Recognition: unknown
Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
Pith reviewed 2026-05-07 16:01 UTC · model grok-4.3
The pith
Aspect-aware and agentic evaluation reveals retriever behaviors missed by standard metrics, and fine-tuning on decomposed evidence data produces RTriever-4B with clear gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reasoning-intensive retrieval requires evidence portfolios that cover distinct aspects rather than isolated topical matches; current narrow gold sets and single-passage training therefore fail to measure or optimize the needed behavior. BRIGHT-Pro supplies expert-annotated multi-aspect gold evidence and evaluates retrievers under both static ranking and iterative agentic search, while RTriever-Synth generates aspect-decomposed complementary positives and positive-conditioned hard negatives for training. The resulting RTriever-4B substantially outperforms its base model across lexical, general-purpose, and reasoning-intensive retrievers when measured with aspect-aware and agentic metrics.
What carries the argument
BRIGHT-Pro, the expert-annotated benchmark that expands each query into multi-aspect gold evidence sets and runs both static and agentic search protocols; RTriever-Synth, the aspect-decomposed synthetic corpus that produces complementary positives and positive-conditioned hard negatives for fine-tuning.
If this is right
- Aspect-aware and agentic protocols reorder retriever rankings relative to standard single-metric leaderboards.
- Training on complementary positives and positive-conditioned negatives improves a retriever's ability to supply evidence across aspects rather than redundant passages.
- RTriever-4B demonstrates measurable gains over its base model on the expanded evaluation suite.
- Agentic search systems can iterate more effectively when retrievers are optimized for evidence complementarity instead of single-passage relevance.
Where Pith is reading between the lines
- Future agentic pipelines may need to select or combine retrievers according to aspect-coverage profiles rather than overall nDCG.
- The same decomposition approach could be applied to create training data for other multi-faceted retrieval settings such as legal or scientific literature search.
- If the gains hold, developers of reasoning agents would gain a practical recipe for adapting embedding models without full retraining.
Load-bearing premise
The expert-annotated multi-aspect gold evidence sets in BRIGHT-Pro and the aspect-decomposed complementary positives in RTriever-Synth accurately represent the evidence needs of downstream reasoning tasks in real agentic search systems.
What would settle it
If RTriever-4B, when inserted into a live agentic workflow on independently verified multi-step reasoning tasks, fails to increase the quality or completeness of the synthesized output compared with its base model, the claim that the new resources better capture required evidence portfolios would be falsified.
Figures










read the original abstract
Reasoning-intensive retrieval aims to surface evidence that supports downstream reasoning rather than merely matching topical similarity. This capability is increasingly important for agentic search systems, where retrievers must provide complementary evidence across iterative search and synthesis. However, existing work remains limited on both evaluation and training: benchmarks such as BRIGHT provide narrow gold sets and evaluate retrievers in isolation, while synthetic training corpora often optimize single-passage relevance rather than evidence portfolio construction. We introduce BRIGHT-Pro, an expert-annotated benchmark that expands each query with multi-aspect gold evidence and evaluates retrievers under both static and agentic search protocols. We further construct RTriever-Synth, an aspect-decomposed synthetic corpus that generates complementary positives and positive-conditioned hard negatives, and use it to LoRA fine-tune RTriever-4B from Qwen3-Embedding-4B. Experiments across lexical, general-purpose, and reasoning-intensive retrievers show that aspect-aware and agentic evaluation expose behaviors hidden by standard metrics, while RTriever-4B substantially improves over its base model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reasoning-intensive retrieval for agentic search systems requires better evaluation and training than current benchmarks like BRIGHT allow. It introduces BRIGHT-Pro, an expert-annotated expansion of queries with multi-aspect gold evidence sets evaluated under both static and agentic protocols, and RTriever-Synth, an aspect-decomposed synthetic corpus that generates complementary positives and positive-conditioned hard negatives. Using this corpus, the authors LoRA-fine-tune RTriever-4B from Qwen3-Embedding-4B and report that aspect-aware and agentic evaluations expose retriever behaviors hidden by standard metrics, while RTriever-4B substantially outperforms its base model across lexical, general-purpose, and reasoning-intensive retrievers.
Significance. If the central claims hold after addressing validation gaps, the work would be significant for the field: it directly targets the mismatch between single-passage topical retrieval and the complementary evidence portfolios needed for iterative reasoning in agents. The new benchmark and training corpus could become reference points for future agentic retrieval research, provided they are shown to correlate with downstream task gains.
major comments (2)
- [Abstract and §5 (Experiments)] The headline result—that aspect-aware and agentic protocols expose hidden behaviors and that RTriever-4B improves substantially—depends on BRIGHT-Pro and RTriever-Synth accurately representing the evidence needs of downstream reasoning agents. The manuscript does not report end-to-end agentic rollouts, human validation of the expert multi-aspect annotations against real multi-turn search traces, or inter-annotator agreement statistics for the gold sets.
- [§3.2] §3.2 (RTriever-Synth construction): The generation of aspect-decomposed complementary positives and positive-conditioned hard negatives is described at a high level, but no quantitative checks are provided on whether the positives are non-redundant, cover distinct reasoning aspects, or improve over single-query positives in controlled ablations.
minor comments (2)
- [Abstract] The abstract states that RTriever-4B 'substantially improves' without quoting any nDCG, recall, or win-rate deltas against the base model or other baselines; adding one or two key numbers would make the claim immediately evaluable.
- [§2] Notation for 'aspect-aware' versus 'agentic' protocols is used throughout but never given a compact formal definition or pseudocode; a small table or boxed definition in §2 would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below, providing clarifications on our design choices while committing to revisions that strengthen the empirical grounding of BRIGHT-Pro and RTriever-Synth.
read point-by-point responses
-
Referee: [Abstract and §5 (Experiments)] The headline result—that aspect-aware and agentic protocols expose hidden behaviors and that RTriever-4B improves substantially—depends on BRIGHT-Pro and RTriever-Synth accurately representing the evidence needs of downstream reasoning agents. The manuscript does not report end-to-end agentic rollouts, human validation of the expert multi-aspect annotations against real multi-turn search traces, or inter-annotator agreement statistics for the gold sets.
Authors: We agree that end-to-end agentic rollouts and direct alignment with real multi-turn search traces would offer stronger validation of representativeness. BRIGHT-Pro's agentic protocol (detailed in §5) models iterative evidence gathering by permitting multiple retrieval rounds conditioned on prior results, thereby testing for complementary multi-aspect coverage without requiring integration into a specific downstream agent. The multi-aspect gold sets were produced by domain experts following explicit guidelines to isolate distinct reasoning facets; we performed internal consistency reviews but did not compute formal inter-annotator agreement due to annotation cost. In the revised manuscript we will (i) add a limitations subsection explicitly discussing the absence of full rollouts and real-trace validation, (ii) report IAA on a re-annotated subset of queries, and (iii) clarify that the current protocol already reveals retrieval behaviors masked by static single-passage metrics. These changes address the concern without altering the core experimental claims. revision: partial
-
Referee: [§3.2] §3.2 (RTriever-Synth construction): The generation of aspect-decomposed complementary positives and positive-conditioned hard negatives is described at a high level, but no quantitative checks are provided on whether the positives are non-redundant, cover distinct reasoning aspects, or improve over single-query positives in controlled ablations.
Authors: We appreciate the call for quantitative validation of the synthetic corpus construction. Section 3.2 presents the aspect-decomposition pipeline at a methodological level to emphasize its novelty relative to prior single-query synthetic data. In the revised version we will augment §3.2 and the experiments with: (1) pairwise embedding similarity and aspect-diversity metrics demonstrating that the generated positives are non-redundant and span distinct reasoning dimensions, (2) semantic clustering analysis confirming aspect coverage, and (3) controlled ablation studies comparing downstream retrieval performance when training on aspect-decomposed positives versus conventional single-query positives. These additions will supply the missing empirical checks while preserving the paper's focus on the overall training paradigm. revision: yes
Circularity Check
No circularity: empirical benchmark construction and fine-tuning with independent experimental results
full rationale
The paper presents an empirical study that introduces BRIGHT-Pro (expert-annotated multi-aspect gold evidence sets) and RTriever-Synth (aspect-decomposed synthetic corpus for complementary positives and hard negatives), then reports LoRA fine-tuning of RTriever-4B from Qwen3-Embedding-4B and comparative experiments across retriever types under static and agentic protocols. No derivation chain, equations, or self-referential definitions exist that reduce any claimed result to prior inputs by construction. The central claims rest on new data creation and measured performance deltas rather than fitted parameters renamed as predictions or self-citation chains that close the argument. Per the evaluation criteria, this is self-contained empirical work with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert annotations provide reliable multi-aspect gold evidence that supports downstream reasoning
- domain assumption Aspect-decomposed synthetic positives and conditioned hard negatives produce training data that improves retriever performance on complementary evidence tasks
invented entities (2)
-
BRIGHT-Pro
no independent evidence
-
RTriever-Synth
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anirudh Ajith, Mengzhou Xia, Alexis Chevalier, Tanya Goyal, Danqi Chen, and Tianyu Gao
URLhttps://arxiv.org/abs/2504.10861. Anirudh Ajith, Mengzhou Xia, Alexis Chevalier, Tanya Goyal, Danqi Chen, and Tianyu Gao. Litsearch: A retrieval benchmark for scientific literature search,
-
[2]
Litsearch: A retrieval benchmark for scientific literature search,
URLhttps://arxiv.org/abs/2407.18940. Ehsan Kamalloo, Nandan Thakur, Carlos Lassance, Xueguang Ma, Jheng-Hong Yang, and Jimmy Lin. Resources for brewing beir: Reproducible reference models and statistical analyses. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, page 1431–1440,
-
[3]
URL https://doi.org/10.1145/3626772.3657862. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025a. Orion Weller, Benjamin Van Durme, Dawn Lawrie, Ashwin Par...
-
[4]
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nv-embed: Improved techniques for training llms as generalist embedding models.arXiv preprint arXiv:2405.17428,
work page internal anchor Pith review arXiv
-
[5]
Rar-b: Reasoning as retrieval benchmark
Chenghao Xiao, G Thomas Hudson, and Noura Al Moubayed. Rar-b: Reasoning as retrieval benchmark.arXiv preprint arXiv:2404.06347,
-
[6]
URLhttps://openreview.net/forum?id=ykuc5q381b. Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, et al. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent.arXiv preprint arXiv:2508.06600,
-
[7]
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents.arXiv preprint arXiv:2506.11763,
-
[8]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents, 2025a. URL https://arxiv.org/abs/2504.21798. Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Linhai Zhang, Yulan He, Deyu Zh...
work page internal anchor Pith review arXiv
-
[9]
arXiv preprint arXiv:2508.07995 , year=
URL https: //arxiv.org/abs/2508.07995. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025b. USTC, BAAI, and FlagOpen Team. BGE-Reasone...
-
[11]
Rank1: Test-time compute for reranking in information retrieval.arXiv preprint arXiv:2502.18418,
URL https://arxiv.org/abs/2502.18418. Debrup Das, Sam O’ Nuallain, and Razieh Rahimi. Rader: Reasoning-aware dense retrieval models,
-
[12]
Siyue Zhang, Yilun Zhao, Liyuan Geng, Arman Cohan, Anh Tuan Luu, and Chen Zhao
URL https://arxiv.org/abs/2505.18405. Siyue Zhang, Yilun Zhao, Liyuan Geng, Arman Cohan, Anh Tuan Luu, and Chen Zhao. Diffusion vs. autoregressive language models: A text embedding perspective.arXiv preprint arXiv:2505.15045, 2025d. Jiajie Jin, Yanzhao Zhang, Mingxin Li, Dingkun Long, Pengjun Xie, Yutao Zhu, and Zhicheng Dou. Laser: Internalizing explicit...
-
[13]
Limrank: Less is more for reasoning- intensive information reranking.ArXiv, abs/2510.23544, 2025b
Tingyu Song, Yilun Zhao, Siyue Zhang, Chen Zhao, and Arman Cohan. Limrank: Less is more for reasoning- intensive information reranking.ArXiv, abs/2510.23544, 2025b. Abdelrahman Abdallah, J. Holdcroft, M. Ali, and Adam Jatowt. Are llm-based retrievers worth their cost? an empirical study of efficiency, robustness, and reasoning overhead. 2026b. Rulin Shao,...
-
[14]
URLhttps://arxiv.org/abs/2510.14240. Li S. Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar. Researchqa: Evaluating scholarly question answering at scale across 75 fields with survey-mined questions and rubrics,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar
URL https://arxiv. org/abs/2509.00496. 10 Lei Xiong, Kun Luo, Ziyi Xia, Wenbo Zhang, Jin-Ge Yao, Zheng Liu, Jing Shao, Jianlyu Chen, Hongjin Qian, Xi Yang, Qian Yu, Hao Li, C. Yue, Xia’an Du, Yuyang Wang, Yesheng Liu, Haiyu Xu, and Zhicheng Dou. Autoresearchbench: Benchmarking ai agents on complex scientific literature discovery
-
[16]
Ruizhe Li, Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench ii: Diagnosing deep research agents via rubrics from expert report.ArXiv, abs/2601.08536,
-
[17]
Nikita Gupta, Riju Chatterjee, Lukas Haas, Connie Tao, Andrew Wang, Chang Liu, Hidekazu Oiwa, E. Gribovskaya, Jan Ackermann, John Blitzer, S. Goldshtein, and D. Das. Deepsearchqa: Bridging the comprehensiveness gap for deep research agents.ArXiv, abs/2601.20975,
-
[18]
Sage: Benchmarking and improving retrieval for deep research agents.ArXiv, abs/2602.05975,
Tiansheng Hu, Yilun Zhao, Canyu Zhang, Arman Cohan, and Chen Zhao. Sage: Benchmarking and improving retrieval for deep research agents.ArXiv, abs/2602.05975,
-
[19]
Association for Computing Machinery. ISBN 9781605581644. doi: 10.1145/1390334.1390446. URLhttps://doi.org/10.1145/1390334.1390446. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian ...
-
[20]
URL https://arxiv.org/abs/2412. 05579. Daniel Fernando Campos, Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, L. Deng, and Bhaskar Mitra. Ms marco: A human generated machine reading comprehension dataset.ArXiv, abs/1611.09268,
work page internal anchor Pith review arXiv
-
[21]
Scaling synthetic data creation with 1,000,000,000 personas.arXiv:2406.20094, 2024
Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas.ArXiv, abs/2406.20094,
-
[22]
27 Xinyi Zheng, Douglas Burdick, Lucian Popa, and Nancy Xin Ru Wang
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning. ArXiv, abs/2408.05517, 2024a. Stephen Robertson, Hugo Zaragoza, et al. The probabilistic relevance framework: Bm25 and beyond.Foundations and T...
-
[23]
Generative representational instruction tuning.arXiv preprint arXiv:2402.09906, 2024
Niklas Muennighoff, Hongjin Su, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Amanpreet Singh, and Douwe Kiela. Generative representational instruction tuning.arXiv preprint arXiv:2402.09906,
-
[24]
Smith, Luke Zettlemoyer, and Tao Yu
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A Smith, Luke Zettlemoyer, and Tao Yu. One embedder, any task: Instruction-finetuned text embeddings.arXiv preprint arXiv:2212.09741,
-
[25]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023b. Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel M. Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, A...
work page internal anchor Pith review arXiv
-
[26]
Junhan Yang, Jiahe Wan, Yichen Yao, Wei Chu, Yinghui Xu, Emma Wang, and Yuan Qi
URLhttps://arxiv.org/abs/2201.10005. Junhan Yang, Jiahe Wan, Yichen Yao, Wei Chu, Yinghui Xu, Emma Wang, and Yuan Qi. inf-retriever-v1 (revision 5f469d7), 2025c. URLhttps://huggingface.co/infly/inf-retriever-v1. Yilun Zhao, Yitao Long, Tintin Jiang, Chengye Wang, Weiyuan Chen, Hongjun Liu, Xiangru Tang, Yiming Zhang, Chen Zhao, and Arman Cohan. FinDVer: E...
-
[27]
Association for Computational Linguistics. ISBN 979-8-89176-380-7. doi: 10.18653/v1/2026.eacl-long.64. URLhttps://aclanthology.org/2026.eacl-long.64/. Benben Wang, Minghao Tang, Hengran Zhang, Jiafeng Guo, and Keping Bi. Training dense retrievers with multiple positive passages.ArXiv, abs/2602.12727,
-
[28]
Zheng Dou, Deqing Wang, Fuzhen Zhuang, Jian Ren, and Yanling Hu. Flew: Facet-level and adaptive weighted representation learning of scientific documents.ArXiv, abs/2509.07531,
-
[29]
ARK: Answer-Centric Retriever Tuning via KG-augmented Curriculum Learning
Jiawei Zhou, Hang Ding, and Haiyun Jiang. Ark: Answer-centric retriever tuning via kg-augmented curriculum learning.ArXiv, abs/2511.16326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Xincan Feng, Noriki Nishida, Yusuke Sakai, and Yuji Matsumoto. The wisdom of many queries: Complexity- diversity principle for dense retriever training.ArXiv, abs/2602.09448,
-
[31]
Why are mutations limited toGLOgenes?
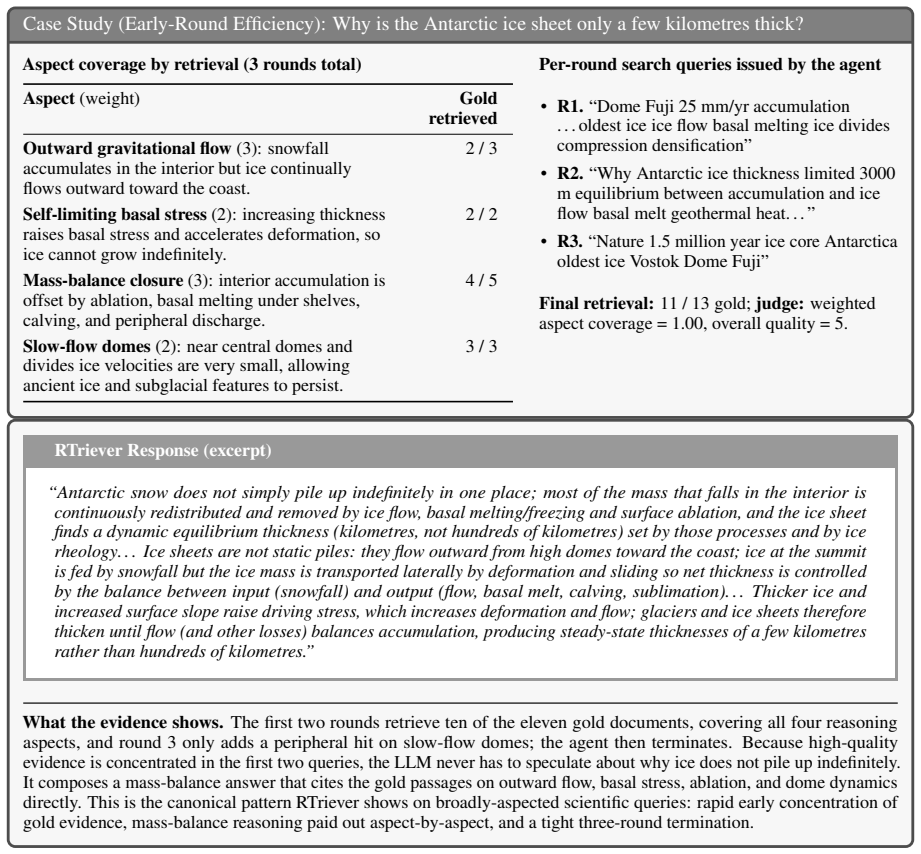
, where wis the weight-normalized mean of the per-aspect coverage scores using the Likert aspect weights. 16 F Agent Decoding and Search Configuration All agentic experiments share the LLM-side decoding and tool-side search settings listed below across both agent backends, so that performance differences across retrievers are attributable to retrieval qua...
2013
-
[32]
unmotivated seeing of connections accompanied by a specific feeling of abnormal meaningfulness
is defined as the “unmotivated seeing of connections accompanied by a specific feeling of abnormal meaningfulness”; introduced in the context of early-stage schizophrenia and distinguished from hallucination. (...abbreviation...) Reasoning Aspect 3 (weight = 0.22) Neuroimaging shows face-like (pareidolic) stimuli activate face-processing regions such as t...
2009
-
[33]
Is sexual reproduction outside the same biological family possible?
are never reached. The final response correctly describes the daylily–Lycoris example but treats reproductive-isolation mechanisms only at a generic level, yielding the partial answer that the aspect-aware judge scores at wac= 0.59 . The failure mode is search-dynamics: feedback from the early rounds narrows rather than expands the candidate set, even whe...
1992
-
[34]
what does EMXT mean / what units
RTriever Response (excerpt), detailed but lop-sided “EMXT is the ‘extreme maximum temperature’ for that station-month, i.e., the single highest daily maximum temperature within the month. . . The CSV/text export is the route to get machine-readable, multi-station data. . . How you can get the data you need (state or county, 1992–2012) in CSV form:(1) Use ...
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.