Recognition: 3 theorem links
· Lean TheoremPersonalized Federated Learning for Gradient Alignment
Pith reviewed 2026-05-08 19:28 UTC · model grok-4.3
The pith
pFLAlign aligns local gradients and realigns global models to preserve client-specific information in personalized federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
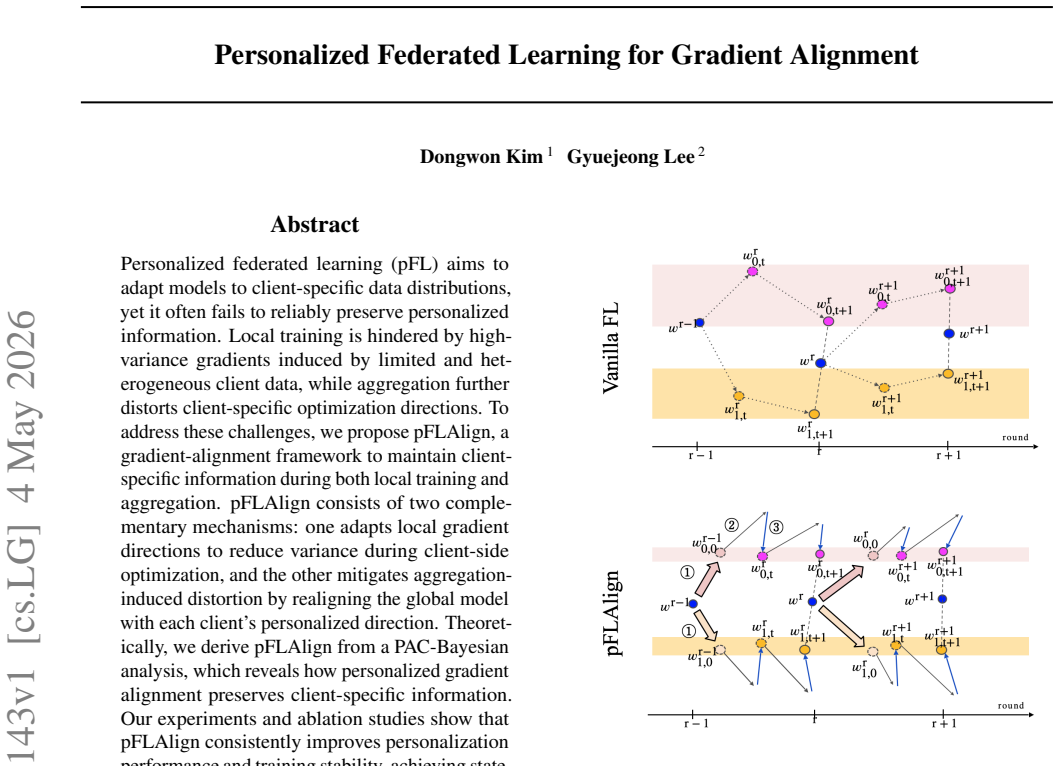
pFLAlign consists of two complementary mechanisms derived from a PAC-Bayesian analysis: adapting local gradient directions to reduce variance during client-side optimization, and mitigating aggregation-induced distortion by realigning the global model with each client's personalized direction. This framework preserves client-specific information throughout training, yielding improved personalization performance and greater training stability.
What carries the argument
The two complementary gradient alignment mechanisms: local adaptation to reduce variance and post-aggregation realignment to match client directions.
If this is right
- Local optimization proceeds with lower gradient variance.
- Aggregation distorts client directions less severely.
- Client-specific information is retained more reliably across rounds.
- Personalization performance exceeds prior federated methods.
- Training stability increases under heterogeneous data conditions.
Where Pith is reading between the lines
- This alignment strategy might reduce the number of communication rounds needed for convergence in heterogeneous settings.
- Similar gradient-direction preservation could apply to other distributed learning tasks beyond federated personalization.
- The PAC-Bayesian grounding might suggest new bounds for analyzing direction loss in aggregation-based methods.
- Testing on real-world non-IID datasets with privacy constraints would clarify practical gains.
Load-bearing premise
That adapting and realigning gradients will maintain client-specific information without adding biases or harming overall model quality.
What would settle it
Experiments on highly heterogeneous client data that show no improvement in client-specific accuracy or increased bias in the aggregated model compared with standard baselines.
Figures


read the original abstract
Personalized federated learning (pFL) aims to adapt models to client specific data distributions, yet it often fails to reliably preserve personalized information. Local training is hindered by high variance gradients induced by limited and heterogeneous client data, while aggregation further distorts client specific optimization directions. To address these challenges, we propose pFLAlign, a gradient alignment framework to maintain client specific information during both local training and aggregation. pFLAlign consists of two complementary mechanisms: one adapts local gradient directions to reduce variance during client side optimization, and the other mitigates aggregation induced distortion by realigning the global model with each client's personalized direction. Theoretically, we derive pFLAlign from a PAC Bayesian analysis, which reveals how personalized gradient alignment preserves client specific information. Our experiments and ablation studies show that pFLAlign consistently improves personalization performance and training stability, achieving state of the art results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes pFLAlign, a gradient alignment framework for personalized federated learning consisting of two complementary mechanisms: one that adapts local gradient directions to reduce variance during client-side optimization, and another that realigns the global model with each client's personalized direction during aggregation. It claims a derivation from PAC-Bayesian analysis showing preservation of client-specific information, along with experimental and ablation results demonstrating consistent improvements in personalization performance, training stability, and state-of-the-art results.
Significance. If the PAC-Bayesian derivation holds and the experiments include proper controls, this could offer a principled approach to mitigating variance and distortion issues in heterogeneous pFL settings, potentially improving reliability of client-specific adaptations over existing methods.
major comments (2)
- [Abstract] Abstract: The claim of deriving pFLAlign from a PAC-Bayesian analysis is presented without any equations, proof sketches, or detailed steps showing how the alignment rules follow from the analysis or preserve client-specific information; this is load-bearing for the theoretical contribution.
- [Experiments] Experiments and ablation studies: The manuscript asserts state-of-the-art results and improved stability but provides no data details, specific metrics, ablation controls, or descriptions of baselines, making it impossible to assess whether gains are robust or free of post-hoc selection.
minor comments (1)
- [Abstract] The abstract could benefit from a one-sentence outline of the key assumptions in the PAC-Bayesian derivation to improve immediate clarity of the theoretical grounding.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and commit to revisions that strengthen the clarity of the theoretical derivation and the transparency of the experimental results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of deriving pFLAlign from a PAC-Bayesian analysis is presented without any equations, proof sketches, or detailed steps showing how the alignment rules follow from the analysis or preserve client-specific information; this is load-bearing for the theoretical contribution.
Authors: We acknowledge that the abstract itself contains no equations or proof steps. The full manuscript derives the two alignment mechanisms in Section 3 from a PAC-Bayesian bound on the client-specific generalization gap; the derivation shows that the local gradient correction reduces the variance term while the aggregation realignment preserves the client posterior mean. To make this contribution self-contained, we will insert a concise proof sketch into the abstract and expand the key steps with explicit equations in the introduction of the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments and ablation studies: The manuscript asserts state-of-the-art results and improved stability but provides no data details, specific metrics, ablation controls, or descriptions of baselines, making it impossible to assess whether gains are robust or free of post-hoc selection.
Authors: We agree that the current experimental section lacks sufficient granularity for independent verification. The manuscript reports results on standard non-IID benchmarks with personalization accuracy and stability metrics, compares against established baselines, and includes ablations isolating each alignment mechanism. In the revision we will add explicit dataset statistics, hyper-parameter tables, full baseline implementation details, numerical values for all reported improvements, and additional ablation controls that vary the strength of each alignment term independently. revision: yes
Circularity Check
Derivation from external PAC-Bayesian analysis is self-contained
full rationale
The paper states that pFLAlign is derived from a standard PAC-Bayesian analysis to show preservation of client-specific information. No equations or steps in the abstract reduce the proposed mechanisms to fitted parameters, self-citations, or renamings by construction. The two alignment mechanisms are presented as outputs of the analysis rather than inputs, and no load-bearing self-citation or ansatz smuggling is indicated. The derivation chain therefore remains independent of the target result.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel (J(x)=½(x+x⁻¹)−1) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
qi = E[gi]^2 / E[gi^2] ... This solution suppresses components dominated by stochastic variance.
-
Foundation.LogicAsFunctionalEquation(no RS analog — standard PAC-Bayes) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EPt∼Qt[R(wk,t)] ≤ EPt∼Qt[R̂nk(wk,t)] + (1/βnk) KL(Qt∥Qt−1) + βC²/2 + (1/βnk) log(1/δ)
-
Cost (J = ½(x+x⁻¹)−1)Jcost_pos_of_ne_one unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
γt ← 0.5 − 0.5 erf(|mt|/√(2(vt−mt²)+ε)) sign(−mt·Δrk)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[2]
Advances in neural information processing systems , volume=
Accelerating stochastic gradient descent using predictive variance reduction , author=. Advances in neural information processing systems , volume=
-
[3]
Decoupled Weight Decay Regularization , author=
-
[4]
Federated Learning Based on Dynamic Regularization , author=
-
[5]
Advances in Neural Information Processing Systems , volume=
Heavy-tailed class imbalance and why adam outperforms gradient descent on language models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Advances in neural information processing systems , volume=
Why transformers need adam: A hessian perspective , author=. Advances in neural information processing systems , volume=
-
[7]
In Search of Adam’s Secret Sauce , author=
-
[8]
arXiv preprint arXiv:2505.12805 , year=
FedSVD: Adaptive Orthogonalization for Private Federated Learning with LoRA , author=. arXiv preprint arXiv:2505.12805 , year=
-
[9]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review arXiv
-
[10]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review arXiv
-
[11]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[12]
Mars: Unleashing the power of variance reduction for training large models , author=. arXiv preprint arXiv:2411.10438 , year=
-
[13]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Towards building the federatedgpt: Federated instruction tuning , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[14]
A Coefficient Makes SVRG Effective , author=
-
[15]
One-Step Generalization Ratio Guided Optimization for Domain Generalization , author=
-
[16]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[17]
Advances in neural information processing systems , volume=
Momentum-based variance reduction in non-convex sgd , author=. Advances in neural information processing systems , volume=
-
[18]
Advances in Neural Information Processing Systems , volume=
Online pac-bayes learning , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
International Conference on Machine Learning , pages=
Dissecting adam: The sign, magnitude and variance of stochastic gradients , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[20]
Improving LoRA in Privacy-preserving Federated Learning , author=
-
[21]
Selective Aggregation for Low-Rank Adaptation in Federated Learning , author=
-
[22]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Beyond Local Sharpness: Communication-Efficient Global Sharpness-aware Minimization for Federated Learning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[23]
FedAdamW: A Communication-Efficient Optimizer with Convergence and Generalization Guarantees for Federated Large Models , author=. arXiv preprint arXiv:2510.27486 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
International conference on machine learning , pages=
Generalized federated learning via sharpness aware minimization , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[25]
Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Openfedllm: Training large language models on decentralized private data via federated learning , author=. Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[26]
Forty-first International Conference on Machine Learning , year=
Position: Will we run out of data? Limits of LLM scaling based on human-generated data , author=. Forty-first International Conference on Machine Learning , year=
-
[27]
Forty-first International Conference on Machine Learning , year=
Rethinking the flat minima searching in federated learning , author=. Forty-first International Conference on Machine Learning , year=
-
[28]
Federated Learning for Feature Generalization with Convex Constraints , author=
-
[29]
Artificial intelligence and statistics , pages=
Communication-efficient learning of deep networks from decentralized data , author=. Artificial intelligence and statistics , pages=. 2017 , organization=
2017
-
[30]
Proceedings of Machine learning and systems , volume=
Federated optimization in heterogeneous networks , author=. Proceedings of Machine learning and systems , volume=
-
[31]
International conference on machine learning , pages=
Scaffold: Stochastic controlled averaging for federated learning , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[32]
International conference on machine learning , pages=
Ditto: Fair and robust federated learning through personalization , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[33]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[34]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[35]
M. J. Kearns , title =
-
[36]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[37]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[38]
Suppressed for Anonymity , author=
-
[39]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[40]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.