantially higher adversarial effectiveness in multi-turn scenarios. These findings highlight persistent vulnerabilities of LLMs under realistic adversarial settings and establish MultiBreak as a scalable resource for advancing LLM safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MultiBreak, a benchmark of 10,389 multi-turn adversarial prompts spanning 2,665 distinct harmful intents, constructed via an active learning pipeline that iteratively fine-tunes a generator using uncertainty-based refinement. It claims this benchmark achieves up to 54.0 and 34.6 higher attack success rates (ASR) than the second-best existing dataset on DeepSeek-R1-7B and GPT-4.1-mini, respectively, while also showing that diverse multi-turn attack categories uncover fine-grained LLM vulnerabilities not evident in single-turn settings.
Significance. If the central claims hold after validation, MultiBreak would be a valuable scalable resource for LLM safety research, filling a gap in large, diverse multi-turn jailbreak benchmarks that better approximate real conversational attacks. The empirical ASR comparisons and category-level vulnerability analysis could help prioritize safety improvements, and the active learning method offers a potentially generalizable way to expand such datasets.
major comments (3)
- [§3] §3 (Active Learning Pipeline): The uncertainty-based refinement and iterative fine-tuning of the generator lack reported human validation, cross-generator transfer tests, or ablation studies to rule out generator-specific artifacts or biases in the resulting 10,389 prompts. This is load-bearing for the diversity claim (2,665 intents) and the headline ASR gains, as the skeptic note correctly identifies that such artifacts could inflate measured effectiveness without corresponding to robust, generalizable multi-turn jailbreaks.
- [§4] §4 (Empirical Evaluation): The ASR results (e.g., 54.0 higher on DeepSeek-R1-7B) are reported without error bars, confidence intervals, statistical significance tests, multiple random seeds, or explicit criteria for judging attack success. This makes the quantitative superiority over prior datasets difficult to assess and prevents full evaluation of the central empirical claims.
- [§5] §5 (Vulnerability Analysis): The claim that categories appearing benign under single-turn exhibit substantially higher adversarial effectiveness in multi-turn scenarios requires controls for potential confounds such as total conversation length, token count, or prompt complexity; without them, the multi-turn structure itself may not be the causal factor.
minor comments (2)
- [Abstract] Abstract: A formatting artifact appears as 'ASR)} than'; this should be corrected for clarity.
- [§2] The manuscript would benefit from an explicit taxonomy or categorization scheme for the 2,665 harmful intents and details on how the base harmful intents were unified from prior sources.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with specific plans for revision. These changes will strengthen the empirical rigor and validation of our claims without altering the core contributions of MultiBreak.
read point-by-point responses
-
Referee: §3 (Active Learning Pipeline): The uncertainty-based refinement and iterative fine-tuning of the generator lack reported human validation, cross-generator transfer tests, or ablation studies to rule out generator-specific artifacts or biases in the resulting 10,389 prompts. This is load-bearing for the diversity claim (2,665 intents) and the headline ASR gains, as the skeptic note correctly identifies that such artifacts could inflate measured effectiveness without corresponding to robust, generalizable multi-turn jailbreaks.
Authors: We agree that additional validation is important for substantiating the diversity and generalizability claims. In the revised manuscript, we will add: (1) human evaluation on a stratified random sample of 500 prompts assessing intent fidelity, coherence, and harmfulness; (2) ablation studies comparing the full pipeline against a non-uncertainty baseline to quantify the refinement step's contribution; and (3) transfer results using a second generator model on a 1,000-prompt subset. These additions will directly address potential artifacts while preserving the active learning approach's efficiency. revision: yes
-
Referee: §4 (Empirical Evaluation): The ASR results (e.g., 54.0 higher on DeepSeek-R1-7B) are reported without error bars, confidence intervals, statistical significance tests, multiple random seeds, or explicit criteria for judging attack success. This makes the quantitative superiority over prior datasets difficult to assess and prevents full evaluation of the central empirical claims.
Authors: We acknowledge the need for statistical transparency. The revised version will include: binomial confidence intervals and error bars on all ASR figures; results averaged over three random seeds for prompt ordering and evaluation; two-sided t-tests or Wilcoxon tests with p-values for dataset comparisons; and an explicit section detailing the attack success criteria (binary judgment by GPT-4o following the standard refusal-vs-compliance rubric used in prior jailbreak literature). These updates will allow readers to fully evaluate the reported gains. revision: yes
-
Referee: §5 (Vulnerability Analysis): The claim that categories appearing benign under single-turn exhibit substantially higher adversarial effectiveness in multi-turn scenarios requires controls for potential confounds such as total conversation length, token count, or prompt complexity; without them, the multi-turn structure itself may not be the causal factor.
Authors: This concern is well-taken. To isolate the multi-turn effect, we will add matched-subset analyses in the revised paper: single-turn and multi-turn prompts will be paired on total token count (within ±10%) and linguistic complexity (Flesch-Kincaid and dependency depth). We will report ASR differences on these controlled subsets alongside the original results, confirming whether the multi-turn advantage persists after accounting for length and complexity confounds. revision: yes
Circularity Check
No circularity: benchmark construction and ASR evaluation are independent of each other
full rationale
The paper describes an active learning pipeline (iterative generator fine-tuning + uncertainty refinement) that produces the 10,389 prompts spanning 2,665 intents. The headline empirical results—higher ASR on DeepSeek-R1-7B and GPT-4.1-mini—are measured on held-out target models after construction, not defined in terms of the pipeline itself. No equations, self-definitions, or load-bearing self-citations reduce any claim to its inputs by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Harmful intents can be unified across sources and expanded via iterative generator fine-tuning guided by uncertainty without introducing invalid or non-adversarial examples.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
active learning pipeline... generator is iteratively fine-tuned... guided by uncertainty-based refinement... ASR(qadv) = 1/|V||J| ... σ(qadv) = Std ... faith(q, qadv) = cos(Enc(q), Enc(qadv))
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
10,389 multi-turn adversarial prompts... 2,665 distinct harmful intents... diversity score D = 1/log K Σ -pi log pi (K=26)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[2]
2025 , institution =
Threat Intelligence Report: August 2025 , author =. 2025 , institution =
2025
-
[3]
2025 , eprint=
LLMs know their vulnerabilities: Uncover Safety Gaps through Natural Distribution Shifts , author=. 2025 , eprint=
2025
-
[4]
34th USENIX Security Symposium (USENIX Security 25) , pages=
Great, Now Write an Article About That: The Crescendo \ Multi-Turn \ \ LLM \ Jailbreak Attack , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[5]
Llm defenses are not robust to multi-turn human jailbreaks yet
Llm defenses are not robust to multi-turn human jailbreaks yet , author=. arXiv preprint arXiv:2408.15221 , year=
-
[6]
arXiv preprint arXiv:2409.17458 , year=
Red queen: Safeguarding large language models against concealed multi-turn jailbreaking , author=. arXiv preprint arXiv:2409.17458 , year=
-
[7]
SafeDialBench: A Fine-Grained Safety Benchmark for Large Language Models in Multi-Turn Dialogues with Diverse Jailbreak Attacks , author=. arXiv preprint arXiv:2502.11090 , year=
-
[8]
Safety alignment should be made more than just a few tokens deep.CoRR, abs/2406.05946,
Safety alignment should be made more than just a few tokens deep , author=. arXiv preprint arXiv:2406.05946 , year=
-
[9]
arXiv preprint arXiv:2410.11459 , year=
Jigsaw puzzles: Splitting harmful questions to jailbreak large language models , author=. arXiv preprint arXiv:2410.11459 , year=
-
[10]
arXiv preprint arXiv:2406.17626 , year=
Cosafe: Evaluating large language model safety in multi-turn dialogue coreference , author=. arXiv preprint arXiv:2406.17626 , year=
-
[11]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
2025
-
[12]
2023 , eprint=
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset , author=. 2023 , eprint=
2023
-
[13]
Advances in Neural Information Processing Systems , volume=
Bag of tricks: Benchmarking of jailbreak attacks on llms , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Jailbreakbench: An open robustness benchmark for jailbreaking large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal , author=. arXiv preprint arXiv:2402.04249 , year=
work page internal anchor Pith review arXiv
-
[16]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Zhao, J., Huang, J., Wu, Z., Bau, D., and Shi, W
Sorry-bench: Systematically evaluating large language model safety refusal , author=. arXiv preprint arXiv:2406.14598 , year=
-
[18]
Red-Teaming Large Language Models using Chain of Utterances for Safety-Alignment
Red-teaming large language models using chain of utterances for safety-alignment , author=. arXiv preprint arXiv:2308.09662 , year=
- [19]
-
[20]
Do-Not-Answer: A Dataset for Evaluating Safeguards in LLMs
Do-not-answer: A dataset for evaluating safeguards in llms , author=. arXiv preprint arXiv:2308.13387 , year=
-
[21]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Fine-tuning aligned language models compromises safety, even when users do not intend to! , author=. arXiv preprint arXiv:2310.03693 , year=
work page internal anchor Pith review arXiv
-
[22]
Catastrophic jailbreak of open-source llms via exploiting generation
Catastrophic jailbreak of open-source llms via exploiting generation , author=. arXiv preprint arXiv:2310.06987 , year=
-
[23]
Latent jailbreak: A benchmark for evaluating text safety and output robustness of large language models , author=. arXiv preprint arXiv:2307.08487 , year=
-
[24]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[25]
Computer , volume=
The carbon footprint of machine learning training will plateau, then shrink , author=. Computer , volume=. 2022 , publisher=
2022
-
[26]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[28]
2025 , month = apr, day =
OpenAI , title =. 2025 , month = apr, day =
2025
-
[29]
Best-of-n jailbreaking , author=. arXiv preprint arXiv:2412.03556 , year=
-
[30]
2025 , month = feb, day =
OpenAI , title =. 2025 , month = feb, day =
2025
-
[31]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[33]
2024 , eprint=
Yi: Open Foundation Models by 01.AI , author=. 2024 , eprint=
2024
-
[34]
From clip to dino: Visual encoders shout in multi-modal large language models , author=. arXiv preprint arXiv:2310.08825 , year=
-
[35]
2024 , eprint=
The Multilingual Alignment Prism: Aligning Global and Local Preferences to Reduce Harm , author=. 2024 , eprint=
2024
-
[36]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Mrj-agent: An effective jailbreak agent for multi-round dialogue , author=. arXiv preprint arXiv:2411.03814 , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Active learning helps pretrained models learn the intended task , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
2025 , howpublished =
Claude Opus 4.1 Model Overview , author =. 2025 , howpublished =
2025
-
[41]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[42]
SoSBench: Benchmarking Safety Alignment on Six Scientific Domains
SOSBENCH: Benchmarking Safety Alignment on Scientific Knowledge , author=. arXiv preprint arXiv:2505.21605 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2502.12025 , year=
Safechain: Safety of language models with long chain-of-thought reasoning capabilities , author=. arXiv preprint arXiv:2502.12025 , year=
-
[44]
IEEE Transactions on Neural Networks and Learning Systems , volume=
A survey on deep active learning: Recent advances and new frontiers , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2024 , publisher=
2024
-
[45]
On statistical bias in active learning: How and when to fix it.arXiv preprint arXiv:2101.11665,
On statistical bias in active learning: How and when to fix it , author=. arXiv preprint arXiv:2101.11665 , year=
-
[46]
arXiv preprint arXiv:2408.02666 , year=
Self-taught evaluators , author=. arXiv preprint arXiv:2408.02666 , year=
-
[47]
2024 , eprint=
FlipAttack: Jailbreak LLMs via Flipping , author=. 2024 , eprint=
2024
-
[48]
2024 , eprint=
Jailbreaking Black Box Large Language Models in Twenty Queries , author=. 2024 , eprint=
2024
-
[49]
2025 , eprint=
CleanGen: Mitigating Backdoor Attacks for Generation Tasks in Large Language Models , author=. 2025 , eprint=
2025
-
[50]
Standard Models , author=
Impact of Data Duplication on Deep Neural Network-Based Image Classifiers: Robust vs. Standard Models , author=. 2025 IEEE Security and Privacy Workshops (SPW) , pages=. 2025 , organization=
2025
-
[51]
2025 , eprint=
Prompt Engineering or Fine-Tuning: An Empirical Assessment of LLMs for Code , author=. 2025 , eprint=
2025
-
[52]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[53]
2024 , eprint=
Bias and Fairness in Large Language Models: A Survey , author=. 2024 , eprint=
2024
-
[54]
Continuous Judgment Tasks , author=
Systematic Bias in Large Language Models: Discrepant Response Patterns in Binary vs. Continuous Judgment Tasks , author=. 2025 , eprint=
2025
-
[55]
2024 , eprint=
A StrongREJECT for Empty Jailbreaks , author=. 2024 , eprint=
2024
-
[56]
2025 , eprint=
GuidedBench: Measuring and Mitigating the Evaluation Discrepancies of In-the-wild LLM Jailbreak Methods , author=. 2025 , eprint=
2025
-
[57]
2025 , eprint=
Prompt-Response Semantic Divergence Metrics for Faithfulness Hallucination and Misalignment Detection in Large Language Models , author=. 2025 , eprint=
2025
-
[58]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[59]
2025 , url =
GPT-5 System Card , author =. 2025 , url =
2025
-
[60]
2024 , eprint=
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. 2024 , eprint=
2024
-
[61]
2024 , url =
Introducing the next generation of Claude , author =. 2024 , url =
2024
-
[62]
2023 , howpublished =
GPT-3.5 Turbo , author =. 2023 , howpublished =
2023
-
[63]
2025 , eprint=
From Selection to Generation: A Survey of LLM-based Active Learning , author=. 2025 , eprint=
2025
-
[64]
2023 , eprint=
LLMaAA: Making Large Language Models as Active Annotators , author=. 2023 , eprint=
2023
-
[65]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[66]
Educ Psychol Meas , volume=
A coefficient of agreement for nominal scale , author=. Educ Psychol Meas , volume=
-
[67]
X-boundary: Establishing exact safety boundary to shield llms from multi-turn jailbreaks without compromising usability , author=. arXiv preprint arXiv:2502.09990 , year=
-
[68]
Steering dialogue dynamics for robustness against multi-turn jailbreaking attacks , author=. arXiv preprint arXiv:2503.00187 , year=
-
[69]
X-teaming: Multi-turn jailbreaks and defenses with adaptive multi-agents , author=. arXiv preprint arXiv:2504.13203 , year=
-
[70]
2026 , publisher=
Jailbreak Detection Dataset , author=. 2026 , publisher=
2026
-
[71]
Iterative self-tuning llms for enhanced jailbreaking capabilities , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[72]
2019 IEEE symposium on security and privacy (SP) , pages=
Neural cleanse: Identifying and mitigating backdoor attacks in neural networks , author=. 2019 IEEE symposium on security and privacy (SP) , pages=. 2019 , organization=
2019
-
[73]
arXiv preprint arXiv:1904.06472 , year=
A repository of conversational datasets , author=. arXiv preprint arXiv:1904.06472 , year=
-
[74]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Qwen3Guard Technical Report , author=. arXiv preprint arXiv:2510.14276 , year=
work page internal anchor Pith review arXiv
-
[76]
SEMA: Simple yet Effective Learning for Multi-Turn Jailbreak Attacks , author =. 2026 , booktitle =. 2602.06854 , archivePrefix =
-
[77]
2026 , eprint =
Statistical Estimation of Adversarial Risk in Large Language Models under Best-of-N Sampling , author =. 2026 , eprint =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.