Recognition: 2 theorem links
· Lean TheoremStage Light is Sequence²: Multi-Light Control via Imitation Learning
Pith reviewed 2026-05-08 18:13 UTC · model grok-4.3
The pith
SeqLight generates synchronized multi-light stage effects from music by first predicting global colors then decomposing them via imitation learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SeqLight maps music to multi-light HSV space through a hierarchical framework: SkipBART first predicts the full light color distribution per frame, after which a hybrid imitation learning pipeline solves the decomposition task as a Goal-Conditioned Markov Decision Process by constructing an expert demonstration set inspired by Hindsight Experience Replay and applying a three-phase training procedure, achieving strong generalization across venue-specific lighting configurations.
What carries the argument
The light decomposition module, which frames the assignment of global colors to individual lights as a Goal-Conditioned Markov Decision Process solved by hybrid imitation learning with Hindsight Experience Replay-inspired demonstrations.
If this is right
- The same trained decomposition module can be reused across venues that differ in light count and placement without retraining from scratch.
- End-to-end single-light models can be extended to multi-light output by inserting the learned decomposition stage rather than retraining the entire network.
- Quantitative metrics and human preference scores can be used to compare the imitation-learned policy against direct regression baselines for the decomposition task.
- The three-phase training pipeline provides a reproducible method for turning mixed-light recordings into goal-conditioned expert data for other control problems.
Where Pith is reading between the lines
- The separation into global generation and local decomposition steps may make it easier to inspect or edit the color distribution before it is split among lights.
- If the imitation learning policy generalizes as claimed, it could be applied to other synchronized multi-device problems such as distributed video projection or robotic light positioning.
- Because training uses only mixed data, the method might enable rapid deployment in temporary installations where collecting venue-specific demonstrations is impractical.
Load-bearing premise
That a decomposition policy trained only on mixed light data without professional demonstrations will still produce coherent and effective multi-light assignments when the number or positions of lights change.
What would settle it
A controlled test in which the trained policy is applied to a new venue with a different number of lights or layout and the resulting light sequences are rated lower than both random assignment and professional manual control in a blinded human study.
Figures
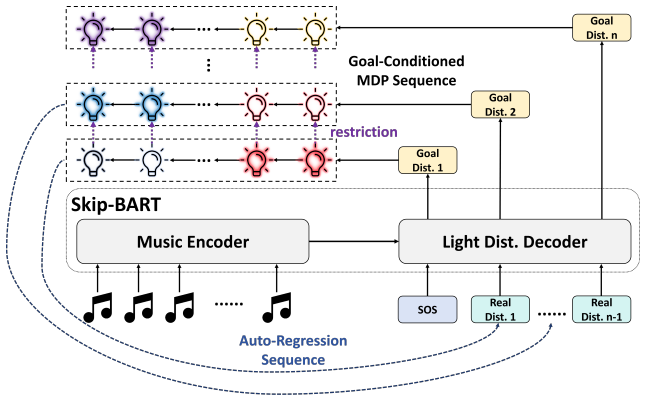





read the original abstract
Music-inspired Automatic Stage Lighting Control (ASLC) has gained increasing attention in recent years due to the substantial time and financial costs associated with hiring and training professional lighting engineers. However, existing methods suffer from several notable limitations: the low interpretability of rule-based approaches, the restriction to single-primary-light control in music-to-color-space methods, and the limited transferability of music-to-controlling-parameter frameworks. To address these gaps, we propose SeqLight, a hierarchical deep learning framework that maps music to multi-light Hue-Saturation-Value (HSV) space. Our approach first customizes SkipBART, an end-to-end single primary light generation model, to predict the full light color distribution for each frame, followed by hybrid Imitation Learning (IL) techniques to derive an effective decomposition strategy that distributes the global color distribution among individual lights. Notably, the light decomposition module can be trained under varying venue-specific lighting configurations using only mixed light data and no professional demonstrations, thereby flexibly adapting across diverse venues. In this stage, we formulate the light decomposition task as a Goal-Conditioned Markov Decision Process (GCMDP), construct an expert demonstration set inspired by Hindsight Experience Replay (HER), and introduce a three-phase IL training pipeline, achieving strong generalization capability. To validate our IL solution for the proposed GCMDP, we conduct a series of quantitative analysis and human study. The code and trained models are provided at https://github.com/RS2002/SeqLight .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SeqLight, a hierarchical deep learning framework for music-inspired automatic stage lighting control. It first customizes SkipBART to generate per-frame global light color distributions in HSV space from music input, then applies hybrid imitation learning to decompose these distributions across multiple individual lights. The decomposition is formulated as a Goal-Conditioned Markov Decision Process (GCMDP) with expert demonstrations constructed via Hindsight Experience Replay (HER) from mixed light data only (no professional demonstrations), enabling training under varying venue configurations. The authors claim strong generalization across venues and validate via quantitative analysis plus human study, with code and models released.
Significance. If the central claims hold, this could meaningfully advance practical automation of stage lighting by addressing single-light restrictions and poor transferability in prior work. The HER-inspired synthetic expert construction from mixed data is a creative way to sidestep the need for professional demonstrations, and the explicit release of code and trained models is a clear strength for reproducibility and follow-on research.
major comments (2)
- [GCMDP formulation and IL training pipeline] GCMDP formulation and three-phase IL pipeline: the claim that the policy generalizes to arbitrary venue-specific light counts, positions, and intensities rests on relabeling trajectories in color-distribution space alone; without venue parameters in the state/reward or explicit physical constraints, it is unclear whether the resulting per-light HSV assignments will respect hardware limits or transfer beyond the training mixtures. This is load-bearing for the 'flexibly adapting across diverse venues' assertion.
- [Quantitative analysis and human study] Validation section: the abstract states that quantitative analysis and a human study were conducted to validate the IL solution, yet no concrete metrics, baselines, ablation results, or error measures are referenced; the full paper must supply these (e.g., success rates on held-out venue configs, comparison to rule-based or single-light baselines) to substantiate the generalization claim.
minor comments (2)
- [Methods] The introduction of 'SkipBART' and 'GCMDP' would benefit from a short paragraph relating them to the original BART architecture and standard goal-conditioned RL formulations, respectively.
- [Notation and figures] Notation for HSV decomposition and the hybrid IL phases should be made consistent between text and any pseudocode or diagrams.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and the constructive major comments. We address each point below and will revise the manuscript to provide additional clarifications and details.
read point-by-point responses
-
Referee: [GCMDP formulation and IL training pipeline] GCMDP formulation and three-phase IL pipeline: the claim that the policy generalizes to arbitrary venue-specific light counts, positions, and intensities rests on relabeling trajectories in color-distribution space alone; without venue parameters in the state/reward or explicit physical constraints, it is unclear whether the resulting per-light HSV assignments will respect hardware limits or transfer beyond the training mixtures. This is load-bearing for the 'flexibly adapting across diverse venues' assertion.
Authors: The GCMDP formulation conditions the policy on the goal global color distribution, which is independent of specific venue details. Expert demonstrations are synthesized via HER applied to mixed light data, enabling the policy to learn general decomposition strategies that adapt to varying light counts and positions during training. The three-phase IL pipeline supports this by progressively refining the policy. We agree that explicit discussion of how variable configurations are accommodated and any hardware constraints are handled would strengthen the presentation. We will revise the manuscript to expand the GCMDP and IL sections with a clearer description of the state representation, reward design, and generalization mechanism. revision: yes
-
Referee: [Quantitative analysis and human study] Validation section: the abstract states that quantitative analysis and a human study were conducted to validate the IL solution, yet no concrete metrics, baselines, ablation results, or error measures are referenced; the full paper must supply these (e.g., success rates on held-out venue configs, comparison to rule-based or single-light baselines) to substantiate the generalization claim.
Authors: We agree that concrete metrics, baselines, and ablations are necessary to fully substantiate the generalization claims. Although the abstract notes that quantitative analysis and a human study were performed, we will revise the manuscript to ensure the validation section explicitly supplies these elements, including success rates on held-out venue configurations, comparisons against rule-based and single-light baselines, ablation results on the IL pipeline, and detailed human study outcomes with error measures. We will also update the abstract to reference key quantitative findings. revision: yes
Circularity Check
No significant circularity in the SeqLight derivation chain
full rationale
The paper's core derivation consists of two sequential stages: (1) customizing SkipBART to map music to a global per-frame HSV color distribution, and (2) formulating light decomposition as a GCMDP whose policy is trained by a three-phase IL pipeline whose expert demonstrations are constructed from mixed-light trajectories via a standard HER-inspired relabeling procedure. Neither stage reduces to a self-definitional loop, a fitted parameter renamed as a prediction, or a load-bearing self-citation; the HER construction operates on external mixed data rather than presupposing the target per-light assignments, and the resulting policy is evaluated on held-out quantitative metrics and human studies. The approach therefore remains self-contained against external benchmarks and receives a score of 0.
Axiom & Free-Parameter Ledger
free parameters (1)
- SkipBART and IL model parameters
axioms (2)
- domain assumption Music signals contain sufficient information to predict coherent light color distributions
- domain assumption Imitation learning from mixed-light observations can produce generalizable decomposition policies
invented entities (2)
-
SkipBART
no independent evidence
-
GCMDP formulation for light decomposition
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ KL divergence as the distance metric ... the direction of the KL divergence is chosen following the principle of Variational Autoencoders
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Automatic chord recognition technique for a music visualizer application,
P. Mabpa, T. Sapaklom, E. Mujjalinvimut, J. Kunthong, and P. N. N. Ayudhya, “Automatic chord recognition technique for a music visualizer application,” in2021 9th International Electrical Engineering Congress (iEECON), pp. 416–419, IEEE, 2021
2021
-
[2]
Auditory and visual based intelligent lighting design for music concerts,
E. O. Bonde, E. K. Hansen, and G. Triantafyllidis, “Auditory and visual based intelligent lighting design for music concerts,”Eai Endrosed Trasactions on Creative Technologies, vol. 5, no. 15, p. e2, 2018
2018
-
[3]
Automatic visual effect adjustment system,
Y .-P. Liao, D.-C. Chen, and B.-H. Chen, “Automatic visual effect adjustment system,” in2023 International Automatic Control Conference (CACS), pp. 1–6, IEEE, 2023
2023
-
[4]
Automatic stage lighting control: Is it a rule- driven process or generative task?,
Z. Zhao, D. Jin, Z. Zhou, and X. Zhang, “Automatic stage lighting control: Is it a rule- driven process or generative task?,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
Illuminating music: Impact of color hue for background lighting on emotional arousal in piano performance videos,
J. McDonald, S. Canazza, A. Chmiel, G. De Poli, E. Houbert, M. Murari, A. Rodà, E. Schubert, and J. D. Zhang, “Illuminating music: Impact of color hue for background lighting on emotional arousal in piano performance videos,”Frontiers in Psychology, vol. 13, p. 828699, 2022
2022
-
[6]
Let network decide what to learn: Symbolic music understanding model based on large-scale adversarial pre-training,
Z. Zhao, “Let network decide what to learn: Symbolic music understanding model based on large-scale adversarial pre-training,” inProceedings of the 2025 International Conference on Multimedia Retrieval, pp. 2128–2132, 2025
2025
-
[7]
Lightinggen: A dmx based generation method for entertainment stage lighting,
T. Wang, Y . Jiang, W. Jiang, X. Zhou, and X. Guan, “Lightinggen: A dmx based generation method for entertainment stage lighting,”IEEE Transactions on Multimedia, 2026
2026
-
[8]
Hindsight experience replay,
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. To- bin, O. Pieter Abbeel, and W. Zaremba, “Hindsight experience replay,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[9]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013
work page Pith review arXiv 2013
-
[10]
A survey on transfer learning,
S. J. Pan and Q. Yang, “A survey on transfer learning,”IEEE Transactions on knowledge and data engineering, vol. 22, no. 10, pp. 1345–1359, 2009
2009
-
[11]
Learning robust rewards with adverserial inverse reinforcement learning,
J. Fu, K. Luo, and S. Levine, “Learning robust rewards with adverserial inverse reinforcement learning,” inInternational Conference on Learning Representations, 2018
2018
-
[12]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[13]
arXiv preprint arXiv:1611.03852 , year=
C. Finn, P. Christiano, P. Abbeel, and S. Levine, “A connection between generative adver- sarial networks, inverse reinforcement learning, and energy-based models,”arXiv preprint arXiv:1611.03852, 2016
-
[14]
Generative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,”Advances in neural information processing systems, vol. 27, 2014
2014
-
[15]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[16]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High-dimensional continuous control using generalized advantage estimation,”arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review arXiv 2015
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu,et al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024. 10
work page internal anchor Pith review arXiv 2024
-
[18]
Development and evaluation of a mixed reality music visualization for a live performance based on music information retrieval,
M. Erdmann, M. von Berg, and J. Steffens, “Development and evaluation of a mixed reality music visualization for a live performance based on music information retrieval,”Frontiers in Virtual Reality, vol. 6, p. 1552321, 2025
2025
-
[19]
Methodology for stage lighting control based on music emotions,
S.-W. Hsiao, S.-K. Chen, and C.-H. Lee, “Methodology for stage lighting control based on music emotions,”Information sciences, vol. 412, pp. 14–35, 2017
2017
-
[20]
Mood lighting system reflecting music mood,
C. B. Moon, H. Kim, D. W. Lee, and B. M. Kim, “Mood lighting system reflecting music mood,” Color Research & Application, vol. 40, no. 2, pp. 201–212, 2015
2015
-
[21]
Automatic control system for stage lights,
I.-D. Stanescu, B.-A. Enache, G.-C. Seritan, S.-D. Grigorescu, F.-C. Argatu, and F.-C. Adochiei, “Automatic control system for stage lights,” in2018 International Symposium on Fundamentals of Electrical Engineering (ISFEE), pp. 1–4, IEEE, 2018
2018
-
[22]
Music-driven lighting manipulation for stage performance visual design,
J. Lei, M. Chen, Z. Wang, Y . Wang, and J. Lin, “Music-driven lighting manipulation for stage performance visual design,” inTwelfth International Conference on Graphics and Image Processing (ICGIP 2020), vol. 11720, pp. 646–655, SPIE, 2021
2020
-
[23]
Automatic stage illumination control system by impression of the lyrics and music tune,
M. Kanno and Y . Fukuhara, “Automatic stage illumination control system by impression of the lyrics and music tune,” in2022 13th International Congress on Advanced Applied Informatics Winter (IIAI-AAI-Winter), pp. 219–224, IEEE, 2022
2022
-
[24]
Avai: A tool for expressive music visualization based on autoencoders and constant q transformation,
S. B. Tyroll, D. Overholt, and G. Palamas, “Avai: A tool for expressive music visualization based on autoencoders and constant q transformation,” in17th Sound and Music Computing Conference, pp. 378–385, Axea sas/SMC Network, 2020
2020
-
[25]
Glow with the flow: Ai-assisted creation of ambient lightscapes for music videos,
F. A. Robinson, V . Raj, D. Cooper, F. Du, and D. Gunawan, “Glow with the flow: Ai-assisted creation of ambient lightscapes for music videos,”arXiv preprint arXiv:2602.08838, 2026
-
[26]
A survey of imitation learning: Algorithms, recent developments, and challenges,
M. Zare, P. M. Kebria, A. Khosravi, and S. Nahavandi, “A survey of imitation learning: Algorithms, recent developments, and challenges,”IEEE Transactions on Cybernetics, vol. 54, no. 12, pp. 7173–7186, 2024
2024
-
[27]
Offline inverse reinforcement learning for joint optimization of energy costs and demand charge in industrial pv-battery load systems,
Y . Hu and S. Li, “Offline inverse reinforcement learning for joint optimization of energy costs and demand charge in industrial pv-battery load systems,”Applied Energy, vol. 408, p. 127416, 2026
2026
-
[28]
Equilibrium inverse reinforcement learning for ride-hailing vehicle network,
T. Oda, “Equilibrium inverse reinforcement learning for ride-hailing vehicle network,” in Proceedings of the Web Conference 2021, pp. 2281–2290, 2021
2021
-
[29]
Energy-efficient and damage-recovery slithering gait design for a snake-like robot based on reinforcement learning and inverse reinforcement learning,
Z. Bing, C. Lemke, L. Cheng, K. Huang, and A. Knoll, “Energy-efficient and damage-recovery slithering gait design for a snake-like robot based on reinforcement learning and inverse reinforcement learning,”Neural Networks, vol. 129, pp. 323–333, 2020
2020
-
[30]
A survey of inverse reinforcement learning: Challenges, methods and progress,
S. Arora and P. Doshi, “A survey of inverse reinforcement learning: Challenges, methods and progress,”Artificial Intelligence, vol. 297, p. 103500, 2021
2021
-
[31]
Apprenticeship learning via inverse reinforcement learning,
P. Abbeel and A. Y . Ng, “Apprenticeship learning via inverse reinforcement learning,” in Proceedings of the twenty-first international conference on Machine learning, p. 1, 2004
2004
-
[32]
Maximum entropy inverse reinforcement learning.,
B. D. Ziebart, A. L. Maas, J. A. Bagnell, A. K. Dey,et al., “Maximum entropy inverse reinforcement learning.,” inAaai, vol. 8, pp. 1433–1438, Chicago, IL, USA, 2008
2008
-
[33]
Generative adversarial imitation learning,
J. Ho and S. Ermon, “Generative adversarial imitation learning,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[34]
Guided cost learning: Deep inverse optimal control via policy optimization,
C. Finn, S. Levine, and P. Abbeel, “Guided cost learning: Deep inverse optimal control via policy optimization,” inInternational conference on machine learning, pp. 49–58, PMLR, 2016
2016
-
[35]
Z. Zhao and S. Li, “One step is enough: Multi-agent reinforcement learning based on one-step policy optimization for order dispatch on ride-sharing platforms,”arXiv preprint arXiv:2507.15351, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Accurate translucent material rendering under spherical gaussian lights,
L.-Q. Yan, Y . Zhou, K. Xu, and R. Wang, “Accurate translucent material rendering under spherical gaussian lights,” inComputer Graphics Forum, vol. 31, pp. 2267–2276, Wiley Online Library, 2012
2012
-
[37]
Visualizing with vtk: a tutorial,
W. J. Schroeder, L. S. Avila, and W. Hoffman, “Visualizing with vtk: a tutorial,”IEEE Computer graphics and applications, vol. 20, no. 5, pp. 20–27, 2000
2000
-
[38]
Vector morphological operators in hsv color space,
T. Lei, Y . Wang, Y . Fan, and J. Zhao, “Vector morphological operators in hsv color space,” Science China Information Sciences, vol. 56, no. 1, pp. 1–12, 2013
2013
-
[39]
I am a singer
C. of Hunan Television, “I am a singer.”
-
[40]
Sound of my dream
C. of Zhejiang Television, “Sound of my dream.”
-
[41]
Look, listen, and learn more: Design choices for deep audio embeddings,
A. L. Cramer, H.-H. Wu, J. Salamon, and J. P. Bello, “Look, listen, and learn more: Design choices for deep audio embeddings,” inICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3852–3856, IEEE, 2019
2019
-
[42]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga,et al., “Pytorch: An imperative style, high-performance deep learning library. arxiv 2019,”arXiv preprint arXiv:1912.01703, vol. 10, 1912
work page internal anchor Pith review arXiv 2019
-
[43]
Benchmarking music emotion recognition sys- tems,
A. Alajanki, Y .-H. Yang, and M. Soleymani, “Benchmarking music emotion recognition sys- tems,”PloS one, pp. 835–838, 2016
2016
-
[44]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[45]
Mapping emotion to color,
N. A. Nijdam, “Mapping emotion to color,”Book Mapping emotion to color, pp. 2–9, 2009. 12 Appendix Contents A Related Work 14 A.1 Automatic Stage Light Control . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 A.2 Imitation Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B Function Definition 15 C Network Architect...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.