Recognition: unknown
RamanBench: A Large-Scale Benchmark for Machine Learning on Raman Spectroscopy
Pith reviewed 2026-05-09 17:19 UTC · model grok-4.3
The pith
RamanBench unifies 74 datasets to show tabular foundation models beat domain-specific methods on Raman spectra yet no approach generalizes across tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RamanBench assembles 74 datasets (16 newly released) across four domains and applies one evaluation protocol to 28 models; under that protocol tabular foundation models such as TabPFN outperform both Raman-specific networks and gradient-boosting baselines while time-series models like ROCKET remain competitive, but every tested method fails to maintain performance when moved to a different dataset.
What carries the argument
RamanBench, the unified dataset collection plus fixed preprocessing, train-test splits, and scoring code that turns fragmented Raman spectra into directly comparable supervised learning tasks.
If this is right
- Tabular foundation models become the default reference point for new Raman spectroscopy tasks.
- Effort shifts toward architectures that explicitly address cross-dataset shifts in spectral features.
- Time-series methods receive renewed attention as low-cost alternatives for certain spectral patterns.
- The living leaderboard structure lets the community add datasets and close the observed gap over time.
- Reproducible baselines now exist for applications that rely on Raman data such as material identification.
Where Pith is reading between the lines
- If the generalization gap persists, future work may test hybrid models that combine foundation-model pretraining with Raman-specific feature extractors.
- The same benchmark protocol could be reused for related spectroscopic techniques such as infrared or fluorescence data.
- Practical systems may need dataset-specific adaptation layers rather than single universal models.
- Adding more datasets with extreme experimental conditions would test whether the current gap is an artifact of the initial collection.
Load-bearing premise
The 74 chosen datasets and the single preprocessing-plus-split protocol capture enough of the real experimental variability in Raman measurements to support claims of consistent model rankings and a universal generalization gap.
What would settle it
A model that reaches high accuracy on every one of the 74 datasets under the published splits, or a newly collected Raman dataset on which all current top models collapse while a simple baseline succeeds.
Figures




















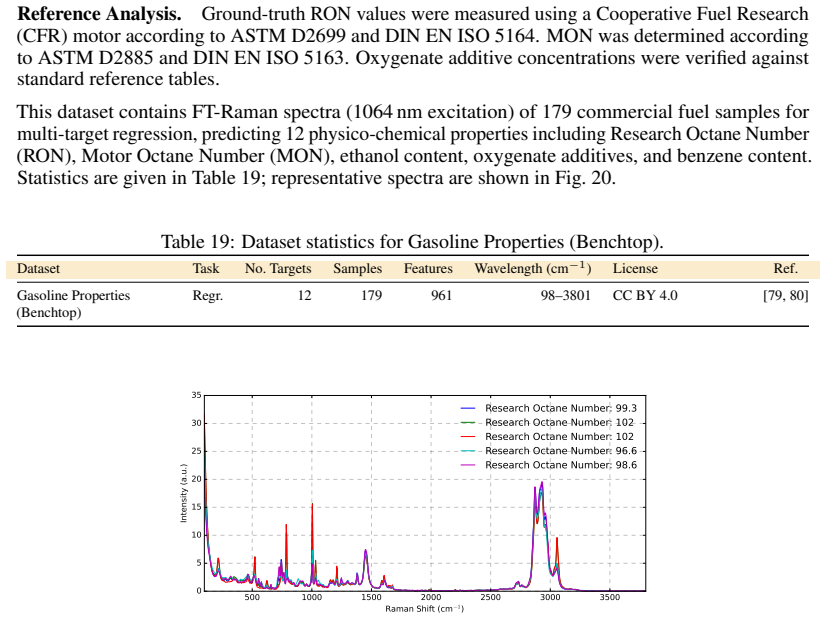
































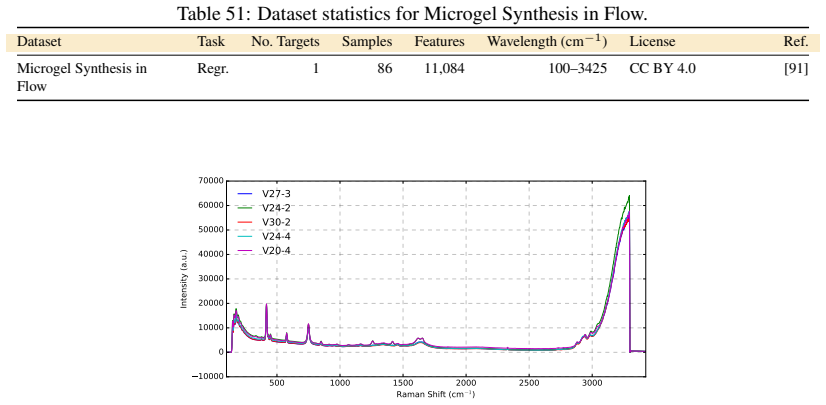


read the original abstract
Machine Learning (ML) has transformed many scientific fields, yet key applications still lack standardized benchmarks. Raman spectroscopy, a widely used technique for non-invasive molecular analysis, is one such field where progress is limited by fragmented datasets, inconsistent evaluation, and models that fail to capture the structure of spectral data. We introduce RamanBench, the first large-scale, fully reproducible benchmark for ML on Raman spectroscopy, consisting of streamlined data access, evaluation protocols and code, as well as a live leaderboard. It unifies 74 datasets (including 16 first released with this benchmark) across four domains, comprising 325,668 spectra and spanning classification and regression tasks under diverse experimental conditions. We benchmark 28 models under a standardized protocol, including classical methods (e.g., PLS), Raman-specific (e.g., RamanNet), Tabular Foundation Model (TFM) (e.g., TabPFN), and time-series approaches (e.g., ROCKET). TFM consistently outperform domain-specific and gradient boosting baselines, while time-series models remain competitive. However, no method generalizes across datasets, revealing a fundamental gap. Therefore, we invite the community to contribute new approaches to our living benchmark, with the potential to accelerate advances in critical applications such as medical diagnostics, biological research, and materials science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RamanBench, the first large-scale reproducible benchmark for machine learning on Raman spectroscopy. It unifies 74 datasets (16 newly released) totaling 325,668 spectra across classification and regression tasks in four domains. Under a single standardized protocol, 28 models are evaluated, including classical (PLS), Raman-specific (RamanNet), Tabular Foundation Models (TFM e.g. TabPFN), and time-series (ROCKET) approaches. The central claims are that TFM consistently outperform domain-specific and gradient-boosting baselines, time-series models remain competitive, and no method generalizes across datasets, revealing a fundamental gap.
Significance. If the protocol and rankings prove robust, RamanBench supplies a much-needed standardized, living evaluation platform with code and leaderboard for a fragmented field. The reported generalization failure, if not an artifact of preprocessing or splitting choices, would be a substantive finding that motivates new inductive biases for spectral data in medical, biological, and materials applications. The release of 16 new datasets and full reproducibility artifacts are clear strengths.
major comments (3)
- [Methods / Evaluation Protocol] Methods / Evaluation Protocol: The single fixed preprocessing pipeline (baseline correction, normalization, peak alignment, train/test splits) is applied uniformly to all 74 datasets with no reported ablation or sensitivity analysis to alternative domain-standard pipelines. Because the headline claims of TFM outperformance and the fundamental cross-dataset generalization gap rest on these rankings, the absence of such checks leaves open the possibility that the observed ordering is protocol-dependent rather than intrinsic.
- [Results] Results: Performance tables and the abstract state clear rankings and a generalization gap, yet no statistical significance tests, error bars, or variance across random seeds / multiple runs are described. Without these, it is impossible to determine whether the reported TFM superiority over baselines is robust or could be explained by implementation or split variability.
- [Evaluation Protocol / Results] Cross-dataset evaluation: The claim that 'no method generalizes across datasets' is central, but the manuscript does not specify the exact cross-dataset protocol (e.g., leave-one-dataset-out, meta-learning splits, or per-task train/test ratios) or the quantitative threshold used to declare failure of generalization. This detail is load-bearing for the 'fundamental gap' conclusion.
minor comments (2)
- [Abstract / §1] Abstract and §1: The total number of models (28) and the breakdown into categories (classical, Raman-specific, TFM, time-series) should be stated consistently; minor mismatches between abstract and main text reduce clarity.
- [Dataset description] Dataset table: Ensure every one of the 74 datasets has a clear citation or permanent link in the benchmark release; a few entries appear to rely only on internal identifiers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which highlights both the strengths of RamanBench and areas where additional clarity and analysis would strengthen the work. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: The single fixed preprocessing pipeline (baseline correction, normalization, peak alignment, train/test splits) is applied uniformly to all 74 datasets with no reported ablation or sensitivity analysis to alternative domain-standard pipelines. Because the headline claims of TFM outperformance and the fundamental cross-dataset generalization gap rest on these rankings, the absence of such checks leaves open the possibility that the observed ordering is protocol-dependent rather than intrinsic.
Authors: We selected the preprocessing pipeline to reflect a consensus approach commonly used in Raman spectroscopy studies, thereby enabling reproducible and comparable results across the 74 datasets. We agree that sensitivity to alternative pipelines is a relevant consideration. In the revised manuscript we will expand the methods section with an explicit rationale for the chosen pipeline and add a limited sensitivity analysis on a representative subset of datasets using two alternative domain-standard pipelines. revision: partial
-
Referee: Performance tables and the abstract state clear rankings and a generalization gap, yet no statistical significance tests, error bars, or variance across random seeds / multiple runs are described. Without these, it is impossible to determine whether the reported TFM superiority over baselines is robust or could be explained by implementation or split variability.
Authors: We acknowledge that reporting variability and statistical tests would improve the robustness assessment of the reported rankings. In the revised version we will recompute all results with multiple random seeds, include error bars (standard deviation) in the performance tables, and add paired statistical significance tests (e.g., Wilcoxon signed-rank) between the leading models and baselines. revision: yes
-
Referee: The claim that 'no method generalizes across datasets' is central, but the manuscript does not specify the exact cross-dataset protocol (e.g., leave-one-dataset-out, meta-learning splits, or per-task train/test ratios) or the quantitative threshold used to declare failure of generalization. This detail is load-bearing for the 'fundamental gap' conclusion.
Authors: We will add a precise description of the cross-dataset evaluation protocol, including the training and testing splits across datasets and the quantitative criteria used to identify generalization failure, to the evaluation protocol subsection of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark with direct held-out measurements
full rationale
This is a pure empirical benchmarking paper that unifies 74 datasets, applies one fixed preprocessing and evaluation protocol, and reports model rankings on held-out splits. The claims (TFM outperformance, competitive time-series models, and absence of cross-dataset generalization) are direct experimental outcomes measured against independent test data rather than any derivation, equation, or self-referential fit. No self-citation is used to justify a uniqueness theorem or ansatz, and no prediction is constructed from parameters fitted to the same quantities being reported. The protocol choices are explicit and falsifiable by re-running on alternative pipelines, satisfying the criteria for a self-contained empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vibrational spectroscopy and its future applications in microbiology.Applied Spectroscopy Reviews, 58(2):132–158, 2023
Miia Marika Jansson, Martin Kögler, Sohvi Hörkkö, Tero Ala-Kokko, and Lassi Rieppo. Vibrational spectroscopy and its future applications in microbiology.Applied Spectroscopy Reviews, 58(2):132–158, 2023
2023
-
[2]
Barbara Lafuente, Robert T Downs, Hexiong Yang, and Nate Stone. 1. the power of databases: The rruff project. InHighlights in mineralogical crystallography, pages 1–30. De Gruyter (O), 2015
2015
-
[3]
The role of raman spectroscopy in biopharmaceuticals from development to manufacturing.Analytical and Bioanalytical Chemistry, 414(2):969–991, 2022
Karen A Esmonde-White, Maryann Cuellar, and Ian R Lewis. The role of raman spectroscopy in biopharmaceuticals from development to manufacturing.Analytical and Bioanalytical Chemistry, 414(2):969–991, 2022
2022
-
[4]
Rapid identification of pathogenic bacteria using raman spectroscopy and deep learning.Nature communications, 10 (1):4927, 2019
Chi-Sing Ho, Neal Jean, Catherine A Hogan, Lena Blackmon, Stefanie S Jeffrey, Mark Holodniy, Niaz Banaei, Amr AE Saleh, Stefano Ermon, and Jennifer Dionne. Rapid identification of pathogenic bacteria using raman spectroscopy and deep learning.Nature communications, 10 (1):4927, 2019
2019
-
[5]
An integrated computational pipeline for machine learning-driven diagnosis based on raman spectra of saliva samples.Computers in Biology and Medicine, 171:108028, 2024
Dario Bertazioli, Marco Piazza, Cristiano Carlomagno, Alice Gualerzi, Marzia Bedoni, and Enza Messina. An integrated computational pipeline for machine learning-driven diagnosis based on raman spectra of saliva samples.Computers in Biology and Medicine, 171:108028, 2024
2024
-
[6]
Open-source raman spectra of chemical compounds for active pharmaceutical ingredient development.Scientific Data, 12(1):498, 2025
Aaron R Flanagan and Frank G Glavin. Open-source raman spectra of chemical compounds for active pharmaceutical ingredient development.Scientific Data, 12(1):498, 2025
2025
-
[7]
Inline raman spectroscopy and indirect hard modeling for concentration monitoring of dissociated acid species.Applied spectroscopy, 75(5):506–519, 2021
Alexander Echtermeyer, Caroline Marks, Alexander Mitsos, and Jörn Viell. Inline raman spectroscopy and indirect hard modeling for concentration monitoring of dissociated acid species.Applied spectroscopy, 75(5):506–519, 2021
2021
-
[8]
Deep learning for raman spectroscopy: A review.Analytica, 3(3):287–301, 2022
Ruihao Luo, Juergen Popp, and Thomas Bocklitz. Deep learning for raman spectroscopy: A review.Analytica, 3(3):287–301, 2022
2022
-
[9]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data. InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS), 2025. URLhttps://arxiv.org/abs/2506.16791. 10
-
[10]
TALENT: A tabular analytics and learning toolbox.Journal of Machine Learning Research, 26(226):1–16, 2025
Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, Huai-Hong Yin, Tao Zhou, Jun-Peng Jiang, and Han-Jia Ye. TALENT: A tabular analytics and learning toolbox.Journal of Machine Learning Research, 26(226):1–16, 2025
2025
-
[11]
The ucr time series archive.IEEE/CAA Journal of Automatica Sinica, 6(6):1293–1305, 2019
Hoang Anh Dau, Anthony Bagnall, Kaveh Kamgar, Chin-Chia Michael Yeh, Yan Zhu, Shaghayegh Gharghabi, Chotirat Ann Ratanamahatana, and Eamonn Keogh. The ucr time series archive.IEEE/CAA Journal of Automatica Sinica, 6(6):1293–1305, 2019
2019
-
[12]
A., Lines, J., Flynn, M., Large, J., Bostrom, A.,
Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh. The uea multivariate time series classification archive, 2018. arXiv preprint arXiv:1811.00075, 2018
-
[13]
Artificial intelligence-powered raman spectroscopy through open science and fair principles.ACS nano, 19(44):38189–38218, 2025
Nicolas Coca-Lopez, Victor Alcolea-Rodriguez, Miguel A Bañares, Sandor Brockhauser, Julien Gorenflot, Alex Henderson, Ron Hildebrandt, Nina Jeliazkova, Nikolay Kochev, Enrique Lozano Diz, et al. Artificial intelligence-powered raman spectroscopy through open science and fair principles.ACS nano, 19(44):38189–38218, 2025
2025
-
[14]
The fair guiding principles for scientific data management and stewardship
Mark D Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg, Jan-Willem Boiten, Luiz Bonino da Silva Santos, Philip E Bourne, et al. The fair guiding principles for scientific data management and stewardship. Scientific data, 3(1):1–9, 2016
2016
-
[15]
Qiaohao Liang, Shyam Dwaraknath, and Kristin A. Persson. High-throughput computation and evaluation of Raman spectra.Scientific Data, 6:135, 2019. doi: 10.1038/s41597-019-0138-y
-
[16]
Convolutional neural networks as a tool for raman spectral mineral classification under low signal, dusty mars conditions.Earth and Space Science, 9(10):e2021EA002125, 2022
Genesis Berlanga, Quentin Williams, and Nathan Temiquel. Convolutional neural networks as a tool for raman spectral mineral classification under low signal, dusty mars conditions.Earth and Space Science, 9(10):e2021EA002125, 2022
2022
-
[17]
J. Schuetzke, N. J. Szymanski, and M. Reischl. Validating neural networks for spectroscopic classification on a universal synthetic dataset.npj Computational Materials, 9:100, 2023. doi: 10.1038/s41524-023-01055-y
-
[18]
Songlin Lu, Yuanfang Huang, Wan Xiang Shen, Yu Lin Cao, Mengna Cai, Yan Chen, Ying Tan, Yu Yang Jiang, and Yu Zong Chen. Raman spectroscopic deep learning with signal aggregated representations for enhanced cell phenotype and signature identification.PNAS Nexus, 3(8): pgae268, 2024. doi: 10.1093/pnasnexus/pgae268
-
[19]
Ramanspy: An open-source python package for integrative raman spectroscopy data analysis.Analytical chemistry, 96(21):8492–8500, 2024
Dimitar Georgiev, Simon Vilms Pedersen, Ruoxiao Xie, Álvaro Fernández-Galiana, Molly M Stevens, and Mauricio Barahona. Ramanspy: An open-source python package for integrative raman spectroscopy data analysis.Analytical chemistry, 96(21):8492–8500, 2024
2024
-
[20]
Jaume Béjar-Grimalt, Ángel Sánchez-Illana, Guillermo Quintás, Hugh J. Byrne, and David Pérez-Guaita. Monte Carlo peaks: Simulated datasets to benchmark machine learning algorithms for clinical spectroscopy.Chemometrics and Intelligent Laboratory Systems, 2025. doi: 10.1016/j.chemolab.2025.105548
-
[21]
Deep learning for raman spectroscopy: Benchmarking models for upstream bioprocess monitoring.Measurement, page 118884, 2025
Christoph Lange, Madeline Altmann, Daniel Stors, Simon Seidel, Kyle Moynahan, Linda Cai, Stefan Born, Peter Neubauer, and M Nicolas Cruz Bournazou. Deep learning for raman spectroscopy: Benchmarking models for upstream bioprocess monitoring.Measurement, page 118884, 2025
2025
-
[22]
Christoph Lange, Maxim Borisyak, Martin Kögler, Stefan Born, Andreas Ziehe, Peter Neubauer, and M. Nicolas Cruz Bournazou. Comparing machine learning methods on Raman spectra from eight different spectrometers.Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy, 334:125861, 2025. doi: 10.1016/j.saa.2025.125861
-
[23]
J. Lilek et al. Machine learning of Raman spectroscopic data: Comparison of different validation strategies.Journal of Raman Spectroscopy, 56(9):867–877, 2025. doi: 10.1002/jrs.6842
-
[24]
Zhuo Yang, Jiaqing Xie, Shuaike Shen, Daolang Wang, Yeyun Chen, Ben Gao, Shuzhou Sun, Biqing Qi, Dongzhan Zhou, Lei Bai, et al. Spectrumworld: Artificial intelligence foundation for spectroscopy.arXiv preprint arXiv:2508.01188, 2025. 11
-
[25]
Deep spectral component filtering as a foundation model for spectral analysis demonstrated in metabolic profiling.Nature Machine Intelligence, 7 (5):743–757, 2025
Bingsen Xue, Xinyuan Bi, Zheyi Dong, Yunzhe Xu, Minghui Liang, Xin Fang, Yizhe Yuan, Ruoxi Wang, Shuyu Liu, Rushi Jiao, et al. Deep spectral component filtering as a foundation model for spectral analysis demonstrated in metabolic profiling.Nature Machine Intelligence, 7 (5):743–757, 2025
2025
-
[26]
Adithya Sineesh and Akshita Kamsali. Benchmarking deep learning models for raman spec- troscopy across open-source datasets.arXiv preprint arXiv:2601.16107, 2026
-
[27]
Raman-enabled predictions of pro- tein content and metabolites in biopharmaceutical saccharomyces cerevisiae fermentations
Jeppe Hagedorn, Guilherme Ramos, Miguel Ressurreição, Ernst Broberg Hansen, Michael Sokolov, Carlos Casado Vázquez, and Christos Panos. Raman-enabled predictions of pro- tein content and metabolites in biopharmaceutical saccharomyces cerevisiae fermentations. Engineering in Life Sciences, 24(12):e202400045, 2024
2024
-
[28]
Combining mechanistic modeling and raman spectroscopy for monitoring antibody chromatographic purification.Processes, 7(10): 683, 2019
Fabian Feidl, Simone Garbellini, Martin F Luna, Sebastian V ogg, Jonathan Souquet, Hervé Broly, Massimo Morbidelli, and Alessandro Butté. Combining mechanistic modeling and raman spectroscopy for monitoring antibody chromatographic purification.Processes, 7(10): 683, 2019
2019
-
[29]
Soft modeling: the basic design and some extensions.Systems under indirect observation, Part II, 2:36–37, 1982
Herman Wold. Soft modeling: the basic design and some extensions.Systems under indirect observation, Part II, 2:36–37, 1982
1982
-
[30]
Support-vector networks.Machine learning, 20(3): 273–297, 1995
Corinna Cortes and Vladimir Vapnik. Support-vector networks.Machine learning, 20(3): 273–297, 1995
1995
-
[31]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[32]
Glue: A multi-task benchmark and analysis platform for natural language understanding
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP, pages 353–355, 2018
2018
-
[33]
Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
2022
-
[34]
Walter de Gruyter GmbH & Co KG, 2023
Günter G Hoffmann.Infrared and Raman Spectroscopy: Principles and Applications. Walter de Gruyter GmbH & Co KG, 2023
2023
-
[35]
Carte: pretraining and transfer for tabular learning.arXiv preprint arXiv:2402.16785, 2024
Myung Jun Kim, Léo Grinsztajn, and Gaël Varoquaux. Carte: pretraining and transfer for tabular learning.arXiv preprint arXiv:2402.16785, 2024
-
[36]
Table Foundation Models: on knowledge pre-training for tabular learning, May 2025
Myung Jun Kim, Félix Lefebvre, Gaëtan Brison, Alexandre Perez-Lebel, and Gaël Varoquaux. Table foundation models: on knowledge pre-training for tabular learning.arXiv preprint arXiv:2505.14415, 2025
-
[37]
Rapid identification of staphylococci by raman spectroscopy.Scientific reports, 7(1):14846, 2017
Katarína Rebrošová, Martin Šiler, Ota Samek, Filip R˚ užiˇcka, Silvie Bernatová, Veronika Holá, Jan Ježek, Pavel Zemánek, Jana Sokolová, and Petr Petráš. Rapid identification of staphylococci by raman spectroscopy.Scientific reports, 7(1):14846, 2017
2017
-
[38]
How to pre-process raman spectra for reliable and stable models?Analytica chimica acta, 704(1-2): 47–56, 2011
Thomas Bocklitz, Angela Walter, Katharina Hartmann, Petra Rösch, and Jürgen Popp. How to pre-process raman spectra for reliable and stable models?Analytica chimica acta, 704(1-2): 47–56, 2011
2011
-
[39]
Deep convolutional neural networks for raman spectrum recognition: a unified solution.Analyst, 142(21):4067–4074, 2017
Jinchao Liu, Margarita Osadchy, Lorna Ashton, Michael Foster, Christopher J Solomon, and Stuart J Gibson. Deep convolutional neural networks for raman spectrum recognition: a unified solution.Analyst, 142(21):4067–4074, 2017
2017
-
[40]
Scale-adaptive deep model for bacterial raman spectra identification.IEEE Journal of Biomedical and Health Informatics, 26(1):369–378, 2021
Lin Deng, Yuzhong Zhong, Maoning Wang, Xiujuan Zheng, and Jianwei Zhang. Scale-adaptive deep model for bacterial raman spectra identification.IEEE Journal of Biomedical and Health Informatics, 26(1):369–378, 2021. 12
2021
-
[41]
Ramannet: a generalized neural network architecture for raman spectrum analysis.Neural Computing and Applications, 35(25):18719–18735, 2023
Nabil Ibtehaz, Muhammad EH Chowdhury, Amith Khandakar, Serkan Kiranyaz, M Sohel Rahman, and Susu M Zughaier. Ramannet: a generalized neural network architecture for raman spectrum analysis.Neural Computing and Applications, 35(25):18719–18735, 2023
2023
-
[42]
Ramanformer: A transformer-based quantification approach for raman mixture components.ACS omega, 9(22):23241–23251, 2024
Onur Can Koyun, Reyhan Kevser Keser, Safa Onur Sahin, Damla Bulut, Mustafa Yorulmaz, Veysel Yucesoy, and Behcet Ugur Toreyin. Ramanformer: A transformer-based quantification approach for raman mixture components.ACS omega, 9(22):23241–23251, 2024
2024
-
[43]
Deep learning- based raman spectroscopy qualitative analysis algorithm: A convolutional neural network and transformer approach.Talanta, 275:126138, 2024
Zilong Wang, Yunfeng Li, Jinglei Zhai, Siwei Yang, Biao Sun, and Pei Liang. Deep learning- based raman spectroscopy qualitative analysis algorithm: A convolutional neural network and transformer approach.Talanta, 275:126138, 2024
2024
-
[44]
A self-supervised learning method for raman spectroscopy based on masked autoencoders.Expert Systems with Applications, page 128576, 2025
Pengju Ren, Ri-gui Zhou, and Yaochong Li. A self-supervised learning method for raman spectroscopy based on masked autoencoders.Expert Systems with Applications, page 128576, 2025
2025
-
[45]
Tabpfn: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second. InInternational Conference on Learning Representations, 2023
2023
-
[46]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tab- ular foundation model.Nature, 637(8045):319–326, 2025. doi: 10.1038/s41586-024-08328-6
-
[47]
TabICL: A tabular foundation model for in-context learning on large data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data. InInternational Conference on Machine Learning, 2025
2025
-
[48]
Tabiclv2: A better, faster, scalable, and open tabular foundation model, 2026
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139, 2026
-
[49]
Rocket: exceptionally fast and accurate time series classification using random convolutional kernels.Data Mining and Knowledge Discovery, 34(5):1454–1495, 2020
Angus Dempster, Petitjean François, and Geoffrey I Webb. Rocket: exceptionally fast and accurate time series classification using random convolutional kernels.Data Mining and Knowledge Discovery, 34(5):1454–1495, 2020
2020
-
[50]
Hive-cote 2.0: a new meta ensemble for time series classification.Machine Learning, 110(11):3211–3243, 2021
Matthew Middlehurst, James Large, Michael Flynn, Jason Lines, Aaron Bostrom, and Anthony Bagnall. Hive-cote 2.0: a new meta ensemble for time series classification.Machine Learning, 110(11):3211–3243, 2021
2021
-
[51]
Massspecgym: A benchmark for the discovery and identification of molecules.Advances in Neural Information Processing Systems, 37:110010–110027, 2024
Roman Bushuiev, Anton Bushuiev, Niek F de Jonge, Adamo Young, Fleming Kretschmer, Raman Samusevich, Janne Heirman, Fei Wang, Luke Zhang, Kai Dührkop, et al. Massspecgym: A benchmark for the discovery and identification of molecules.Advances in Neural Information Processing Systems, 37:110010–110027, 2024
2024
-
[52]
Toward a unified benchmark and framework for deep learning-based prediction of nuclear magnetic resonance chemical shifts.Nature Computational Science, 5(4):292–300, 2025
Fanjie Xu, Wentao Guo, Feng Wang, Lin Yao, Hongshuai Wang, Fujie Tang, Zhifeng Gao, Linfeng Zhang, Weinan E, Zhong-Qun Tian, et al. Toward a unified benchmark and framework for deep learning-based prediction of nuclear magnetic resonance chemical shifts.Nature Computational Science, 5(4):292–300, 2025
2025
-
[53]
In-line monitoring of microgel synthesis: flow versus batch reactor.Organic Process Research & Development, 25(9):2039–2051, 2021
Luise F Kaven, Hanna JM Wolff, Lukas Wille, Matthias Wessling, Alexander Mitsos, and Joern Viell. In-line monitoring of microgel synthesis: flow versus batch reactor.Organic Process Research & Development, 25(9):2039–2051, 2021
2039
-
[54]
Martin Kögler, Andrea Paul, Emmanuel Anane, Mario Birkholz, Alex Bunker, Tapani Viitala, Michael Maiwald, Stefan Junne, and Peter Neubauer. Comparison of time-gated surface- enhanced raman spectroscopy (tg-sers) and classical sers based monitoring of escherichia coli cultivation samples.Biotechnology progress, 34(6):1533–1542, 2018
2018
-
[55]
Open raman spectral library for biomolecule identification.Chemometrics and Intelligent Laboratory Systems, 264:105476, 2025
Marcelo Terán, José Javier Ruiz, Pablo Loza-Alvarez, David Masip, and David Merino. Open raman spectral library for biomolecule identification.Chemometrics and Intelligent Laboratory Systems, 264:105476, 2025. 13
2025
-
[56]
Dataset of raman and surface-enhanced raman spectroscopy spectra of illicit adulterants added to dietary supplements
Serena Rizzo, Yannick Weesepoel, Sara Erasmus, Joost Sinkeldam, Anna Lisa Piccinelli, and Saskia van Ruth. Dataset of raman and surface-enhanced raman spectroscopy spectra of illicit adulterants added to dietary supplements. 2023
2023
-
[57]
Transfer-learning-based raman spectra identification.Journal of Raman Spectroscopy, 51 (1):176–186, 2020
Rui Zhang, Huimin Xie, Shuning Cai, Yong Hu, Guo-kun Liu, Wenjing Hong, and Zhong-qun Tian. Transfer-learning-based raman spectra identification.Journal of Raman Spectroscopy, 51 (1):176–186, 2020
2020
-
[58]
Ricardo Knauer, Marvin Grimm, and Erik Rodner. Pmlbmini: A tabular classification benchmark suite for data-scarce applications.arXiv preprint arXiv:2409.01635, 2024
-
[59]
Revisiting deep learning models for tabular data.Advances in neural information processing systems, 34: 18932–18943, 2021
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data.Advances in neural information processing systems, 34: 18932–18943, 2021
2021
-
[60]
Rezero is all you need: Fast convergence at large depth
Thomas Bachlechner, Bodhisattwa Prasad Majumder, Henry Mao, Gary Cottrell, and Julian McAuley. Rezero is all you need: Fast convergence at large depth. InUncertainty in artificial intelligence, pages 1352–1361. PMLR, 2021
2021
-
[61]
Tabular data: Is deep learning all you need?arXiv preprint arXiv:2402.03970, 2024
Guri Zabërgja, Arlind Kadra, Christian MM Frey, and Josif Grabocka. Tabular data: Is deep learning all you need?arXiv preprint arXiv:2402.03970, 2024
-
[62]
Coatnet: Marrying convolution and attention for all data sizes.Advances in neural information processing systems, 34:3965–3977, 2021
Zihang Dai, Hanxiao Liu, Quoc V Le, and Mingxing Tan. Coatnet: Marrying convolution and attention for all data sizes.Advances in neural information processing systems, 34:3965–3977, 2021
2021
-
[63]
Xiyuan Zhang, Danielle C Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W Mahoney, et al. Mitra: Mixed synthetic priors for enhancing tabular foundation models.arXiv preprint arXiv:2510.21204, 2025
-
[64]
Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Alex Labach, Hamidreza Kamkari, Jesse C Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L Caterini, and Maksims V olkovs. Tabdpt: Scaling tabular foundation models on real data.arXiv preprint arXiv:2410.18164, 2024
-
[65]
TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling, February 2025
Yury Gorishniy, Akim Kotelnikov, and Artem Babenko. TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling, February 2025. URL http://arxiv.org/ abs/2410.24210. arXiv:2410.24210 [cs]
-
[66]
Classification of deep-sea cold seep bacteria by transformer combined with raman spectroscopy.Scientific Reports, 13(1):3240, 2023
Bo Liu, Kunxiang Liu, Xiaoqing Qi, Weijia Zhang, and Bei Li. Classification of deep-sea cold seep bacteria by transformer combined with raman spectroscopy.Scientific Reports, 13(1):3240, 2023
2023
-
[67]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pedro Larroy, Mu Li, and Alexander Smola. Autogluon-tabular: Robust and accurate automl for structured data.arXiv preprint arXiv:2003.06505, 2020
work page internal anchor Pith review arXiv 2003
-
[68]
TabRepo: A large scale repository of tabular model evalua- tions and its AutoML applications
David Salinas and Nick Erickson. TabRepo: A large scale repository of tabular model evalua- tions and its AutoML applications. InAutoML Conference 2024 (ABCD Track), 2024
2024
-
[69]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
2006
-
[70]
Sara Mostafapour, Thomas Dörfer, Ralf Heinke, Petra Rösch, Jürgen Popp, and Thomas Bocklitz. Investigating the effect of different pre-treatment methods on raman spectra recorded with different excitation wavelengths.Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy, 302:123100, 2023
2023
-
[71]
Amy Brand, Liz Allen, Micah Altman, Marjorie Hlava, and Jo Scott. Beyond authorship: attribution, contribution, collaboration, and credit.Learned Publishing, 28(2):151–155, 2015. doi: https://doi.org/10.1087/20150211. URL https://onlinelibrary.wiley.com/doi/ abs/10.1087/20150211. 14
-
[72]
The proposed uscf rating system, its development, theory, and applications.Chess life, 22(8):242–247, 1967
Arpad E Elo. The proposed uscf rating system, its development, theory, and applications.Chess life, 22(8):242–247, 1967
1967
-
[73]
Steffen Herbold. Autorank: A Python package for automated ranking of classifiers.Journal of Open Source Software, 5(48):2173, 2020. doi: 10.21105/joss.02173
-
[74]
Xception: Deep learning with depthwise separable convolutions
François Chollet. Xception: Deep learning with depthwise separable convolutions. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 1251–1258, 2017
2017
-
[75]
A new ecoc algorithm for multiclass microarray data classification
Mengxin Sun, Kunhong Liu, Qingqi Hong, and Beizhan Wang. A new ecoc algorithm for multiclass microarray data classification. In2018 24th International Conference on Pattern Recognition (ICPR), pages 454–458. IEEE, 2018
2018
-
[76]
A setup for automatic raman measurements in high-throughput experimentation.Biotechnology and Bioengineering, 122 (10):2751–2769, 2025
Christoph Lange, Simon Seidel, Madeline Altmann, Daniel Stors, Annina Kemmer, Linda Cai, Stefan Born, Peter Neubauer, and M Nicolas Cruz Bournazou. A setup for automatic raman measurements in high-throughput experimentation.Biotechnology and Bioengineering, 122 (10):2751–2769, 2025
2025
-
[77]
Application of green analytical chemistry to a green chemistry process: Magnetic resonance and raman spectroscopic process monitoring of continuous ethanolic fermentation
Robin Legner, Alexander Wirtz, Tim Koza, Till Tetzlaff, Anna Nickisch-Hartfiel, and Martin Jaeger. Application of green analytical chemistry to a green chemistry process: Magnetic resonance and raman spectroscopic process monitoring of continuous ethanolic fermentation. Biotechnology and bioengineering, 116(11):2874–2883, 2019
2019
-
[78]
Data augmentation scheme for raman spectra with highly correlated annotations
Christoph Lange, Isabel Thiele, Lara Santolin, Sebastian L Riedel, Maxim Borisyak, Peter Neubauer, and Mariano Nicolas Cruz-Bournazou. Data augmentation scheme for raman spectra with highly correlated annotations. InComputer Aided Chemical Engineering, volume 53, pages 3055–3060. Elsevier, 2024
2024
-
[79]
Melanie V oigt, Robin Legner, Simon Haefner, Anatoli Friesen, Alexander Wirtz, and Martin Jaeger. Using fieldable spectrometers and chemometric methods to determine ron of gasoline from petrol stations: A comparison of low-field 1h nmr@ 80 mhz, handheld raman and benchtop nir.Fuel, 236:829–835, 2019
2019
-
[80]
Robin Legner, Melanie V oigt, Alexander Wirtz, Anatoli Friesen, Simon Haefner, and Martin Jaeger. Using compact proton nuclear magnetic resonance at 80 mhz and vibrational spectro- scopies and data fusion for research octane number and gasoline additive determination.Energy & Fuels, 34(1):103–110, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.