SAGA: A Robust Self-Attention and Goal-Aware Anchor-based Planner for Safe UAV Autonomous Navigation
Pith reviewed 2026-05-08 18:44 UTC · model grok-4.3
The pith
SAGA turns a fixed set of motion anchors into tokens, applies self-attention with polar encoding, and selects safe high-speed trajectories for UAVs from depth images in one pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
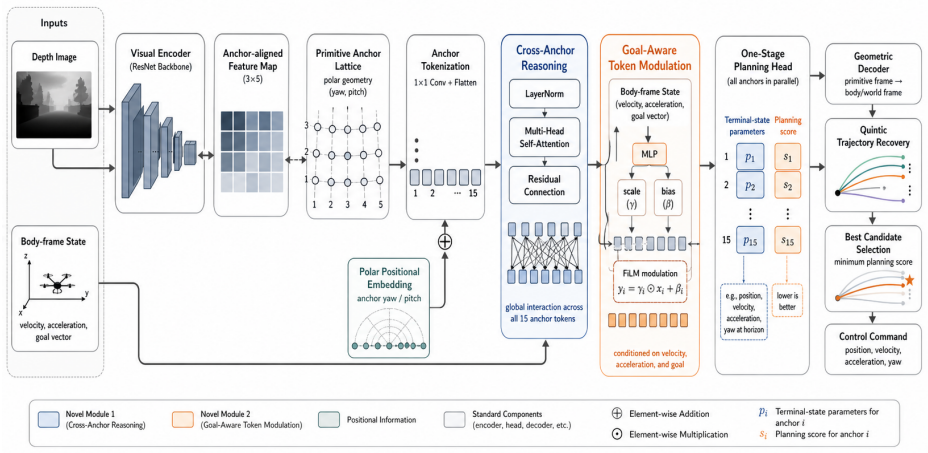
SAGA formulates local planning as a one-stage joint regression-and-ranking problem over a fixed lattice of motion anchors. Given a depth image and a body-frame motion state, the planner predicts refined terminal states and planning scores for all anchors in a single forward pass, after which the best candidate is decoded into a dynamically feasible trajectory. The key idea is to transform anchor-aligned features into geometry-aware tokens and perform cross-anchor global reasoning with self-attention. To preserve directional structure in the token space, polar positional encoding derived from anchor yaw and pitch is introduced. A goal-aware modulation module further injects velocity, target,
What carries the argument
Self-attention performed on geometry-aware tokens produced from anchor-aligned features, augmented by polar positional encoding and goal-aware modulation, that jointly regresses and ranks motion anchors in one forward pass.
If this is right
- SAGA records a 100 percent success rate at maximum speeds of 2, 3, and 4 m/s in cluttered pillar environments where the compared planners drop to between 38 and 90 percent.
- At 4 m/s the method raises average clearance from 1.98 m to 2.39 m and minimum clearance from 0.44 m to 0.76 m relative to the next-best baseline.
- Total flight time drops from 40.5 s to 27.5 s under the same 4 m/s condition.
- Removing the polar positional encoding produces unstable anchor selection and unsafe passages in the same cluttered test scenes.
- All predictions occur inside one network pass, removing the need for separate optimization stages after feature extraction.
Where Pith is reading between the lines
- Because the entire selection process runs in a single forward pass, the architecture could be placed directly on embedded flight controllers that lack the compute for iterative planners.
- The explicit separation of directional encoding from learned features suggests that similar positional schemes could improve attention-based planners that currently ignore yaw or pitch order.
- If the anchor lattice is kept fixed, the method may be extended to other vehicles by retraining only the final modulation layers while retaining the shared attention backbone.
- The reported ablation on polar encoding indicates that any future version without it would need additional mechanisms to restore cross-anchor ordering.
Load-bearing premise
Results measured in simulated pillar-map environments with perfect sensing will continue to hold when the same planner runs on a real UAV that encounters sensor noise, wind, and irregular obstacles.
What would settle it
Run the planner on a physical UAV flying through a real cluttered space at 4 m/s maximum speed and record whether the success rate stays at 100 percent and whether minimum clearance remains above 0.75 m.
Figures






read the original abstract
Agile unmanned aerial vehicle (UAV) navigation in cluttered environments demands a planning architecture that is both computationally efficient and structurally expressive enough to reason over multiple feasible motions. This paper presents SAGA, a robust self-attention and goal-aware anchor-based planner for safe UAV autonomous navigation. SAGA formulates local planning as a one-stage joint regression-and-ranking problem over a fixed lattice of motion anchors. Given a depth image and a body-frame motion state, the planner predicts refined terminal states and planning scores for all anchors in a single forward pass, after which the best candidate is decoded into a dynamically feasible trajectory. The key idea of SAGA is to transform anchor-aligned features into geometry-aware tokens and perform cross-anchor global reasoning with self-attention. To preserve directional structure in the token space, we further introduce a polar positional encoding derived from anchor yaw and pitch. In addition, a goal-aware modulation module injects velocity, acceleration, and target information into the token representation before final score prediction. Experiments in cluttered pillar-map environments under maximum speed settings of 2.0, 3.0, and 4.0~m/s show that SAGA consistently achieves a 100\% success rate, while YOPO drops from 90.91\% to 62.50\%, Ego-planner from 71.43\% to 52.63\%, and Fast-planner from 52.63\% to 38.46\%. Under the 4.0~m/s maximum speed setting, SAGA also improves average safety from 1.9843~m to 2.3888~m and minimum safety from 0.4390~m to 0.7576~m over YOPO, while reducing total flight time from 40.4631~s to 27.4901~s. The comparison with SAGA w/o PPE further shows that explicit polar positional encoding is critical for stable cross-anchor reasoning and safe passage selection in cluttered scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAGA, a self-attention and goal-aware anchor-based planner for UAV navigation in cluttered environments. Local planning is cast as a one-stage joint regression-and-ranking task over a fixed lattice of motion anchors. Given depth images and body-frame states, the network predicts refined terminal states and scores for all anchors in a single forward pass; the best candidate is then decoded into a dynamically feasible trajectory. Key components include transforming anchor-aligned features into geometry-aware tokens, cross-anchor self-attention, a polar positional encoding derived from anchor yaw/pitch, and a goal-aware modulation module that injects velocity, acceleration, and target information. Experiments in simulated pillar-map environments at maximum speeds of 2.0, 3.0, and 4.0 m/s report 100% success rates for SAGA versus declining rates for YOPO, Ego-planner, and Fast-planner, together with gains in average/minimum safety and reduced flight time.
Significance. If the performance claims hold under broader conditions, the architecture offers a computationally efficient alternative to multi-stage or sampling-based planners by performing global cross-anchor reasoning in one pass while preserving directional structure via polar encoding. The explicit ablation on polar positional encoding and the goal-modulation module provide concrete evidence that these additions improve safe passage selection. However, the current significance is tempered by the narrow simulation setting, which limits immediate applicability to real UAV systems.
major comments (2)
- [Abstract / Experiments] Abstract / Experiments: The headline quantitative claims (100% success rate across all tested speeds, average safety rising from 1.9843 m to 2.3888 m, minimum safety from 0.4390 m to 0.7576 m, and flight time dropping from 40.4631 s to 27.4901 s at 4 m/s) are presented without reporting the number of trials, standard deviations, or statistical significance tests. These omissions are load-bearing because the superiority statements rest directly on the magnitude and consistency of the reported deltas versus YOPO, Ego-planner, and Fast-planner.
- [Experimental Setup] Experimental Setup: All results are obtained in idealized pillar-map simulations that supply perfect depth images, regularly spaced cylindrical obstacles, and no sensor noise, wind, or dynamic/irregular obstacles. Because the central robustness claim is that SAGA remains safe at high speeds in cluttered scenes, the absence of distribution-shift tests (e.g., added Gaussian depth noise or wind disturbances) directly weakens the generalization argument that underpins the title and abstract.
minor comments (1)
- [Abstract] Abstract: The phrase 'SAGA w/o PPE' appears without first expanding PPE; the manuscript should define all acronyms on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract / Experiments: The headline quantitative claims (100% success rate across all tested speeds, average safety rising from 1.9843 m to 2.3888 m, minimum safety from 0.4390 m to 0.7576 m, and flight time dropping from 40.4631 s to 27.4901 s at 4 m/s) are presented without reporting the number of trials, standard deviations, or statistical significance tests. These omissions are load-bearing because the superiority statements rest directly on the magnitude and consistency of the reported deltas versus YOPO, Ego-planner, and Fast-planner.
Authors: We agree that the manuscript should report the number of trials, standard deviations, and any relevant statistical information to properly support the quantitative claims. The current version omits these details. In the revised manuscript we will update the abstract and experimental results section to state the number of trials conducted for each speed setting and baseline, and we will add standard deviations for the average safety, minimum safety, and flight time metrics. For success rates, SAGA achieved 100% across the full set of trials at every speed; we will note this consistency explicitly. While formal significance tests were not included originally, the magnitude of the gaps versus the baselines (e.g., 100% versus 38.46%) is large enough that we will add a short discussion of the observed separation. revision: yes
-
Referee: [Experimental Setup] Experimental Setup: All results are obtained in idealized pillar-map simulations that supply perfect depth images, regularly spaced cylindrical obstacles, and no sensor noise, wind, or dynamic/irregular obstacles. Because the central robustness claim is that SAGA remains safe at high speeds in cluttered scenes, the absence of distribution-shift tests (e.g., added Gaussian depth noise or wind disturbances) directly weakens the generalization argument that underpins the title and abstract.
Authors: We agree that the experiments use an idealized simulation environment with perfect depth images and static, regularly spaced obstacles, without sensor noise, wind, or dynamic elements. This controlled setting was chosen to isolate the planner's ability to perform cross-anchor reasoning at high speeds. We recognize that the lack of distribution-shift tests limits the strength of the robustness claims in the title and abstract. In the revision we will add a dedicated limitations paragraph that explicitly discusses these idealizations and their implications for real-world transfer. We will also moderate the language in the abstract and introduction to reflect that the reported results are obtained under idealized conditions. We cannot complete new experiments with added noise or disturbances within the revision timeline, but we will outline how the self-attention and polar positional encoding components are expected to aid robustness against such perturbations. revision: partial
Circularity Check
No circularity: novel architecture with independent experimental validation
full rationale
The paper introduces an original neural architecture (self-attention over anchor tokens + polar positional encoding + goal-aware modulation) for one-stage regression-and-ranking of motion primitives. Performance metrics (100% success, safety margins, flight time) are obtained via direct head-to-head simulation trials against external baselines (YOPO, Ego-planner, Fast-planner) in pillar environments; these are not forced by construction, self-citation chains, or re-labeling of fitted quantities. No equations or design choices reduce to tautological re-use of the target result. The derivation chain is architectural and empirical, remaining self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Depth images combined with body-frame motion state provide sufficient information for local motion planning.
- domain assumption A fixed lattice of motion anchors can represent all necessary feasible motions for safe navigation.
invented entities (2)
-
Polar positional encoding
no independent evidence
-
Goal-aware modulation module
no independent evidence
Lean theorems connected to this paper
-
Foundation.BranchSelection / Cost (J function)RCLCombiner_isCoupling_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a polar positional encoding using the anchor yaw-pitch coordinates: e_i = W_pe a_i + b_pe
-
Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
J_i = λ_s J_smooth + λ_c J_safe + λ_g J_goal + λ_a J_acc — weighted sum with tunable coefficients
-
Foundation (8-tick period, D=3 dimension forcing)AlexanderDuality.alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
3×5 grid yielding N=15 anchor hypotheses
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
KIO-planner: Attention-Guided Single-Stage Motion Planning with Dual Mapping for UAV Navigation
KIO-planner combines CBAM attention with a Dual Mapping mechanism of physical bounds and geometric safety shield to deliver 24 ms latency, 28.4% lower control cost, and 0.76 m obstacle clearance at 3 m/s in simulated ...
Reference graph
Works this paper leans on
-
[1]
Ego-planner: An esdf-free gradient-based local planner for quadrotors[J]
Zhou X, Wang Z, Ye H, et al. Ego-planner: An esdf-free gradient-based local planner for quadrotors[J]. IEEE Robotics and Automation Letters, 2020, 6(2): 478-485
2020
-
[2]
Navrl: Learning safe flight in dynamic environments[J]
Xu Z, Han X, Shen H, et al. Navrl: Learning safe flight in dynamic environments[J]. IEEE Robotics and Automation Letters, 2025
2025
-
[3]
You only plan once: A learning-based one-stage planner with guidance learning[J]
Lu J, Zhang X, Shen H, et al. You only plan once: A learning-based one-stage planner with guidance learning[J]. IEEE Robotics and Automation Letters, 2024, 9(7): 6083-6090
2024
-
[4]
Robust and efficient quadrotor trajectory generation for fast autonomous flight[J]
Zhou B, Gao F, Wang L, et al. Robust and efficient quadrotor trajectory generation for fast autonomous flight[J]. IEEE Robotics and Automation Letters, 2019, 4(4): 3529-3536
2019
-
[5]
Tgk-planner: An efficient topology guided kinodynamic planner for autonomous quadrotors[J]
Ye H, Zhou X, Wang Z, et al. Tgk-planner: An efficient topology guided kinodynamic planner for autonomous quadrotors[J]. IEEE Robotics and Automation Letters, 2020, 6(2): 494-501
2020
-
[6]
Ego-swarm: A fully autonomous and decentralized quadrotor swarm system in cluttered environments[C]//2021 IEEE international conference on robotics and automation (ICRA)
Zhou X, Zhu J, Zhou H, et al. Ego-swarm: A fully autonomous and decentralized quadrotor swarm system in cluttered environments[C]//2021 IEEE international conference on robotics and automation (ICRA). IEEE, 2021: 4101-4107
2021
-
[7]
Fuel: Fast uav exploration using incremental frontier structure and hierarchical planning[J]
Zhou B, Zhang Y , Chen X, et al. Fuel: Fast uav exploration using incremental frontier structure and hierarchical planning[J]. IEEE Robotics and Automation Letters, 2021, 6(2): 779-786
2021
-
[8]
YOPOv2-tracker: An end-to-end agile tracking and navigation framework from perception to action
Lu J, Hui Y , Zhang X, et al. YOPOv2-Tracker: An End-to-End Agile Tracking and Navigation Framework from Perception to Action[J]. arXiv preprint arXiv:2505.06923, 2025
-
[9]
Accelerate multi-agent reinforcement learning in zero-sum games with subgame curriculum learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence
Chen J, Xu Z, Li Y , et al. Accelerate multi-agent reinforcement learning in zero-sum games with subgame curriculum learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 38(10): 11320- 11328
2024
-
[10]
Wei J, Gu Y , Law K L E, et al. Adaptive Position Updating Particle Swarm Optimization for UA V Path Plan- ning[C]//2024 22nd International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt). IEEE, 2024: 124-131
2024
-
[11]
LSEWOA: An Enhanced Whale Optimization Algorithm with Multi-Strategy for Numerical and Engineering Design Optimization Problems[J]
Wei J, Gu Y , Yan Y , et al. LSEWOA: An Enhanced Whale Optimization Algorithm with Multi-Strategy for Numerical and Engineering Design Optimization Problems[J]. Sensors, 2025, 25(7): 2054
2025
-
[12]
Li Z, Zhu W, Zhang R, et al. ASKSSA-CNN-BiLSTM: A Novel Time Series Forecasting Model for Stock Price Prediction Based on An Enhanced Sparrow Search Algorithm[C]//2026 2026 6th Asia Conference on Information Engineering (ACIE) ACIE. Nanyang Technological University, Singapore, 2026: 20-26
2026
-
[13]
MRBMO: An Enhanced Red-Billed Blue Magpie Optimization Algorithm for Solving Numerical Optimization Challenges[J]
Lu B, Xie Z, Wei J, et al. MRBMO: An Enhanced Red-Billed Blue Magpie Optimization Algorithm for Solving Numerical Optimization Challenges[J]. Symmetry, 2025, 17(8): 1295. 11
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.