Recognition: unknown
Quantum Tilted Loss in Variational Optimization: Theory and Applications
Pith reviewed 2026-05-09 16:06 UTC · model grok-4.3
The pith
Tuning one parameter sharpens variational quantum landscapes without moving the global minimum
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Quantum Tilted Loss is obtained by exponentially tilting the cost operator with a positive real parameter. The resulting family of objectives shares exactly the same global minima as the original expectation-value problem, yet the gradient signal is scaled upward in structured regions of the parameter space. The construction supplies a single-parameter interpolation that recovers standard variational training at zero tilt and recovers CVaR and Gibbs-style objectives at finite or infinite tilt. In the finite-shot regime the method converts the dominant difficulty from vanishing gradients to increased estimator variance, and ascending tilt schedules are shown to mitigate this variance penalty.
What carries the argument
Quantum Tilted Loss (QTL), an operator obtained by exponentially weighting the spectrum of the cost Hamiltonian with a tunable tilt parameter that leaves the ground-state eigenvector unchanged
If this is right
- QTL supplies a continuous unification of expectation minimization with CVaR and Gibbs formulations through variation of the tilt parameter.
- Gradient magnitudes increase with tilt while the set of global minima remains exactly the same.
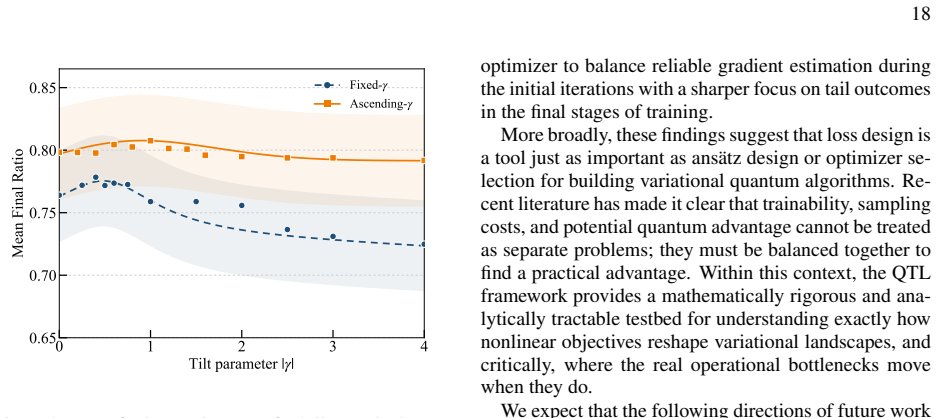
- The primary optimization bottleneck shifts from landscape flatness to measurement-sample complexity as the tilt grows.
- Ascending tilt schedules outperform constant-tilt training under realistic finite-shot constraints in the reported simulations.
Where Pith is reading between the lines
- The same tilting construction could be applied to classical variational problems that suffer from flat loss surfaces, provided the underlying cost operator can be evaluated.
- Adaptive controllers that raise the tilt only when measured gradient variance exceeds a threshold might further improve the trainability-estimability balance on hardware.
- Combining QTL with existing barren-plateau mitigations such as parameter initialization or circuit pruning remains an open direction that follows directly from the trade-off analysis.
Load-bearing premise
The geometric benefits of landscape sharpening can be realized without shifting the location of the true global minimum and without making the variance of the nonlinear gradient estimator grow faster than the signal itself under finite measurements.
What would settle it
A small-scale numerical optimization with a known analytic minimum in which large positive tilt values cause the optimizer to converge to a different point or require an impractically rapid growth in shot count to maintain accuracy.
Figures



read the original abstract
Variational quantum algorithms (VQAs) are leading strategies for using near-term quantum devices, with a well-studied bottleneck being their trainability. Standard expectation-value objectives with expressive circuits frequently encounter barren plateaus in the optimization landscape during training. To address this challenge, we introduce the Quantum Tilted Loss (QTL), an operator-level generalization of classical exponential tilting designed to systematically reshape the optimization landscape. By tuning a single continuous parameter, QTL can amplify gradient signals in structured settings while preserving the problem's true global minima. We provide a theoretical foundation that unifies standard expectation minimization with popular tunable heuristics, such as Conditional Value-at-Risk (CVaR) and Gibbs formulations. Deploying this framework requires balancing the geometric benefits of a sharpened landscape against the statistical cost of estimating nonlinear gradients from finite quantum measurements. We formalize this trainability-estimability trade-off, demonstrating how aggressive tilting fundamentally shifts the optimization bottleneck from landscape flatness to sample complexity. Thus, the operational bottleneck shifts from vanishing gradients to measurement sampling variance. Finally, we exhibit through numerical simulations that ascending tilt schedules can outperform fixed-tilt training in finite-shot regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Quantum Tilted Loss (QTL) as an operator-level generalization of classical exponential tilting for variational quantum algorithms (VQAs). It claims that tuning a single continuous tilting parameter amplifies gradient signals in structured settings while preserving the true global minima of the original problem, provides a theoretical unification of standard expectation minimization with heuristics such as Conditional Value-at-Risk (CVaR) and Gibbs formulations, formalizes a trainability-estimability trade-off arising from nonlinear gradient estimation, and demonstrates via numerical simulations that ascending tilt schedules outperform fixed-tilt training in finite-shot regimes.
Significance. If the central claims are rigorously established, QTL could supply a principled, tunable mechanism for reshaping VQA landscapes to mitigate barren plateaus without relocating the global minimum, while unifying several existing heuristics under one framework. The explicit treatment of the statistical cost of estimating tilted gradients and the numerical evidence for adaptive schedules represent concrete strengths that could guide practical implementations.
major comments (2)
- [Abstract and theoretical foundation] Abstract and theoretical foundation section: The claim that QTL preserves the problem’s true global minima for any tilting parameter is load-bearing for the unification and practical applicability statements. However, because QTL generalizes CVaR and Gibbs at the distribution level rather than via a strictly monotonic scalar map on the exact expectation, argmin_θ QTL(θ) coincides with argmin_θ E(θ) only when the variational state at the optimum is an eigenstate (distribution collapses to a delta). For hardware-efficient ansätze of finite depth that cannot reach the ground state, different parameters can optimize the mean versus the upper tail, shifting the effective global minimum in parameter space. This directly undermines the “preserving the problem’s true global minima” guarantee in all realistic VQA settings.
- [Trainability-estimability trade-off] Trainability-estimability trade-off section: The formalization of the shift from landscape flatness to sample complexity is presented without explicit bounds on the variance of the nonlinear gradient estimator or conditions on the tilting parameter under which the statistical cost remains polynomial. Without these, it is unclear whether the claimed amplification of gradients can be realized within the finite-shot regime that the numerical simulations address.
minor comments (2)
- [Abstract] The abstract refers to “operator-level generalization” without immediately defining the tilted operator or its relation to the standard Hamiltonian; a brief inline definition or pointer to the first equation would improve readability.
- [Numerical simulations] Numerical simulations section: The description of the ascending tilt schedule lacks details on the functional form of the schedule, the number of shots per iteration, and the precise metric used to declare outperformance; these should be stated explicitly to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive report. We address each major comment below with point-by-point responses and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and theoretical foundation] Abstract and theoretical foundation section: The claim that QTL preserves the problem’s true global minima for any tilting parameter is load-bearing for the unification and practical applicability statements. However, because QTL generalizes CVaR and Gibbs at the distribution level rather than via a strictly monotonic scalar map on the exact expectation, argmin_θ QTL(θ) coincides with argmin_θ E(θ) only when the variational state at the optimum is an eigenstate (distribution collapses to a delta). For hardware-efficient ansätze of finite depth that cannot reach the ground state, different parameters can optimize the mean versus the upper tail, shifting the effective global minimum in parameter space. This directly undermines the “preserving the problem’s true global minima” guarantee in all realistic VQA settings.
Authors: We thank the referee for identifying this key qualification. The manuscript's claim that QTL preserves the true global minima is exact when the optimal variational state is an eigenstate of the Hamiltonian, at which point the tilted loss reduces to a strictly monotonic function of the expectation value. For finite-depth ansatze that cannot express the ground state exactly, we acknowledge that the argmin in parameter space may shift because QTL acts on the full distribution rather than solely on the mean. We will revise the abstract, the theoretical foundation section, and related statements to explicitly condition the preservation claim on the ansatz being able to reach an eigenstate at optimality. This revision preserves the unification with CVaR and Gibbs (which holds at the distributional level) while accurately delimiting the guarantee for realistic VQA settings. revision: yes
-
Referee: [Trainability-estimability trade-off] Trainability-estimability trade-off section: The formalization of the shift from landscape flatness to sample complexity is presented without explicit bounds on the variance of the nonlinear gradient estimator or conditions on the tilting parameter under which the statistical cost remains polynomial. Without these, it is unclear whether the claimed amplification of gradients can be realized within the finite-shot regime that the numerical simulations address.
Authors: We agree that the trade-off section would benefit from greater quantitative detail. The formalization in the manuscript is primarily conceptual, establishing the shift of the bottleneck from vanishing gradients to measurement variance as the tilt parameter increases. Deriving general, instance-independent bounds on the variance of the nonlinear (tilted) gradient estimator that guarantee polynomial sample complexity for arbitrary Hamiltonians is technically involved and lies beyond the scope of the present work. We will revise the section to include an explicit expression for the variance of the tilted gradient estimator, discuss its dependence on the tilting parameter and the spectrum of the observable, and note the regimes (moderate tilt values) in which the sample overhead remains practical. The numerical simulations already demonstrate that ascending tilt schedules achieve better performance than fixed-tilt training under finite-shot conditions, providing empirical support for realizability even without universal polynomial bounds. revision: partial
Circularity Check
No load-bearing circularity; QTL parameter remains free and unification is explicit
full rationale
The derivation introduces QTL via an operator-level exponential tilt with a single free continuous parameter whose value is not fitted from the target objective or data. Preservation of global minima follows from the monotonicity properties of the tilt applied to the spectrum (shown via direct comparison of argmin locations), while unification with CVaR and Gibbs is obtained by taking explicit limits of the same parameter rather than by redefinition. The trainability-estimability trade-off is analyzed as a separate statistical cost, not derived from the geometric claim itself. No equation reduces a claimed prediction to a quantity defined in terms of itself, and no self-citation is invoked to establish uniqueness or forbid alternatives. The central claims therefore retain independent mathematical content.
Axiom & Free-Parameter Ledger
free parameters (1)
- tilting parameter
axioms (1)
- domain assumption Tilting preserves the location of the true global minimum
Reference graph
Works this paper leans on
-
[1]
That is, the QTL is an exact scalar post-processing of the ordinary expectation value CG(θ)—a monotone but nonlinear reshaping of the standard global cost
Monotonicity: The functionϕ γ is strictly increas- ing on[0,1]withϕ γ(0) = 0andϕ γ(x)>0 forx >0. That is, the QTL is an exact scalar post-processing of the ordinary expectation value CG(θ)—a monotone but nonlinear reshaping of the standard global cost
-
[2]
The proof is given in Appendix E 1
Faithfulness:L γ(OG, ρ(θ)) = 0⇐ ⇒C G(θ) = 0, so the tilted and untilted losses share the same global minimizers. The proof is given in Appendix E 1. The reduction property explains the visual preservation of the min- ima: in this benchmark model, the tilted loss is an exact scalar post-processing of the ordinary expectation value CG(θ). Consequently, the ...
-
[3]
Cerezo, A
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, Nature Reviews Physics3, 625–644 (2021)
2021
-
[4]
Nature Communications5(1), 4213 (2014) https://doi.org/ 10.1038/ncomms5213
A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, Nature Communications5, 10.1038/ncomms5213 (2014)
-
[5]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, and S. Gutmann, A quan- tum approximate optimization algorithm (2014), arXiv:1411.4028 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[6]
J. R. McClean, S. Boixo, V . N. Smelyanskiy, R. Bab- bush, and H. Neven, Nature Communications9, 10.1038/s41467-018-07090-4 (2018)
-
[7]
S. Wang, E. Fontana, M. Cerezo, K. Sharma, A. Sone, L. Cincio, and P. J. Coles, Nature Communications12, 10.1038/s41467-021-27045-6 (2021)
-
[8]
Ortiz Marrero, M
C. Ortiz Marrero, M. Kieferov ´a, and N. Wiebe, PRX Quantum2, 040316 (2021)
2021
-
[9]
Z. Holmes, K. Sharma, M. Cerezo, and P. J. Coles, PRX Quantum3, 10.1103/prxquantum.3.010313 (2022)
-
[10]
Larocca, S
M. Larocca, S. Thanasilp, S. Wang, K. Sharma, J. Bia- monte, P. J. Coles, L. Cincio, J. R. McClean, Z. Holmes, and M. Cerezo, Nature Reviews Physics7, 174–189 (2025)
2025
-
[11]
Kandala, A
A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, Nature549, 242–246 (2017)
2017
-
[12]
Romero, R
J. Romero, R. Babbush, J. R. McClean, C. Hempel, P. J. Love, and A. Aspuru-Guzik, Quantum Science and Tech- nology4, 014008 (2018)
2018
-
[13]
H. L. Tang, V . Shkolnikov, G. S. Barron, H. R. Grims- ley, N. J. Mayhall, E. Barnes, and S. E. Economou, PRX Quantum2, 020310 (2021)
2021
-
[14]
Stokes, J
J. Stokes, J. Izaac, N. Killoran, and G. Carleo, Quantum 4, 269 (2020)
2020
-
[15]
Grant, L
E. Grant, L. Wossnig, M. Ostaszewski, and M. Benedetti, Quantum3, 214 (2019)
2019
-
[16]
S. Sim, P. D. Johnson, and A. Aspuru-Guzik, Advanced Quantum Technologies2, 10.1002/qute.201900070 (2019)
-
[17]
Arrasmith, M
A. Arrasmith, M. Cerezo, P. Czarnik, L. Cincio, and P. J. Coles, Quantum5, 558 (2021)
2021
-
[18]
M. Cerezo, A. Sone, T. V olkoff, L. Cincio, and P. J. Coles, Nature Communications12, 10.1038/s41467-021-21728- w (2021)
-
[19]
P. K. Barkoutsos, G. Nannicini, A. Robert, I. Tavernelli, and S. Woerner, Quantum4, 256 (2020)
2020
-
[20]
L. Li, M. Fan, M. Coram, P. Riley, and S. Leichenauer, Phys. Rev. Res.2, 023074 (2020)
2020
-
[21]
Amaro, C
D. Amaro, C. Modica, M. Rosenkranz, M. Fiorentini, M. Benedetti, and M. Lubasch, Quantum Science and Technology7, 015021 (2022)
2022
-
[22]
M. Kieferova, O. M. Carlos, and N. Wiebe, Quan- tum generative training using r ´enyi divergences (2021), arXiv:2106.09567 [quant-ph]
-
[23]
Khatri, R
S. Khatri, R. LaRose, A. Poremba, L. Cincio, A. T. Sorn- borger, and P. J. Coles, Quantum3, 140 (2019)
2019
-
[24]
De Palma, M
G. De Palma, M. Marvian, D. Trevisan, and S. Lloyd, IEEE Transactions on Information Theory67, 6627–6643 (2021)
2021
-
[25]
Esscher, Skandinavisk Aktuarietidskrift15, 175 (1932)
F. Esscher, Skandinavisk Aktuarietidskrift15, 175 (1932)
1932
-
[26]
A. Ben-Tal and M. Teboulle, Math- ematical Finance17, 449 (2007), https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1467- 9965.2007.00311.x
-
[27]
Ahmadi-Javid, Journal of Optimization Theory and Applications155, 1105–1123 (2011)
A. Ahmadi-Javid, Journal of Optimization Theory and Applications155, 1105–1123 (2011)
2011
-
[28]
T. Li, A. Beirami, M. Sanjabi, and V . Smith, inICLR (2021)
2021
-
[29]
T. Li, A. Beirami, M. Sanjabi, and V . Smith, Journal of Machine Learning Research24, 1 (2023)
2023
-
[30]
F ¨ollmer and A
H. F ¨ollmer and A. Schied,Stochastic Finance: An Intro- duction in Discrete Time(De Gruyter, 2016)
2016
- [31]
-
[32]
Kubo, Journal of the Physical Society of Japan17, 1100–1120 (1962)
R. Kubo, Journal of the Physical Society of Japan17, 1100–1120 (1962)
1962
-
[33]
Touchette, Physics Reports478, 1–69 (2009)
H. Touchette, Physics Reports478, 1–69 (2009)
2009
-
[34]
Emori, Quantum statistical functions (2026), arXiv:2602.05821 [quant-ph]
H. Emori, Quantum statistical functions (2026), arXiv:2602.05821 [quant-ph]
-
[35]
R. T. Rockafellar, S. Uryasev,et al., Journal of risk2, 21 (2000)
2000
-
[36]
Pritsker, Journal of Financial Services Research12, 201 (1997)
M. Pritsker, Journal of Financial Services Research12, 201 (1997)
1997
-
[37]
A. V . Uvarov and J. D. Biamonte, Journal of Physics A: Mathematical and Theoretical54, 245301 (2021)
2021
-
[38]
Aghaei Saem, B
R. Aghaei Saem, B. Tafreshi, Z. Holmes, and S. Thanasilp, Quantum Science and Technology11, 015049 (2026)
2026
-
[39]
K. M. Nakanishi, K. Mitarai, and K. Fujii, Phys. Rev. Res. 1, 033062 (2019)
2019
-
[40]
Higgott, D
O. Higgott, D. Wang, and S. Brierley, Quantum3, 156 (2019). 20
2019
-
[41]
W. M. Kirby, A. Tranter, and P. J. Love, Quantum5, 456 (2021)
2021
-
[42]
Mitarai, M
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Phys. Rev. A98, 032309 (2018)
2018
-
[43]
Schuld, V
M. Schuld, V . Bergholm, C. Gogolin, J. Izaac, and N. Kil- loran, Phys. Rev. A99, 032331 (2019)
2019
-
[44]
Wierichs, J
D. Wierichs, J. Izaac, C. Wang, and C. Y .-Y . Lin, Quantum 6, 677 (2022)
2022
-
[45]
E. R. Anschuetz and B. T. Kiani, Nature Communications 13, 10.1038/s41467-022-35364-5 (2022)
-
[46]
S. J. W. Jorge Nocedal,Numerical Optimization (Springer-Verlag, 1999)
1999
-
[47]
Y . N. Dauphin, R. Pascanu, C. Gulcehre, K. Cho, S. Gan- guli, and Y . Bengio, inProceedings of the 28th Interna- tional Conference on Neural Information Processing Sys- tems - Volume 2, NIPS’14 (MIT Press, Cambridge, MA, USA, 2014) p. 2933–2941
2014
-
[48]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
L. Sagun, U. Evci, V . U. Guney, Y . Dauphin, and L. Bottou, Empirical analysis of the hessian of over- parametrized neural networks (2018), arXiv:1706.04454 [cs.LG]
work page Pith review arXiv 2018
-
[49]
Ghorbani, S
B. Ghorbani, S. Krishnan, and Y . Xiao, inProceedings of the 36th International Conference on Machine Learn- ing, Proceedings of Machine Learning Research, V ol. 97, edited by K. Chaudhuri and R. Salakhutdinov (PMLR,
-
[50]
T. Li, T. Zhou, and J. A. Bilmes, inProceedings of the 42nd International Conference on Machine Learning, ICML’25 (JMLR.org, 2025)
2025
-
[51]
Cerezo and P
M. Cerezo and P. J. Coles, Quantum Science and Technol- ogy6, 035006 (2021)
2021
-
[52]
Y . Huang and Y . Wang, Analysis of hessian scaling for local and global costs in variational quantum algorithm (2026), arXiv:2602.00783 [quant-ph]
-
[53]
K. Ito, W. Mizukami, and K. Fujii, Phys. Rev. Res.5, 023025 (2023)
2023
-
[54]
Farhi and A
E. Farhi and A. W. Harrow, Quantum supremacy through the quantum approximate optimization algorithm (2016)
2016
-
[55]
L. Zhou, S.-T. Wang, S. Choi, H. Pichler, and M. D. Lukin, Physical Review X10, 10.1103/phys- revx.10.021067 (2020)
-
[56]
D. Rabinovich, S. Adhikary, E. Campos, V . Ak- shay, E. Anikin, R. Sengupta, O. Lakhmanskaya, K. Lakhmanskiy, and J. Biamonte, Physical Review A 106, 10.1103/physreva.106.032418 (2022)
-
[57]
G. Adamatti Bridi, D. Lim, L. Pira, R. Azevedo Medeiros Santos, F. de Lima Marquezino, and S. Ad- hikary, Physical Review A113, 10.1103/8l54-9g97 (2026)
-
[58]
Larocca, P
M. Larocca, P. Czarnik, K. Sharma, G. Muraleedharan, P. J. Coles, and M. Cerezo, Quantum6, 824 (2022)
2022
-
[59]
E. Fontana, D. Herman, S. Chakrabarti, N. Kumar, R. Yalovetzky, J. Heredge, S. H. Sureshbabu, and M. Pis- toia, Nature Communications15, 10.1038/s41467-024- 49910-w (2024)
-
[60]
Bakalov, Frédéric Sauvage, Alexander F
M. Ragone, B. N. Bakalov, F. Sauvage, A. F. Kem- per, C. Ortiz Marrero, M. Larocca, and M. Cerezo, Na- ture Communications15, 10.1038/s41467-024-49909-3 (2024)
-
[61]
R. Mao, P. Yuan, J. Allcock, and S. Zhang, Qaoa-maxcut has barren plateaus for almost all graphs (2025)
2025
-
[62]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V . Bergholm, J. Izaac,et al., Pennylane: Automatic differentiation of hybrid quantum-classical computations (2022), arXiv:1811.04968 [quant-ph]
work page internal anchor Pith review arXiv 2022
-
[63]
Polyak, USSR Computational Mathematics and Math- ematical Physics4, 1–17 (1964)
B. Polyak, USSR Computational Mathematics and Math- ematical Physics4, 1–17 (1964)
1964
-
[64]
Kolotouros and P
I. Kolotouros and P. Wallden, Phys. Rev. Res.4, 023225 (2022)
2022
-
[65]
A. Deshpande, M. Hinsche, K. Najafi, K. Sharma, R. Sweke, and C. Zoufal, Dynamic parameterized quan- tum circuits: expressive and barren-plateau free (2025), arXiv:2411.05760 [quant-ph]
-
[66]
Huang, R
H.-Y . Huang, R. Kueng, and J. Preskill, Nature Physics 16, 1050 (2020)
2020
-
[67]
S. H. Sack, R. A. Medina, A. A. Michailidis, R. Kueng, and M. Serbyn, PRX Quantum3, 020365 (2022)
2022
-
[68]
M. J. Wainwright and M. I. Jordan, Foundations and Trends® in Machine Learning1, 1–305 (2007)
2007
-
[69]
F ¨ollmer and T
H. F ¨ollmer and T. Knispel, Stochastics and Dynamics11, 333–351 (2011)
2011
-
[70]
D. Kuhn, S. Shafiee, and W. Wiesemann, Acta Numerica 34, 579–804 (2025)
2025
-
[71]
Mas-Colell, M
A. Mas-Colell, M. D. Whinston, J. R. Green,et al.,Mi- croeconomic theory, V ol. 1 (Oxford university press New York, 1995)
1995
-
[72]
Gollier,The Economics of Risk and Time(The MIT Press, 2001) p
C. Gollier,The Economics of Risk and Time(The MIT Press, 2001) p. xv–xviii
2001
-
[73]
An Empirical Model of Large-Batch Training
S. McCandlish, J. Kaplan, D. Amodei, and O. D. Team, arXiv preprint arXiv:1812.06162 (2018)
work page Pith review arXiv 2018
-
[74]
Bottou, F
L. Bottou, F. E. Curtis, and J. Nocedal, SIAM Review60, 223 (2018)
2018
-
[75]
T. M. Cover and J. A. Thomas,Elements of Information Theory 2nd Edition (Wiley Series in Telecommunications and Signal Processing)(Wiley-Interscience, 2006)
2006
-
[76]
Brassard, P
G. Brassard, P. Hoyer, M. Mosca, and A. Tapp, AMS Con- temporary Mathematics Series305(2000)
2000
-
[77]
Poulin and P
D. Poulin and P. Wocjan, Phys. Rev. Lett.103, 220502 (2009)
2009
-
[78]
Temme, T
K. Temme, T. J. Osborne, K. V ollbrecht, D. Poulin, and F. Verstraete, Nature471, 87 (2011). 21 SUPPLEMENTAL MATERIAL Appendix A: Classical Variational Representations and Entropic Risk
2011
-
[79]
Statistics and machine learning Li et al. [26, 27] replaced the usual empirical risk minimization (ERM) with aγ-tilted empirical risk, an exponential- tilting of the per-sample/objective values that smoothly interpolates between ERM and worst-case (or best-case) be- havior and is known to relate to VaR/CVaR-type risks. Definition 1(Tilted Empirical Risk M...
-
[80]
Economic expected utility theory Classical economic treatments of decision-making under uncertainty provide a standard framework for evaluating random outcomes and formalizing risk preferences [28, 69, 70]. Three core ingredients are emphasized: (a) expected utility as a criterion for ranking uncertain payoffs and its equivalent representation via certain...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.