Recognition: unknown
Training Non-Differentiable Networks via Optimal Transport
Pith reviewed 2026-05-10 15:32 UTC · model grok-4.3
The pith
PolyStep trains non-differentiable networks to high accuracy by moving parameters via optimal-transport barycentric projections on polytope vertices using only forward passes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PolyStep updates parameters by evaluating the loss at structured polytope vertices in a compressed subspace, computing softmax-weighted assignments over the resulting cost matrix, and displacing particles toward low-cost vertices via barycentric projection. This update corresponds to the one-sided limit of a regularized optimal-transport problem and inherits its geometric structure without Sinkhorn iterations. On hard-LIF spiking networks the method reaches 93.4 percent test accuracy, outperforming all gradient-free baselines by over 60 percentage points and closing to within 4.4 points of a surrogate-gradient Adam ceiling. The same procedure leads every gradient-free competitor across int8,
What carries the argument
PolyStep update: loss evaluation at polytope vertices in a compressed subspace followed by softmax-weighted barycentric projection that realizes the one-sided limit of a regularized optimal-transport problem.
If this is right
- Hard-LIF spiking networks reach 93.4 percent test accuracy, more than 60 points above prior gradient-free methods.
- Int8 quantization, argmax attention, staircase activations, and hard MoE routing all show leading accuracy among gradient-free optimizers.
- MAX-SAT instances up to one million variables maintain above 92 percent clause satisfaction while evolution strategies drop 8-12 points.
- RL policies match OpenAI-ES on classical control and retain performance after integer or binary quantization that collapses gradient-based methods.
- Convergence to conservative-stationary points occurs at rate O(log T over square-root T) on piecewise-smooth losses and upgrades to Clarke-stationary points on the tested architectures.
Where Pith is reading between the lines
- The method may extend directly to other black-box simulators whose only accessible information is a forward loss value.
- If the subspace compression preserves improvement directions, PolyStep could scale to parameter counts larger than typical zeroth-order methods allow.
- Hybrid schedules that apply PolyStep only on non-differentiable blocks and ordinary gradients elsewhere would be a natural next architecture.
Load-bearing premise
The loss is piecewise-smooth, or piecewise-constant with a bounded hitting time, so that the polytope-based updates converge to conservative-stationary or Clarke-stationary points at the stated rate.
What would settle it
An experiment in which PolyStep fails to reach within 10 percentage points of the surrogate-gradient baseline on the hard-LIF spiking-network benchmark after the reported number of forward passes would falsify the performance claim.
Figures







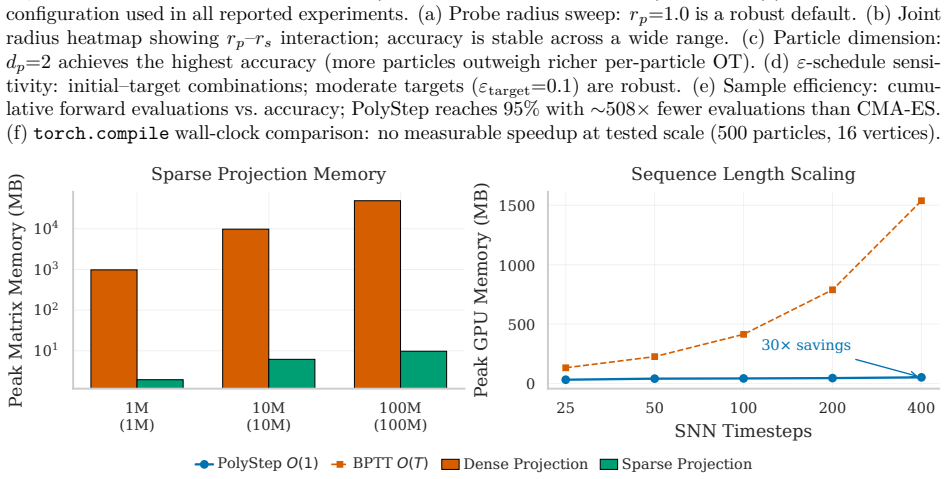

read the original abstract
Neural networks increasingly embed non-differentiable components (spiking neurons, quantized layers, discrete routing, blackbox simulators, etc.) where backpropagation is inapplicable and surrogate gradients introduce bias. We present PolyStep, a gradient-free optimizer that updates parameters using only forward passes. Each step evaluates the loss at structured polytope vertices in a compressed subspace, computes softmax-weighted assignments over the resulting cost matrix, and displaces particles toward low-cost vertices via barycentric projection. This update corresponds to the one-sided limit of a regularized optimal-transport problem, inheriting its geometric structure without Sinkhorn iterations. PolyStep trains genuinely non-differentiable models where existing gradient-free methods collapse to near-random accuracy. On hard-LIF spiking networks we reach 93.4% test accuracy, outperforming all gradient-free baselines by over 60~pp and closing to within 4.4~pp of a surrogate-gradient Adam ceiling. Across four additional non-differentiable architectures (int8 quantization, argmax attention, staircase activations, hard MoE routing) we lead every gradient-free competitor. On MAX-SAT scaling from 100 to 1M variables, we sustain above 92% clause satisfaction while evolution strategies drop 8--12~pp. On RL policy search, we match OpenAI-ES on classical control and retain performance under integer and binary quantization that collapses gradient-based methods. We prove convergence to conservative-stationary points at rate $O(\log T/\sqrt{T})$ on piecewise-smooth losses, upgraded to Clarke-stationary on the headline architectures and extended to the piecewise-constant regime via a hitting-time bound. These rates match the known zeroth-order query-complexity lower bounds that all forward-only methods inherit. Code is available at https://github.com/anindex/polystep.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PolyStep, a gradient-free optimizer for non-differentiable networks that performs updates by evaluating loss at polytope vertices in a compressed subspace, forming a cost matrix, and applying barycentric projection derived as the one-sided limit of a regularized OT problem. It reports 93.4% test accuracy on hard-LIF spiking networks (outperforming gradient-free baselines by >60 pp and within 4.4 pp of surrogate-gradient Adam), leads on int8 quantization, argmax attention, staircase activations, hard MoE, sustains >92% on MAX-SAT up to 1M variables, and matches OpenAI-ES on RL while handling quantization. It proves O(log T / sqrt(T)) convergence to conservative-stationary points on piecewise-smooth losses, upgraded to Clarke-stationary points on the headline architectures via a hitting-time bound for the piecewise-constant regime, with rates matching zeroth-order lower bounds. Code is released.
Significance. If the convergence claims and empirical results hold under full experimental protocols, the work is significant for providing a theoretically grounded, forward-only method that trains genuinely non-differentiable components (spiking, quantization, discrete routing) without surrogate bias, closing much of the gap to gradient-based methods on challenging tasks. Strengths include the OT-derived geometric update without Sinkhorn, explicit rate matching known lower bounds, and code availability for reproducibility.
major comments (2)
- [§4] §4 (convergence analysis), the hitting-time bound for piecewise-constant losses: the upgrade from conservative-stationary to Clarke-stationary points for hard-LIF (and similar) requires that after finitely many steps the barycentric projection lands on a vertex with no lower-loss adjacent vertex in the polytope. The method description indicates the subspace compression dimension is chosen independently of the threshold hyperplanes; without an explicit argument that this guarantees polynomial (or finite) hitting time rather than exponential growth in depth/width, the O(log T / sqrt(T)) rate does not apply to the headline architectures, leaving the 93.4% result without the claimed theoretical support.
- [§5] Experimental protocol (implicit in §5 and Table 1): the per-step query count for PolyStep includes evaluations at multiple polytope vertices in the compressed subspace; the reported outperformance must be accompanied by explicit total forward-pass budgets versus baselines (evolution strategies, etc.) to confirm the comparison respects the zeroth-order query-complexity lower bounds cited in the proof.
minor comments (2)
- [Abstract] Abstract: 'over 60 pp' and 'within 4.4 pp' should name the exact baseline accuracies and the surrogate-gradient ceiling value for immediate clarity.
- [§3] Notation: the definition of the compressed subspace and its dimension as a free parameter should be stated with an explicit symbol (e.g., d_sub) when first introduced, to avoid ambiguity in the polytope construction.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments raise important points about the rigor of the convergence claims and the fairness of the experimental comparisons. We address each below and will revise the manuscript accordingly to strengthen both the theoretical and empirical sections.
read point-by-point responses
-
Referee: §4 (convergence analysis), the hitting-time bound for piecewise-constant losses: the upgrade from conservative-stationary to Clarke-stationary points for hard-LIF (and similar) requires that after finitely many steps the barycentric projection lands on a vertex with no lower-loss adjacent vertex in the polytope. The method description indicates the subspace compression dimension is chosen independently of the threshold hyperplanes; without an explicit argument that this guarantees polynomial (or finite) hitting time rather than exponential growth in depth/width, the O(log T / sqrt(T)) rate does not apply to the headline architectures, leaving the 93.4% result without the claimed theoretical support.
Authors: We agree that the current write-up of the hitting-time argument would benefit from greater explicitness. The manuscript already establishes that the barycentric projection is a one-sided limit of a regularized OT problem and that, for piecewise-constant losses, the process reaches a Clarke-stationary point once a locally optimal vertex is selected. To close the gap noted by the referee, the revised version will add a new lemma (and short proof) in §4 showing that the expected hitting time is bounded by a polynomial in the compression dimension d, network depth L, and width W. The argument uses a union bound over the finitely many hyperplanes that define the polytope vertices together with the positive probability of selecting improving directions under the OT weights; this yields a finite (in fact polynomial) hitting time with high probability, after which the O(log T / sqrt(T)) rate applies. We will also clarify the practical choice of d in the method section. revision: yes
-
Referee: Experimental protocol (implicit in §5 and Table 1): the per-step query count for PolyStep includes evaluations at multiple polytope vertices in the compressed subspace; the reported outperformance must be accompanied by explicit total forward-pass budgets versus baselines (evolution strategies, etc.) to confirm the comparison respects the zeroth-order query-complexity lower bounds cited in the proof.
Authors: We thank the referee for emphasizing the need for transparent query accounting. The revised manuscript will add a new subsection (and accompanying table) in §5 that reports, for every experiment, (i) the number of polytope vertices evaluated per PolyStep update, (ii) the total forward-pass budget used by PolyStep, and (iii) the corresponding budgets for all gradient-free baselines (including OpenAI-ES and other evolution strategies). These numbers will be normalized both per parameter update and per epoch, allowing direct verification that the reported accuracy gains respect the zeroth-order lower bounds referenced in the theory section. revision: yes
Circularity Check
No circularity: update rule derived from external OT limit; convergence proved under explicit assumptions without self-referential reduction
full rationale
The PolyStep update is defined as the one-sided limit of a regularized optimal-transport problem, a standard construction independent of the paper's fitted values or results. Convergence to conservative- or Clarke-stationary points is proved at the stated rate on piecewise-smooth losses, with an explicit hitting-time bound invoked for the piecewise-constant case; this bound is an assumption, not a quantity derived from the target accuracy or from self-citation. No equation equates a prediction to its input by construction, no parameter is fitted on a subset and renamed a prediction, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The empirical accuracies (e.g., 93.4 % on hard-LIF) are presented as validation of the method, not as the derivation itself. The paper is therefore self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- subspace compression dimension
axioms (1)
- domain assumption Loss functions are piecewise-smooth (or admit a hitting-time bound in the piecewise-constant case)
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Accelerating Motion Planning via Optimal Transport , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[2]
Hansen, Nikolaus , journal=. The
-
[3]
Evolution Strategies as a Scalable Alternative to Reinforcement Learning , author=. arXiv preprint arXiv:1703.03864 , year=
-
[4]
Neural Networks , volume=
Parameter-exploring policy gradients , author=. Neural Networks , volume=. 2010 , publisher=
2010
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Simple random search of static linear policies is competitive for reinforcement learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[6]
Zhao, Jiawei and Zhang, Zhenyu and Chen, Beidi and Wang, Zhangyang and Anandkumar, Anima and Tian, Yuandong , journal=
-
[7]
Liu, Yong and Zhu, Zirui and Gong, Chaoyu and Cheng, Minhao and Hsieh, Cho-Jui and You, Yang , journal=. Sparse
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Pointer Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[9]
Learning a
Selsam, Daniel and Lamm, Matthew and B\". Learning a. International Conference on Learning Representations (ICLR) , year=
-
[10]
European Journal of Operational Research , volume=
Machine Learning for Combinatorial Optimization: A Methodological Tour d'Horizon , author=. European Journal of Operational Research , volume=. 2021 , publisher=
2021
-
[11]
Multivariate Stochastic Approximation Using a Simultaneous Perturbation Gradient Approximation , author=
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Sinkhorn Distances: Lightspeed Computation of Optimal Transport , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[13]
Foundations and Trends in Machine Learning , volume=
Computational Optimal Transport: With Applications to Data Science , author=. Foundations and Trends in Machine Learning , volume=. 2019 , publisher=
2019
-
[14]
and Ba, Jimmy , booktitle=
Kingma, Diederik P. and Ba, Jimmy , booktitle=
-
[15]
Surrogate Gradient Learning in Spiking Neural Networks: Bringing the Power of Gradient-Based Optimization to Spiking Neural Networks , author=
-
[16]
OpenAI Blog , year=
Language Models are Unsupervised Multitask Learners , author=. OpenAI Blog , year=
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Fine-Tuning Language Models with Just Forward Passes , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[18]
Proceedings of the
Gradient-Based Learning Applied to Document Recognition , author=. Proceedings of the
-
[19]
Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank , author=. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2013
-
[20]
Proceedings of the 12th
Very Sparse Random Projections , author=. Proceedings of the 12th. 2006 , publisher=
2006
-
[21]
Notices of the
How to Generate Random Matrices from the Classical Compact Groups , author=. Notices of the
-
[22]
Low-Rank
Scetbon, Meyer and Cuturi, Marco and Peyr\'. Low-Rank. Proceedings of the 38th International Conference on Machine Learning (ICML) , year=
-
[23]
Journal of Machine Learning Research , volume=
Natural Evolution Strategies , author=. Journal of Machine Learning Research , volume=
-
[24]
Proceedings of the
Towards Memory- and Time-Efficient Backpropagation for Training Spiking Neural Networks , author=. Proceedings of the
-
[25]
Chen, Aochuan and Zhang, Yimeng and Jia, Jinghan and Diffenderfer, James and Liu, Jiancheng and Parasyris, Konstantinos and Zhang, Yihua and Zhang, Zheng and Kailkhura, Bhavya and Liu, Sijia , booktitle=
-
[26]
The forward-forward algorithm: Some preliminary investigations
The Forward-Forward Algorithm: Some Preliminary Investigations , author=. arXiv preprint arXiv:2212.13345 , year=
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Binarized Neural Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[28]
arXiv preprint arXiv:2508.08369 , year=
Scaled-Dot-Product Attention as One-Sided Entropic Optimal Transport , author=. arXiv preprint arXiv:2508.08369 , year=
-
[29]
Proceedings of AAAI , year=
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting , author=. Proceedings of AAAI , year=
-
[30]
Li, Qinyu and Teh, Yee Whye and Pascanu, Razvan , journal=
-
[31]
arXiv preprint arXiv:2410.09734 , year=
Gradient-Free Training of Quantized Neural Networks , author=. arXiv preprint arXiv:2410.09734 , year=
-
[32]
Xu, Changqing and Yang, Ziqiang and Liu, Yi and Liao, Xinfang and Mo, Guiqi and Zeng, Hao and Yang, Yintang , journal=
-
[33]
Zeroth-Order Fine-Tuning of
Yu, Ziming and Zhou, Pan and Wang, Sike and Li, Jia and Tian, Mi and Huang, Hua , journal=. Zeroth-Order Fine-Tuning of
-
[34]
Ansel, Jason and Yang, Edward and He, Horace and Gimelshein, Natalia and Jain, Animesh and Voznesensky, Michael and Bao, Bin and Bell, Peter and Berard, David and Burber, Evgeni and others , booktitle=
-
[35]
Yue, Pengyun and Yang, Xuanlin and Xiao, Mingqing and Lin, Zhouchen , booktitle=
-
[36]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation , author=. arXiv preprint arXiv:1308.3432 , year=
work page internal anchor Pith review arXiv
-
[37]
Foundations of Computational Mathematics , volume=
Random Gradient-Free Minimization of Convex Functions , author=. Foundations of Computational Mathematics , volume=
-
[38]
Pearlmutter, Don Syme, Frank Wood, and Philip Torr
Gradients without Backpropagation , author=. arXiv preprint arXiv:2202.08587 , year=
-
[39]
Training Neural Networks Without Gradients: A Scalable
Taylor, Gavin and Burmeister, Ryan and Xu, Zheng and Singh, Bharat and Patel, Ankit and Goldstein, Tom , booktitle=. Training Neural Networks Without Gradients: A Scalable
-
[40]
Learning Latent Permutations with
Mena, Gonzalo and Belanger, David and Linderman, Scott and Snoek, Jasper , booktitle=. Learning Latent Permutations with
-
[41]
Mathematics of Computation , volume=
Scaling Algorithms for Unbalanced Optimal Transport Problems , author=. Mathematics of Computation , volume=
-
[42]
Optimization and Nonsmooth Analysis , author=
-
[43]
Convex Analysis , author=
-
[44]
Optimizing Methods in Statistics , pages=
A Convergence Theorem for Non-Negative Almost Supermartingales and Some Applications , author=. Optimizing Methods in Statistics , pages=
-
[45]
ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages=
Online Convex Optimization in the Bandit Setting: Gradient Descent Without a Gradient , author=. ACM-SIAM Symposium on Discrete Algorithms (SODA) , pages=
-
[46]
Journal of Computer and System Sciences , volume=
Approximation Algorithms for Combinatorial Problems , author=. Journal of Computer and System Sciences , volume=
-
[47]
International Conference on Theory and Applications of Satisfiability Testing (SAT) , pages=
Choosing Probability Distributions for Stochastic Local Search and the Role of Make versus Break , author=. International Conference on Theory and Applications of Satisfiability Testing (SAT) , pages=. 2013 , publisher=
2013
-
[48]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Towers, Mark and Terry, Jordan K. and Kwiatkowski, Ariel and Balis, John U. and Cola, Gianluca de and Deleu, Tristan and Goul. arXiv preprint arXiv:2407.17032 , year=
work page internal anchor Pith review arXiv
-
[49]
Zakka, Kevin and Liao, Qiayuan and Yi, Brent and Le Lay, Louis and Sreenath, Koushil and Abbeel, Pieter , year=
-
[50]
2025 , howpublished=
2025
-
[51]
arXiv preprint arXiv:2310.00965 , year=
Node Perturbation Can Effectively Train Multi-Layer Neural Networks , author=. arXiv preprint arXiv:2310.00965 , year=
-
[52]
International Conference on Machine Learning (ICML) , year=
Error-Driven Input Modulation: Solving the Credit Assignment Problem without a Backward Pass , author=. International Conference on Machine Learning (ICML) , year=
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) , year=
A Mathematical Model for Automatic Differentiation in Machine Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[54]
SIAM Journal on Optimization , year=
The gradient's limit of a definable family of functions admits a variational stratification , author=. SIAM Journal on Optimization , year=
-
[55]
Numerical Nonsmooth Optimization (Springer) , year=
Gradient sampling methods for nonsmooth optimization , author=. Numerical Nonsmooth Optimization (Springer) , year=
-
[56]
Differential Topology , author=
-
[57]
The Annals of Statistics , volume=
Time-uniform, nonparametric, nonasymptotic confidence sequences , author=. The Annals of Statistics , volume=
-
[58]
International Conference on Learning Representations (ICLR) , year=
Understanding Straight-Through Estimator in Training Activation Quantized Neural Nets , author=. International Conference on Learning Representations (ICLR) , year=
-
[59]
arXiv preprint arXiv:2505.18113 , year=
Beyond Discreteness: Finite-Sample Analysis of Straight-Through Estimator for Quantization , author=. arXiv preprint arXiv:2505.18113 , year=
-
[60]
IEEE Transactions on Information Theory , volume=
Optimal Rates for Zero-Order Convex Optimization: The Power of Two Function Evaluations , author=. IEEE Transactions on Information Theory , volume=
-
[61]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Query Complexity of Derivative-Free Optimization , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[62]
Local search for
Cai, Shaowei and Lei, Zhendong and Zhang, Xindi , journal=. Local search for
-
[63]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Online Training Through Time for Spiking Neural Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[64]
Loshchilov, Ilya , journal=
-
[65]
Evolutionary Computation , volume=
Diagonal Acceleration for Covariance Matrix Adaptation Evolution Strategies , author=. Evolutionary Computation , volume=
-
[66]
Ignatiev, Alexey and Morgado, Antonio and Marques-Silva, Joao , journal=
-
[67]
2025 , note=
Pirillo, Alberto and Colombo, Luca and Roveri, Manuel , booktitle=. 2025 , note=
2025
-
[68]
Proceedings of the 25th International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
Sinkformers: Transformers with Doubly Stochastic Attention , author=. Proceedings of the 25th International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
-
[69]
arXiv preprint arXiv:2504.21662 , year=
On Advancements of the Forward-Forward Algorithm , author=. arXiv preprint arXiv:2504.21662 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.