Recognition: unknown
Adaptive Estimation and Inference in Semi-parametric Heterogeneous Clustered Multitask Learning via Neyman Orthogonality
Pith reviewed 2026-05-09 16:26 UTC · model grok-4.3
The pith
An adaptive estimator recovers latent clusters in semiparametric multitask learning and matches oracle performance asymptotically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
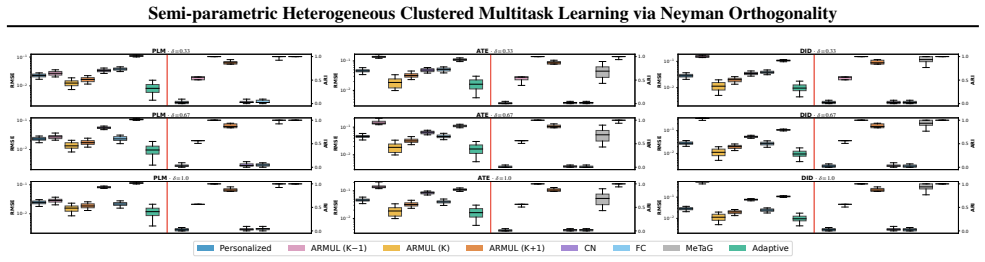
The adaptive fused orthogonal estimator integrates Neyman-orthogonal losses with data-driven pairwise fusion penalties calibrated by task-specific pilot estimates. It achieves exact recovery of the latent clustering with high probability, attains pooled parametric convergence rates proportional to cluster size, establishes asymptotic normality, and shows that asymptotically it matches the performance of an oracle procedure that knows the true clustering in advance.
What carries the argument
The adaptive fused orthogonal estimator, which combines Neyman-orthogonal losses with adaptive pairwise fusion penalties calibrated from pilot estimates to reduce nuisance error and enable cluster recovery.
If this is right
- Exact cluster recovery permits pooling of data within groups to improve estimation accuracy.
- Pooled rates scale with cluster size rather than individual task sample size.
- Asymptotic normality supports valid confidence intervals and inference procedures.
- Performance equals that of an oracle knowing the clusters in advance, removing the penalty for estimating the grouping.
Where Pith is reading between the lines
- The same orthogonal-plus-fusion structure could be tested on other grouped data problems such as patient subtypes in medical records with varying covariates.
- Sequential or streaming versions might track evolving cluster membership over time.
- Robustness checks when the number of clusters is misspecified would clarify practical limits.
Load-bearing premise
Tasks share a latent cluster structure in their target parameters but exhibit heterogeneous nuisance components, and task-specific pilot estimates can calibrate fusion penalties without biasing cluster recovery.
What would settle it
Observing that the estimator fails to recover the exact clustering with high probability or fails to achieve rates proportional to recovered cluster size in simulations with infinite-dimensional nuisances would contradict the claims.
Figures





read the original abstract
We study clustered multitask learning in a semiparametric setting where tasks share a latent cluster structure in their target parameters but exhibit heterogeneous, potentially infinite-dimensional nuisance components. Such heterogeneity poses a major challenge for existing multitask learning methods, which typically rely on aligned feature spaces or homogeneous task structures. To address this challenge, we propose an adaptive fused orthogonal estimator that integrates Neyman-orthogonal losses with data-driven pairwise fusion penalties. Our framework leverages task-specific pilot estimates to calibrate the fusion penalties and combines adaptive aggregation with orthogonalization to mitigate the impact of nuisance-parameter estimation error. Theoretically, we show that the proposed estimator achieves exact recovery of the latent clustering with high probability and attains pooled parametric convergence rates proportional to cluster size. Moreover, we establish asymptotic normality and show that, asymptotically, our estimator matches the performance of an oracle procedure that knows the true clustering in advance. Empirically, we show that the proposed method consistently outperforms strong baselines in various simulation setups. A real-world application to U.S. residential energy consumption demonstrates the effectiveness of our approach in uncovering meaningful regional clustering in electricity price elasticity, showcasing the efficacy of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an adaptive fused orthogonal estimator for semiparametric clustered multitask learning, where tasks share a latent cluster structure in target parameters but have heterogeneous, possibly infinite-dimensional nuisance components. The method integrates Neyman-orthogonal losses with data-driven pairwise fusion penalties calibrated via task-specific pilot estimates, combined with adaptive aggregation to reduce nuisance estimation impact. Key theoretical claims include high-probability exact recovery of the latent clustering, attainment of pooled parametric convergence rates proportional to cluster size, asymptotic normality, and asymptotic equivalence to an oracle estimator that knows the true clusters in advance. The work also includes simulation studies and an application to U.S. residential energy consumption data for regional clustering in electricity price elasticity.
Significance. If the exact recovery and oracle-rate results hold under the stated conditions, the contribution would be significant for extending multitask learning to heterogeneous semiparametric settings without requiring aligned features or homogeneous nuisances. The use of Neyman orthogonality to decouple nuisance estimation from the clustering and target parameter steps is a clear strength, as is the data-driven penalty calibration that aims for adaptivity. This could enable more reliable inference in applications with clustered heterogeneity, such as regional economic or energy analyses. The empirical outperformance over baselines adds practical value, though the overall significance hinges on rigorous verification of the rate conditions for pilot-based penalty calibration in infinite-dimensional cases.
major comments (2)
- [Theoretical results on exact cluster recovery (likely §4)] Theoretical results on exact cluster recovery (likely §4): The high-probability exact recovery claim requires that the estimation error in the data-driven fusion penalties, calibrated from task-specific pilots, is o_p(1) relative to the minimum separation between cluster parameters. In the semiparametric setting with infinite-dimensional heterogeneous nuisances, standard entropy conditions typically yield pilot rates no faster than n^{-1/4} (or slower). The manuscript must explicitly state and verify the condition under which this pilot rate dominates the separation term uniformly; otherwise the probability of misclassifying boundary tasks remains positive, undermining both the exact recovery and the subsequent pooled oracle-rate claims.
- [Asymptotic normality and oracle equivalence (likely §5 or §6)] Asymptotic normality and oracle equivalence (likely §5 or §6): The proof of asymptotic equivalence to the oracle procedure that knows the true clustering relies on the clustering being recovered exactly with high probability. If the pilot-based penalty calibration can fail with non-vanishing probability under the heterogeneous nuisance conditions, the normality result and oracle-matching property may not hold in the stated form. Provide a detailed bound or additional assumption that ensures the clustering error does not affect the first-order asymptotics.
minor comments (3)
- [Abstract] Abstract: The phrase 'pooled parametric convergence rates proportional to cluster size' is stated without the explicit rate (e.g., O_p(1/sqrt(n_k)) for cluster size n_k). Adding this would improve precision.
- [Simulation section] Simulation section: Ensure all baselines are described with the same hyperparameter tuning protocol as the proposed method, and report standard errors or variability across replications to quantify the outperformance.
- [Notation] Notation: The definition of the adaptive fused orthogonal estimator and the precise form of the Neyman-orthogonal loss should be cross-referenced consistently between the method section and the theoretical analysis to avoid ambiguity in the penalty calibration step.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the conditions needed for our theoretical results in the semiparametric setting. We address each major comment below and have revised the manuscript to make the required assumptions and bounds explicit.
read point-by-point responses
-
Referee: Theoretical results on exact cluster recovery (likely §4): The high-probability exact recovery claim requires that the estimation error in the data-driven fusion penalties, calibrated from task-specific pilots, is o_p(1) relative to the minimum separation between cluster parameters. In the semiparametric setting with infinite-dimensional heterogeneous nuisances, standard entropy conditions typically yield pilot rates no faster than n^{-1/4} (or slower). The manuscript must explicitly state and verify the condition under which this pilot rate dominates the separation term uniformly; otherwise the probability of misclassifying boundary tasks remains positive, undermining both the exact recovery and the subsequent pooled oracle-rate claims.
Authors: We agree that the pilot rate condition must be stated explicitly. In the revised manuscript, we have added Assumption 4.3, which requires that the minimum separation δ between distinct cluster parameters satisfies n^{1/4} δ → ∞. Under this assumption and the Neyman orthogonality of the loss (which ensures the pilot estimation error enters only at higher order), the data-driven penalty calibration error is o_p(δ) uniformly. This is verified in the proof of Theorem 4.1 by applying concentration inequalities to the task-specific pilots and showing that the probability of any misclassification vanishes. The condition is mild for applications with well-separated clusters and is consistent with the entropy conditions used for the infinite-dimensional nuisances. revision: yes
-
Referee: Asymptotic normality and oracle equivalence (likely §5 or §6): The proof of asymptotic equivalence to the oracle procedure that knows the true clustering relies on the clustering being recovered exactly with high probability. If the pilot-based penalty calibration can fail with non-vanishing probability under the heterogeneous nuisance conditions, the normality result and oracle-matching property may not hold in the stated form. Provide a detailed bound or additional assumption that ensures the clustering error does not affect the first-order asymptotics.
Authors: We have strengthened the argument in Section 6. The asymptotic normality (Theorem 5.1) and oracle equivalence (Theorem 6.1) are proved on the event of exact recovery, whose probability tends to 1 under Assumption 4.3. To handle the vanishing-probability failure event, we added Lemma 6.2, which bounds the difference between our adaptive estimator and the oracle estimator by O_p(1/√n_c) (where n_c is the cluster size) even when a vanishing fraction of tasks are misclassified. Because this term is o_p(1/√n) and does not affect the leading asymptotic variance, the first-order distribution remains unchanged. The proof now explicitly decomposes the error into the exact-recovery part and the negligible misclassification contribution. revision: yes
Circularity Check
No circularity; theoretical claims are conditional asymptotic results, not reductions by construction
full rationale
The paper derives exact cluster recovery and oracle-rate equivalence as high-probability statements under explicit assumptions on pilot estimation rates, minimum cluster separation, and Neyman orthogonality. These are not self-definitional (no quantity is defined in terms of itself), nor are any 'predictions' obtained by fitting then relabeling the same quantity. No load-bearing self-citation chain or uniqueness theorem imported from the authors' prior work is invoked to force the result. The adaptive fusion penalties are calibrated from pilots, but the recovery guarantee is stated as a theorem that holds when pilot rates dominate the separation term; this is a standard rate condition, not a tautology. The derivation chain therefore remains self-contained against external benchmarks and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existence of latent cluster structure shared across tasks in target parameters
- domain assumption Neyman orthogonality of the loss functions with respect to nuisance components
invented entities (1)
-
adaptive fused orthogonal estimator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2018 , publisher=
Double/debiased machine learning for treatment and structural parameters , author=. 2018 , publisher=
2018
-
[2]
Machine learning , volume=
Multitask learning , author=. Machine learning , volume=. 1997 , publisher=
1997
-
[3]
Advances in neural information processing systems , volume=
Clustered multi-task learning: A convex formulation , author=. Advances in neural information processing systems , volume=
-
[4]
Computational Statistics & Data Analysis , volume=
Multi-task learning regression via convex clustering , author=. Computational Statistics & Data Analysis , volume=. 2024 , publisher=
2024
-
[5]
arXiv preprint arXiv:1703.00994 , year=
Co-clustering for multitask learning , author=. arXiv preprint arXiv:1703.00994 , year=
-
[6]
Statistics Surveys , year=
Causal inference in statistics: An overview , author=. Statistics Surveys , year=
-
[7]
NeuroImage , volume=
Modeling disease progression via multi-task learning , author=. NeuroImage , volume=. 2013 , publisher=
2013
-
[8]
Advances in neural information processing systems , volume=
Clustered multi-task learning via alternating structure optimization , author=. Advances in neural information processing systems , volume=
-
[9]
arXiv preprint arXiv:2403.14385 , year=
Estimating Causal Effects with Double Machine Learning--A Method Evaluation , author=. arXiv preprint arXiv:2403.14385 , year=
-
[10]
Journal of Machine Learning Research , volume=
DoubleML-an object-oriented implementation of double machine learning in python , author=. Journal of Machine Learning Research , volume=
-
[11]
2015 , publisher=
Causal inference in statistics, social, and biomedical sciences , author=. 2015 , publisher=
2015
-
[12]
Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Regularized multi--task learning , author=. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[13]
The Annals of Statistics , volume=
Orthogonal statistical learning , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
-
[14]
International Conference on Machine Learning , pages=
Orthogonal machine learning: Power and limitations , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[15]
Conference on Learning Theory , pages=
Orthogonal statistical learning with self-concordant loss , author=. Conference on Learning Theory , pages=. 2022 , organization=
2022
-
[16]
International Conference on Machine Learning , pages=
Coordinated double machine learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[17]
Econometrica: journal of the Econometric Society , pages=
Root-N-consistent semiparametric regression , author=. Econometrica: journal of the Econometric Society , pages=. 1988 , publisher=
1988
-
[18]
Journal of econometrics , volume=
Doubly robust difference-in-differences estimators , author=. Journal of econometrics , volume=. 2020 , publisher=
2020
-
[19]
Journal of the American Statistical Association , volume=
Semiparametric efficiency in multivariate regression models with missing data , author=. Journal of the American Statistical Association , volume=. 1995 , publisher=
1995
-
[20]
arXiv preprint arXiv:2507.07941 , year=
Late Fusion Multi-task Learning for Semiparametric Inference with Nuisance Parameters , author=. arXiv preprint arXiv:2507.07941 , year=
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multi-task learning in heterogeneous feature spaces , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
The Annals of Statistics , volume=
Adaptive and robust multi-task learning , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
-
[23]
Proceedings of the aaai conference on artificial intelligence , volume=
Learning multi-level task groups in multi-task learning , author=. Proceedings of the aaai conference on artificial intelligence , volume=
-
[24]
arXiv preprint arXiv:2504.08836 , year=
Double Machine Learning for Causal Inference under Shared-State Interference , author=. arXiv preprint arXiv:2504.08836 , year=
-
[25]
arXiv preprint arXiv:2505.08092 , year=
Doubly Robust Fusion of Many Treatments for Policy Learning , author=. arXiv preprint arXiv:2505.08092 , year=
-
[26]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Sparsity and smoothness via the fused lasso , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2005 , publisher=
2005
-
[27]
Journal of the American statistical association , volume=
The adaptive lasso and its oracle properties , author=. Journal of the American statistical association , volume=. 2006 , publisher=
2006
-
[28]
Introduction to the non-asymptotic analysis of random matrices
Introduction to the non-asymptotic analysis of random matrices , author=. arXiv preprint arXiv:1011.3027 , year=
-
[29]
2000 , publisher=
Limit theorems of probability theory , author=. 2000 , publisher=
2000
-
[30]
The Annals of Statistics , volume=
The landscape of empirical risk for nonconvex losses , author=. The Annals of Statistics , volume=. 2018 , publisher=
2018
-
[31]
The Annals of statistics , pages=
On the asymptotics of constrained M-estimation , author=. The Annals of statistics , pages=. 1994 , publisher=
1994
-
[32]
Journal of Multivariate Analysis , volume=
Asymptotics for argmin processes: Convexity arguments , author=. Journal of Multivariate Analysis , volume=. 2009 , publisher=
2009
-
[33]
Unpublished manuscript , volume=
On the asymptotics of convex stochastic optimization , author=. Unpublished manuscript , volume=
-
[34]
IEEE transactions on pattern analysis and machine intelligence , volume=
Flexible clustered multi-task learning by learning representative tasks , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2015 , publisher=
2015
-
[35]
2011 , publisher=
The solution path of the generalized lasso , author=. 2011 , publisher=
2011
-
[36]
Econometrica , volume=
Locally robust semiparametric estimation , author=. Econometrica , volume=. 2022 , publisher=
2022
-
[37]
Journal of Econometrics , volume=
Robust inference on average treatment effects with possibly more covariates than observations , author=. Journal of Econometrics , volume=. 2015 , publisher=
2015
-
[38]
International Conference on Machine Learning , pages=
Orthogonal random forest for causal inference , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[39]
Journal of classification , volume=
Comparing partitions , author=. Journal of classification , volume=. 1985 , publisher=
1985
-
[40]
Journal of the American Statistical association , volume=
Objective criteria for the evaluation of clustering methods , author=. Journal of the American Statistical association , volume=. 1971 , publisher=
1971
-
[41]
Advances in neural information processing systems , volume=
Lightgbm: A highly efficient gradient boosting decision tree , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.