Statistical Inference of Day-to-Day Traffic Dynamics
Pith reviewed 2026-05-08 17:31 UTC · model grok-4.3
The pith
A statistical framework enables formal inference of behavioral parameters in day-to-day route choice models from trajectory data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework develops a likelihood-based approach for the stochastic individual-level adjustment model of day-to-day route choice, establishes identifiability and consistency of the resulting estimators, and extends the model to incorporate demand variation, user heterogeneity through hierarchical structure, and anonymized observability from privacy-constrained trajectory data.
What carries the argument
The stochastic individual-level adjustment model, which represents each traveler's daily route choice as a probabilistic update based on prior experience and information.
If this is right
- Parameters estimated from data carry calibrated uncertainty that can be used for hypothesis tests on learning behavior.
- The framework remains consistent when total demand varies across days or when users differ systematically.
- It produces usable inferences even when only anonymized trajectory segments are observable.
- Simulation studies confirm finite-sample accuracy and robustness when the model is mildly misspecified.
- Application to laboratory and real commuting data reveals whether purely inter-day learning suffices or whether en-route information changes behavior.
Where Pith is reading between the lines
- The approach could be applied to test how different information systems affect day-to-day adaptation rates.
- Estimated heterogeneity parameters might help segment travelers for targeted interventions such as personalized routing apps.
- The same inference structure could extend to other repeated-choice settings such as mode or departure-time decisions.
- If demand variation is large, the model suggests collecting supplementary aggregate counts to tighten parameter estimates.
Load-bearing premise
The stochastic individual-level adjustment model correctly describes how travelers learn from experience and adjust their route choices each day.
What would settle it
A controlled simulation or laboratory experiment in which the framework is applied to data generated from known behavioral parameters yet fails to recover those parameters within the reported uncertainty bounds or produces inconsistent estimates across repeated trials.
Figures













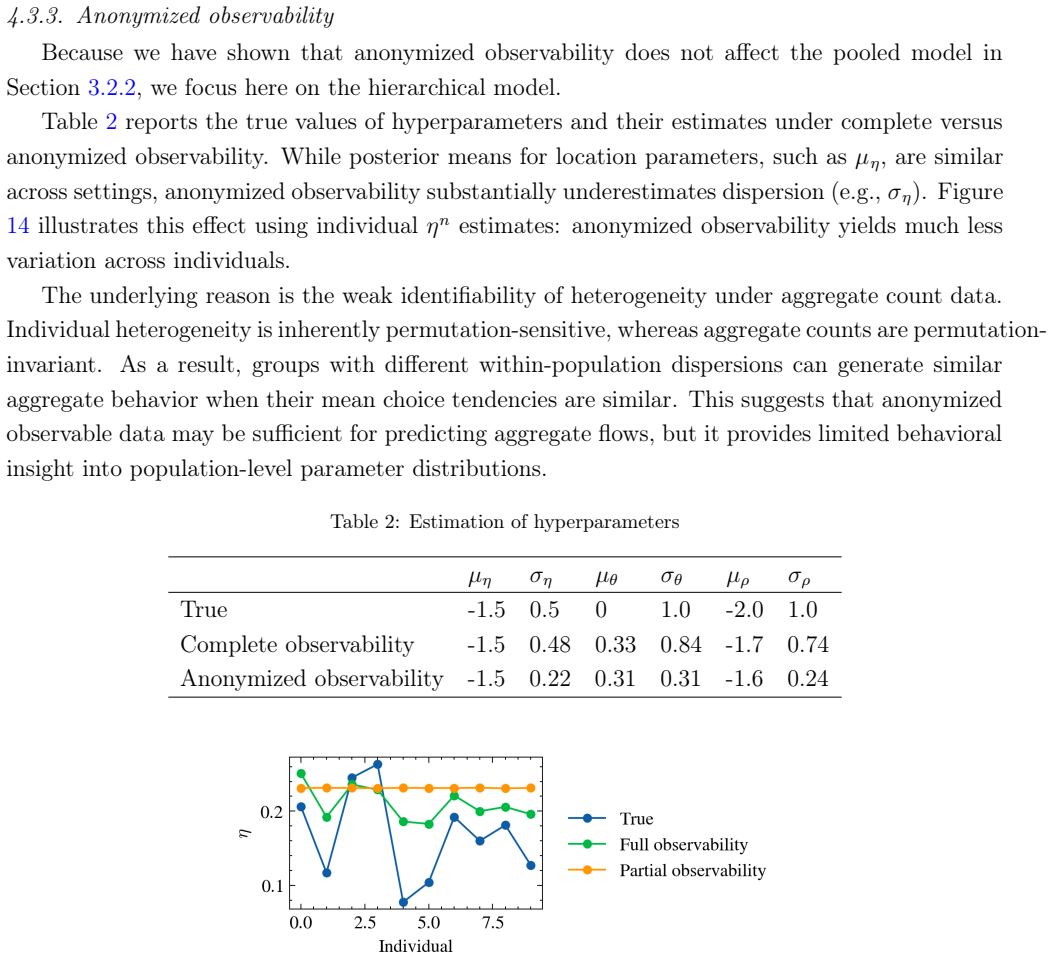






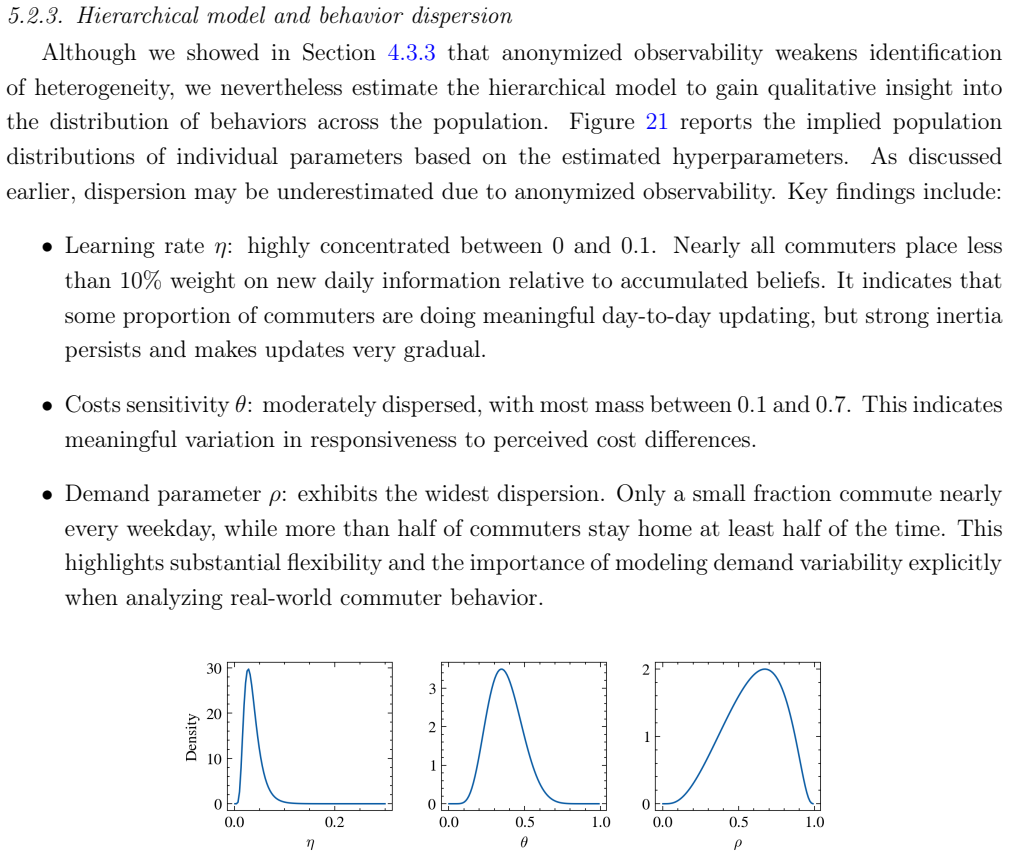














read the original abstract
Day-to-day traffic dynamics are widely used to model flow evolution due to travelers' learning and adjustment behavior, yet empirical analysis of these models often relies on descriptive calibration with limited inferential content. This paper develops a statistical inference framework for day-to-day route choice dynamics based on a stochastic individual-level adjustment model. The framework enables uncertainty quantification and formal inference for behavioral parameters from trajectory data. We establish identifiability and consistency under mild conditions, and extend the framework to accommodate demand variation, user heterogeneity through a hierarchical structure, and anonymized observability caused by privacy constraints on trajectory data. Simulation studies demonstrate good finite-sample performance, calibrated uncertainty, and robustness to model misspecification. Empirical analyses of controlled laboratory experiments and real-world trajectory data from Ann Arbor, Michigan, show that the framework can generate novel behavioral insights across settings: it reveals the inadequacy of a purely inter-day learning model once en-route information is introduced, recovers systematic behavioral differences across participant types, and uncovers meaningful day-to-day learning together with substantial demand variation in real-world commuting behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a statistical inference framework for day-to-day route choice dynamics based on a stochastic individual-level adjustment model. It establishes identifiability and consistency of the estimator under mild conditions, extends the model to accommodate demand variation, hierarchical user heterogeneity, and anonymized observability arising from privacy constraints on trajectory data, validates finite-sample performance and robustness via simulations, and applies the framework to laboratory experiments and real-world Ann Arbor trajectory data to recover behavioral insights on learning, en-route information, participant heterogeneity, and demand variation.
Significance. If the identifiability and consistency results hold under the stated extensions, particularly the handling of anonymized observability, the work would provide a valuable rigorous statistical foundation for parameter estimation and uncertainty quantification in day-to-day traffic models, which have historically relied on descriptive calibration. The simulation validation and dual empirical applications (controlled lab plus real-world commuting) illustrate potential for generating falsifiable behavioral insights from trajectory data.
major comments (3)
- [theoretical results for anonymized observability] Section on theoretical results for anonymized observability: the consistency proof relies on conditions such as uniform positive probability of observing individual choices across days and correct specification of the heterogeneity distribution. These may fail under the irregular, potentially non-ignorable missingness patterns typical of sparse real-world trajectory data (as in the Ann Arbor application), even if the base model is correct; the manuscript should provide a concrete sensitivity analysis or counterexample check for such cases.
- [simulation studies] Simulation studies section: the reported robustness checks employ controlled synthetic missingness mechanisms, which do not replicate the irregular and possibly correlated patterns in the Ann Arbor data. This weakens support for the claim that the estimator remains consistent and well-calibrated under realistic privacy-induced anonymization.
- [empirical analysis of Ann Arbor data] Empirical analysis of Ann Arbor data: the separation of day-to-day learning parameters from substantial demand variation via the hierarchical structure is central to the novel insights, yet no explicit diagnostics (e.g., for multicollinearity between learning rates and demand parameters or sensitivity to the assumed heterogeneity distribution) are provided; without these, the recovered behavioral conclusions rest on unverified identifiability in the observed data regime.
minor comments (2)
- The abstract refers to 'mild conditions' for identifiability and consistency; these should be stated explicitly in the main text (e.g., as a numbered list or theorem statement) rather than left implicit.
- Figure captions and legends in the empirical results section would benefit from additional detail on axis scaling and confidence interval construction to improve clarity for readers unfamiliar with the estimator.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the scope and limitations of our theoretical and empirical results. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Section on theoretical results for anonymized observability: the consistency proof relies on conditions such as uniform positive probability of observing individual choices across days and correct specification of the heterogeneity distribution. These may fail under the irregular, potentially non-ignorable missingness patterns typical of sparse real-world trajectory data (as in the Ann Arbor application), even if the base model is correct; the manuscript should provide a concrete sensitivity analysis or counterexample check for such cases.
Authors: We agree that the consistency result for the anonymized observability extension is established under the stated sufficient conditions, including a uniform positive lower bound on per-individual observation probabilities and correct specification of the heterogeneity distribution. These assumptions enable the application of standard M-estimator consistency arguments to the incomplete-data likelihood. While the conditions are mild and standard for missing-data problems, we acknowledge that real-world sparse trajectory data may involve more irregular or non-ignorable missingness. To address the concern directly, we will add a new sensitivity analysis subsection. This will include Monte Carlo experiments with irregular missingness patterns (e.g., day- and user-specific missingness correlated with latent route utilities) and mild violations of the uniform probability bound, together with a discussion of implications for the Ann Arbor application. revision: yes
-
Referee: Simulation studies section: the reported robustness checks employ controlled synthetic missingness mechanisms, which do not replicate the irregular and possibly correlated patterns in the Ann Arbor data. This weakens support for the claim that the estimator remains consistent and well-calibrated under realistic privacy-induced anonymization.
Authors: The existing simulation design deliberately employs controlled synthetic mechanisms to isolate the separate effects of anonymization rate, heterogeneity, and demand variation on finite-sample bias and coverage. We recognize, however, that these do not fully reproduce the irregular and possibly correlated missingness patterns present in the Ann Arbor dataset. In the revision we will augment the simulation section with an additional set of experiments that replicate the empirical missingness structure observed in the Ann Arbor data (user-day specific missingness correlated with observed covariates). These new checks will be reported alongside the existing results to provide stronger support for performance under realistic privacy constraints. revision: yes
-
Referee: Empirical analysis of Ann Arbor data: the separation of day-to-day learning parameters from substantial demand variation via the hierarchical structure is central to the novel insights, yet no explicit diagnostics (e.g., for multicollinearity between learning rates and demand parameters or sensitivity to the assumed heterogeneity distribution) are provided; without these, the recovered behavioral conclusions rest on unverified identifiability in the observed data regime.
Authors: The hierarchical specification is motivated by the theoretical identifiability results, which separate learning rates from demand parameters under the maintained assumptions. We did not, however, report explicit post-estimation diagnostics in the current version. In the revised empirical section we will add (i) a parameter correlation matrix and variance-inflation-factor diagnostics to assess multicollinearity between learning and demand parameters, and (ii) a sensitivity analysis that re-estimates the model under alternative heterogeneity distributions (e.g., different numbers of mixture components and alternative mixing densities). These diagnostics will be presented to support the robustness of the reported behavioral conclusions. revision: yes
Circularity Check
No circularity: framework uses independent identifiability proofs and external statistical theory
full rationale
The paper constructs a statistical inference framework for a stochastic individual-level adjustment model of day-to-day route choice, derives identifiability and consistency results under stated mild conditions, and extends the estimator to demand variation, hierarchical heterogeneity, and anonymized observability. These steps rely on standard M-estimator or martingale convergence arguments rather than self-referential definitions or fitted quantities renamed as predictions. Simulation studies and empirical applications on laboratory and Ann Arbor data serve as independent validation, not reductions of outputs to inputs by construction. No load-bearing self-citations or uniqueness theorems imported from prior author work appear in the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
some theoretical aspects of road traffic research
Road paper. some theoretical aspects of road traffic research. , author=. Proceedings of the institution of civil engineers , volume=. 1952 , publisher=
work page 1952
-
[2]
Transportation science , volume=
The stability of a dynamic model of traffic assignment—an application of a method of Lyapunov , author=. Transportation science , volume=. 1984 , publisher=
work page 1984
-
[3]
Transportation Research Part B: Methodological , volume=
Modeling the day-to-day traffic evolution process after an unexpected network disruption , author=. Transportation Research Part B: Methodological , volume=. 2012 , publisher=
work page 2012
-
[4]
Transportation Research Part B: Methodological , volume=
Bounded rationality and irreversible network change , author=. Transportation Research Part B: Methodological , volume=. 2011 , publisher=
work page 2011
-
[5]
Transportation Research Part B: Methodological , volume=
Stochastic travel demand estimation: Improving network identifiability using multi-day observation sets , author=. Transportation Research Part B: Methodological , volume=. 2018 , publisher=
work page 2018
-
[6]
Transportation Research Part A: General , volume=
Dynamic models of commuter behavior: Experimental investigation and application to the analysis of planned traffic disruptions , author=. Transportation Research Part A: General , volume=. 1990 , publisher=
work page 1990
-
[7]
Transportation Research Part A: Policy and Practice , volume=
Transferring insights into commuter behavior dynamics from laboratory experiments to field surveys , author=. Transportation Research Part A: Policy and Practice , volume=. 2000 , publisher=
work page 2000
-
[8]
Transportation Research Part B: Methodological , volume=
Analyzing heterogeneity and unobserved structural effects in route-switching behavior under ATIS: a dynamic kernel logit formulation , author=. Transportation Research Part B: Methodological , volume=. 2003 , publisher=
work page 2003
-
[9]
Transportation Research Part C: Emerging Technologies , volume=
Exploration of day-to-day route choice models by a virtual experiment , author=. Transportation Research Part C: Emerging Technologies , volume=. 2018 , publisher=
work page 2018
-
[10]
Travel Behaviour and Society , volume=
Contrarians do better: Testing participants’ response to information in a simulated day-to-day route choice experiment , author=. Travel Behaviour and Society , volume=. 2019 , publisher=
work page 2019
-
[11]
Transportation Research Part A: Policy and Practice , volume=
Investigating day-to-day route choices based on multi-scenario laboratory experiments, Part I: Route-dependent attraction and its modeling , author=. Transportation Research Part A: Policy and Practice , volume=. 2023 , publisher=
work page 2023
-
[12]
Organizational Behavior and Human Performance , volume=
Experiments in the laboratory and the real world , author=. Organizational Behavior and Human Performance , volume=. 1973 , publisher=
work page 1973
-
[13]
Transportation Research Part C: Emerging Technologies , volume=
Surrogate-based simulation optimization approach for day-to-day dynamics model calibration with real data , author=. Transportation Research Part C: Emerging Technologies , volume=. 2019 , publisher=
work page 2019
-
[14]
Transportation science , volume=
Alternative approaches for real-time estimation and prediction of time-dependent origin--destination flows , author=. Transportation science , volume=. 2000 , publisher=
work page 2000
-
[15]
Transportation science , volume=
Estimation and prediction of time-dependent origin-destination flows with a stochastic mapping to path flows and link flows , author=. Transportation science , volume=. 2002 , publisher=
work page 2002
-
[16]
Transportation Research Part B: Methodological , volume=
Trip matrix and path flow reconstruction and estimation based on plate scanning and link observations , author=. Transportation Research Part B: Methodological , volume=. 2008 , publisher=
work page 2008
-
[17]
Transportation Research Part B: Methodological , volume=
The stability of stochastic equilibrium in a two-link transportation network , author=. Transportation Research Part B: Methodological , volume=. 1984 , publisher=
work page 1984
-
[18]
Interpretable Latent Variable Models: Identifiability, Estimation, and Inference , author=
-
[19]
The Annals of Mathematical Statistics , volume=
The identification of structural characteristics , author=. The Annals of Mathematical Statistics , volume=. 1950 , publisher=
work page 1950
-
[20]
arXiv preprint arXiv:2404.08667 , year=
Traffic State Estimation and Uncertainty Quantification at Signalized Intersections with Low Penetration Rate Vehicle Trajectory Data , author=. arXiv preprint arXiv:2404.08667 , year=
-
[21]
The journal of chemical physics , volume=
Equation of state calculations by fast computing machines , author=. The journal of chemical physics , volume=. 1953 , publisher=
work page 1953
-
[22]
Monte Carlo sampling methods using Markov chains and their applications , author=. 1970 , journal=
work page 1970
-
[23]
Transportation Science , volume=
An efficient method for computing traffic equilibria in networks with asymmetric transportation costs , author=. Transportation Science , volume=. 1984 , publisher=
work page 1984
-
[24]
Transportation Research Part B: Methodological , volume=
On the local and global stability of a travel route choice adjustment process , author=. Transportation Research Part B: Methodological , volume=. 1996 , publisher=
work page 1996
-
[25]
Transportation Science , volume=
Projected dynamical systems in the formulation, stability analysis, and computation of fixed-demand traffic network equilibria , author=. Transportation Science , volume=. 1997 , publisher=
work page 1997
-
[26]
Transportation Research Part B: Methodological , volume=
A link-based day-to-day traffic assignment model , author=. Transportation Research Part B: Methodological , volume=. 2010 , publisher=
work page 2010
-
[27]
Transportation Research Part C: Emerging Technologies , volume=
A discrete rational adjustment process of link flows in traffic networks , author=. Transportation Research Part C: Emerging Technologies , volume=. 2013 , publisher=
work page 2013
-
[28]
Transportation Science , volume=
On stochastic-user-equilibrium-based day-to-day dynamics , author=. Transportation Science , volume=. 2022 , publisher=
work page 2022
-
[29]
Transportation Research Part B: Methodological , volume=
On a link-based day-to-day traffic assignment model , author=. Transportation Research Part B: Methodological , volume=. 2012 , publisher=
work page 2012
-
[30]
Transportation Research Part B: Methodological , volume=
Day-to-day stationary link flow pattern , author=. Transportation Research Part B: Methodological , volume=. 2009 , publisher=
work page 2009
-
[31]
Transportation Research Part B: Methodological , volume=
Link-based day-to-day network traffic dynamics and equilibria , author=. Transportation Research Part B: Methodological , volume=. 2015 , publisher=
work page 2015
-
[32]
Transportation Science , volume=
Dynamic processes and equilibrium in transportation networks: towards a unifying theory , author=. Transportation Science , volume=. 1995 , publisher=
work page 1995
-
[33]
Transportation Research Part B: Methodological , volume=
Stability and attraction domains of traffic equilibria in a day-to-day dynamical system formulation , author=. Transportation Research Part B: Methodological , volume=. 2010 , publisher=
work page 2010
-
[34]
Transportation Research Part C: Emerging Technologies , volume=
Day-to-day dynamic models for intelligent transportation systems design and appraisal , author=. Transportation Research Part C: Emerging Technologies , volume=. 2013 , publisher=
work page 2013
-
[35]
Transportation research part B: methodological , volume=
Day-to-day dynamics with advanced traveler information , author=. Transportation research part B: methodological , volume=. 2021 , publisher=
work page 2021
-
[36]
Transportation Research Part B: Methodological , volume=
Stability of the stochastic equilibrium assignment problem: a dynamical systems approach , author=. Transportation Research Part B: Methodological , volume=. 1999 , publisher=
work page 1999
-
[37]
Networks and Spatial Economics , volume=
Combined route choice and adaptive traffic control in a day-to-day dynamical system , author=. Networks and Spatial Economics , volume=. 2015 , publisher=
work page 2015
-
[38]
Transportation Research Part B: Methodological , volume=
The emergence of stochastic user equilibria in day-to-day traffic models , author=. Transportation Research Part B: Methodological , volume=. 2022 , publisher=
work page 2022
-
[39]
Transportation Research Part B: Methodological , volume=
Physics of day-to-day network flow dynamics , author=. Transportation Research Part B: Methodological , volume=. 2016 , publisher=
work page 2016
- [40]
-
[41]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Riemann manifold langevin and hamiltonian monte carlo methods , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2011 , publisher=
work page 2011
-
[42]
The annals of statistics , volume=
Slice sampling , author=. The annals of statistics , volume=. 2003 , publisher=
work page 2003
-
[43]
The poisson multinomial distribution and its applications in voting theory, ecological inference, and machine learning , author=. arXiv preprint arXiv:2201.04237 , year=
- [44]
-
[45]
Comparing AI and human decision-making mechanisms in daily collaborative experiments , author=. iScience , volume=. 2025 , publisher=
work page 2025
-
[46]
Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan , author=. 2014 , publisher=
work page 2014
-
[47]
Wiley interdisciplinary reviews: cognitive science , volume=
Bayesian data analysis , author=. Wiley interdisciplinary reviews: cognitive science , volume=. 2010 , publisher=
work page 2010
-
[48]
Psychonomic bulletin & review , volume=
The Bayesian New Statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective , author=. Psychonomic bulletin & review , volume=. 2018 , publisher=
work page 2018
-
[49]
Applied psychological measurement , volume=
Set correlation and contingency tables , author=. Applied psychological measurement , volume=. 1988 , publisher=
work page 1988
-
[50]
Naval research logistics quarterly , volume=
An algorithm for quadratic programming , author=. Naval research logistics quarterly , volume=. 1956 , publisher=
work page 1956
-
[51]
International conference on machine learning , pages=
Revisiting Frank-Wolfe: Projection-free sparse convex optimization , author=. International conference on machine learning , pages=. 2013 , organization=
work page 2013
-
[52]
An experimental study of the Online Information Paradox: Does en-route information improve road network performance? , author=. PLoS One , volume=. 2017 , publisher=
work page 2017
-
[53]
Advances in methods and practices in psychological science , volume=
Rejecting or accepting parameter values in Bayesian estimation , author=. Advances in methods and practices in psychological science , volume=. 2018 , publisher=
work page 2018
-
[54]
Transportation Research Record , volume=
Trajectory data processing and mobility performance evaluation for urban traffic networks , author=. Transportation Research Record , volume=. 2023 , publisher=
work page 2023
-
[55]
Regional Forecast , year =
-
[56]
Large population approximations of a general stochastic traffic assignment model , author=. Operations Research , volume=. 1993 , publisher=
work page 1993
-
[57]
Transportation Science , volume=
Computation of equilibrium distributions of Markov traffic-assignment models , author=. Transportation Science , volume=. 2004 , publisher=
work page 2004
-
[58]
Transportation Research Part B: Methodological , volume=
Day-to-day variation in Markovian traffic assignment models , author=. Transportation Research Part B: Methodological , volume=. 2002 , publisher=
work page 2002
-
[59]
Hang Qi and Ning Jia and Xiaobo Qu and Zhengbing He , keywords =. Investigating day-to-day route choices based on multi-scenario laboratory experiments, Part II: Route-dependent attraction-based stochastic process model , journal =. 2024 , issn =
work page 2024
-
[60]
Transportation Research Part B: Methodological , volume=
Bayesian inference for day-to-day dynamic traffic models , author=. Transportation Research Part B: Methodological , volume=. 2013 , publisher=
work page 2013
-
[61]
Transportation Research Part B: Methodological , volume=
Statistical methods for comparison of day-to-day traffic models , author=. Transportation Research Part B: Methodological , volume=. 2016 , publisher=
work page 2016
-
[62]
Transportmetrica B: transport dynamics , volume=
Modelling sources of variation in transportation systems: theoretical foundations of day-to-day dynamic models , author=. Transportmetrica B: transport dynamics , volume=. 2013 , publisher=
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.