Recognition: unknown
OracleProto: A Reproducible Framework for Benchmarking LLM Native Forecasting via Knowledge Cutoff and Temporal Masking
Pith reviewed 2026-05-07 16:24 UTC · model grok-4.3
The pith
OracleProto creates reproducible LLM forecasting benchmarks with leakage held to 1% by enforcing knowledge cutoffs and detecting residual content leaks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
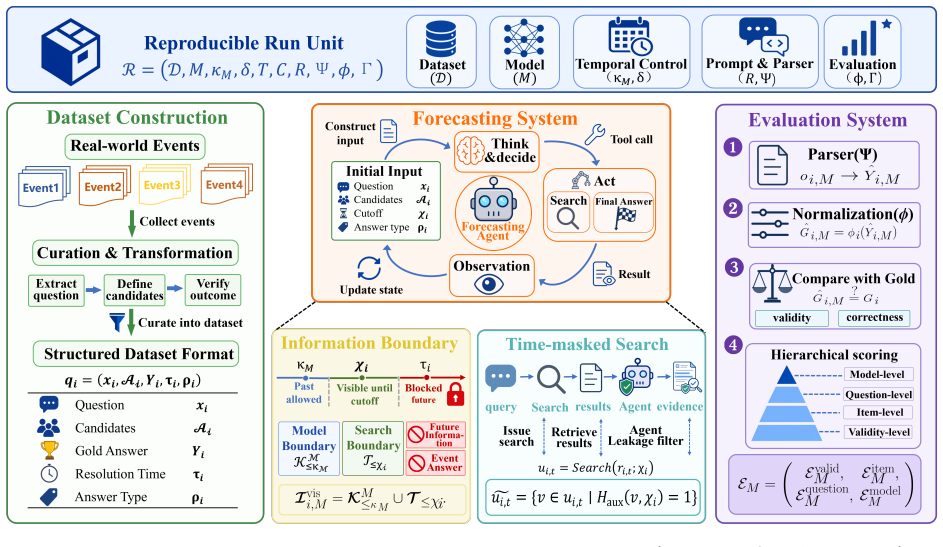
OracleProto reconstructs resolved events into forecasting samples by combining model-cutoff-aligned sample admission, tool-level temporal masking, content-level leakage detection, discrete answer normalization, and hierarchical scoring. Instantiated on a FutureX-Past-derived dataset, the framework reduces residual leakage to the 1% level—an order of magnitude below tool-only temporal filtering—while distinguishing forecasting quality, sampling stability, and cost efficiency under controlled information boundaries.
What carries the argument
The OracleProto framework, which turns past events into controlled forecasting samples through cutoff-aligned admission plus layered masking and leakage detection.
If this is right
- Distinguishes forecasting quality, sampling stability, and cost efficiency under controlled information boundaries.
- Reduces residual leakage to 1%, an order of magnitude below tool-only temporal filtering.
- Turns LLM forecasting evaluation into an auditable, reusable, and trainable dataset-level capability.
- Supplies a unified interface for fair cross-model comparison and a controlled signal source for downstream SFT and RL.
Where Pith is reading between the lines
- The same boundary-enforcement steps could be applied to create training corpora that improve native forecasting without introducing leakage from resolved events.
- Similar leakage controls might help evaluate other temporal or causal reasoning tasks where models could otherwise exploit pre-training data.
- If leakage stays low across more models and domains, the datasets produced by the framework could become standard test sets for tracking progress in LLM forecasting.
Load-bearing premise
Content-level leakage detection combined with model-cutoff-aligned sample admission can reliably prevent models from accessing pre-trained knowledge about resolved events even when those events are reconstructed from public historical data.
What would settle it
A controlled test in which models still achieve well above 1% accuracy on the benchmark by recalling or reconstructing specific resolved events despite the cutoff alignment, temporal masking, and content-level detection steps.
Figures
read the original abstract
Large language models are moving from static text generators toward real-world decision-support systems, where forecasting is a composite capability that links information gathering, evidence integration, situational judgment, and action-oriented decision making. This capability is in broad demand across finance, policy, industry, and scientific research, yet its evaluation remains difficult: live benchmarks evaluate forecasts before answers exist, making them the cleanest way to measure forecasting ability, but they expire once events resolve; retrospective benchmarks are reproducible, but they cannot reliably distinguish genuine forecasting from facts a model may have already learned during pretraining. Prompting models to "pretend not to know" cannot replace a genuine knowledge boundary. We propose OracleProto, a reproducible framework for evaluating LLM native forecasting capability. OracleProto reconstructs resolved events into time-bounded forecasting samples by combining model-cutoff-aligned sample admission, tool-level temporal masking, content-level leakage detection, discrete answer normalization, and hierarchical scoring. Instantiated on a FutureX-Past-derived dataset with six contemporary LLMs, OracleProto distinguishes forecasting quality, sampling stability, and cost efficiency under controlled information boundaries, while reducing residual leakage to the $1\%$ level, an order of magnitude below tool-only temporal filtering. OracleProto turns LLM forecasting from one-off evaluation into an auditable, reusable, and trainable dataset-level capability, providing a unified interface for fair cross-model comparison and a controlled signal source for downstream SFT and RL. Code and data are available at https://github.com/MaYiding/OracleProto and https://huggingface.co/datasets/MaYiding/OracleProto.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OracleProto, a reproducible framework for benchmarking LLM native forecasting on resolved events. It reconstructs time-bounded forecasting samples via model-cutoff-aligned sample admission, tool-level temporal masking, content-level leakage detection, discrete answer normalization, and hierarchical scoring. Instantiated on a FutureX-Past-derived dataset with six contemporary LLMs, the framework is claimed to reduce residual leakage to the 1% level (an order of magnitude below tool-only filtering), while distinguishing forecasting quality, sampling stability, and cost efficiency under controlled boundaries. Code and data are released publicly.
Significance. If the leakage reduction and evaluation controls hold, OracleProto would provide a valuable, auditable standard for measuring genuine LLM forecasting capability separate from pretraining contamination, supporting fair cross-model comparisons and controlled data for SFT/RL. The explicit release of code (https://github.com/MaYiding/OracleProto) and dataset (Hugging Face) is a clear strength that enables reproducibility and community use.
major comments (1)
- [Abstract] Abstract: The central claim that OracleProto reduces residual leakage to the 1% level (an order-of-magnitude improvement over tool-only temporal filtering) is load-bearing for the paper's contribution. However, no ablation, recall analysis, or false-negative evaluation is described for the content-level leakage detection component when applied to paraphrased or indirectly reconstructed pre-cutoff events. Because samples are derived from public historical data, models may still surface internalized facts via inference or partial recall that evades the detection method, leaving the 1% figure and its superiority unverified.
minor comments (1)
- [Abstract] The abstract introduces 'hierarchical scoring' and 'discrete answer normalization' without a brief definition or reference to the relevant section; adding one sentence of clarification would improve readability for readers unfamiliar with the scoring pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of OracleProto as a reproducible benchmark. We address the single major comment below and commit to revisions that directly strengthen the verification of the leakage claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that OracleProto reduces residual leakage to the 1% level (an order-of-magnitude improvement over tool-only temporal filtering) is load-bearing for the paper's contribution. However, no ablation, recall analysis, or false-negative evaluation is described for the content-level leakage detection component when applied to paraphrased or indirectly reconstructed pre-cutoff events. Because samples are derived from public historical data, models may still surface internalized facts via inference or partial recall that evades the detection method, leaving the 1% figure and its superiority unverified.
Authors: We agree that the current manuscript lacks a dedicated ablation or false-negative analysis of the content-level leakage detector on paraphrased or indirectly reconstructed pre-cutoff events, which limits the strength of the 1% claim. The reported 1% residual leakage is measured empirically on the final dataset after the full pipeline (cutoff-aligned admission, tool-level temporal masking, and content-level detection), showing an order-of-magnitude drop relative to tool-only filtering. However, this does not isolate the incremental contribution or robustness of the content-level step against paraphrases. In the revised manuscript we will add a new subsection containing: (1) a held-out set of paraphrased historical events drawn from public sources, (2) application of the leakage detector with reported precision/recall, and (3) comparison of end-to-end leakage rates with and without the content-level component. This will provide the requested quantitative support while noting that exhaustive detection of all inference-based recall remains inherently limited without training-data access. revision: yes
Circularity Check
No circularity: procedural framework relies on external benchmarks
full rationale
OracleProto defines its evaluation pipeline through explicit procedural components (model-cutoff-aligned admission, tool-level temporal masking, content-level leakage detection) applied to reconstructed public historical events. These steps are not derived from or equivalent to the paper's own outputs or fitted parameters; leakage reduction to 1% is reported as an empirical measurement against external references rather than a self-defining tautology. No equations, uniqueness theorems, or self-citations are invoked as load-bearing premises that reduce the central claims to their inputs by construction. The framework remains self-contained against external model cutoffs and datasets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chandak, S
N. Chandak, S. Goel, A. Prabhu, M. Hardt, and J. Geiping. Scaling open-ended reasoning to predict the future,
- [2]
-
[3]
FutureX-Past Dataset
futurex-ai. FutureX-Past Dataset. Hugging Face Datasets, 2025. URL https://huggingface.co/datasets/ futurex-ai/Futurex-Past
2025
- [4]
- [5]
- [6]
- [7]
-
[8]
Metaculus FAQ
Metaculus. Metaculus FAQ. Online documentation, 2026. URL https://www.metaculus.com/faq/. Ac- cessed: 2026-05-05
2026
-
[9]
K. Murphy. Agentic forecasting using sequential bayesian updating of linguistic beliefs, 2026. URL https: //arxiv.org/abs/2604.18576
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [10]
- [11]
-
[12]
A. Tversky. Features of similarity.Psychological Review, 84(4):327–352, 1977. doi: 10.1037/0033-295X.84.4.327
- [13]
-
[14]
Z. Zeng, J. Liu, S. Chen, T. He, Y . Liao, Y . Tian, J. Wang, Z. Wang, Y . Yang, L. Yin, M. Yin, Z. Zhu, T. Cai, Z. Chen, J. Chen, Y . Du, X. Gao, J. Guo, L. Hu, J. Jiao, X. Li, J. Liu, S. Ni, Z. Wen, G. Zhang, K. Zhang, X. Zhou, J. Blanchet, X. Qiu, M. Wang, and W. Huang. FutureX: An advanced live benchmark for LLM agents in future prediction, 2025. URLh...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.