Recognition: unknown
Amortized Variational Inference for Joint Posterior and Predictive Distributions in Bayesian Uncertainty Quantification
Pith reviewed 2026-05-07 13:04 UTC · model grok-4.3
The pith
A joint variational approach directly approximates both the parameter posterior and the posterior-predictive distribution in an amortized manner.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a variational Bayesian framework that directly targets the posterior-predictive distribution and jointly learns variational approximations of both the posterior and the corresponding predictive distribution. The formulation introduces a variational upper bound on the Kullback-Leibler divergence together with moment-based regularization terms. The variational distributions are trained in an amortized manner, shifting computational effort to an offline stage and enabling efficient online inference. Numerical experiments demonstrate that the proposed method achieves more accurate predictive distributions than conventional two-stage variational inference, while substantially reducing
What carries the argument
The variational upper bound on the predictive KL divergence combined with moment-based regularization terms, enabling amortized joint learning of posterior and predictive distributions.
If this is right
- More accurate predictive distributions than conventional two-stage variational inference.
- Substantially reduced computational cost for online predictive inference.
- Applicable to high-fidelity models such as those governed by partial differential equations.
- Amortized training shifts effort to offline stage for fast online evaluations.
Where Pith is reading between the lines
- The joint approximation may prevent error accumulation that occurs when posterior and predictive steps are handled separately.
- This framework could support real-time uncertainty quantification in applications requiring repeated predictions.
- Similar amortization techniques might extend to other sequential Bayesian computations involving expensive propagations.
- Further validation on larger scale problems would clarify the method's scalability beyond the tested finite-element example.
Load-bearing premise
The variational upper bound on the predictive KL divergence together with the moment-based regularization terms produce a sufficiently tight and unbiased approximation to the true posterior-predictive without requiring the conventional two-stage separation.
What would settle it
A direct comparison on the finite-element solid mechanics problem where the proposed method fails to produce lower error in predictive distributions or higher online inference times than two-stage variational inference would falsify the claims.
Figures







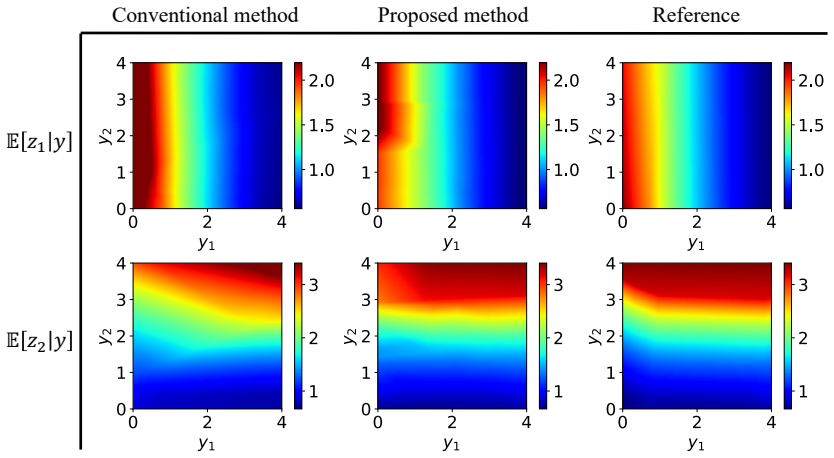
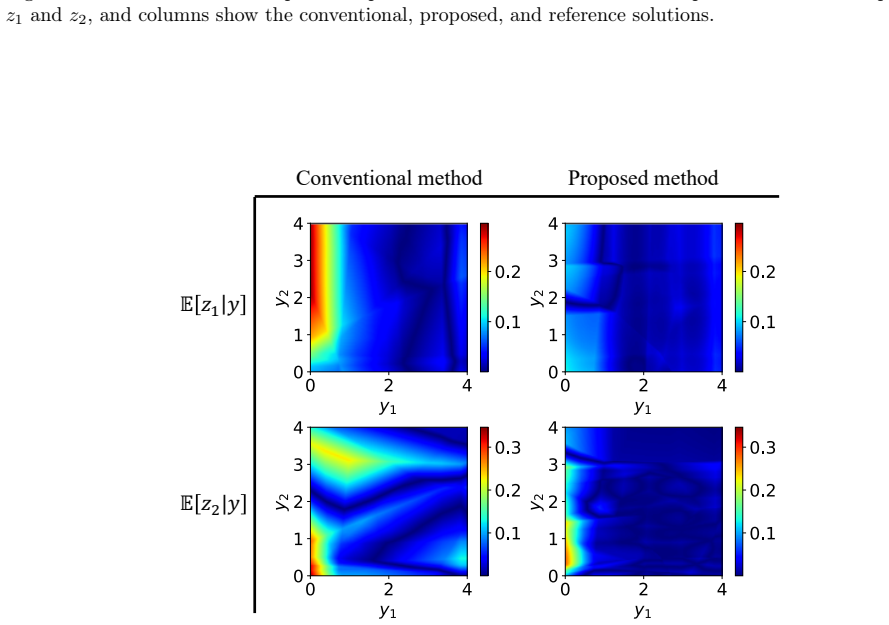



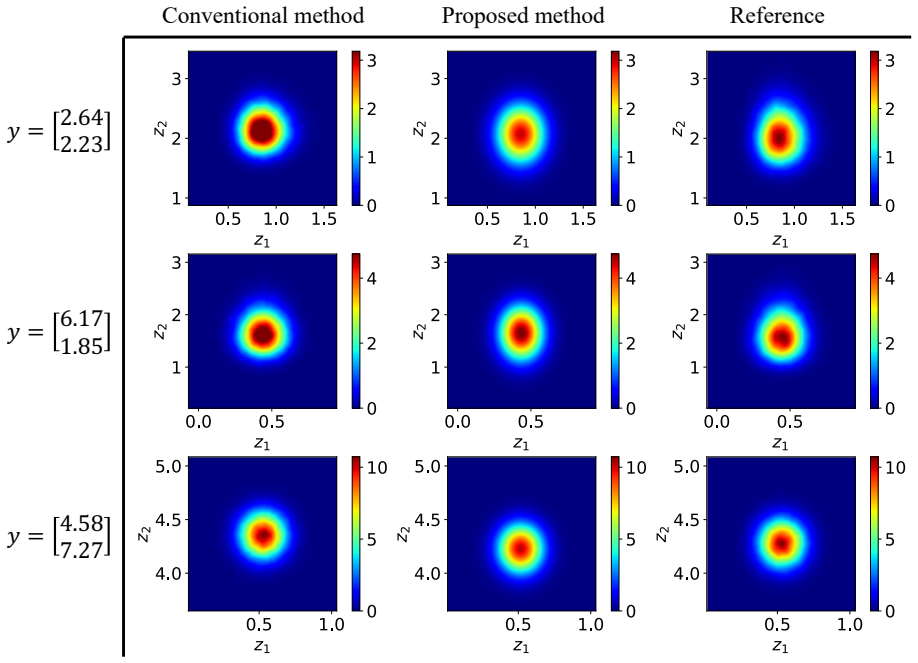








read the original abstract
Bayesian predictive inference propagates parameter uncertainty to quantities of interest through the posterior-predictive distribution. In practice, this is typically performed using a two-stage procedure: first approximating the posterior distribution of model parameters, and then propagating posterior samples through the predictive model via Monte Carlo simulation. This sequential workflow can be computationally demanding, particularly for high-fidelity models such as those governed by partial differential equations. We propose a variational Bayesian framework that directly targets the posterior-predictive distribution and jointly learns variational approximations of both the posterior and the corresponding predictive distribution. The formulation introduces a variational upper bound on the Kullback--Leibler divergence together with moment-based regularization terms. The variational distributions are trained in an amortized manner, shifting computational effort to an offline stage and enabling efficient online inference. Numerical experiments ranging from analytical benchmarks to a finite-element solid mechanics problem demonstrate that the proposed method achieves more accurate predictive distributions than conventional two-stage variational inference, while substantially reducing the cost of online predictive inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an amortized variational inference framework that jointly targets the posterior distribution of model parameters and the posterior-predictive distribution. It replaces the conventional two-stage workflow (posterior approximation followed by Monte Carlo propagation) with a single variational upper bound on the predictive KL divergence, augmented by moment-based regularization terms. The variational distributions are trained offline in an amortized manner to enable low-cost online predictive inference. Experiments on analytical benchmarks and a finite-element solid mechanics problem are presented as evidence that the method yields more accurate predictive distributions at substantially lower online cost than standard two-stage variational inference.
Significance. If the joint bound and regularization prove effective, the approach could meaningfully reduce the online computational cost of Bayesian predictive inference for expensive forward models such as PDE-governed systems, while potentially improving calibration of the predictive distributions. The amortized formulation is a practical strength for repeated-query settings.
minor comments (3)
- [Abstract / §1] The abstract and introduction would benefit from a brief explicit statement of the precise form of the moment-based regularization (e.g., which moments are matched and how the penalty is scaled).
- [Numerical experiments] In the experimental section, the baseline two-stage VI implementation should be described with the same level of detail as the proposed method (e.g., number of posterior samples used for Monte Carlo propagation and the variational family employed).
- [Figures 2–5] Figure captions should report the specific error metrics (e.g., predictive log-likelihood, calibration error) and the number of independent runs used to compute means and standard deviations.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately captures the core contribution of our amortized variational framework for jointly targeting posterior and posterior-predictive distributions.
Circularity Check
No significant circularity identified
full rationale
The paper introduces a joint amortized variational scheme that directly optimizes a variational upper bound on the predictive KL divergence together with moment-based regularization terms, then demonstrates empirical superiority over the conventional two-stage posterior-then-predictive workflow on benchmarks and a PDE problem. No load-bearing step reduces by construction to a fitted parameter, self-citation, or renamed input; the upper bound and regularization are presented as novel modeling choices whose validity is checked externally via numerical accuracy and cost metrics rather than by internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
T. J. Hughes, The Finite Element Method: Linear Static and Dynamic Finite Element Analysis, Courier Corporation, 2012
2012
-
[2]
J. H. Ferziger, M. Perić, R. L. Street, Computational methods for fluid dynamics, Springer, 2019.doi:10.1007/978-3-642-56026-2
-
[3]
E. A. de Souza Neto, D. Peric, D. R. Owen, Computational Methods for Plasticity: Theory and Applications, John Wiley & Sons, 2011.doi:10.1002/9780470694626
-
[4]
R. C. Smith, Uncertainty Quantification: Theory, Implementation, and Applications, SIAM, 2013.doi:10.1137/1.9781611973228
-
[5]
Soize, Uncertainty Quantification: An accelerated Course with Advanced Applications in Computational Engineering, Springer, 2017.doi:10.1007/ 978-3-319-54339-0
C. Soize, Uncertainty Quantification: An accelerated Course with Advanced Applications in Computational Engineering, Springer, 2017.doi:10.1007/ 978-3-319-54339-0
2017
-
[6]
In: Handbook of Uncertainty Quantification, pp
R. Ghanem, D. Higdon, H. Owhadi, Handbook of Uncertainty Quantification, Springer International Publishing, Cham, 2017.doi:10.1007/978-3-319-12385-1. 28
-
[7]
A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari, D. B. Rubin, Bayesian Data Analysis, CRC press, 2013.doi:10.1201/b16018
-
[8]
D. S. Sivia, J. Skilling, Data Analysis: A Bayesian Tutorial, Oxford University Press, 2006.doi:10.1093/oso/9780198568315.001.0001
-
[9]
S. Brooks, A. Gelman, G. L. Jones, X.-L. Meng, Handbook of Markov Chain Monte Carlo, CRC Press, 2011.doi:10.1201/b10905
-
[10]
S. Duane, A. D. Kennedy, B. J. Pendleton, D. Roweth, Hybrid Monte Carlo, Physics letters B 195 (2) (1987) 216–222.doi:10.1016/0370-2693(87)91197-X
-
[11]
R. M. Neal, MCMC using Hamiltonian dynamics, in: Handbook of Markov Chain Monte Carlo, Chapman and Hall/CRC, 2011, pp. 47–95
2011
-
[12]
A Conceptual Introduction to Hamiltonian Monte Carlo
M. Betancourt, A conceptual introduction to Hamiltonian Monte Carlo, arXiv preprint arXiv:1701.02434 (2017).arXiv:1701.02434
work page Pith review arXiv 2017
-
[13]
M. D. Hoffman, A. Gelman, The No-U-Turn Sampler: adaptively setting path lengths in Hamiltonian Monte Carlo, Journal of Machine Learning Research 15 (1) (2014) 1593– 1623
2014
-
[14]
M. I. Jordan, Z. Ghahramani, T. S. Jaakkola, L. K. Saul, An introduction to variational methods for graphical models, Machine Learning 37 (2) (1999) 183–233.doi:10.1023/ A:1007665907178
1999
-
[15]
D. M. Blei, A. Kucukelbir, J. D. McAuliffe, Variational inference: A review for statis- ticians, Journal of the American Statistical Association 112 (518) (2017) 859–877. doi:10.1080/01621459.2017.1285773
-
[16]
C. Zhang, J. Bütepage, H. Kjellström, S. Mandt, Advances in variational inference, IEEE Transactions on Pattern Analysis and Machine Intelligence 41 (8) (2018) 2008– 2026.doi:10.1109/TPAMI.2018.2889774
-
[17]
Q. Liu, D. Wang, Stein variational gradient descent: A general purpose bayesian infer- ence algorithm, in: D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, R. Garnett (Eds.), Advances in Neural Information Processing Systems, Vol. 29, Curran Associates, Inc., 2016
2016
-
[18]
Detommaso, T
G. Detommaso, T. Cui, Y. Marzouk, A. Spantini, R. Scheichl, A stein variational new- ton method, in: S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, R. Garnett (Eds.), Advances in Neural Information Processing Systems, Vol. 31, Curran Associates, Inc., 2018
2018
-
[19]
P. Chen, O. Ghattas, Projected stein variational gradient descent, in: H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, H. Lin (Eds.), Advances in Neural Information Processing Systems, Vol. 33, Curran Associates, Inc., 2020, pp. 1947–1958
2020
-
[20]
Robert, G
C. Robert, G. Casella, Monte Carlo Statistical Methods, Springer, 2004.doi:10.1007/ 978-1-4757-4145-2. 29
2004
-
[21]
R. Y. Rubinstein, D. P. Kroese, Simulation and the Monte Carlo Method, John Wiley & Sons, 2016.doi:10.1002/9781118631980
-
[22]
P. Blanchard, D. J. Higham, N. J. Higham, Accurately computing the log-sum-exp and softmax functions, IMA Journal of Numerical Analysis 41 (4) (2020) 2311–2330. doi:10.1093/imanum/draa038
-
[23]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, in: Proceedings of the 3rd International Conference on Learning Representations (ICLR), 2015.arXiv: 1412.6980
work page internal anchor Pith review arXiv 2015
-
[24]
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Is- ard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S.Moore, D.Murray, C.Olah, M.Schuster, J.Shlens, B.Steiner, I.Sutskever, K.Talwar, P. Tucker, V. Vanhoucke, V. V...
work page Pith review arXiv 2015
-
[25]
K. He, X. Zhang, S. Ren, J. Sun, Delving deep into rectifiers: Surpassing human-level performance on imageNet classification, in: IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1026–1034.doi:10.1109/ICCV.2015.123
-
[26]
Holzapfel, Nonlinear Solid Mechanics: A Continuum Approach for Engineering, sec- ond print Edition, John Wiley & Sons, 2001
G. Holzapfel, Nonlinear Solid Mechanics: A Continuum Approach for Engineering, sec- ond print Edition, John Wiley & Sons, 2001
2001
-
[27]
T. A. El Moselhy, Y. M. Marzouk, Bayesian inference with optimal maps, Journal of Computational Physics 231 (23) (2012) 7815–7850.doi:10.1016/j.jcp.2012.07.022
-
[28]
Y. Marzouk, T. Moselhy, M. Parno, A. Spantini, Sampling via measure transport: An introduction, in: Handbook of Uncertainty Quantification, Springer International Pub- lishing, Cham, 2016, pp. 1–41.doi:10.1007/978-3-319-11259-6_23-1
-
[29]
Z. O. Wang, R. Baptista, Y. Marzouk, L. Ruthotto, D. Verma, Efficient neural net- work approaches for conditional optimal transport with applications in Bayesian in- ference, SIAM Journal on Scientific Computing 47 (4) (2025) C979–C1005.doi: 10.1137/24m1678659
-
[30]
I. Kobyzev, S. J. Prince, M. A. Brubaker, Normalizing flows: An introduction and review of current methods, IEEE Transactions on Pattern Analysis and Machine Intelligence 43 (11) (2020) 3964–3979.doi:10.1109/TPAMI.2020.2992934
-
[31]
Papamakarios, E
G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mohamed, B. Lakshminarayanan, Normalizing flows for probabilistic modeling and inference, Journal of Machine Learning Research 22 (57) (2021) 1–64. 30
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.