Recognition: unknown
ARMATA: Auto-Regressive Multi-Agent Task Assignment
Pith reviewed 2026-05-08 17:24 UTC · model grok-4.3
The pith
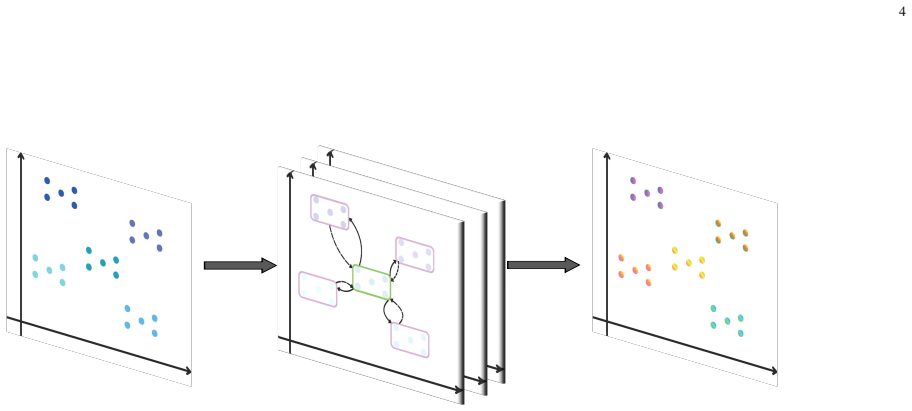
A centralized autoregressive decoder jointly generates multi-agent task allocations and routing sequences in one pass while tracking global state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The core contribution is a multi-stage decoding mechanism that unifies high-level allocation and low-level routing in a single autoregressive pass while maintaining a centralized global state. This enables the model to implicitly balance workload distribution with routing efficiency, avoiding local optima common in decentralized methods. Extensive experiments demonstrate that the resulting solutions improve quality by up to 20% over Google OR-Tools, IBM CPLEX, and LKH-3 while reducing computation time from hours to seconds.
What carries the argument
Multi-stage autoregressive decoder that unifies allocation decisions and routing sequences in one centralized pass.
If this is right
- Joint autoregressive generation captures inter-stage dependencies between allocation and routing that decoupled methods miss.
- Centralized global state prevents the local-optima traps that arise in decentralized heuristics.
- End-to-end training eliminates the need for separate solvers or manual post-processing steps.
- Solution quality improves by up to 20% while runtime drops from hours to seconds on the tested instances.
Where Pith is reading between the lines
- The same joint-decoding structure could be tested on dynamic settings where new tasks appear after agents have started moving.
- Extending the centralized state to include agent heterogeneity might allow direct handling of teams with different speeds or capacities.
- The implicit balancing learned by the decoder suggests the approach could reduce reliance on hand-crafted heuristics in other hierarchical assignment problems.
Load-bearing premise
The autoregressive decoder can reliably learn an implicit balance between workload distribution and routing efficiency without explicit constraints, post-processing, or problem-specific tuning.
What would settle it
Apply the trained model to a large instance with tight workload capacity limits and check whether it produces allocations that violate those limits or yield worse total route length than CPLEX.
Figures





read the original abstract
Coordinating multi-agent systems over spatially distributed areas requires solving a complex hierarchical problem: first distributing areas among agents (allocation) and subsequently determining the optimal visitation order (routing). Existing methods typically decouple these stages ignoring inter-stage dependencies or rely on decentralized heuristics that lack global context. In this work, we propose a centralized, fully end-to-end auto-regressive framework that jointly generates allocation decisions and routing sequences. The core contribution of our approach is a multi-stage decoding mechanism that unifies high-level allocation and low-level routing in a single autoregressive pass while maintaining a centralized global state. This enables the model to implicitly balance workload distribution with routing efficiency, avoiding local optima common in decentralized methods. Extensive experiments demonstrate that our method significantly outperforms diverse baselines, achieving up to a 20\% improvement in solution quality over industrial solvers such as Google OR-Tools, IBM CPLEX, and LKH-3, while reducing computation time from hours to seconds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ARMATA, a centralized end-to-end autoregressive framework for multi-agent task assignment that jointly solves area allocation and routing via a multi-stage decoder maintaining a global state. It claims this implicitly balances workload and efficiency, outperforming OR-Tools, CPLEX, and LKH-3 by up to 20% in solution quality while reducing runtime from hours to seconds.
Significance. If the experimental claims are substantiated with verifiable feasibility guarantees and rigorous reporting, the work could demonstrate a viable learning-based alternative to decoupled or heuristic methods for hierarchical combinatorial problems in multi-agent systems.
major comments (2)
- Abstract: the claim of 'up to a 20% improvement in solution quality' and 'extensive experiments' is unsupported because no information is supplied on instance sizes, number of trials, statistical significance, baseline configurations, data splits, or the exact quality metric; without these the data cannot be verified to support the central outperformance claim.
- Method section (multi-stage decoding mechanism): the autoregressive decoder is asserted to produce valid, complete assignments (all tasks allocated exactly once, valid tours) without explicit constraints, masking, or post-processing, yet no mechanism is described to enforce combinatorial feasibility during generation; this is load-bearing because any hidden repair step would mean the reported gains are not attributable to the end-to-end model as stated.
minor comments (1)
- Abstract: the phrase 'reducing computation time from hours to seconds' should be accompanied by concrete runtime tables or figures comparing against each baseline on the same instances.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity and verifiability, and we address each major comment below with our planned revisions.
read point-by-point responses
-
Referee: Abstract: the claim of 'up to a 20% improvement in solution quality' and 'extensive experiments' is unsupported because no information is supplied on instance sizes, number of trials, statistical significance, baseline configurations, data splits, or the exact quality metric; without these the data cannot be verified to support the central outperformance claim.
Authors: We agree that the abstract, as a concise summary, omits the specific experimental details needed for immediate verification of the performance claims. The full manuscript provides these in Section 4 (Experiments), covering instance sizes, trial counts, statistical reporting, baselines, and the total travel distance metric. To address the concern directly, we will revise the abstract to briefly incorporate key details on experimental scale and the quality metric while retaining the high-level summary. This is a partial revision. revision: partial
-
Referee: Method section (multi-stage decoding mechanism): the autoregressive decoder is asserted to produce valid, complete assignments (all tasks allocated exactly once, valid tours) without explicit constraints, masking, or post-processing, yet no mechanism is described to enforce combinatorial feasibility during generation; this is load-bearing because any hidden repair step would mean the reported gains are not attributable to the end-to-end model as stated.
Authors: The manuscript describes the multi-stage decoder as operating autoregressively over a maintained global state that tracks assignments and agent positions. We acknowledge that an explicit description of the feasibility enforcement (such as how the decoder restricts selections to unassigned tasks) is not provided in the current method section. We will revise the method section to include this clarification, confirming there is no post-processing or repair and that validity follows from the generation process itself. This is a full revision to the relevant subsection. revision: yes
Circularity Check
No circularity: empirical ML model with no derivation chain
full rationale
The paper describes a trained neural architecture (multi-stage autoregressive decoder) for joint allocation and routing, evaluated empirically against solvers. No equations, closed-form derivations, or first-principles results are present in the provided text. Claims rest on experimental outperformance rather than any self-referential reduction, fitted parameter renamed as prediction, or load-bearing self-citation. The approach is therefore self-contained as a data-driven method without circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-agent systems: A survey about its components, framework and workflow,
D. Maldonado, E. Cruz, J. Abad Torres, P. J. Cruz, and S. d. P. Gamboa Benitez, “Multi-agent systems: A survey about its components, framework and workflow,”IEEE Access, vol. 12, pp. 80 950–80 975, 2024
2024
-
[2]
Uav path planning for target coverage task in dynamic environment,
J. Li, Y . Xiong, and J. She, “Uav path planning for target coverage task in dynamic environment,”IEEE Internet of Things Journal, vol. 10, no. 20, pp. 17 734–17 745, 2023
2023
-
[3]
A coordinated scheduling approach for task assignment and multi-agent path planning,
C. Fang, J. Mao, D. Li, N. Wang, and N. Wang, “A coordinated scheduling approach for task assignment and multi-agent path planning,” Journal of King Saud University-Computer and Information Sciences, vol. 36, no. 1, p. 101930, 2024
2024
-
[4]
[Online]
Nov 2024. [Online]. Available: https://www.ibm.com/products/ ilog-cplex-optimization-studio
2024
-
[5]
Google OR-Tools,
Google OR-Tools Team, “Google OR-Tools,” https://developers.google. com/optimization/, 2024, accessed: 2024-08-13
2024
-
[6]
Toward energy-efficient routing of multiple agvs with multi-agent reinforcement learning,
X. Ye, Z. Deng, Y . Shi, and W. Shen, “Toward energy-efficient routing of multiple agvs with multi-agent reinforcement learning,”Sensors, vol. 23, no. 12, p. 5615, 2023
2023
-
[7]
Deep reinforcement learning for large- scale efficient routing of electric vehicles,
R. Shahbazian and F. Guerriero, “Deep reinforcement learning for large- scale efficient routing of electric vehicles,” in2024 International Con- ference on Automation in Manufacturing, Transportation and Logistics (ICaMaL), 2024, pp. 1–10
2024
-
[8]
Integrated task assignment and path planning for capacitated multi- agent pickup and delivery,
Z. Chen, J. Alonso-Mora, X. Bai, D. D. Harabor, and P. J. Stuckey, “Integrated task assignment and path planning for capacitated multi- agent pickup and delivery,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5816–5823, 2021
2021
-
[9]
A collaborative task allocation and path planning method for multi-unmanned vehicles based on dynamic energy consumption optimization,
Z. Li, J. Fan, P. Liu, and H. Zhang, “A collaborative task allocation and path planning method for multi-unmanned vehicles based on dynamic energy consumption optimization,” in2025 IEEE International Annual Conference on Complex Systems and Intelligent Science (CSIS-IAC), 2025, pp. 654–658
2025
-
[10]
Neural combinatorial optimization with reinforcement learning in industrial engineering: a survey,
K. Chung, C. Lee, and Y . Tsang, “Neural combinatorial optimization with reinforcement learning in industrial engineering: a survey,”Artifi- cial Intelligence Review, vol. 58, no. 5, p. 130, 2025
2025
-
[11]
A survey on reinforcement learning-based multi-agent path planning,
J. Hu, “A survey on reinforcement learning-based multi-agent path planning,” inITM Web of Conferences, vol. 78. EDP Sciences, 2025, p. 01015
2025
-
[12]
Path planning approaches in multi-robot system: A review,
S. Banik, S. C. Banik, and S. S. Mahmud, “Path planning approaches in multi-robot system: A review,”Engineering Reports, vol. 7, no. 1, p. e13035, 2025
2025
-
[13]
Dynamic multi-robot task allocation under uncertainty and temporal constraints,
S. Choudhury, J. K. Gupta, M. J. Kochenderfer, D. Sadigh, and J. Bohg, “Dynamic multi-robot task allocation under uncertainty and temporal constraints,”Autonomous Robots, vol. 46, no. 1, pp. 231–247, 2022
2022
-
[14]
An overview of vehicle routing problems,
P. Toth and D. Vigo, “An overview of vehicle routing problems,”The vehicle routing problem, pp. 1–26, 2002
2002
-
[15]
The vehicle routing problem: State of the art classification and review,
K. Braekers, K. Ramaekers, and I. Van Nieuwenhuyse, “The vehicle routing problem: State of the art classification and review,”Computers & industrial engineering, vol. 99, pp. 300–313, 2016
2016
-
[16]
Vehicle routing problem and its solution methodologies: a survey,
R. Goel and R. Maini, “Vehicle routing problem and its solution methodologies: a survey,”International Journal of Logistics Systems and Management, vol. 28, no. 4, pp. 419–435, 2017
2017
-
[17]
A heuristic algorithm for the asymmetric capacitated vehicle routing problem,
D. Vigo, “A heuristic algorithm for the asymmetric capacitated vehicle routing problem,”European Journal of Operational Research, vol. 89, no. 1, pp. 108–126, 1996
1996
-
[18]
Traveling salesman problem heuristics: Leading methods, implementations and latest advances,
C. Rego, D. Gamboa, F. Glover, and C. Osterman, “Traveling salesman problem heuristics: Leading methods, implementations and latest advances,”European Journal of Operational Research, vol. 211, no. 3, pp. 427–441, 2011. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0377221710006065
2011
-
[19]
Heuristics and meta- heuristics for solving capacitated vehicle routing problem: An algorithm comparison,
D. Muriyatmoko, A. Djunaidy, and A. Muklason, “Heuristics and meta- heuristics for solving capacitated vehicle routing problem: An algorithm comparison,”Procedia Computer Science, vol. 234, pp. 494–501, 2024
2024
-
[20]
Learning combinatorial optimization on graphs: A survey with applica- tions to networking,
N. Vesselinova, R. Steinert, D. F. Perez-Ramirez, and M. Boman, “Learning combinatorial optimization on graphs: A survey with applica- tions to networking,”IEEE Access, vol. 8, pp. 120 388–120 416, 2020
2020
-
[21]
Online vehicle routing with neural combinatorial optimization and deep reinforcement learning,
J. James, W. Yu, and J. Gu, “Online vehicle routing with neural combinatorial optimization and deep reinforcement learning,”IEEE Transactions on Intelligent Transportation Systems, vol. 20, no. 10, pp. 3806–3817, 2019
2019
-
[22]
Machine learning for combinato- rial optimization: a methodological tour d’horizon,
Y . Bengio, A. Lodi, and A. Prouvost, “Machine learning for combinato- rial optimization: a methodological tour d’horizon,”European Journal of Operational Research, vol. 290, no. 2, pp. 405–421, 2021
2021
-
[23]
Pointer networks,
O. Vinyals, M. Fortunato, and N. Jaitly, “Pointer networks,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[24]
Attention, Learn to Solve Routing Problems!
W. Kool, H. Van Hoof, and M. Welling, “Attention, learn to solve routing problems!”arXiv preprint arXiv:1803.08475, 2018
work page Pith review arXiv 2018
-
[25]
Neural Combinatorial Optimization with Reinforcement Learning
I. Bello, H. Pham, Q. V . Le, M. Norouzi, and S. Bengio, “Neural combinatorial optimization with reinforcement learning,”arXiv preprint arXiv:1611.09940, 2016
work page Pith review arXiv 2016
-
[26]
Pomo: Policy optimization with multiple optima for reinforcement learning,
Y .-D. Kwon, J. Choo, B. Kim, I. Yoon, Y . Gwon, and S. Min, “Pomo: Policy optimization with multiple optima for reinforcement learning,”Advances in Neural Information Processing Systems, vol. 33, pp. 21 188–21 198, 2020
2020
-
[27]
Neural combinatorial optimization with heavy decoder: Toward large scale generalization,
F. Luo, X. Lin, F. Liu, Q. Zhang, and Z. Wang, “Neural combinatorial optimization with heavy decoder: Toward large scale generalization,” Advances in Neural Information Processing Systems, vol. 36, pp. 8845– 8864, 2023
2023
-
[28]
Bq- nco: Bisimulation quotienting for efficient neural combinatorial opti- mization,
D. Drakulic, S. Michel, F. Mai, A. Sors, and J.-M. Andreoli, “Bq- nco: Bisimulation quotienting for efficient neural combinatorial opti- mization,”Advances in Neural Information Processing Systems, vol. 36, pp. 77 416–77 429, 2023
2023
-
[29]
Prompt learning for generalized vehicle routing,
F. Liu, X. Lin, W. Liao, Z. Wang, Q. Zhang, X. Tong, and M. Yuan, “Prompt learning for generalized vehicle routing,”arXiv preprint arXiv:2405.12262, 2024
-
[30]
The vehicle routing problem: A taxonomic review,
B. Eksioglu, A. V . Vural, and A. Reisman, “The vehicle routing problem: A taxonomic review,”Computers & Industrial Engineering, vol. 57, no. 4, pp. 1472–1483, 2009
2009
-
[31]
Multi-agent actor-critic for mixed cooperative-competitive environ- ments,
R. Lowe, Y . I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environ- ments,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[32]
Task and path planning for multi- agent pickup and delivery,
M. Liu, H. Ma, J. Li, and S. Koenig, “Task and path planning for multi- agent pickup and delivery,” inProceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2019
2019
-
[33]
Heterogeneous multi-robot task allocation and scheduling via reinforcement learning,
W. Dai, U. Rai, J. Chiun, C. Yuhong, and G. Sartoretti, “Heterogeneous multi-robot task allocation and scheduling via reinforcement learning,” IEEE Robotics and Automation Letters, 2025
2025
-
[34]
Multi-agent graph-attention communication and teaming
Y . Niu, R. R. Paleja, and M. C. Gombolay, “Multi-agent graph-attention communication and teaming.” inAAMAS, vol. 21, 2021, p. 20th
2021
-
[35]
Graph-based decentralized task allocation for multi-robot target localization,
J. Peng, H. Viswanath, and A. Bera, “Graph-based decentralized task allocation for multi-robot target localization,”IEEE Robotics and Au- tomation Letters, 2024
2024
-
[36]
Graph neural networks for decentralized multi-robot target 11 tracking,
L. Zhou, V . D. Sharma, Q. Li, A. Prorok, A. Ribeiro, P. Tokekar, and V . Kumar, “Graph neural networks for decentralized multi-robot target 11 tracking,” in2022 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR). IEEE, 2022, pp. 195–202
2022
-
[37]
L. Ratnabala, A. Fedoseev, R. Peter, and D. Tsetserukou, “Magnnet: Multi-agent graph neural network-based efficient task allocation for autonomous vehicles with deep reinforcement learning,”arXiv preprint arXiv:2502.02311, 2025
-
[38]
Decentralized multi-agent reinforcement learning based on best-response policies,
V . Gabler and D. Wollherr, “Decentralized multi-agent reinforcement learning based on best-response policies,”Frontiers in Robotics and AI, vol. 11, p. 1229026, 2024
2024
-
[39]
Parallel autoregressive models for multi-agent combinatorial optimization,
F. Berto, C. Hua, L. Luttmann, J. Son, J. Park, K. Ahn, C. Kwon, L. Xie, and J. Park, “Parallel autoregressive models for multi-agent combinatorial optimization,”arXiv preprint arXiv:2409.03811, 2024
-
[40]
Centralized deep reinforcement learning method for dynamic multi-vehicle pickup and delivery problem with crowdshippers,
C. Xiang, Z. Wu, J. Tu, and J. Huang, “Centralized deep reinforcement learning method for dynamic multi-vehicle pickup and delivery problem with crowdshippers,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 8, pp. 9253–9267, 2024
2024
-
[41]
Asynchronous multi-agent deep reinforcement learning under partial observability,
Y . Xiao, W. Tan, J. Hoffman, T. Xia, and C. Amato, “Asynchronous multi-agent deep reinforcement learning under partial observability,”The International Journal of Robotics Research, vol. 44, no. 8, pp. 1257– 1286, 2025
2025
-
[42]
An end-to-end deep reinforcement learning based modular task allocation framework for autonomous mobile systems,
S. Ma, J. Ruan, Y . Du, R. Bucknall, and Y . Liu, “An end-to-end deep reinforcement learning based modular task allocation framework for autonomous mobile systems,”IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 1519–1533, 2025
2025
-
[43]
An experimental study of neural networks for variable graphs,
X. Bresson and T. Laurent, “An experimental study of neural networks for variable graphs,”ICLR Workshop, 2018
2018
-
[44]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[45]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schul- man, J. Tang, and W. Zaremba, “Openai gym,”arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review arXiv 2016
-
[46]
Extending the openai gym for robotics: a toolkit for reinforcement learning using ros and gazebo,
I. Zamora, N. G. Lopez, V . M. Vilches, and A. H. Cordero, “Extending the openai gym for robotics: a toolkit for reinforcement learning using ros and gazebo,”arXiv preprint arXiv:1608.05742, 2016
-
[47]
gym-gazebo2, a toolkit for reinforcement learning using ros 2 and gazebo,
N. G. Lopez, Y . L. E. Nuin, E. B. Moral, L. U. S. Juan, A. S. Rueda, V . M. Vilches, and R. Kojcev, “gym-gazebo2, a toolkit for reinforcement learning using ros 2 and gazebo,”arXiv preprint arXiv:1903.06278, 2019
-
[48]
An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems,
K. Helsgaun, “An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems,” Roskilde University, Roskilde, Denmark, Technical Report, 2017. [Online]. Available: http://akira.ruc.dk/ ∼keld/research/LKH-3/LKH-3. pdf
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.