Recognition: unknown
From Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Pith reviewed 2026-05-08 17:33 UTC · model grok-4.3
The pith
LLM applications in materials science are shifting from standalone assistants to integrated multi-agent systems that organize knowledge and execute scientific actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action.
What carries the argument
The paper's taxonomy dividing projects into Knowledge Infrastructure systems (for structuring and validating scientific information) and Action Systems (for executing and automating work in computational or experimental environments); this split tracks the move to combined workflows.
If this is right
- Retrieval-augmented generation becomes standard grounding for reliable scientific outputs.
- Persistent structured knowledge bases enable better synthesis across papers and data.
- Multimodal inputs allow LLMs to process images, spectra, and text together in one workflow.
- Early closed-loop systems link computation directly to lab execution.
- A shared taxonomy helps researchers design and compare future LLM-enabled scientific tools.
Where Pith is reading between the lines
- If the pattern holds, research groups could build custom agents that move from literature review to experiment design without manual handoffs.
- Similar hackathons in other domains like biology or physics might produce parallel taxonomies for cross-field comparison.
- A testable next step is piloting one multi-agent system in an actual lab and tracking time saved from idea to result.
Load-bearing premise
The hackathon submissions represent the main trends and future directions for LLM use across materials science and chemistry.
What would settle it
A survey of LLM tools published in the field over the next 18 months that shows most remain single-purpose rather than integrated multi-agent systems would undermine the claimed transition.
Figures







































































































read the original abstract
Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript summarizes outcomes from the 2025 LLM Hackathon focused on materials science and chemistry. It partitions the submitted projects into two categories—Knowledge Infrastructure (systems for structuring, retrieving, synthesizing, and validating scientific information) and Action Systems (systems for executing, coordinating, or automating scientific tasks)—and extracts recurring themes including retrieval-augmented generation, persistent structured knowledge representations, multimodal/multilingual inputs, and early closed-loop laboratory integrations. The central interpretive claim is that these patterns indicate LLMs are transitioning from general-purpose assistants to composable infrastructure for scientific reasoning and action.
Significance. If the reported patterns accurately capture the hackathon submissions, the work supplies a practical taxonomy and community snapshot that could help researchers navigate emerging LLM workflows. The two-category organization is internally consistent with the described themes and provides a clear organizing lens. However, the manuscript contains no quantitative metrics, error bars, or comparative benchmarks against the wider literature, limiting its ability to support stronger claims about field-wide evolution.
major comments (1)
- [Abstract] Abstract and concluding section: the statement that the submissions 'suggest that LLMs are evolving from general-purpose assistants into composable infrastructure' rests on self-selected, short-timeline hackathon prototypes. No comparison is provided to non-hackathon deployments or the broader literature on LLM use in materials science, so the inference to a general trajectory is not load-bearing on the data presented.
minor comments (3)
- The manuscript would benefit from an explicit limitations subsection that quantifies the number of projects per category, notes the self-selection bias, and discusses how hackathon constraints (e.g., reliance on LangChain/AutoGen) may shape the observed themes.
- Project descriptions should include direct links or DOIs to the original submissions or code repositories to enable reproducibility and follow-up by readers.
- Figure captions and table headings could be expanded to clarify how individual projects map onto the two-category taxonomy.
Simulated Author's Rebuttal
We thank the referee for their constructive review of our manuscript. We agree that the central interpretive claim requires more cautious framing and have revised the abstract and conclusion accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and concluding section: the statement that the submissions 'suggest that LLMs are evolving from general-purpose assistants into composable infrastructure' rests on self-selected, short-timeline hackathon prototypes. No comparison is provided to non-hackathon deployments or the broader literature on LLM use in materials science, so the inference to a general trajectory is not load-bearing on the data presented.
Authors: We agree that the claim as originally phrased overreaches the scope of the hackathon data. The manuscript is a community snapshot of submitted projects rather than a field-wide survey. In the revised version we have changed the abstract and conclusion to state that the observed patterns 'illustrate emerging trends in the hackathon submissions toward composable multi-agent systems,' explicitly noting the self-selected and prototype nature of the entries. We have also added citations to recent reviews on LLM applications in materials science and chemistry to situate the hackathon observations within the broader literature. revision: yes
Circularity Check
No circularity: descriptive summary of external hackathon submissions
full rationale
The paper is a post-hoc community report summarizing submitted hackathon projects into Knowledge Infrastructure and Action Systems categories. It contains no derivations, equations, predictions, fitted parameters, or mathematical claims. The central inference about LLMs evolving into composable infrastructure is drawn from observed patterns in external submissions rather than from any self-referential fitting or self-citation chain. No load-bearing steps reduce to inputs by construction, and the analysis is self-contained against external benchmarks with no ansatz smuggling or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Enabling large language models for real-world materials discovery,
S. Miret and N. A. Krishnan, “Enabling large language models for real-world materials discovery,” Nature Machine Intelligence, vol. 7, no. 7, pp. 991–998, 2025
2025
-
[2]
An automatic end-to-end chemical synthesis development platform powered by large language models,
Y. Ruan, C. Lu, N. Xu, Y. He, Y. Chen, J. Zhang, J. Xuan, J. Pan, Q. Fang, H. Gao,et al., “An automatic end-to-end chemical synthesis development platform powered by large language models,” Nature communications, vol. 15, no. 1, p. 10160, 2024
2024
-
[3]
Comproscanner: a multi-agent based framework forcomposition-propertystructureddataextractionfromscientificliterature,
A. Roy, E. Grisan, J. Buckeridge, and C. Gattinoni, “Comproscanner: a multi-agent based framework forcomposition-propertystructureddataextractionfromscientificliterature,”Digital Discovery, vol.5, pp. 1794–1808, 2026
2026
-
[4]
Chemnlp: a natural language-processing-based library for materials chemistry text data,
K. Choudhary and M. L. Kelley, “Chemnlp: a natural language-processing-based library for materials chemistry text data,”The Journal of Physical Chemistry C, vol. 127, no. 35, pp. 17545–17555, 2023
2023
-
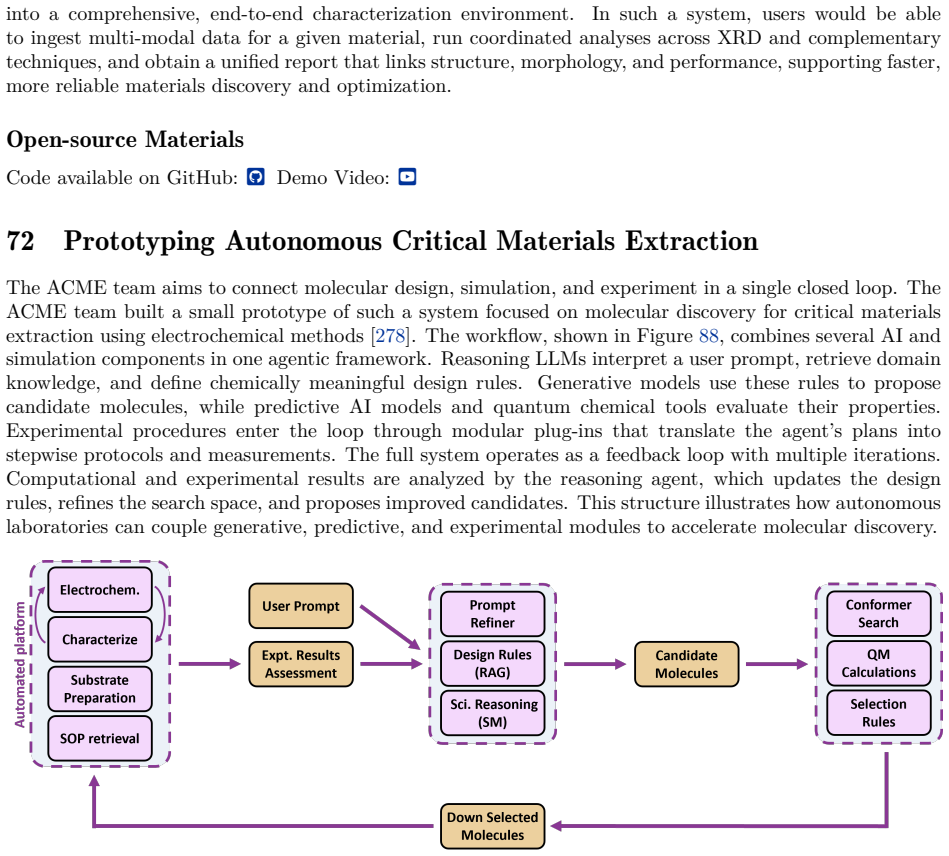
[5]
Language models enable data- augmented synthesis planning for inorganic materials,
T. Prein, E. Pan, J. Jehkul, S. Weinmann, E. Olivetti, and J. L. Rupp, “Language models enable data- augmented synthesis planning for inorganic materials,”ACS Applied Materials & Interfaces, vol. 17, no. 51, pp. 69221–69233, 2025
2025
-
[6]
Large language models for reticular chemistry,
Z. Zheng, N. Rampal, T. J. Inizan, C. Borgs, J. T. Chayes, and O. M. Yaghi, “Large language models for reticular chemistry,”Nature Reviews Materials, vol. 10, no. 5, pp. 369–381, 2025
2025
-
[7]
Towards foundation models for materials science: The open matsci ml toolkit,
K. L. K. Lee, C. Gonzales, M. Spellings, M. Galkin, S. Miret, and N. Kumar, “Towards foundation models for materials science: The open matsci ml toolkit,” inProceedings of the SC’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, pp. 51–59, 2023
2023
-
[8]
Understanding hackathons for science: Collaboration, affor- dances, and outcomes,
E. P. P. Pe-Than and J. D. Herbsleb, “Understanding hackathons for science: Collaboration, affor- dances, and outcomes,” inInternational Conference on Information, pp. 27–37, Springer, 2019
2019
-
[9]
How to support newcomers in scientific hackathons-an action research study on expert mentoring,
A. Nolte, L. B. Hayden, and J. D. Herbsleb, “How to support newcomers in scientific hackathons-an action research study on expert mentoring,”Proceedings of the ACM on Human-Computer Interaction, vol. 4, no. CSCW1, pp. 1–23, 2020
2020
-
[10]
Hack your organizational innovation: literature review and integrative model for running hackathons,
B. Heller, A. Amir, R. Waxman, and Y. Maaravi, “Hack your organizational innovation: literature review and integrative model for running hackathons,”Journal of Innovation and Entrepreneurship, vol. 12, no. 1, p. 6, 2023
2023
-
[11]
Organizing across disciplines to tackle shared computational challenges,
W. Treyde, A. Kwiatkowski, J. Achterberg, D. Akarca, M. Buttenschoen, R. T. Byrne, K. Didi, K. Kordova, J. Lála, J. Langford,et al., “Organizing across disciplines to tackle shared computational challenges,”Patterns, vol. 7, no. 4, 2026
2026
-
[12]
14 examples of how llms can transform materials science and chemistry: a reflection on a large language model hackathon,
K. M. Jablonka, Q. Ai, A. Al-Feghali, S. Badhwar, J. D. Bocarsly, A. M. Bran, S. Bringuier, L. C. Brinson, K. Choudhary, D. Circi,et al., “14 examples of how llms can transform materials science and chemistry: a reflection on a large language model hackathon,”Digital discovery, vol. 2, no. 5, pp. 1233–1250, 2023. 142
2023
-
[13]
Reflections from the 2024 large language model (llm) hackathon for applications in materials science and chemistry,
Y. Zimmermann, A. Bazgir, Z. Afzal, F. Agbere, Q. Ai, N. Alampara, A. Al-Feghali, M. Ansari, D. An- typov, A. Aswad, J. Bai, V. Baibakova, D. D. Biswajeet, E. Bitzek, J. D. Bocarsly, A. Borisova, A. M. Bran, L. C. Brinson, M. M. Calderon, A. Canalicchio, V. Chen, Y. Chiang, D. Circi, B. Charmes, V. Chaudhary, Z. Chen, M.-H. Chiu, J. Clymo, K. Dabhadkar, N...
2024
-
[14]
Large language models for chemistry robotics,
N. Yoshikawa, M. Skreta, K. Darvish, S. Arellano-Rubach, Z. Ji, L. Bjørn Kristensen, A. Z. Li, Y. Zhao, H. Xu, A. Kuramshin,et al., “Large language models for chemistry robotics,”Autonomous Robots, vol. 47, no. 8, pp. 1057–1086, 2023
2023
-
[15]
Autonomous materials synthesis laboratories: Integrating artificial intel- ligence with advanced robotics for accelerated discovery,
L. Duo, Y. Hao, and J. He, “Autonomous materials synthesis laboratories: Integrating artificial intel- ligence with advanced robotics for accelerated discovery,”ChemRxiv preprint, 2025
2025
-
[16]
Agents for self-driving laboratories applied to quantum computing,
S. Cao, Z. Zhang, M. Alghadeer, S. D. Fasciati, M. Piscitelli, M. Bakr, P. Leek, and A. Aspuru-Guzik, “Agents for self-driving laboratories applied to quantum computing,”arXiv preprint arXiv:2412.07978, 2024
-
[17]
Benchmarks and metrics for evaluations of code generation: A critical review,
D. G. Paul, H. Zhu, and I. Bayley, “Benchmarks and metrics for evaluations of code generation: A critical review,” in2024 IEEE International Conference on Artificial Intelligence Testing (AITest), pp. 87–94, IEEE, 2024
2024
-
[18]
Are large language models superhuman chemists?arXiv preprint arXiv:2404.01475,
A. Mirza, N. Alampara, S. Kunchapu, M. Ríos-García, B. Emoekabu, A. Krishnan, T. Gupta, M. Schilling-Wilhelmi, M. Okereke, A. Aneesh,et al., “Are large language models superhuman chemists?,”arXiv preprint arXiv:2404.01475, 2024
-
[19]
Rational design of high-entropy ceramics based on machine learning – a critical review,
J. Zhang, X. Xiang, B. Xu, S. Huang, Y. Xiong, S. Ma, H. Fu, Y. Ma, H. Chen, Z. Wu, and S. Zhao, “Rational design of high-entropy ceramics based on machine learning – a critical review,”Current Opinion in Solid State and Materials Science, vol. 27, p. 101057, 4 2023
2023
-
[20]
Web of science
Clarivate Analytics, “Web of science.”https://www.webofscience.com, 2025. Accessed: 2025-11-05
2025
-
[21]
Mistral-large:123b-instruct-2407-q4_0
Mistral AI, “Mistral-large:123b-instruct-2407-q4_0.”https://mistral.ai/news/mistral-large/,
-
[22]
Large Language Model by Mistral AI
-
[23]
Gpt-oss:120b
Open Source Science (OSS), “Gpt-oss:120b.”https://huggingface.co/oss/gpt-oss-120b, 2024. Open large language model for scientific applications
2024
-
[24]
Mendeleev – a python resource for properties of chemical elements, ions and isotopes,
M. Szymański, R. V. Vlasov,et al., “Mendeleev – a python resource for properties of chemical elements, ions and isotopes,”Journal of Open Source Software, vol. 3, no. 32, p. 1113, 2018
2018
-
[25]
The nomad laboratory – fair data infrastructure for materials science
NOMAD Laboratory Consortium, “The nomad laboratory – fair data infrastructure for materials science.”https://nomad-lab.eu, 2023. FAIR data platform for materials science
2023
-
[26]
Factsage thermochemical software and databases
Thermfact/CRCT and GTT-Technologies, “Factsage thermochemical software and databases.”https: //www.factsage.com, 2022. Thermochemical calculation and database system. 143
2022
-
[27]
Synthesis and neutron powder diffraction study of the superconductor HgBa2Ca2Cu3O8 +δby Tl substitution,
P. Dai, B. C. Chakoumakos, G. F. Sun, K. W. Wong, Y. Xin, and D. F. Lu, “Synthesis and neutron powder diffraction study of the superconductor HgBa2Ca2Cu3O8 +δby Tl substitution,”Physica C: Superconductivity, vol. 243, pp. 201–206, Mar. 1995
1995
-
[28]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Google, “Gemini: A Family of Highly Capable Multimodal Models,”arXiv preprint arXiv:2312.11805v5, 2025
work page internal anchor Pith review arXiv 2025
-
[29]
Exploration of crystal chemical space using text-guided generative artificial intelligence,
H. Park, A. Onwuli, and A. Walsh, “Exploration of crystal chemical space using text-guided generative artificial intelligence,”Nature Communications, vol. 16, p. 4379, 2025
2025
-
[30]
The ai revolution in science,
S. Fortunato, C. T. Bergstrom, K. Börner, J. A. Evans, D. Helbing, S. Milojević, and et al., “The ai revolution in science,”Science, vol. 359, no. 6379, p. eaao0185, 2018
2018
-
[31]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., “Language models are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[32]
On the dangers of stochastic par- rots: Can language models be too big?,
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the dangers of stochastic par- rots: Can language models be too big?,” inProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pp. 610–623, 2021
2021
-
[33]
Neural-symbolic computing: An effective methodology for principled integration of machine learning and reasoning,
A. Garcez, M. Gori, L. C. Lamb, L. Serafini, M. Spranger, and S. N. Tran, “Neural-symbolic computing: An effective methodology for principled integration of machine learning and reasoning,”Journal of Artificial Intelligence Research, vol. 74, pp. 895–946, 2022
2022
-
[35]
The dawn after the dark: An empirical study on factuality hallucination in large language models,
J. Li, J. Chen, R. Ren, X. Cheng, W. X. Zhao, J.-Y. Nie, and J.-R. Wen, “The dawn after the dark: An empirical study on factuality hallucination in large language models,”arXiv preprint arXiv:2401.03205, 2024
-
[36]
Grounding llm reasoning with knowledge graphs,
A. Amayuelas, J. Sain, S. Kaur, and C. Smiley, “Grounding llm reasoning with knowledge graphs,” 2025
2025
-
[37]
Making retrieval-augmented language models robust to irrelevant context,
O. Yoran, T. Wolfson, O. Ram, and J. Berant, “Making retrieval-augmented language models robust to irrelevant context,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[38]
Roadmap on electronic structure codes in the exascale era,
V. Gavini, S. Baroni, V. Blum, D. R. Bowler, A. Buccheri, J. R. Chelikowsky, S. Das, W. Dawson, P. Delugas, M. Dogan, C. Draxl, G. Galli, L. Genovese, P. Giannozzi, M. Giantomassi, X. Gonze, M. Govoni, F. Gygi, A. Gulans, J. M. Herbert, S. Kokott, T. D. Kühne, K.-H. Liou, T. Miyazaki, P. Motamarri, A. Nakata, J. E. Pask, C. Plessl, L. E. Ratcliff, R. M. R...
2023
-
[39]
Flexibilities of wavelets as a computational basis set for large-scale electronic structure calculations,
L. E. Ratcliff, W. Dawson, G. Fisicaro, D. Caliste, S. Mohr, A. Degomme, B. Videau, V. Cristiglio, M. Stella, M. D’Alessandro, S. Goedecker, T. Nakajima, T. Deutsch, and L. Genovese, “Flexibilities of wavelets as a computational basis set for large-scale electronic structure calculations,”The Journal of Chemical Physics, vol. 152, p. 194110, 05 2020
2020
-
[40]
BigDFT software package
BigDFT developers, “BigDFT software package.”https://l_sim.gitlab.io/bigdft-suite, 2018. A wavelet-based Density Functional Theory code. Accessed: October 2025
2018
-
[41]
Exploratory data science on supercomputers for quantum mechanical calculations,
W. Dawson, L. Beal, L. E. Ratcliff, M. Stella, T. Nakajima, and L. Genovese, “Exploratory data science on supercomputers for quantum mechanical calculations,”Electronic Structure, vol. 6, p. 027003, Jun 2024. 144
2024
-
[42]
remotemanager
remotemanager developers, “remotemanager.”https://gitlab.com/l_sim/remotemanager, 2023. Modular serialisation and management package for handling the running of functions on remote ma- chines. Accessed: October 2025
2023
-
[43]
A chemical language model for molecular taste prediction,
Y. Zimmermann, L. Sieben, H. Seng, P. Pestlin, and F. Görlich, “A chemical language model for molecular taste prediction,”Npj Sci. Food, vol. 9, p. 122, July 2025
2025
-
[44]
Magnetstein: An open-source tool for quantitative nmr mixture analysis robust to low resolution, distorted lineshapes, and peak shifts,
B. Domżał, E. K. Nawrocka, D. Gołowicz, M. A. Ciach, B. Miasojedow, K. Kazimierczuk, and A. Gam- bin, “Magnetstein: An open-source tool for quantitative nmr mixture analysis robust to low resolution, distorted lineshapes, and peak shifts,”Analytical Chemistry, vol. 96, no. 1, pp. 188–196, 2024
2024
-
[45]
Twenty years of nmrshiftdb2: A case study of an open database for analytical chemistry,
S. Kuhn, H. Kolshorn, C. Steinbeck, and N. Schlörer, “Twenty years of nmrshiftdb2: A case study of an open database for analytical chemistry,”Magnetic Resonance in Chemistry, vol. 62, no. 2, pp. 74–83, 2024
2024
-
[46]
Nmrextractor: Lever- aging large language models to construct an experimental nmr database from open-source scientific publications,
Q. Wang, W. Zhang, M. Chen, X. Li, Z. Xiong, J. Xiong, Z. Fu, and M. Zheng, “Nmrextractor: Lever- aging large language models to construct an experimental nmr database from open-source scientific publications,”Chemical Science, 2025
2025
-
[47]
Reactiont5: Apre-trainedtransformermodelforaccuratechemicalreaction prediction with limited data,
T.SagawaandR.Kojima, “Reactiont5: Apre-trainedtransformermodelforaccuratechemicalreaction prediction with limited data,”Journal of Cheminformatics, vol. 17, p. 126, 2025
2025
-
[48]
Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild
A. Abid, A. Abdalla, A. Abid, D. Khan, A. Alfozan, and J. Zou, “Gradio: Hassle-free sharing and testing of ML models in the wild,”arXiv preprint arXiv:1906.02569, June 2019
work page Pith review arXiv 1906
-
[49]
DeepSeek-V3 technical report,
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Wang, J. Chen, J. Chen, J. Yuan, J...
2024
-
[50]
A survey on data collection for machine learning: A big data - ai integration perspective,
Y. Roh, G. Heo, and S. E. Whang, “A survey on data collection for machine learning: A big data - ai integration perspective,”IEEE Transactions on Knowledge and Data Engineering, vol. 33, no. 4, pp. 1328–1347, 2021
2021
-
[51]
Structural and optical properties of highly hydroxylated fullerenes: stability of molecular domains on the c60 surface,
R. Guirado-López and M. Rincón, “Structural and optical properties of highly hydroxylated fullerenes: stability of molecular domains on the c60 surface,”The Journal of chemical physics, vol. 125, no. 15, 2006
2006
-
[52]
Functionalized fullerene: a key driver for high performance inverted perovskite solar cell,
X. Zhang, J. Zhang, D. Liu, and W. Zhang, “Functionalized fullerene: a key driver for high performance inverted perovskite solar cell,”Journal of Energy Chemistry, 2025
2025
-
[53]
Uma: A family of universal models for atoms,
B. M. Wood, M. Dzamba, X. Fu, M. Gao, M. Shuaibi, L. Barroso-Luque, K. Abdelmaqsoud, V. Gharakhanyan, J. R. Kitchin, D. S. Levine, K. Michel, A. Sriram, T. Cohen, A. Das, A. Rizvi, S. J. Sahoo, Z. W. Ulissi, and C. L. Zitnick, “Uma: A family of universal models for atoms,” 2025. 145
2025
-
[54]
crewai: Framework for orchestrating role-playing, autonomous ai agents,
“crewai: Framework for orchestrating role-playing, autonomous ai agents,” 2025. Accessed: 2025-07-11
2025
-
[55]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y. Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Ding, H. Gao, H. Qu, H. Li, J. Gu...
2025
-
[56]
Training a scientific reasoning model for chemistry,
S. M. Narayanan, J. D. Braza, R.-R. Griffiths, A. Bou, G. Wellawatte, M. C. Ramos, L. Mitchener, S. G. Rodriques, and A. D. White, “Training a scientific reasoning model for chemistry,” 2025
2025
-
[57]
Thought anchors: Which llm reasoning steps matter?,
P. C. Bogdan, U. Macar, N. Nanda, and A. Conmy, “Thought anchors: Which llm reasoning steps matter?,” 2025
2025
-
[58]
Introductory tutorials for simulating protein dynamics with gromacs,
J. A. Lemkul, “Introductory tutorials for simulating protein dynamics with gromacs,”The Journal of Physical Chemistry B, vol. 128, no. 39, pp. 9418–9435, 2024
2024
-
[59]
Streamlit: The fastest way to build data apps,
S. Inc., “Streamlit: The fastest way to build data apps,” 2025. Python library for creating interactive web apps
2025
-
[60]
Lammps - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales,
A. P. Thompson, H. M. Aktulga, R. Berger, D. S. Bolintineanu, W. M. Brown, P. S. Crozier, P. J. Doak, M. J. D’Evelyn, D. W. Engel, M. Feng, O. Gissinger, A. Hackl, H. Heinz, O. Homeyer, S. Hou, M. Ihm, G. Kresse, A. Kucukel, D. Lee, T. D. Li, Z. Y. Ma, D. M. Makarov, L. Martinez, D. M. Merz, J. A. Miller, K. A. Min, C. H. Moore, R. E. Moore, T. Müller, F....
2022
-
[61]
Gromacs: Amessage-passingparallelmolecular dynamics implementation,
H.J.Berendsen, D.vanderSpoel, andR.vanDrunen, “Gromacs: Amessage-passingparallelmolecular dynamics implementation,”Computer physics communications, vol. 91, no. 1-3, pp. 43–56, 1995
1995
-
[62]
Amber 2025,
D. A. Case, H. M. Aktulga, K. Belfon, I. Y. Ben-Shalom, J. T. Berryman, S. R. Brozell, F. S. Carvahol, D. S. Cerutti, T. E. Cheatham, G. A. Cisneros, V. W. D. Cruzeiro, T. A. Darden, N. Forouzesh, M. Ghazimirsaeed, G. Giambasu, T. Giese, M. K. Gilson, H. Gohlke, A. W. Goetz, J. Harris, Z. Huang, S. Izadi, S. A. Izmailov, K. Kasavajhala, M. C. Kaymak, I. K...
2025
-
[63]
Chatgpt (openai api),
OpenAI, “Chatgpt (openai api),” 2025. Large language model / AI service
2025
-
[64]
Oxdna. org: a public webserver for coarse-grained simulations of dna and rna nanostructures,
E. Poppleton, R. Romero, A. Mallya, L. Rovigatti, and P. Šulc, “Oxdna. org: a public webserver for coarse-grained simulations of dna and rna nanostructures,”Nucleic acids research, vol. 49, no. W1, pp. W491–W498, 2021
2021
-
[65]
Hoomd-blue: A python package for high-performance molecular dynamics and hard particle monte carlo simulations,
J. A. Anderson, J. Glaser, and S. C. Glotzer, “Hoomd-blue: A python package for high-performance molecular dynamics and hard particle monte carlo simulations,”Computational Materials Science, vol. 173, p. 109363, 2020
2020
-
[66]
Concepts for a semantically acces- sible materials data space: Overview over specific implementations in materials science,
B. Bayerlein, J. Waitelonis, H. Birkholz, M. Jung, M. Schilling, P. v. Hartrott, M. Bruns, J. Schaarschmidt, K. Beilke, M. Mutz, V. Nebel, V. Königer, L. Beran, T. Kraus, A. Vyas, L. Vogt, M. Blum, B. Ell, Y.-F. Chen, T. Waurischk, A. Thomas, A. R. Durmaz, S. Ben Hassine, C. Fresemann, G. Dziwis, H. Beygi Nasrabadi, T. Hanke, M. Telong, S. Pirskawetz, M. ...
2025
-
[67]
Seamless science: Lifting experimental mechanical testing lab data to an interoperable semantic representation,
M. Schilling, S. Bruns, B. Bayerlein, J. Kryeziu, J. Schaarschmidt, J. Waitelonis, P. Dolabella Portella, and K. Durst, “Seamless science: Lifting experimental mechanical testing lab data to an interoperable semantic representation,”Advanced Engineering Materials, vol. 27, no. 8, p. 2401527, 2025
2025
-
[68]
T. P. Schrader, M. Finco, S. Grünewald, F. Hildebrand, and A. Friedrich, “Mulms: A multi-layer annotated text corpus for information extraction in the materials science domain,”arXiv preprint arXiv:2310.15569, 2023
-
[69]
Pmd core ontology: Achieving semantic interoperability in materials science,
B. Bayerlein, M. Schilling, H. Birkholz, M. Jung, J. Waitelonis, L. Mädler, and H. Sack, “Pmd core ontology: Achieving semantic interoperability in materials science,”Materials & Design, vol. 237, p. 112603, 2024
2024
-
[70]
Bridging microscopy with molecular dynamics and quantum simulations: an atomai based pipeline,
A. Ghosh, M. Ziatdinov, O. Dyck, B. G. Sumpter, and S. V. Kalinin, “Bridging microscopy with molecular dynamics and quantum simulations: an atomai based pipeline,”npj Computational Materi- als, vol. 8, no. 1, p. 74, 2022
2022
-
[71]
M. Ziatdinov, A. Ghosh, T. Wong, and S. V. Kalinin, “Atomai: a deep learning framework for analysis of image and spectroscopy data in (scanning) transmission electron microscopy and beyond,”arXiv preprint arXiv:2105.07485, 2021
-
[72]
Localization and segmentation of atomic columns in supported nanoparticles for fast scanning transmission electron microscopy,
H. Eliasson and R. Erni, “Localization and segmentation of atomic columns in supported nanoparticles for fast scanning transmission electron microscopy,”npj Computational Materials, vol. 10, no. 1, p. 168, 2024
2024
-
[73]
Microscopy study of structural evolution in epitaxial licoo2 positive electrode films during electrochemical cycling,
H. Tan, S. Takeuchi, K. K. Bharathi, I. Takeuchi, , and L. A. Beddersky, “Microscopy study of structural evolution in epitaxial licoo2 positive electrode films during electrochemical cycling,”ACS Applied Materials & Interfaces, vol. 8, no. 10, pp. 6727–6735, 2016
2016
-
[74]
Deep learning enabled strain mapping of single-atom defects in two- dimensional transition metal dichalcogenides with sub-picometer precision,
C. Lee, A. Khan, D. Luo, T. P. Santos, C. Shi, B. E. Janicek, S. Kang, W. Zhu, N. A. Sobh, A. Schleife, B. K. Clark, and P. Huang, “Deep learning enabled strain mapping of single-atom defects in two- dimensional transition metal dichalcogenides with sub-picometer precision,”Nano Letters, vol. 20, no. 5, pp. 3369–3377, 2020
2020
-
[75]
Mechanistic insights into potassium- assistant thermal-catalytic oxidation of soot over single-crystalline srtio3 nanotubes with ordered meso- pores,
F. Fang, X. L. F. Xu, C. Chen, N. Feng, Y. Jiang, , and J. Huang, “Mechanistic insights into potassium- assistant thermal-catalytic oxidation of soot over single-crystalline srtio3 nanotubes with ordered meso- pores,”ACS Catalysis, vol. 15, no. 2, pp. 789–799, 2025
2025
-
[76]
arXiv preprint arXiv:2401.00096 , year=
I. Batatia, P. Benner, Y. Chiang, A. M. Elena, D. P. Kovács, J. Riebesell, X. R. Advincula, M. Asta, M. Avaylon, W. J. Baldwin,et al., “A foundation model for atomistic materials chemistry,”arXiv preprint arXiv:2401.00096, 2023. 147
-
[77]
New substructure filters for removal of pan assay interference com- pounds (pains) from screening libraries and for their exclusion in bioassays,
J. B. Baell and G. A. Holloway, “New substructure filters for removal of pan assay interference com- pounds (pains) from screening libraries and for their exclusion in bioassays,”Journal of Medicinal Chemistry, vol. 53, no. 7, pp. 2719–2740, 2010
2010
-
[78]
Chemistry: Chemical con artists foil drug discovery,
J. B. Baell and M. Walters, “Chemistry: Chemical con artists foil drug discovery,”Nature, vol. 513, p. 481–483, 2014
2014
-
[79]
Chemberta: Large-scale self-supervised pretraining for molecular property prediction,
S. Chithrananda, G. Grand, and B. Ramsundar, “Chemberta: Large-scale self-supervised pretraining for molecular property prediction,” 10 2020
2020
-
[80]
Neural scaling of deep chemical models,
N. Frey, R. Soklaski, S. Axelrod, S. Samsi, R. Gómez-Bombarelli, C. Coley, and V. Gadepally, “Neural scaling of deep chemical models,”Nature Machine Intelligence, vol. 5, pp. 1–9, 10 2023
2023
-
[81]
Txgemma: Efficient and agentic llms for therapeutics
E. Wang, S. Schmidgall, P. F. Jaeger, F. Zhang, R. Pilgrim, Y. Matias, J. Barral, D. Fleet, and S. Azizi, “Txgemma: Efficient and agentic llms for therapeutics,”arXiv preprint arXiv:2504.06196, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.