Recognition: unknown
MOC-3D: Manifold-Order Consistency for Text-to-3D Generation
Pith reviewed 2026-05-10 15:15 UTC · model grok-4.3
The pith
MOC-3D enforces monotonic CLIP score ordering across views and Riemannian continuity on SPD manifolds to fix view bias and gradient noise in text-to-3D generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
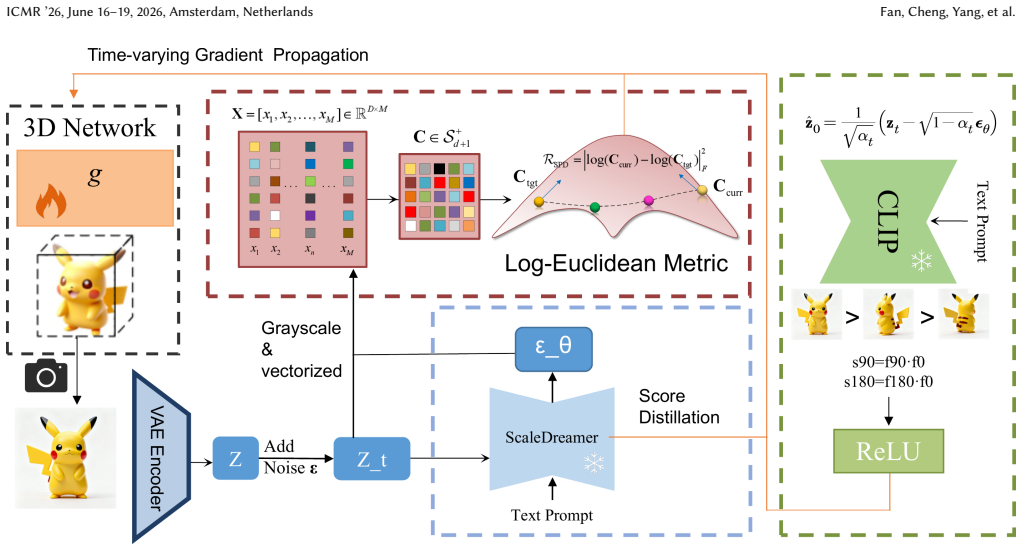
By incorporating a Semantic View-Order Constraint Module that imposes a Monotonicity Rank Constraint on CLIP semantic scores and a Manifold-based Feature Continuity Module that minimizes Riemannian distances between SPD feature distributions, the method achieves simultaneous improvement in macro-structural consistency and micro-detail continuity for text-to-3D generation.
What carries the argument
Semantic View-Order Constraint Module using monotonicity rank constraint on CLIP scores for macro topology and Manifold-based Feature Continuity Module using Riemannian metric on SPD manifolds for micro-texture continuity.
If this is right
- The Semantic View-Order Constraint Module rectifies macro-topological inconsistency such as the Janus problem by providing global topological guidance.
- The Manifold-based Feature Continuity Module eliminates micro-geometric discontinuity by promoting smooth statistical evolution of textures across views.
- The two modules operate synergistically to address both issues simultaneously while remaining compatible with existing 2D diffusion priors.
- The approach maintains the core optimization loop of score distillation sampling but adds explicit consistency terms.
Where Pith is reading between the lines
- The same monotonicity and Riemannian continuity constraints could be tested in related multi-view tasks such as text-to-video or novel-view synthesis.
- Integration with other base frameworks beyond ScaleDreamer would show whether the gains depend on that specific starting point.
- Quantitative evaluation on standard 3D consistency metrics would clarify the practical magnitude of the reported improvements.
Load-bearing premise
Imposing monotonicity on CLIP semantic scores across views and minimizing Riemannian distance on SPD feature distributions will reliably correct view bias and gradient noise without introducing new inconsistencies or slowing convergence.
What would settle it
Generating a 3D model from the prompt 'a single cat' and observing multiple faces or abrupt texture jumps when rotating the model around its vertical axis would falsify the claim of improved macro and micro consistency.
Figures


read the original abstract
With the burgeoning development of fields such as the Metaverse, Virtual Reality (VR), and Digital Twins, text-to-3D generation has emerged as a research hotspot in both academia and industry. Currently, optimization methods based on Score Distillation Sampling (SDS) utilizing 2D diffusion priors have become the mainstream technological paradigm in this field. However, due to the view bias of 2D priors and the mode-seeking ambiguity combined with gradient noise induced by high Classifier-Free Guidance (CFG), these methods still suffer from macro-topological inconsistency (e.g., the Janus problem) and micro-geometric discontinuity. To address these challenges, we propose MOC-3D, a text-to-3D generation method based on geometric manifold and semantic view-order consistency. Built upon the ScaleDreamer framework, our method incorporates a Semantic View-Order Constraint Module and a Manifold-based Feature Continuity Module. The former aims to rectify macro-topological inconsistency, while the latter focuses on eliminating micro-geometric discontinuity. Specifically, the Semantic View-Order Constraint Module leverages the prior knowledge of CLIP to impose a Monotonicity Rank Constraint on semantic score representations across different views, thereby providing effective guidance for the global topological structure of 3D objects. Meanwhile, the Manifold-based Feature Continuity Module employs the Riemannian Metric on the Symmetric Positive Definite (SPD) manifold. By measuring the distance of feature statistical distributions in the Riemannian space, it promotes the smooth evolution and continuity of micro-textures across multi-views in a statistical sense. Under the macro-micro synergistic optimization of these two modules, our model can simultaneously improve macro-structural consistency and micro-detail continuity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MOC-3D, a text-to-3D generation method built on the ScaleDreamer framework. It introduces a Semantic View-Order Constraint Module that imposes a monotonicity rank constraint on CLIP semantic scores across multiple views to address macro-topological inconsistencies (e.g., Janus problem) arising from view bias in 2D diffusion priors, and a Manifold-based Feature Continuity Module that measures Riemannian distances between feature distributions on the Symmetric Positive Definite (SPD) manifold to enforce micro-geometric continuity and reduce discontinuity from gradient noise and high CFG. The central claim is that joint optimization of these modules yields simultaneous improvements in structural consistency and detail continuity.
Significance. If the modules deliver the claimed improvements without new inconsistencies or convergence issues, the work would offer a lightweight, prior-based correction to longstanding limitations in SDS-based text-to-3D pipelines. The combination of semantic ordering with manifold geometry is a coherent extension of existing techniques and could be adopted in other view-consistent generation settings.
major comments (3)
- [§3.2] §3.2 (Semantic View-Order Constraint): the monotonicity rank constraint is defined on CLIP scores, but the manuscript does not demonstrate that this ordering is preserved under the SDS gradient updates or that it does not introduce new view-dependent biases when the underlying 2D prior itself is inconsistent.
- [§3.3] §3.3 and Eq. (7) (Manifold-based Feature Continuity): the Riemannian distance is applied to SPD feature covariances, yet the paper provides no ablation isolating the contribution of the manifold metric versus a Euclidean baseline, leaving open whether the claimed micro-continuity gain is due to the geometry or simply to additional regularization.
- [§4.2] §4.2 (Experiments): quantitative metrics for macro-consistency (e.g., multi-view CLIP score variance or topological error) and micro-continuity (e.g., texture variance across views) are reported, but the tables do not include statistical significance tests or comparisons against recent concurrent methods that also target Janus and discontinuity, weakening the cross-method claim.
minor comments (3)
- [§3.3] Notation for the SPD manifold distance should be introduced once with an explicit reference to the chosen Riemannian metric (affine-invariant or log-Euclidean).
- [Figure 3] Figure 3 caption should clarify whether the visualized features are before or after the manifold projection.
- [Abstract and §4.1] The abstract states the method is 'parameter-free' in its constraints, but the implementation section lists two additional weighting hyperparameters; this minor inconsistency should be resolved.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed review and the recommendation of minor revision. The comments are helpful in improving the manuscript's rigor. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Semantic View-Order Constraint): the monotonicity rank constraint is defined on CLIP scores, but the manuscript does not demonstrate that this ordering is preserved under the SDS gradient updates or that it does not introduce new view-dependent biases when the underlying 2D prior itself is inconsistent.
Authors: We appreciate this valid concern. The Semantic View-Order Constraint Module applies the monotonicity rank constraint dynamically at each optimization iteration based on the CLIP scores of the rendered views at that step. This ensures that the constraint influences the SDS gradient updates in real-time to promote consistent ordering. While a formal proof of invariance under all possible updates is beyond the scope, our experimental results in Section 4.2 show that the optimized 3D assets achieve lower multi-view CLIP score variance, indicating effective preservation of the ordering without introducing additional biases. To further clarify this, we will add a plot or discussion in the revised manuscript illustrating the constraint's behavior during training. revision: partial
-
Referee: [§3.3] §3.3 and Eq. (7) (Manifold-based Feature Continuity): the Riemannian distance is applied to SPD feature covariances, yet the paper provides no ablation isolating the contribution of the manifold metric versus a Euclidean baseline, leaving open whether the claimed micro-continuity gain is due to the geometry or simply to additional regularization.
Authors: Thank you for highlighting this. We chose the Riemannian metric on the SPD manifold because it respects the geometric structure of covariance matrices, which is more appropriate than Euclidean distance for measuring distribution similarities in feature space. However, we agree that an explicit ablation is necessary to isolate its effect. In the revised version, we will include an ablation study replacing the Riemannian distance with a Euclidean counterpart while keeping other components fixed, demonstrating the specific benefits of the manifold geometry for micro-geometric continuity. revision: yes
-
Referee: [§4.2] §4.2 (Experiments): quantitative metrics for macro-consistency (e.g., multi-view CLIP score variance or topological error) and micro-continuity (e.g., texture variance across views) are reported, but the tables do not include statistical significance tests or comparisons against recent concurrent methods that also target Janus and discontinuity, weakening the cross-method claim.
Authors: We acknowledge this point. The current experiments focus on comparisons with the base ScaleDreamer and other established baselines, showing consistent improvements. To address the lack of statistical tests, we will perform and report significance tests (e.g., paired t-tests) on the quantitative metrics in the updated tables. Additionally, we will incorporate comparisons with more recent concurrent methods addressing similar issues, such as those improving view consistency in text-to-3D, to better contextualize our contributions. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper defines MOC-3D as an extension of the external ScaleDreamer framework by adding two explicitly constructed modules: a Semantic View-Order Constraint that imposes monotonicity on CLIP scores across views, and a Manifold-based Feature Continuity module that minimizes Riemannian distance on SPD feature distributions. The claimed macro-micro improvement is presented as the outcome of jointly optimizing these additions to address view bias and gradient noise; no equation or step reduces the final consistency gain to a fitted parameter or prior result by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from the authors' prior work appear in the provided text. The derivation remains self-contained as a design proposal whose performance claims are left for empirical validation rather than being tautological.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CLIP embeddings yield monotonic semantic scores that can be ranked to enforce global topological consistency
- domain assumption Riemannian metric on the SPD manifold provides a statistically meaningful distance for multi-view feature continuity
Reference graph
Works this paper leans on
-
[1]
Vincent Arsigny, Pierre Fillard, Xavier Pennec, et al. 2006. Log-Euclidean metrics for fast and simple calculus on diffusion tensors.Magnetic Resonance in Medicine 56, 2 (2006), 411–421
2006
-
[2]
Peter J Basser, James Mattiello, and Denis LeBihan. 1994. MR diffusion tensor spectroscopy and imaging.Biophysical Journal66, 1 (1994), 259–267
1994
-
[3]
Eric R Chan, Koki Nagano, Matthew A Chan, et al . 2023. Generative Novel View Synthesis with 3D-Aware Diffusion Models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, Paris, France, 4217– 4229
2023
- [4]
-
[5]
Rui Chen, Yongwei Chen, Ning Jiao, et al . 2023. Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, Paris, France, 22189–22199
2023
- [6]
-
[7]
Li Ding, Shaocong Dong, Zhaoyu Huang, et al . 2024. Text-to-3D generation with bidirectional diffusion using both 2D and 3D priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, WA, USA, 5115–5124
2024
-
[8]
R. Gao, A. Holynski, P. Henzler, et al . 2024. CAT3D: Create Anything in 3D with Multi-View Diffusion Models. InProceedings of the Thirty-Eighth Confer- ence on Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., Vancouver, BC, Canada, 1–15
2024
-
[9]
R. Gao, A. Holynski, P. Henzler, et al. 2025. CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Nashville, TN, USA, 1–10
2025
- [10]
-
[11]
Yicong Hong, Kai Zhang, Jiatao Gu, et al . 2024. 3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, WA, USA, 1–10
2024
-
[12]
Yicong Hong, Kai Zhang, Jiatao Gu, et al. 2024. LRM: Large Reconstruction Model for Single Image to 3D. InProceedings of the International Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria, 1–15
2024
-
[13]
H. Hu, T. Yin, F. Luan, et al. 2025. Turbo3D: Ultra-fast Text-to-3D Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Nashville, TN, USA, 1–10
2025
-
[14]
Huang, B
Y. Huang, B. Liao, Y. Hu, et al. 2025. DaCapo: Score Distillation as Stacked Bridge for Fast and High-quality 3D Editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Nashville, TN, USA, 1–10
2025
-
[15]
Zhiwu Huang and Luc Van Gool. 2017. A Riemannian Network for SPD Matrix Learning. InProceedings of the AAAI Conference on Artificial Intelligence. AAAI Press, San Francisco, CA, USA, 2036–2042
2017
-
[16]
Ajay Jain, Matthew Tancik, and Pieter Abbeel. 2021. DietNeRF: Monocular Neural Radiance Fields with Semantic Consistency. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, Montreal, QC, Canada, 12267–12276
2021
- [17]
-
[18]
W. Li, R. Chen, X. Chen, et al. 2024. SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Text-to-3D. InProceedings of the International Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria, 1–15
2024
-
[19]
Yixun Liang, Xin Yang, Jiaming Lin, et al. 2024. Luciddreamer: Towards high- fidelity text-to-3D generation via interval score matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, WA, USA, 6517–6526
2024
-
[20]
Tang, et al
Chen-Hsuan Lin, Jun Gao, L. Tang, et al. 2023. Magic3D: High-Resolution Text- to-3D Content Creation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Vancouver, BC, Canada, 300–309
2023
-
[21]
Yiwei Ma, Ying He, Kaushik Kundu, et al. 2024. ScaleDreamer: A Scalable and Efficient Framework for High-Quality Text-to-3D Generation. InProceedings of the International Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria, 1–15
2024
-
[22]
Gal Metzer, Elad Richardson, Or Patashnik, et al. 2023. Latent-NeRF for shape- guided generation of 3D shapes and textures. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Vancouver, BC, Canada, 12663–12673
2023
-
[23]
Thomas Müller, Alex Evans, Christoph Schied, et al. 2022. Instant neural graphics primitives with a multiresolution hash encoding.ACM Transactions on Graphics (TOG)41, 4 (2022), 102:1–102:15
2022
-
[24]
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, et al . 2022. Point-E: A Sys- tem for Generating 3D Point Clouds from Complex Prompts.arXiv preprint arXiv:2212.08751abs/2212.08751, 1 (2022), 1–10
work page internal anchor Pith review arXiv 2022
-
[25]
Xavier Pennec, Pierre Fillard, and Nicholas Ayache. 2006. A Riemannian frame- work for tensor computing.International Journal of Computer Vision66, 1 (2006), 41–66
2006
-
[26]
Ben Poole, Ajay Jain, Jonathan T Barron, et al. 2023. DreamFusion: Text-to-3D using 2D Diffusion. InProceedings of the International Conference on Learning Representations (ICLR). OpenReview.net, Kigali, Rwanda, 1–15
2023
-
[27]
Y. Qin, Z. Xu, and Y. Liu. 2025. Apply Hierarchical-Chain-of-Generation to Com- plex Attributes Text-to-3D Generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Nashville, TN, USA, 1–10
2025
-
[28]
L. Qiu, G. Chen, X. Gu, et al. 2024. RichDreamer: A generalizable normal-depth diffusion model for detail richness in text-to-3D. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, WA, USA, 9914–9925
2024
-
[29]
Rodriguez, et al
Dario Rossi, Barbara Roessle, A.L. Rodriguez, et al. 2022. PeRF: Pose-Free Neural Radiance Fields. InProceedings of the European Conference on Computer Vision (ECCV). Springer, Tel Aviv, Israel, 416–433
2022
-
[30]
Yichun Shi, Peng Wang, Jianglong Ye, et al. 2024. MVDream: Multi-view Diffusion for 3D Generation. InProceedings of the International Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria, 1–15
2024
- [31]
-
[32]
Jiaxiang Tang, Jiawei Ren, Hang Zhou, et al . 2024. LGM: Large multi-view gaussian model for high-resolution 3d content creation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, WA, USA, 4353–4364
2024
- [33]
-
[34]
Oncel Tuzel, Fatih Porikli, and Peter Meer. 2006. Region Covariance: A Fast Descriptor for Detection and Classification. InProceedings of the European Con- ference on Computer Vision (ECCV). Springer, Graz, Austria, 589–600
2006
-
[35]
Haochen Wang, Xiaodan Du, Jiahao Li, et al . 2023. Score Jacobian Chaining: Lifting Pretrained 2D Diffusion Models for 3D Generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Vancouver, BC, Canada, 12619–12629
2023
-
[36]
Zhengyi Wang, Cheng Lu, Yiming Wang, et al . 2023. ProlificDreamer: High- Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. InProceedings of the Thirty-Seventh Conference on Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., New Orleans, LA, USA, 25779–25797
2023
-
[37]
Xiang, X
J. Xiang, X. Chen, S. Xu, et al . 2025. Structured 3D Latents for Scalable and Versatile 3D Generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Nashville, TN, USA, 1–10
2025
- [38]
- [39]
-
[40]
Lior Yariv, Jiatao Gu, Yoni Kasten, et al. 2021. Volume rendering of neural implicit surfaces. InProceedings of the Thirty-Fifth Conference on Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., Online, 4805–4815
2021
-
[41]
Richard Zhang, Phillip Isola, Alexei A Efros, et al . 2018. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Salt Lake City, UT, USA, 586–595
2018
-
[42]
Zhang and L
Y. Zhang and L. Chen. 2025. LEGO-Maker: A Semantic-Driven Algorithm for Text-to-3D Generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, San Diego, CA, USA, 1–10
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.