Recognition: unknown
Binary Rewards and Reinforcement Learning: Fundamental Challenges
Pith reviewed 2026-05-09 16:23 UTC · model grok-4.3
The pith
Under model misspecification, lowering beta in KL-controlled RL with binary rewards concentrates the policy on fewer and fewer valid outputs rather than the filtered model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
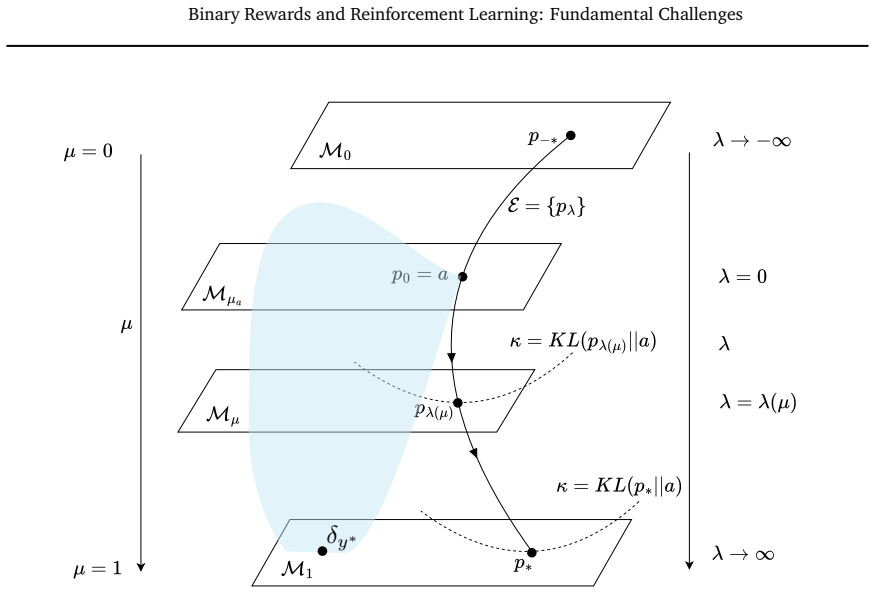
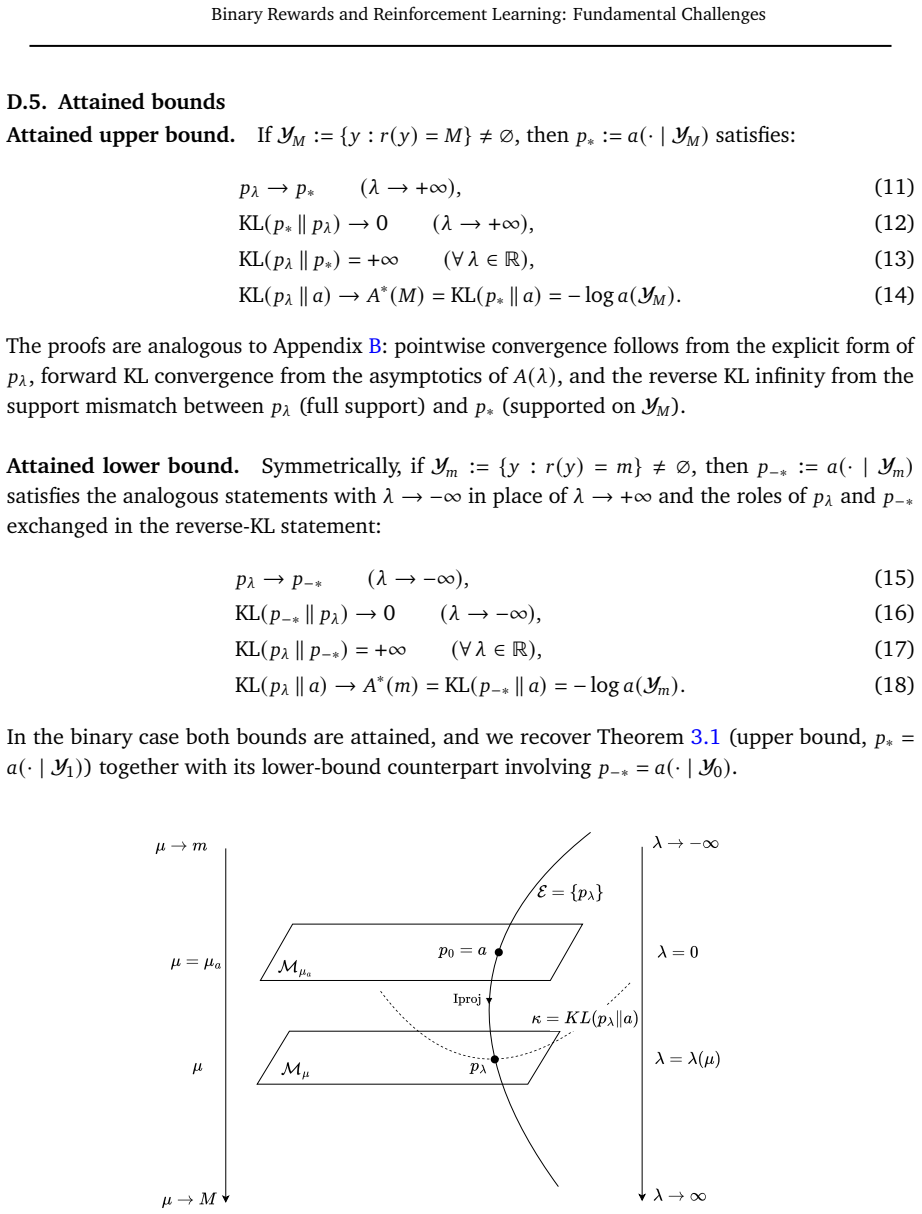
Binary rewards create a fundamental degeneracy for policy gradient methods: the set of distributions maximizing expected reward is infinite, with no distinguished element. KL-control resolves this degeneracy by selecting, in the limit beta to 0, the filtered model p* defined as the base model conditioned on validity, which is the unique fully valid distribution closest to the base model in KL divergence. Under model misspecification, the pressure to decrease beta drives the optimizer toward highly concentrated distributions over a small number of valid outputs, collapsing toward ever fewer as beta decreases, rather than toward the filtered model.
What carries the argument
The tilted distribution p_{[beta]} proportional to a(y) times exp(v(y)/beta) that arises from the KL-penalized objective and whose limiting behavior under misspecification produces concentration instead of the filtered model.
If this is right
- KL-control selects the filtered model p* in the limit as beta approaches zero when the model is correctly specified.
- Explicit formulas relate the hyperparameter beta to the more interpretable target validity rate mu.
- The set of reward-maximizing distributions remains infinite without KL control.
- Alternative divergences that directly reward coverage of the support of p* avoid concentration on a small number of outputs.
Where Pith is reading between the lines
- Monitoring the effective number of distinct valid samples during beta annealing could detect the onset of collapse in large-scale training runs.
- Switching to divergences that penalize missing support of p* rather than rewarding high individual validity scores may preserve multi-sample coverage.
- The same concentration dynamic may appear in any RL setting that uses binary verifiable rewards and KL regularization under imperfect models.
Load-bearing premise
The assumption that real training occurs under model misspecification so that the validity function does not perfectly align with the base model.
What would settle it
In a controlled autoregressive toy model with known base distribution and validity function, measure whether the number of distinct valid outputs sampled from the optimized policy shrinks as beta is lowered while holding the target validity rate fixed.
Figures




read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become a standard approach for improving reasoning in language models, yet models trained with RLVR often suffer from diversity collapse: while single-sample accuracy improves, multi-sample coverage degrades, sometimes falling below the base model. We provide a structural account of this phenomenon grounded in the properties of binary rewards. Binary rewards create a fundamental degeneracy for policy gradient methods: the set of distributions maximizing expected reward is infinite, with no distinguished element. KL-control resolves this degeneracy by selecting, in the limit $\beta\to 0$, the filtered model $p_*:=a(\cdot\mid\mathcal{Y}_1)$ -- the base model conditioned on validity -- which is the unique fully valid distribution closest to the base model in KL divergence. This selection operates through a nontrivial asymmetry: the tilted distribution $p_{[\beta]}\propto a(y)\,e^{v(y)/\beta}$ converges to $p_*$ in forward KL as $\beta\to 0$, yet $p_*$ cannot serve as a direct optimization target because $\mathrm{KL}(q\,\|\,p_*)$ is infinite for any full-support policy $q$. We develop explicit formulas relating the hyperparameter $\beta$ to the more interpretable target validity rate $\mu$. Under model misspecification -- the typical practical regime -- the pressure to decrease $\beta$ drives the optimizer toward highly concentrated distributions over a small number of valid outputs, collapsing toward ever fewer as $\beta$ decreases, rather than toward the filtered model. We illustrate this mechanism on a toy autoregressive experiment and discuss how alternative divergences that target $p_*$ directly -- as pursued empirically by \citet{kruszewski_whatever_2026} -- avoid this failure mode by rewarding coverage of $p_*$'s support rather than concentration on high-validity outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a theoretical analysis of diversity collapse in reinforcement learning with verifiable binary rewards (RLVR). It shows that binary rewards lead to an infinite set of reward-maximizing distributions, resolved by KL-control which selects the filtered base model p_* in the β → 0 limit via the tilted distribution p_{[β]}. Explicit relations between β and target validity μ are derived, and under model misspecification, the paper argues that decreasing β causes practical optimization to collapse to concentrated distributions over few valid outputs rather than p_*. A toy autoregressive experiment illustrates this, and alternatives using different divergences are discussed.
Significance. This work offers a potential explanation for the common issue of reduced diversity in RLVR-trained models despite improved accuracy. The explicit β-μ formulas and the identification of the forward KL convergence to p_* are valuable contributions. If the mechanism is confirmed, it would support exploring coverage-rewarding objectives as in the cited work. The toy experiment provides initial empirical grounding.
major comments (1)
- [Abstract] Abstract (sentence beginning 'Under model misspecification'): The claim that decreasing β drives the optimizer toward highly concentrated distributions over a small number of valid outputs rather than the filtered model p_* is load-bearing for the central account. However, the explicit tilted form p_{[β]} ∝ a(y) exp(v(y)/β) with binary v(y) ∈ {0,1} yields p_β(y | valid) = a(y | valid) exactly for every β (after normalization over the valid set). Thus the global optimum exhibits no additional concentration within valids as β decreases; any such collapse in the toy experiment or practice must arise from optimization failure to reach p_β (e.g., policy-gradient variance or parameterization limits) rather than a structural property of the objective. This distinction requires clarification or correction to sustain the proposed mechanism under misspecification.
minor comments (2)
- [Abstract] The citation 'kruszewski_whatever_2026' appears to be a placeholder and should be replaced with the actual reference.
- Notation for p_{[β]}, p_*, and the validity function v(y) would benefit from earlier introduction and a dedicated notation table or paragraph to aid readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (sentence beginning 'Under model misspecification'): The claim that decreasing β drives the optimizer toward highly concentrated distributions over a small number of valid outputs rather than the filtered model p_* is load-bearing for the central account. However, the explicit tilted form p_{[β]} ∝ a(y) exp(v(y)/β) with binary v(y) ∈ {0,1} yields p_β(y | valid) = a(y | valid) exactly for every β (after normalization over the valid set). Thus the global optimum exhibits no additional concentration within valids as β decreases; any such collapse in the toy experiment or practice must arise from optimization failure to reach p_β (e.g., policy-gradient variance or parameterization limits) rather than a structural property of the objective. This distinction requires clarification or correction to sustain the proposed mechanism under misspecification.
Authors: We thank the referee for this precise observation, which is correct: the conditional p_β(y | valid) equals a(y | valid) for every β, so the global optimum exhibits no additional concentration as β decreases. Our abstract statement refers specifically to the dynamics of practical optimizers under model misspecification (the typical regime), where the explicit β-μ relations we derive require lowering β to achieve higher validity; this change in the objective makes the optimization landscape progressively harder for policy-gradient methods, increasing gradient variance and causing finite models to lose support over the full valid set, collapsing onto few outputs. The toy autoregressive experiment illustrates exactly this empirical behavior. We will revise the abstract and discussion to explicitly distinguish the unchanging global optimum p_β from the observed optimization failures, clarifying that collapse arises from inability to reach p_β rather than any change in p_β itself. This clarification sustains the central account while improving precision. revision: yes
Circularity Check
No significant circularity; derivations are self-contained using standard KL properties
full rationale
The paper derives the tilted distribution p_[β] ∝ a(y) exp(v(y)/β) for binary v, its convergence to p_* as β→0, the infinite KL(q||p_*) issue, and explicit β-μ relations directly from the normalizing partition function and standard exponential tilting identities. These steps are mathematically independent of the target claims and do not reduce any 'prediction' to a fitted quantity or self-referential definition by construction. The misspecification discussion and toy experiment are presented as interpretive consequences rather than load-bearing derivations that collapse to inputs. No self-citation chains or uniqueness theorems from prior author work are invoked to force the central results.
Axiom & Free-Parameter Ledger
free parameters (1)
- beta
axioms (2)
- domain assumption For binary rewards the set of distributions maximizing expected reward is infinite with no distinguished element.
- standard math The tilted distribution p_[β] ∝ a(y) exp(v(y)/β) converges to the filtered model p_* in forward KL as β → 0.
Reference graph
Works this paper leans on
-
[1]
S.-i. Amari. Information Geometry and Its Applications. Applied Mathematical Sciences, vol. 194. Springer, 2016
2016
-
[2]
L. D. Brown. Fundamentals of Statistical Exponential Families with Applications in Statistical Decision Theory. Institute of Mathematical Statistics Lecture Notes---Monograph Series, vol. 9. Institute of Mathematical Statistics, Hayward, CA, 1986
1986
-
[3]
Csisz \'a r
I. Csisz \'a r. I-divergence geometry of probability distributions and minimization problems. The Annals of Probability, 3(1):146--158, 1975
1975
-
[4]
Exponential families from a single KL identity
M. Dymetman. Exponential families from a single KL identity. arXiv preprint arXiv:2604.28036, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
D. Go, T. Korbak, G. Kruszewski, J. Rozen, N. Ryu, and M. Dymetman. Aligning language models with preferences through f-divergence minimization. In International Conference on Machine Learning (ICML), 2023
2023
-
[7]
Khalifa, H
M. Khalifa, H. Elsahar, and M. Dymetman. A distributional approach to controlled text generation. In 9th International Conference on Learning Representations (ICLR), 2021
2021
-
[8]
H. J. Kappen. Linear theory for control of nonlinear stochastic systems. Physical Review Letters, 95(20):200201, 2005
2005
-
[9]
M. Kim, T. Thonet, J. Rozen, H. Lee, K. Jung, and M. Dymetman. Guaranteed generation from large language models. In International Conference on Learning Representations (ICLR), 2025
2025
-
[10]
Korbak, H
T. Korbak, H. Elsahar, G. Kruszewski, and M. Dymetman. On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forgetting. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[11]
T. Korbak, E. Perez, and C. L. Buckley. RL with KL penalties is better viewed as Bayesian inference. arXiv preprint arXiv:2205.11275, 2022
-
[12]
Kruszewski, P
G. Kruszewski, P. Erbacher, J. Rozen, and M. Dymetman. Whatever remains must be true: Filtering drives reasoning in LLMs , shaping diversity. In International Conference on Learning Representations (ICLR), 2026
2026
- [13]
- [14]
-
[15]
Y. Liu, Y. Zeng, Y. Yao, Z. Xie, Z. Sun, B. Wang, H. Wang, Y. Wang, and D. Yin. Understanding R1-Zero-like training: A critical perspective. arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[17]
R \'e nyi
A. R \'e nyi. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 547--561. University of California Press, 1961
1961
-
[18]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. K. Li, Y. Wu, and D. Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
E. Todorov. Linearly-solvable M arkov decision problems. In Advances in Neural Information Processing Systems (NeurIPS), pages 1369--1376, 2007
2007
- [21]
-
[22]
M. J. Wainwright and M. I. Jordan. Graphical models, exponential families, and variational inference. Foundations and Trends in Machine Learning, 1(1--2):1--305, 2008
2008
-
[23]
R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3--4):229--256, 1992
1992
-
[24]
Q. Yu, Z. Liu, J. Peng, S. Zheng, C. Lyu, Y. Cao, H. Huang, et al. DAPO : An open-source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Y. Yue, Z. Chen, A. Lu, Z. Ye, and S. Zheng. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[26]
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.