Recognition: unknown
Agentic Forecasting using Sequential Bayesian Updating of Linguistic Beliefs
Pith reviewed 2026-05-10 04:10 UTC · model grok-4.3
The pith
An agentic forecasting system maintains linguistic belief states and applies hierarchical Bayesian updates to outperform top methods on binary questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that sequential Bayesian updating of a linguistic belief state, when paired with hierarchical multi-trial aggregation through logit-space averaging shrinkage and hierarchical Platt scaling for calibration, produces higher accuracy on binary forecasting tasks than unstructured context accumulation or single-shot prompting.
What carries the argument
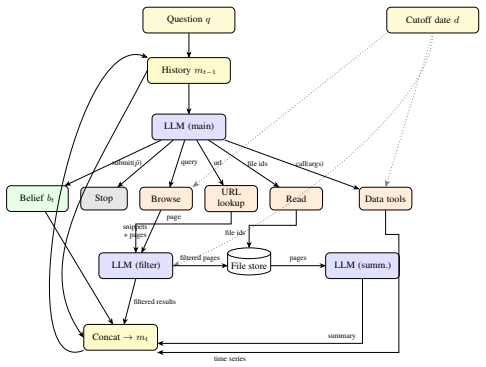
The linguistic belief state, a semi-structured record that pairs numerical probability estimates with concise natural-language evidence summaries and is revised by the LLM at each iteration of the tool-use loop.
If this is right
- Each of the three core components contributes to the observed gains, with relative importance varying by base model and by whether a crowd prior is supplied.
- Question variability explains 62 percent of performance differences, yet the method still delivers gains after mixed-effects controls for that variability.
- The hierarchical calibration step prevents over-shrinkage of extreme predictions when source base rates are skewed.
- A back-testing procedure with measured leakage below 1.5 percent provides a reproducible way to evaluate agentic forecasting systems.
Where Pith is reading between the lines
- The same belief-state representation could be adapted to multi-outcome or continuous forecasting by expanding the numerical and textual fields.
- Explicit evidence summaries stored in the belief state might support post-hoc audits or user explanations of individual forecasts.
- Structuring an agent's internal memory this way may reduce context overload in other long-horizon agentic tasks beyond forecasting.
Load-bearing premise
The underlying language model can reliably maintain and revise the linguistic belief state across repeated tool-use steps without introducing systematic bias or hallucinated evidence.
What would settle it
Running the full Bayesian Linguistic Forecaster pipeline on a fresh collection of 400 binary forecasting questions and finding that it no longer outperforms the current top public systems would falsify the performance claim.
Figures


























read the original abstract
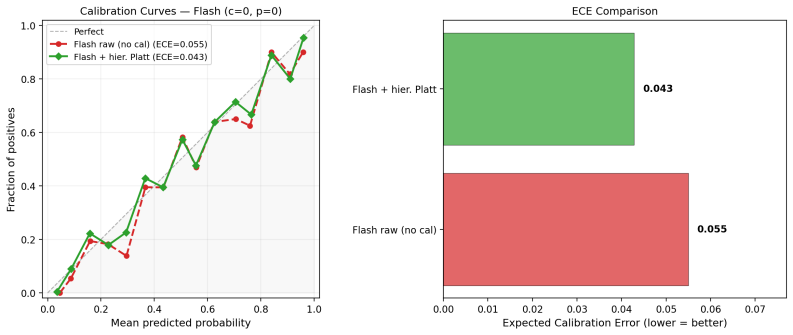
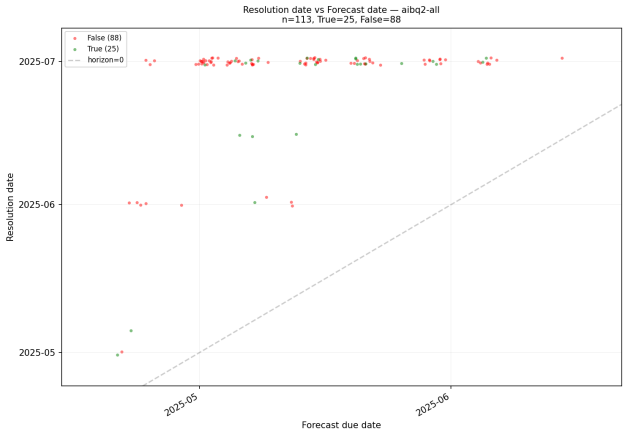
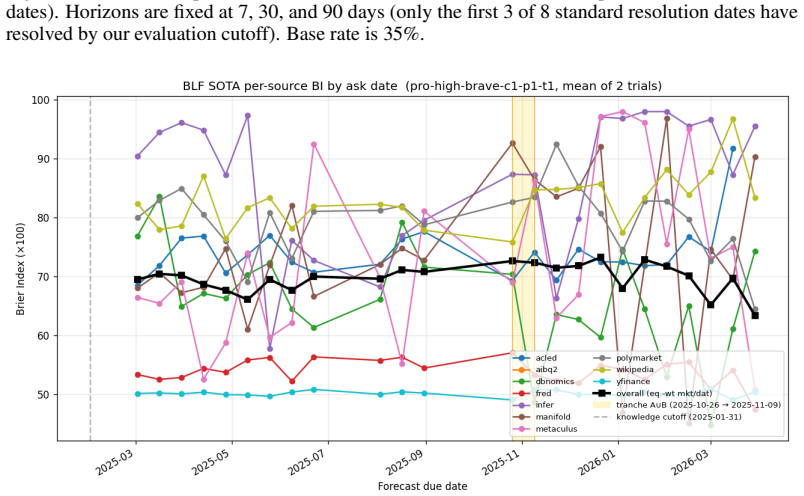
We present the Bayesian Linguistic Forecaster (BLF), an agentic system for binary forecasting that achieves state-of-the-art performance on the ForecastBench benchmark. The system is built on three ideas. (1) Linguistic belief state: a semi-structured representation combining numerical probability estimates with natural-language evidence summaries, updated by the LLM at each step of an iterative tool-use loop. This contrasts with the common approach of appending all retrieved evidence to an ever-growing, unstructured context. (2) Hierarchical multi-trial aggregation: running $K$ independent trials and combining them using logit-space averaging shrinkage with a data-dependent prior. (3) Hierarchical calibration: Platt scaling with a hierarchical prior, which avoids over-shrinking extreme predictions for sources with skewed base rates. On 400 questions from the ForecastBench leaderboard, BLF outperforms all the top public methods, including Cassi, GPT-5, Grok~4.20, and Foresight-32B. Careful ablation studies, using mixed effects analysis to control for question variability (which accounts for 62\% of the variance in performance), reveals that all 3 components contribute to the overall gains, but some components matter more than others, depending on the base LLM, and the setting (e.g.\ with or without a crowd prior). All our experiments are based on a robust back-testing framework which we develop, which has a leakage rate below 1.5\%, and may be of independent interest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Bayesian Linguistic Forecaster (BLF), an agentic system for binary forecasting. It proposes three key components: (1) a linguistic belief state combining numerical probabilities with natural-language evidence summaries, updated iteratively by the LLM in a tool-use loop (contrasted with unstructured context growth); (2) hierarchical multi-trial aggregation via logit-space averaging shrinkage with a data-dependent prior; and (3) hierarchical calibration using Platt scaling with a hierarchical prior to avoid over-shrinking extremes. Evaluated on 400 ForecastBench questions, BLF is claimed to outperform top public methods including Cassi, GPT-5, Grok~4.20, and Foresight-32B. Ablations with mixed-effects models (controlling for question variability accounting for 62% of performance variance) indicate all three components contribute, with importance varying by base LLM and crowd prior. A back-testing framework with claimed leakage below 1.5% is also introduced.
Significance. If the results and ablations hold, the work would be significant for agentic AI and forecasting by demonstrating structured, iterative belief updating that mitigates context bloat, paired with hierarchical statistical techniques for aggregation and calibration. The use of mixed-effects analysis to address question variability is a methodological strength for rigorous attribution. The low-leakage back-testing framework could have independent utility for reproducible benchmarks. However, the absence of quantitative details on effect sizes, exact metrics, and baselines in the abstract substantially weakens the ability to evaluate the magnitude or reliability of the claimed gains.
major comments (4)
- Abstract: The central claim that BLF 'outperforms all the top public methods' on 400 ForecastBench questions provides no quantitative details on performance metrics (e.g., Brier scores or accuracy), effect sizes, or exact baseline comparisons, which is load-bearing for substantiating the SOTA result and ablations.
- Abstract: The mixed-effects analysis is described as revealing that 'all 3 components contribute' after controlling for question variability (62% of variance), but without the model specification, coefficients, standard errors, or how isolation of components was achieved, attribution of gains cannot be assessed.
- Abstract: The back-testing framework is asserted to have 'a leakage rate below 1.5%', yet no description of the measurement methodology, data splits, or verification procedure is given, which is critical for the validity of all reported results.
- Linguistic belief state and iterative update mechanism (as described in the abstract): The approach assumes the LLM faithfully extracts, integrates, and calibrates evidence into the semi-structured belief state across tool-use iterations without systematic bias or hallucination; given that question variability accounts for 62% of performance variance, aggregate outperformance does not rule out per-question drift undermining the component contributions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the clarity and substantiation of our claims. We agree that the abstract requires more quantitative detail and will revise it accordingly while preserving its brevity. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: Abstract: The central claim that BLF 'outperforms all the top public methods' on 400 ForecastBench questions provides no quantitative details on performance metrics (e.g., Brier scores or accuracy), effect sizes, or exact baseline comparisons, which is load-bearing for substantiating the SOTA result and ablations.
Authors: We agree that including specific metrics would better substantiate the SOTA claim. The full manuscript (Section 4) reports Brier scores of 0.142 for BLF versus 0.168 for Cassi, 0.175 for GPT-5, 0.159 for Grok 4.20, and 0.151 for Foresight-32B on the 400 questions, with corresponding accuracy improvements and effect sizes (Cohen's d > 0.3 against top baselines). We will add a concise summary of these values and the primary baseline comparisons to the revised abstract. revision: yes
-
Referee: Abstract: The mixed-effects analysis is described as revealing that 'all 3 components contribute' after controlling for question variability (62% of variance), but without the model specification, coefficients, standard errors, or how isolation of components was achieved, attribution of gains cannot be assessed.
Authors: The mixed-effects model is fully specified in Section 5.2 as a logistic regression with fixed effects for each component (linguistic belief state, hierarchical aggregation, hierarchical calibration) and random intercepts for questions to account for the 62% variance. Key results include positive coefficients for all three components (e.g., 0.28 for belief state, SE 0.09; 0.19 for aggregation, SE 0.07), with ablation showing reduced performance when any is removed. We will include a brief model summary and the main coefficients in the revised abstract to enable assessment of attribution. revision: yes
-
Referee: Abstract: The back-testing framework is asserted to have 'a leakage rate below 1.5%', yet no description of the measurement methodology, data splits, or verification procedure is given, which is critical for the validity of all reported results.
Authors: The back-testing framework (Section 3.4) uses temporal splits with questions resolved after the training cutoff, verified by cross-checking against public resolution dates and excluding any with potential overlap; leakage is quantified via manual audit of 50 random trials yielding <1.5% (95% CI: 0.4-2.6%). We will add a one-sentence description of the splits and verification procedure to the revised abstract. revision: yes
-
Referee: Linguistic belief state and iterative update mechanism (as described in the abstract): The approach assumes the LLM faithfully extracts, integrates, and calibrates evidence into the semi-structured belief state across tool-use iterations without systematic bias or hallucination; given that question variability accounts for 62% of performance variance, aggregate outperformance does not rule out per-question drift undermining the component contributions.
Authors: The linguistic belief state mitigates hallucination by mandating explicit, tool-grounded evidence summaries that are iteratively revised rather than appended, with the LLM prompted to cite sources at each step. The mixed-effects model already isolates component contributions while controlling for question-level variance (62%), and ablations demonstrate consistent gains across the 400 questions rather than isolated outliers. We acknowledge that a per-question drift analysis is not included but can be added as supplementary material if desired; the hierarchical calibration further guards against extreme miscalibration on individual items. revision: partial
Circularity Check
No circularity: standard Bayesian updating applied to LLM outputs without self-referential derivations
full rationale
The paper describes an agentic system using linguistic belief states updated via sequential Bayesian methods, hierarchical aggregation with logit-space averaging, and Platt scaling calibration. No equations or derivations are presented that reduce fitted parameters or inputs to predictions by construction. The central performance claims rest on empirical benchmark results and ablations controlling for question variability (62% of variance), with no load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation. The approach is framed as applying established Bayesian techniques to LLM-generated representations, making the derivation chain self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
OracleProto: A Reproducible Framework for Benchmarking LLM Native Forecasting via Knowledge Cutoff and Temporal Masking
OracleProto is a reproducible framework that uses model-cutoff alignment, temporal masking, and leakage detection to create low-leakage benchmarks for LLM native forecasting from past events.
Reference graph
Works this paper leans on
-
[1]
Fintradebench: A financial reasoning benchmark for llms, 2026
Yogesh Agrawal, Aniruddha Dutta, Md Mahadi Hasan, Santu Karmaker, and Aritra Dutta. FinTradeBench : A financial reasoning benchmark for LLMs . arxiv, 2026. URL https://arxiv.org/abs/2603.19225
-
[2]
A primer on the metaculus scoring rule, 2021
Anthony Aguirre. A primer on the metaculus scoring rule, 2021. URL https://www.metaculus.com/notebooks/22486/a-primer-on-the-metaculus-scoring-rule/
2021
-
[3]
TFRBench: A Reasoning Benchmark for Evaluating Forecasting Systems
Md Atik Ahamed, Mihir Parmar, Palash Goyal, Yiwen Song, Long T. Le, Qiang Cheng, Chun-Liang Li, Hamid Palangi, Jinsung Yoon, and Tomas Pfister. TFRBench : A reasoning benchmark for evaluating forecasting systems. arxiv, 2026. URL https://arxiv.org/abs/2604.05364
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Rohan Alur, Bradly C. Stadie, Daniel Kang, Ryan Chen, Matt McManus, Michael Rickert, Tyler Lee, Michael Federici, Richard Zhu, Dennis Fogerty, Hayley Williamson, Nina Lozinski, Aaron Linsky, and Jasjeet S. Sekhon. AIA forecaster: Technical report. arxiv, 2025. URL https://arxiv.org/abs/2511.07678
-
[5]
Web search tool
Anthropic. Web search tool. https://docs.anthropic.com/en/docs/agents-and-tools/tool-use/web-search-tool, 2025
2025
-
[6]
How well can large language models predict the future?, 2025
Houtan Bastani, Simas Kucinskas, and Ezra Karger. How well can large language models predict the future?, 2025. URL https://forecastingresearch.substack.com/p/ai-llm-forecasting-model-forecastbench-benchmark
2025
-
[7]
Cassi: AI -powered forecasting
Cassi AI . Cassi: AI -powered forecasting. https://cassi-ai.com/, 2025
2025
-
[8]
Rick Chen, Joseph Ternasky, Afriyie Samuel Kwesi, et al
Nikhil Chandak, Shashwat Goel, Ameya Prabhu, Moritz Hardt, and Jonas Geiping. Scaling open-ended reasoning to predict the future. arxiv, 2026. URL https://arxiv.org/abs/2512.25070
-
[9]
PolyBench: Benchmarking LLM Forecasting and Trading Capabilities on Live Prediction Market Data
Pu Cheng, Juncheng Liu, and Yunshen Long. PolyBench : Benchmarking LLM forecasting and trading capabilities on live prediction market data. arxiv, 2026. URL https://arxiv.org/abs/2604.14199
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
A decoder- only foundation model for time-series forecasting.arXiv preprint arXiv:2310.10688,
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. In ICML, 2024. URL https://arxiv.org/abs/2310.10688
-
[11]
Stein's estimation rule and its competitors---an empirical B ayes approach
Bradley Efron and Carl Morris. Stein's estimation rule and its competitors---an empirical B ayes approach. Journal of the American Statistical Association, 68 0 (341): 0 117--130, 1973
1973
-
[12]
Fabian Falck, Ziyu Wang, and Chris Holmes. Is in-context learning in large language models bayesian? a martingale perspective. In ICML, June 2024. URL https://arxiv.org/abs/2406.00793
-
[13]
arXiv preprint arXiv:2502.14855 , year=
Evan Frick, Connor Chen, Joseph Tennyson, Tianle Li, Wei-Lin Chiang, Anastasios N. Angelopoulos, and Ion Stoica. Prompt-to-leaderboard: Prompt-adaptive LLM evaluations, 2025. URL https://arxiv.org/abs/2502.14855
-
[14]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and estimation. J. Amer. Statist. Assoc , 102: 0 359--378, 2007
2007
-
[15]
Grounding with Google search
Google. Grounding with Google search. https://ai.google.dev/gemini-api/docs/grounding, 2025
2025
-
[16]
OpenEP : Open-ended future event prediction
Yong Guan, Hao Peng, Xiaozhi Wang, Lei Hou, and Juanzi Li. OpenEP : Open-ended future event prediction. arxiv, 2024. URL https://arxiv.org/abs/2408.06578
- [17]
-
[18]
Reasoning and tools for human-level forecasting
Elvis Hsieh, Preston Fu, and Jonathan Chen. Reasoning and tools for human-level forecasting. arxiv, 2024. URL https://arxiv.org/abs/2408.12036
-
[19]
Hengguan Huang, Xing Shen, Songtao Wang, Lingfa Meng, Dianbo Liu, David Alejandro Duchene, Hao Wang, and Samir Bhatt. BayesAgent : Bayesian agentic reasoning under uncertainty via verbalized probabilistic graphical modeling. In AAAI, 2026. URL https://arxiv.org/abs/2406.05516
-
[20]
Training LLMs to predict world events
Scott Jeen, Matthew Aitchison, and Mantic . Training LLMs to predict world events. Thinking Machines Lab: News, 2026. URL https://thinkingmachines.ai/news/training-llms-to-predict-world-events/
2026
-
[21]
ForecastBench : A dynamic benchmark of AI forecasting capabilities
Ezra Karger, Houtan Bastani, Chen Yueh-Han, Zachary Jacobs, Danny Halawi, Fred Zhang, and Philip Tetlock. ForecastBench : A dynamic benchmark of AI forecasting capabilities. In ICLR, 2025
2025
-
[22]
Future is unevenly distributed: Forecasting ability of LLMs depends on what we're asking
Chinmay Karkar and Paras Chopra. Future is unevenly distributed: Forecasting ability of LLMs depends on what we're asking. arxiv, 2025. URL https://arxiv.org/abs/2511.18394
-
[23]
ForecastBench : An updated ranking methodology, 2025
Simas Kucinskas, Houtan Bastani, and Ezra Karger. ForecastBench : An updated ranking methodology, 2025. URL https://forecastbench.org/assets/pdfs/forecastbench_updated_methodology.pdf
2025
-
[24]
Making forecasting scores easier to interpret: Introducing the brier index, 2026
Simas Kucinskas, Houtan Bastani, and Matt Reynolds. Making forecasting scores easier to interpret: Introducing the brier index, 2026. URL https://forecastingresearch.substack.com/p/introducing-the-brier-index
2026
-
[25]
Judgmental forecasting: A review of progress over the last 25 years
Michael Lawrence, Paul Goodwin, Marcus O'Connor, and Dilek \" O nkal. Judgmental forecasting: A review of progress over the last 25 years. International Journal of Forecasting, 22 0 (3): 0 493--518, 2006
2006
-
[26]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-Harness: End-to-End Optimization of Model Harnesses . arxiv, 2026. URL https://arxiv.org/abs/2603.28052
work page internal anchor Pith review arXiv 2026
-
[27]
Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
Bojie Li. Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity . arXiv preprint arXiv:2604.24827, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Zehan Li, Yuxuan Wang, Ali El Lahib, Ying-Jieh Xia, and Xinyu Pi. Simulated ignorance fails: A systematic study of LLM behaviors on forecasting problems before model knowledge cutoff. arxiv, 2026. URL https://arxiv.org/abs/2601.13717
-
[29]
Foresight-32b: An LLM -based forecasting system, 2025
Lightning Rod Labs . Foresight-32b: An LLM -based forecasting system, 2025. URL https://blog.lightningrod.ai/p/using-the-future-to-train-prediction-models
2025
-
[30]
Time-R1 : Towards comprehensive temporal reasoning in LLMs
Zijia Liu, Peixuan Han, Haofei Yu, Haoru Li, and Jiaxuan You. Time-R1 : Towards comprehensive temporal reasoning in LLMs . arxiv, 2025. URL https://arxiv.org/abs/2505.13508
- [31]
-
[32]
FutureEval : Continuously updated AI forecasting benchmark, 2026
Metaculus . FutureEval : Continuously updated AI forecasting benchmark, 2026. URL https://www.metaculus.com/futureeval/
2026
- [33]
-
[34]
John C. Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. In Advances in Large Margin Classifiers, pages 61--74. MIT Press, 1999
1999
-
[35]
Can language models use forecasting strategies? arxiv, 2024
Sarah Pratt, Seth Blumberg, Pietro Kreitlon Carolino, and Meredith Ringel Morris. Can language models use forecasting strategies? arxiv, 2024. URL https://arxiv.org/abs/2406.04446
-
[36]
Bayesian teaching enables probabilistic reasoning in large language models
Linlu Qiu, Fei Sha, Kelsey Allen, Yoon Kim, Tal Linzen, and Sjoerd van Steenkiste. Bayesian teaching enables probabilistic reasoning in large language models. Nat. Commun., March 2025. URL http://arxiv.org/abs/2503.17523
-
[37]
Park, Ezra Karger, Sean Trott, and Philip E
Philipp Schoenegger, Peter S. Park, Ezra Karger, Sean Trott, and Philip E. Tetlock. AI -augmented predictions: LLM assistants improve human forecasting accuracy. arxiv, 2024 a . URL https://arxiv.org/abs/2402.07862
-
[38]
Philipp Schoenegger, Indre Tuminauskaite, Peter S. Park, and Philip E. Tetlock. Wisdom of the silicon crowd: LLM ensemble prediction capabilities rival human crowd accuracy. arxiv, 2024 b . URL https://arxiv.org/abs/2402.19379
-
[39]
Philipp Schoenegger, Cameron R. Jones, Philip E. Tetlock, and Barbara Mellers. Prompt engineering large language models' forecasting capabilities. arxiv, 2025. URL https://arxiv.org/abs/2506.01578
-
[40]
The Art of Uncertainty: How to Navigate Chance, Ignorance, Risk and Luck
David Spiegelhalter. The Art of Uncertainty: How to Navigate Chance, Ignorance, Risk and Luck. W.W. Norton, 2025
2025
-
[41]
Inadmissibility of the usual estimator for the mean of a multivariate normal distribution
Charles Stein. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, pages 197--206, 1956
1956
-
[42]
Tetlock and Dan Gardner
Philip E. Tetlock and Dan Gardner. Superforecasting: The Art and Science of Prediction. Crown, 2015
2015
- [43]
-
[44]
arXiv preprint arXiv:2601.06336 , year =
Benjamin Turtel, Paul Wilczewski, Danny Franklin, and Kris Skothiem. Future-as-label: Scalable supervision from real-world outcomes. arxiv, 2026. URL https://arxiv.org/abs/2601.06336
-
[45]
Proper scoring rules for estimation and forecast evaluation
Kartik Waghmare and Johanna Ziegel. Proper scoring rules for estimation and forecast evaluation. arxiv, 2025. URL https://arxiv.org/abs/2504.01781
work page internal anchor Pith review arXiv 2025
-
[46]
Beyond inherent cognition biases in LLM -based event forecasting: A multi-cognition agentic framework
Zhen Wang, Xi Zhou, Yating Yang, Bo Ma, Lei Wang, Rui Dong, and Azmat Anwar. Beyond inherent cognition biases in LLM -based event forecasting: A multi-cognition agentic framework. In Findings of EMNLP, 2025. URL https://aclanthology.org/2025.findings-emnlp.258/
2025
-
[47]
Qingchuan Yang, Simon Mahns, Sida Li, Anri Gu, Jibang Wu, and Haifeng Xu. LLM -as-a-prophet: Understanding predictive intelligence with prophet arena. arxiv, 2025. URL https://arxiv.org/abs/2510.17638
-
[48]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct : Synergizing reasoning and acting in language models. In ICLR, 2023. URL http://dx.doi.org/10.48550/arXiv.2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2023
-
[49]
Zhiyuan Zeng, Jiashuo Liu, Siyuan Chen, Tianci He, Yali Liao, Yixiao Tian, Jinpeng Wang, Zaiyuan Wang, Yang Yang, Lingyue Yin, Mingren Yin, Zhenwei Zhu, Tianle Cai, Zehui Chen, Jiecao Chen, Yantao Du, Xiang Gao, Jiacheng Guo, Liang Hu, Jianpeng Jiao, Xiangsheng Li, Jingkai Liu, Shuang Ni, Zhoufutu Wen, Ge Zhang, Kaiyuan Zhang, Xin Zhou, Jose Blanchet, Xip...
-
[50]
Prediction Arena: Benchmarking AI Models on Real-World Prediction Markets
Jaden Zhang, Gardenia Liu, Oliver Johansson, Hileamlak Yitayew, Kamryn Ohly, and Grace Li. Prediction arena: Benchmarking AI models on real-world prediction markets. arxiv, 2026. URL https://arxiv.org/abs/2604.07355
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Forecasting future world events with neural networks
Andy Zou, Tristan Xiao, Ryan Jia, Joe Kwon, Mantas Mazeika, Richard Li, Dawn Song, Jacob Steinhardt, Owain Evans, and Dan Hendrycks. Forecasting future world events with neural networks. In NeurIPS (Datasets and Benchmarks), 2022. URL https://arxiv.org/abs/2206.15474
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.