Population-Aware Imitation Learning in Mean-field Games with Common Noise
Pith reviewed 2026-05-07 17:19 UTC · model grok-4.3
The pith
In mean-field games with common noise, minimizing behavioral cloning or adversarial imitation proxies bounds both the exploitability of learned population-aware policies and their performance gap to the expert.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
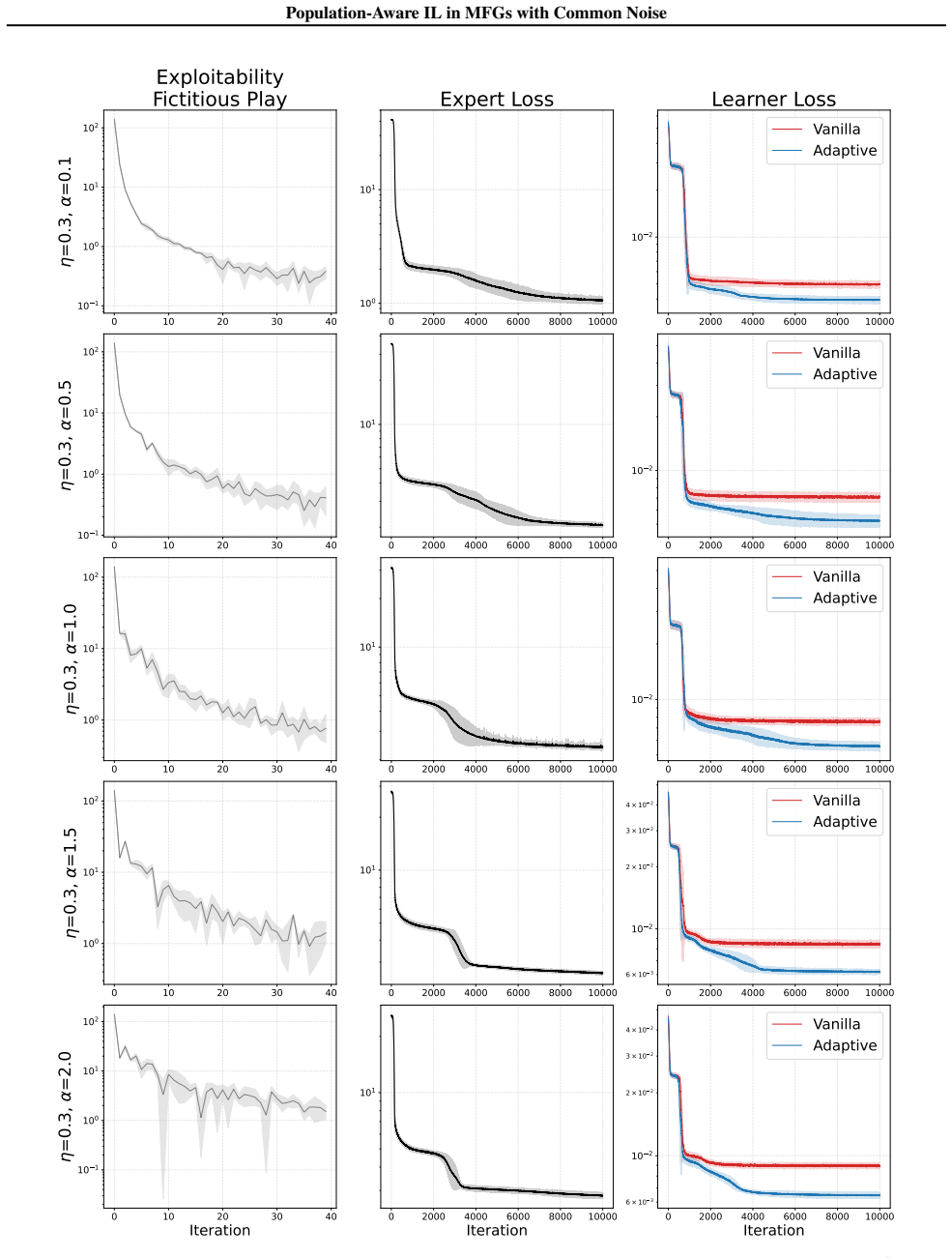
In mean-field games subject to common noise, where the population distribution evolves stochastically, population-aware imitation learning via behavioral cloning and adversarial divergence controls exploitability and the performance gap to the expert through finite-sample error bounds. A numerical method based on generalized fictitious play and deep learning computes the required expert population-aware policies. Experiments on three environments show that population-unaware policies fail to capture the equilibrium dynamics induced by common noise.
What carries the argument
The population-aware policy, which conditions actions on both an agent's individual state and the current population distribution to respond to common noise, with finite-sample error bounds that link minimization of behavioral cloning and adversarial proxies to reduced exploitability.
If this is right
- Minimizing the proxies reduces the exploitability of the resulting policy.
- The performance gap relative to the expert is controlled by the size of the proxy losses.
- Population-unaware policies cannot capture the stochastic equilibrium dynamics driven by common noise.
- Generalized fictitious play combined with deep learning yields computable expert population-aware policies.
Where Pith is reading between the lines
- The same proxy approach could be tested in other multi-agent settings that involve aggregate uncertainty rather than explicit common noise.
- Empirical checks could scale sample size and measure whether exploitability decays at the rate given by the bounds.
- The method might extend to continuous action spaces or longer horizons to test robustness beyond the reported environments.
Load-bearing premise
The mean-field game with common noise admits well-defined Nash equilibria and the behavioral cloning and adversarial proxies are sufficiently expressive to control exploitability without additional regularity conditions on the noise or dynamics.
What would settle it
An experiment in one of the three environments where increasing the number of samples used to minimize either proxy does not produce a corresponding decrease in the learned policy's exploitability or its performance gap to the expert.
Figures


















read the original abstract
Mean Field Games (MFGs) provide a powerful framework for modeling the collective behavior of large populations of interacting agents. In this paper, we address the problem of Imitation Learning (IL) in MFGs subject to common noise, where the population distribution evolves stochastically. This stochasticity compels agents to adopt population-aware policies to respond to aggregate shocks. We formulate two distinct learning objectives: recovering a Nash equilibrium and maximizing performance against an expert population. We investigate two imitation proxies: Behavioral Cloning (BC) and Adversarial (ADV) divergence. We then establish finite-sample error bounds showing that minimizing these proxies effectively controls both the policy's exploitability and its performance gap relative to the expert. Furthermore, we propose a numerical framework using generalized Fictitious Play and Deep Learning to compute expert population-aware policies. Through experiments on three environments we demonstrate that standard population-unaware policies fail to capture the equilibrium dynamics. Our results highlight that learning population-aware policies is crucial to avoid being misled by the randomness inherent in common noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses imitation learning in mean-field games (MFGs) with common noise, where the population distribution evolves stochastically. It formulates two objectives—recovering a Nash equilibrium and maximizing performance against an expert population—and investigates behavioral cloning (BC) and adversarial (ADV) divergence as imitation proxies. Finite-sample error bounds are established showing that minimizing these proxies controls the policy's exploitability and performance gap relative to the expert. A numerical framework using generalized fictitious play and deep learning is proposed to compute expert population-aware policies, with experiments on three environments demonstrating that population-unaware policies fail to capture equilibrium dynamics under common noise.
Significance. If the finite-sample bounds hold, the work extends imitation learning theory to stochastic MFG settings with common noise, providing guarantees that link proxy minimization to exploitability and expert performance gaps. This is relevant for applications involving aggregate shocks, such as traffic or financial systems. The empirical demonstration that population-awareness is necessary is a practical strength, though the absence of explicit regularity conditions on the noise process limits the immediate applicability of the bounds.
major comments (2)
- [§4] §4 (Theorems on finite-sample bounds): The error bounds for BC and ADV proxies controlling exploitability rely on the mean-field evolution under common noise admitting controlled Wasserstein distances or value function continuity. However, no explicit assumptions (e.g., Lipschitz continuity of the transition kernel, bounded noise moments, or uniform integrability) are stated or used to ensure the constants in the bounds remain finite; without these, the reduction from proxy minimization to the claimed control of exploitability does not hold in general.
- [§3] §3 (Formulation of Nash equilibria): The central claims presuppose well-defined Nash equilibria and a well-behaved exploitability measure for the stochastic MFG with common noise, but existence, uniqueness, or regularity of equilibria under the common noise process are not established or referenced, which is load-bearing for the performance gap and exploitability bounds.
minor comments (2)
- [Abstract and §5] The abstract and experimental section refer to 'three environments' without naming or briefly characterizing them (e.g., whether they are linear-quadratic, crowd navigation, or otherwise); adding this would clarify the scope of the empirical validation.
- [§2] Notation for the population measure under common noise (e.g., the stochastic process μ_t) could be clarified with an explicit definition of the filtration or the common noise variable in the preliminaries to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the theoretical foundations.
read point-by-point responses
-
Referee: §4 (Theorems on finite-sample bounds): The error bounds for BC and ADV proxies controlling exploitability rely on the mean-field evolution under common noise admitting controlled Wasserstein distances or value function continuity. However, no explicit assumptions (e.g., Lipschitz continuity of the transition kernel, bounded noise moments, or uniform integrability) are stated or used to ensure the constants in the bounds remain finite; without these, the reduction from proxy minimization to the claimed control of exploitability does not hold in general.
Authors: We agree that the finite-sample bounds require explicit regularity assumptions for the constants to remain finite and the implications to hold rigorously. In the revised manuscript, we will add a new subsection in §4 detailing the necessary conditions, including Lipschitz continuity of the transition kernel in the Wasserstein metric, bounded moments of the common noise process, and uniform integrability. These will be supported by references to standard results in the MFG literature with common noise. We will also verify that the three experimental environments satisfy these conditions, ensuring the bounds apply directly. revision: yes
-
Referee: §3 (Formulation of Nash equilibria): The central claims presuppose well-defined Nash equilibria and a well-behaved exploitability measure for the stochastic MFG with common noise, but existence, uniqueness, or regularity of equilibria under the common noise process are not established or referenced, which is load-bearing for the performance gap and exploitability bounds.
Authors: We acknowledge that the manuscript does not explicitly reference or establish existence and uniqueness results for Nash equilibria under common noise. In the revision, we will add a remark in §3 citing established results from the MFG literature (e.g., Carmona et al. on stochastic MFGs with common noise) that guarantee existence and uniqueness under standard conditions such as monotonicity or convexity of costs. We will also clarify the regularity assumptions ensuring the exploitability measure is well-defined and continuous, without claiming new existence proofs, as our focus is on imitation learning given such equilibria. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives finite-sample error bounds for behavioral cloning and adversarial proxies in population-aware imitation learning for mean-field games with common noise. These bounds are obtained by applying standard imitation learning theory (controlling exploitability and performance gaps) to the MFG setting with stochastic population measures induced by common noise. No step reduces a claimed prediction or result to a fitted input, self-definition, or load-bearing self-citation by construction; the central claims rest on the expressiveness of the proxies and well-defined Nash equilibria under the stated dynamics, which are treated as external inputs rather than derived from the paper's own fitted quantities. The approach is self-contained against prior IL and MFG results without renaming known patterns or smuggling ansatzes via citation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existence of Nash equilibrium in the MFG with common noise
- domain assumption Behavioral cloning and adversarial proxies can be minimized to control exploitability
Reference graph
Works this paper leans on
-
[1]
and Lauri`ere, M
Achdou, Y . and Lauri`ere, M. Mean field games and applica- tions: Numerical aspects.Mean Field Games: Cetraro, Italy 2019, pp. 249–307,
2019
-
[2]
Bassou, L., Djete, M. F., and Touzi, N. Mean field game of mutual holding with common noise.arXiv:2403.16232,
-
[3]
Firoozi, D., Caines, P. E., and Jaimungal, S. Mean field game systems with common noise and Markovian latent processes.arXiv:1809.07865,
-
[4]
9 Population-Aware IL in MFGs with Common Noise Gu, Z., Lauriere, M., Merkel, S., and Payne, J. Global solu- tions to master equations for continuous time heteroge- neous agent macroeconomic models.arXiv:2406.13726,
-
[5]
Mean field games and applications
Gu´eant, O., Lasry, J.-M., and Lions, P.-L. Mean field games and applications. InParis-Princeton lectures on mathe- matical finance 2010, pp. 205–266. Springer,
2010
-
[6]
URL http://projecteuclid.org/ euclid.cis/1183728987
ISSN 1526-7555. URL http://projecteuclid.org/ euclid.cis/1183728987. Lasry, J.-M. and Lions, P.-L. Mean field games.Jpn. J. Math., 2(1):229–260,
-
[7]
ISSN 0289-2316. doi: 10.1007/s11537-007-0657-8. URL http://dx.DOI. org/10.1007/s11537-007-0657-8. Lasry, J.-M., Lions, P.-L., and Gu ´eant, O. Applica- tion of mean field games to growth theory. HAL preprint, hal-00348376,
-
[8]
URL https:// hal.science/hal-00348376. Lavigne, P. and Tankov, P. Decarbonization of financial markets: a mean-field game approach.arXiv:2301.09163,
-
[9]
Ramponi, G., Kolev, P., Pietquin, O., He, N., Lauri `ere, M., and Geist, M
doi: 10.1609/aaai.v36i9.21173. Ramponi, G., Kolev, P., Pietquin, O., He, N., Lauri `ere, M., and Geist, M. On imitation in mean-field games. Advances in Neural Information Processing Systems, 36,
-
[10]
Vu, H. and Ichiba, T. Heterogenous macro-finance model: A mean-field game approach.arXiv:2502.10666,
-
[11]
H−1X n=0 ∥ρ1 n −ρ 2 n∥1 # +r maxE
10 Population-Aware IL in MFGs with Common Noise A. Useful Inequalities First we extend (Ramponi et al., 2023, Lemma 2 C.4). Lemma A.1.Under Assumptions 2.3 and 2.4, for any policiesπ 1, π2, π3 ∈Π, we have: |V(π 3, π1)−V(π 3, π2)| ≤L rE "H−1X n=0 ∥ρ1 n −ρ 2 n∥1 # +r maxE "H−1X n=0 ∥ρ1,3 n −ρ 2,3 n ∥1 # +r max H−1X n=0 E h EX∼ρ 2,3 n ∥π3 n(X, ρ1 n)−π 3 n(X...
2023
-
[12]
Left: variation across α with fixed η; Right: variation across η with fixedα
Figure 12.Performance metrics for 5 runs in the Beach Bar environment. Left: variation across α with fixed η; Right: variation across η with fixedα. 26 Population-Aware IL in MFGs with Common Noise 0.1 0.2 0.3 0.4 0.5 0.10.51.01.52.0 Behavioral Cloning 0.90 0.50 0.27 0.11 0.08 0.82 0.52 0.41 0.27 0.15 0.62 0.42 0.37 0.31 0.22 0.55 0.43 0.35 0.32 0.26 0.53...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.