Recognition: 3 theorem links
· Lean TheoremAn explainable hypothesis-driven approach to Drug-Induced Liver Injury with HADES
Pith reviewed 2026-05-08 19:12 UTC · model grok-4.3
The pith
HADES reframes drug-induced liver injury prediction as generating explainable mechanistic hypotheses rather than binary classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HADES is an agentic system that generates transparent and auditable reasoning traces for assessing drug-induced liver injury risk by integrating molecular-level predictions, metabolite decomposition, structural understanding, and toxicity pathway evidence. On the DILER Benchmark, it achieves ROC-AUC scores of 0.68 on the Test Set and 0.59 on the Post-2021 Set, outperforming DILI-Predictor, and sets a baseline of 0.16 on the Hypothesis Alignment Fuzzy Jaccard Index for how well its generated hypotheses match literature ones.
What carries the argument
HADES, the agentic system that produces mechanistic assessments by combining molecular predictions with metabolite, structural, and pathway evidence to create auditable reasoning traces.
If this is right
- HADES demonstrates improved binary classification performance compared to existing DILI predictors.
- The approach establishes a baseline metric for evaluating the quality of generated mechanistic hypotheses.
- It provides a framework for more transparent decision-making in predictive toxicology.
- Performance holds on challenging newer compounds from after 2021, indicating better generalization potential.
Where Pith is reading between the lines
- If the method scales, it could be adapted to generate hypotheses for other drug-induced toxicities.
- The modest alignment score highlights opportunities to enhance the underlying knowledge sources or reasoning capabilities.
- Integrating this with high-throughput screening data might allow earlier filtering of risky molecules in drug discovery pipelines.
Load-bearing premise
That the mechanistic hepatotoxicity hypotheses curated from biomedical literature serve as reliable ground truth for constructing benchmarks and assessing the agent's reasoning quality.
What would settle it
A study in which independent toxicologists rate the accuracy and usefulness of HADES-generated hypotheses for a new collection of drugs, or testing whether performance drops significantly on compounds discovered after the current post-2021 set.
Figures
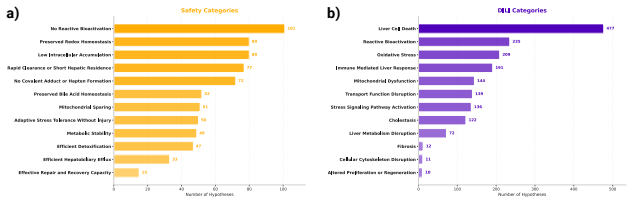






read the original abstract
Drug-induced liver injury (DILI) remains a leading cause of late-stage clinical trial attrition. However, existing computational predictors primarily rely on binary classification, a framing that limits generalization and yields no mechanistic insight to guide translational decisions. We argue that DILI prediction is better posed as an explainable hypothesis-generation problem. To support this shift, we introduce the DILER Benchmark, a dataset that extends beyond binary labels by augmenting a curated set of molecules with mechanistic hepatotoxicity hypotheses derived from biomedical literature. We further present HADES, an agentic system designed to generate transparent and auditable reasoning traces. By combining molecular-level predictions, metabolite decomposition, structural understanding, and toxicity pathway evidence, HADES mechanistically assesses DILI risk. Evaluated on the DILER Benchmark, HADES outperforms existing models in binary classification, achieving a ROC-AUC of 0.68 on the Test Set and 0.59 on the challenging Post-2021 Set, compared with 0.63 and 0.50 for DILI-Predictor, respectively. More importantly, we establish a baseline for mechanistic hypothesis generation, where HADES achieves a Hypothesis Alignment Fuzzy Jaccard Index of 0.16. This result underscores the inherent complexity of the task while highlighting the need for advanced explainable approaches in predictive toxicology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that Drug-Induced Liver Injury (DILI) prediction should be reframed as an explainable hypothesis-generation problem rather than binary classification. It introduces the DILER Benchmark, which augments a set of molecules with mechanistic hepatotoxicity hypotheses derived from biomedical literature, and presents HADES, an agentic system that produces transparent reasoning traces by integrating molecular-level predictions, metabolite decomposition, structural understanding, and toxicity pathway evidence. On the DILER Benchmark, HADES reports ROC-AUC of 0.68 on the Test Set and 0.59 on the Post-2021 Set (vs. 0.63 and 0.50 for DILI-Predictor) and establishes a baseline Hypothesis Alignment Fuzzy Jaccard Index of 0.16.
Significance. If the DILER Benchmark annotations are shown to be reliable and the alignment metric is independently validated, the work could advance explainable AI applications in predictive toxicology by providing mechanistic insights beyond binary risk scores. The creation of a benchmark extending past binary labels and the explicit baseline for hypothesis alignment are concrete contributions that address a recognized gap in translational relevance.
major comments (3)
- [§3 (DILER Benchmark construction)] §3 (DILER Benchmark construction): No curation protocol, inter-annotator agreement statistics, or external validation of the literature-derived mechanistic hepatotoxicity hypotheses is reported. This directly affects the interpretability of the reported Hypothesis Alignment Fuzzy Jaccard Index of 0.16, as the score cannot be distinguished from noise or inconsistencies in the reference set and therefore cannot reliably serve as a baseline for 'transparent and actionable mechanistic insight'.
- [Results section (binary classification performance)] Results section (binary classification performance): The ROC-AUC gains (0.68 vs. 0.63 on Test Set; 0.59 vs. 0.50 on Post-2021 Set) are presented without statistical significance tests, confidence intervals, error bars, or explicit details on data splits and cross-validation. Given the modest absolute improvements and the challenging Post-2021 temporal split, these omissions make it impossible to determine whether the outperformance is robust or reproducible.
- [Evaluation of the Hypothesis Alignment Fuzzy Jaccard Index] Evaluation of the Hypothesis Alignment Fuzzy Jaccard Index: The manuscript provides no validation, sensitivity analysis, or comparison against alternative metrics for the new alignment index. Without such grounding, the claim that HADES produces 'genuinely transparent and actionable mechanistic insight' rests on an untested measure whose low value (0.16) could equally indicate limitations in the reference hypotheses or in the agent's reasoning traces.
minor comments (2)
- [Abstract] The abstract introduces the Hypothesis Alignment Fuzzy Jaccard Index without a concise definition or reference to its formulation; a one-sentence description would improve accessibility.
- [Throughout] Ensure that all acronyms (e.g., DILER, HADES) are expanded on first use in the main text and that figure captions explicitly state the number of molecules and hypotheses in each split.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important areas for improving the clarity and rigor of our work. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3 (DILER Benchmark construction)] §3 (DILER Benchmark construction): No curation protocol, inter-annotator agreement statistics, or external validation of the literature-derived mechanistic hepatotoxicity hypotheses is reported. This directly affects the interpretability of the reported Hypothesis Alignment Fuzzy Jaccard Index of 0.16, as the score cannot be distinguished from noise or inconsistencies in the reference set and therefore cannot reliably serve as a baseline for 'transparent and actionable mechanistic insight'.
Authors: We agree that a transparent description of the benchmark construction is essential for readers to assess the reliability of the reference hypotheses. In the revised manuscript, we will substantially expand §3 to include the full curation protocol: the specific literature databases and search terms used, the criteria for selecting and formulating mechanistic hypotheses from source papers, and the process for mapping them to individual molecules. The annotations were performed by a single hepatotoxicity domain expert to maintain consistency in this highly specialized domain; we will state this explicitly and discuss it as a limitation rather than claiming multi-annotator agreement. External validation is inherently provided by the peer-reviewed literature sources themselves, but we will add a limitations subsection that acknowledges potential inconsistencies across studies and explains why the 0.16 baseline should be viewed as an initial reference point reflecting task difficulty rather than annotation noise. revision: yes
-
Referee: Results section (binary classification performance): The ROC-AUC gains (0.68 vs. 0.63 on Test Set; 0.59 vs. 0.50 on Post-2021 Set) are presented without statistical significance tests, confidence intervals, error bars, or explicit details on data splits and cross-validation. Given the modest absolute improvements and the challenging Post-2021 temporal split, these omissions make it impossible to determine whether the outperformance is robust or reproducible.
Authors: We accept that the current statistical reporting is insufficient. The revised manuscript will add DeLong tests for paired ROC-AUC comparisons, 95% confidence intervals computed via 1000 bootstrap iterations, and error bars on all relevant performance figures. We will also provide a dedicated paragraph detailing the data splits, confirming the temporal nature of the Post-2021 set as a realistic generalization test, and clarifying that cross-validation was not performed because the benchmark uses fixed, publicly defined partitions. These additions will enable readers to evaluate whether the observed gains, though modest, are statistically supported and reproducible under the reported conditions. revision: yes
-
Referee: Evaluation of the Hypothesis Alignment Fuzzy Jaccard Index: The manuscript provides no validation, sensitivity analysis, or comparison against alternative metrics for the new alignment index. Without such grounding, the claim that HADES produces 'genuinely transparent and actionable mechanistic insight' rests on an untested measure whose low value (0.16) could equally indicate limitations in the reference hypotheses or in the agent's reasoning traces.
Authors: We recognize that introducing a new alignment metric requires explicit validation. In the revision, we will add a new evaluation subsection that performs sensitivity analysis by varying the fuzzy threshold parameter and reports results across a range of values. We will also compare the Fuzzy Jaccard Index against two alternative metrics (exact token overlap and cosine similarity on sentence embeddings from a biomedical model) and include illustrative examples of high- and low-alignment cases. The language in the abstract and discussion will be adjusted to present the 0.16 score strictly as an initial baseline that underscores task complexity, while emphasizing that HADES's value lies in producing auditable reasoning traces rather than claiming fully actionable insight at this stage. revision: yes
Circularity Check
No significant circularity; empirical evaluation on externally constructed benchmark
full rationale
The paper introduces the DILER Benchmark (literature-curated mechanistic hypotheses) and HADES agentic system, then reports standard empirical metrics: ROC-AUC of 0.68/0.59 on Test/Post-2021 sets versus DILI-Predictor baselines, plus a new Hypothesis Alignment Fuzzy Jaccard Index of 0.16. No equations, derivations, parameter fits, or self-referential definitions appear. The central claims are direct comparisons and a baseline score on an independent reference set; nothing reduces by construction to its own inputs or to a self-citation chain. This is ordinary ML benchmarking with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mechanistic hepatotoxicity hypotheses derived from biomedical literature accurately represent biological mechanisms suitable for use as ground truth in benchmark construction and hypothesis alignment evaluation.
invented entities (1)
-
HADES agentic system
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel (no relation: this is a tuned retrieval metric, not a calibrated reciprocal cost) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Retrieval is performed over Boltz-1 trunk embeddings using a fractional-exponent energy distance between per-atom embedding sets ... E²_p(X,Y) = 2‖x-y‖_p − ‖x-x'‖_p − ‖y-y'‖_p, with exponent p=0.5
-
Foundation.Atomicity (causal precedence on event systems)atomic_tick (superficial structural analogy only — AOP is biological, not the RS event ledger) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
An AOP represents how an initial biological perturbation propagates ... starts with a Molecular Initiating Event (MIE) and proceeds through one or more Key Events (KEs) to the AO
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ewart, Lorna and Apostolou, Athanasia and Briggs, Skyler A. and Carman, Christopher V. and Chaff, Jake T. and Heng, Anthony R. and Jadalannagari, Sushma and Janardhanan, Jeshina and Jang, Kyung-Jin and Joshipura, Sannidhi R. and Kadam, Mahika M. and Kanellias, Marianne and Kujala, Ville J. and Kulkarni, Gauri and Le, Christopher Y. and Lucchesi, Carolina ...
-
[2]
Taylor, K. and Ram, R. and Ewart, L. and Goldring, C. and Russomanno, G. and Aithal, G. P. and Kostrzewski, T. and Bauch, C. and Wilkinson, J. M. and Modi, S. and Kenna, J. G. and Bailey, J. , year =. Perspective: How complex in vitro models are addressing the challenges of predicting drug-induced liver injury , volume =. doi:10.3389/fddsv.2025.1536756 , ...
-
[3]
Drug-induced liver injury: a comprehensive review , volume =
Hosack, Tom and Damry, Djamil and Biswas, Sujata , year =. Drug-induced liver injury: a comprehensive review , volume =. doi:10.1177/17562848231163410 , journal =
-
[4]
Leenaars, Cathalijn H. C. and Kouwenaar, Carien and Stafleu, Frans R. and Bleich, André and Ritskes-Hoitinga, Merel and De Vries, Rob B. M. and Meijboom, Franck L. B. , year =. Animal to human translation: a systematic scoping review of reported concordance rates , volume =. Journal of Translational Medicine , publisher =. doi:10.1186/s12967-019-1976-2 , number =
-
[5]
Chen, Minjun and Tung, Chun-Wei and Shi, Qiang and Guo, Lei and Shi, Leming and Fang, Hong and Borlak, J\". A testing strategy to predict risk for drug-induced liver injury in humans using high-content screen assays and the ‘rule-of-two’ model , volume =. Archives of Toxicology , publisher =. 2014 , month = jun, pages =. doi:10.1007/s00204-014-1276-9 , number =
-
[6]
Adverse Outcome Pathways , year =
-
[7]
and Spjuth, Ola and Bender, Andreas , year =
Seal, Srijit and Williams, Dominic and Hosseini-Gerami, Layla and Mahale, Manas and Carpenter, Anne E. and Spjuth, Ola and Bender, Andreas , year =. Improved Detection of Drug-Induced Liver Injury by Integrating Predicted In Vivo and In Vitro Data , volume =. Chemical Research in Toxicology , publisher =. doi:10.1021/acs.chemrestox.4c00015 , number =
-
[8]
Pharmacotherapy: The Journal of Human Pharmacology and Drug Therapy , publisher =
Ho, Alfred Zheng Ting and Law, Jeren Zheng Feng and Wang, Aiwen and Lim, Daniel Yan Zheng and Ong, Jasmine Chiat Ling , year =. Pharmacotherapy: The Journal of Human Pharmacology and Drug Therapy , publisher =. doi:10.1002/phar.70131 , number =
-
[9]
Garcia de Lomana, Marina and Gadaleta, Domenico and Raschke, Marian and Fricke, Robert and Montanari, Floriane , year =. Predicting Liver-Related In Vitro Endpoints with Machine Learning to Support Early Detection of Drug-Induced Liver Injury , volume =. Chemical Research in Toxicology , publisher =. doi:10.1021/acs.chemrestox.4c00453 , number =
-
[10]
Txgemma: Efficient and agentic llms for therapeutics
Wang, Eric and Schmidgall, Samuel and Jaeger, Paul F. and Zhang, Fan and Pilgrim, Rory and Matias, Yossi and Barral, Joelle and Fleet, David and Azizi, Shekoofeh , keywords =. TxGemma: Efficient and Agentic LLMs for Therapeutics , publisher =. 2025 , copyright =. doi:10.48550/ARXIV.2504.06196 , url =
-
[11]
ToxReason: A Benchmark for Mechanistic Chemical Toxicity Reasoning via Adverse Outcome Pathway
Park, Jueon and Jang, Wonjune and Kim, Chanhwi and Park, Yein and Kang, Jaewoo , keywords =. ToxReason: A Benchmark for Mechanistic Chemical Toxicity Reasoning via Adverse Outcome Pathway , publisher =. 2026 , copyright =. doi:10.48550/ARXIV.2604.06264 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.06264 2026
-
[12]
A large-scale human toxicogenomics resource for drug-induced liver injury prediction , volume =
Bergen, Volker and Kodella, Konstantia and Srikrishnan, Sreenath and Barrandon, Ornella and Anderson, Sara and Rogers-Grazado, Max and Fowler, Casey and Beyene, Hirit and Robichaud, Nicole and Fulton, Timothy and Lapchyk, Nina and Cortes, Mauricio and Plugis, Nick and Goddeeris, Matthew and Zamanighomi, Mahdi , year =. A large-scale human toxicogenomics r...
-
[13]
and Qu, Yanyan and Connor, Skylar and Tong, Weida and Li, Dongying and Chen, Minjun , year =
Olubamiwa, AyoOluwa O. and Qu, Yanyan and Connor, Skylar and Tong, Weida and Li, Dongying and Chen, Minjun , year =. DILIrank 2.0: An updated and expanded database for drug-induced liver injury risk based on FDA labeling and a literature review , volume =. Drug Discovery Today , publisher =. doi:10.1016/j.drudis.2025.104485 , number =
-
[14]
Thakkar, Shraddha and Li, Ting and Liu, Zhichao and Wu, Leihong and Roberts, Ruth and Tong, Weida , year =. Drug-induced liver injury severity and toxicity (DILIst): binary classification of 1279 drugs by human hepatotoxicity , volume =. Drug Discovery Today , publisher =. doi:10.1016/j.drudis.2019.09.022 , number =
-
[15]
Adverse Outcome Pathways Mechanistically Describing Hepatotoxicity , ISBN =
Callewaert, Ellen and Louisse, Jochem and Kramer, Nynke and Sanz-Serrano, Julen and Vinken, Mathieu , year =. Adverse Outcome Pathways Mechanistically Describing Hepatotoxicity , ISBN =. doi:10.1007/978-1-0716-4003-6_12 , booktitle =
-
[16]
Skat-Rørdam, J. and Lykkesfeldt, J. and Gluud, L. L. and Tveden-Nyborg, P. , year =. Mechanisms of drug induced liver injury , volume =. Cellular and Molecular Life Sciences , publisher =. doi:10.1007/s00018-025-05744-3 , number =
-
[17]
Wishart, David S and Tian, Siyang and Allen, Dana and Oler, Eponine and Peters, Harrison and Lui, Vicki W and Gautam, Vasuk and Djoumbou-Feunang, Yannick and Greiner, Russell and Metz, Thomas O , year =. BioTransformer 3.0—a web server for accurately predicting metabolic transformation products , volume =. Nucleic Acids Research , publisher =. doi:10.1093...
-
[18]
Rusyn, Ivan and Arzuaga, Xabier and Cattley, Russell C. and Corton, J. Christopher and Ferguson, Stephen S. and Godoy, Patricio and Guyton, Kathryn Z. and Kaplowitz, Neil and Khetani, Salman R. and Roberts, Ruth A. and Roth, Robert A. and Smith, Martyn T. , year =. Key Characteristics of Human Hepatotoxicants as a Basis for Identification and Characteriza...
-
[19]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , keywords =. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , publisher =. 2023 , copyright =. doi:10.48550/ARXIV.2303.16634 , url =
work page internal anchor Pith review doi:10.48550/arxiv.2303.16634 2023
-
[20]
Wang, Jialin and Duan, Zhihua , keywords =. Agent AI with LangGraph: A Modular Framework for Enhancing Machine Translation Using Large Language Models , publisher =. 2024 , copyright =. doi:10.48550/ARXIV.2412.03801 , url =
-
[21]
Democratizing ai scientists using tooluniverse.arXiv preprint arXiv:2509.23426, 2025
Gao, Shanghua and Zhu, Richard and Sui, Pengwei and Kong, Zhenglun and Aldogom, Sufian and Huang, Yepeng and Noori, Ayush and Shamji, Reza and Parvataneni, Krishna and Tsiligkaridis, Theodoros and Zitnik, Marinka , keywords =. Democratizing AI scientists using ToolUniverse , publisher =. 2025 , copyright =. doi:10.48550/ARXIV.2509.23426 , url =
-
[22]
2025 , eprint=
TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools , author=. 2025 , eprint=
2025
-
[23]
celltype-agent , year =
-
[24]
Wohlwend, Jeremy and Corso, Gabriele and Passaro, Saro and Getz, Noah and Reveiz, Mateo and Leidal, Ken and Swiderski, Wojtek and Atkinson, Liam and Portnoi, Tally and Chinn, Itamar and Silterra, Jacob and Jaakkola, Tommi and Barzilay, Regina , year =. Boltz-1 Democratizing Biomolecular Interaction Modeling , url =. doi:10.1101/2024.11.19.624167 , publisher =
-
[25]
URL https://www.biorxiv.org/content/early/2025/06/18/2025.06.14.659707
Passaro, Saro and Corso, Gabriele and Wohlwend, Jeremy and Reveiz, Mateo and Thaler, Stephan and Somnath, Vignesh Ram and Getz, Noah and Portnoi, Tally and Roy, Julien and Stark, Hannes and Kwabi-Addo, David and Beaini, Dominique and Jaakkola, Tommi and Barzilay, Regina , year =. Boltz-2: Towards Accurate and Efficient Binding Affinity Prediction , url =....
-
[26]
2012 , publisher =
LiverTox: Clinical and Research Information on Drug-Induced Liver Injury , author =. 2012 , publisher =
2012
-
[27]
ChEMBL: towards direct deposition of bioassay data , volume =
Mendez, David and Gaulton, Anna and Bento, A Patrícia and Chambers, Jon and De Veij, Marleen and Félix, Eloy and Magariños, María Paula and Mosquera, Juan F and Mutowo, Prudence and Nowotka, Michał and Gordillo-Marañón, María and Hunter, Fiona and Junco, Laura and Mugumbate, Grace and Rodriguez-Lopez, Milagros and Atkinson, Francis and Bosc, Nicolas and R...
-
[28]
Data Releases \#1--\#10 , year =
-
[29]
A.\ Anonymous , title =
-
[30]
Veith, Henrike and Southall, Noel and Huang, Ruili and James, Tim and Fayne, Darren and Artemenko, Natalia and Shen, Min and Inglese, James and Austin, Christopher P and Lloyd, David G and Auld, Douglas S , year =. Comprehensive characterization of cytochrome P450 isozyme selectivity across chemical libraries , volume =. Nature Biotechnology , publisher =...
-
[31]
Dual use of artificial-intelligence-powered drug discovery , volume =
Urbina, Fabio and Lentzos, Filippa and Invernizzi, Cédric and Ekins, Sean , year =. Dual use of artificial-intelligence-powered drug discovery , volume =. Nature Machine Intelligence , publisher =. doi:10.1038/s42256-022-00465-9 , number =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.