Recognition: 3 theorem links
· Lean TheoremOnline Nonstochastic Prediction: Logarithmic Regret via Predictive Online Least Squares
Pith reviewed 2026-05-08 18:20 UTC · model grok-4.3
The pith
Hints from a stabilizing Luenberger predictor bound residuals and deliver logarithmic regret for online least squares in marginally stable systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
With model knowledge, hints constructed from any stabilizing Luenberger predictor render the hint residuals uniformly bounded, achieving logarithmic regret despite unbounded trajectory growth. The unconstrained online least squares method is stabilized by these tailored predictive hints, allowing competition with the best-in-hindsight Luenberger predictor under nonstochastic disturbances.
What carries the argument
Tailored predictive hints from a stabilizing Luenberger predictor, which keep hint residuals uniformly bounded and thereby stabilize the online least squares updates.
If this is right
- The cumulative squared prediction loss grows only logarithmically rather than linearly with time.
- No bounds on disturbances or state trajectories are needed for the regret guarantee.
- A model-free universal hint works for symmetric systems while preserving logarithmic regret.
- The resulting predictor is adaptive and instance-optimal relative to any fixed-gain observer.
Where Pith is reading between the lines
- The same hint-based stabilization might extend to other prediction settings with neutral stability, such as certain time-series models.
- In downstream control tasks the logarithmic regret could translate to tighter performance bounds when the predictor is embedded in feedback.
- Numerical tests on real data with slowly diverging states would directly check whether the observed regret tracks the predicted logarithmic curve.
Load-bearing premise
The linear system must admit a stabilizing Luenberger predictor so that the observer error stays bounded and the hint residuals do not grow.
What would settle it
Simulate the algorithm on a detectable marginally stable system and check whether the hint residuals remain bounded and the regret grows only logarithmically over long time horizons with growing states.
Figures





read the original abstract
We study online prediction for marginally stable, partially observed linear dynamical systems under nonstochastic disturbances. Our objective is to minimize the cumulative squared prediction loss and compete with the best-in-hindsight Luenberger predictor. Standard online learning methods typically rely on bounded domains/gradients, and thus their guarantees may fail to deal with potentially unbounded trajectories in marginally stable systems. In this paper, we introduce an unconstrained online least squares method that stabilizes the learning process via tailored predictive hints. With model knowledge, we prove that hints constructed from any stabilizing Luenberger predictor render the hint residuals uniformly bounded, achieving logarithmic regret despite unbounded trajectory growth. We also discuss model-free prediction and introduce a simple universal hint for symmetric systems, under which logarithmic regret is maintained without model knowledge. Our results provide an adaptive, instance-wise optimal online predictor compared to classical fixed-gain observers under nonstochastic disturbances.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that for marginally stable partially observed linear dynamical systems under nonstochastic disturbances, an unconstrained online least-squares algorithm equipped with predictive hints derived from any stabilizing Luenberger observer achieves logarithmic regret against the best-in-hindsight Luenberger predictor, even when trajectories are unbounded. It further shows that a simple universal hint suffices for symmetric systems in the model-free setting, yielding the same logarithmic regret guarantee.
Significance. If the central claims hold, the result is significant: it supplies a concrete mechanism (bounded hint residuals from stable observer error dynamics) that lets standard online least-squares regret analysis apply to systems whose open-loop trajectories grow without bound. This yields an adaptive, instance-optimal predictor relative to fixed-gain observers and extends online learning beyond the usual bounded-gradient regime. The approach is technically clean and directly addresses a practical limitation of prior work on nonstochastic LDS prediction.
minor comments (3)
- [§3.1] §3.1, Algorithm 1: the precise construction of the predictive hint h_t from the Luenberger gain L and the current estimate should be written as an explicit equation rather than described in prose, to avoid any ambiguity in implementation.
- [Theorem 4.2] Theorem 4.2 (model-free case): the logarithmic regret is stated without an explicit constant; adding the dependence on the symmetry parameter or the disturbance bound would make the result more informative.
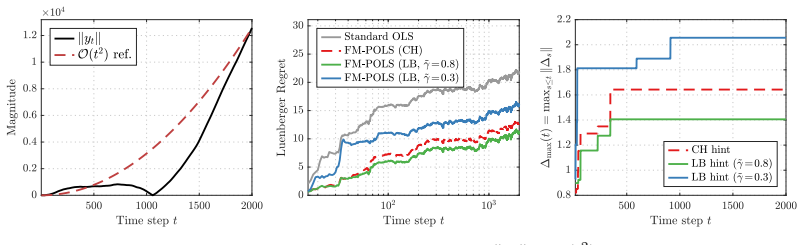
- [Figure 2] Figure 2: the y-axis scaling for the regret curves is not labeled with units or a clear reference to the theoretical O(log T) slope; this makes visual comparison with the bound less immediate.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, as well as the recommendation for minor revision. The referee correctly identifies the core technical contribution: that predictive hints derived from any stabilizing Luenberger observer yield bounded hint residuals, allowing standard online least-squares analysis to deliver logarithmic regret even for unbounded trajectories in marginally stable systems. We are pleased that the significance of extending online learning beyond bounded-gradient regimes is recognized.
Circularity Check
No significant circularity; derivation relies on standard stability properties and external comparator
full rationale
The paper derives logarithmic regret for online least-squares prediction by constructing hints from any stabilizing Luenberger observer on a detectable pair. This produces uniformly bounded residuals under bounded nonstochastic disturbances via the asymptotic stability of the observer error dynamics, a standard result from linear control theory that does not depend on the online algorithm or its regret bound. The comparator is explicitly the best fixed Luenberger predictor in hindsight, an external benchmark. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear; the central claim remains independent of the algorithm's outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The linear system is marginally stable and the pair (A,C) is detectable so that a stabilizing Luenberger predictor exists.
- domain assumption Disturbances are nonstochastic (adversarial) but the analysis holds for any sequence.
Reference graph
Works this paper leans on
-
[1]
A new approach to linear filtering an d prediction problems
Rudolph Emil Kalman. A new approach to linear filtering an d prediction problems. Transac- tions of the ASME–Journal of Basic Engineering , 1960
1960
-
[2]
Optimal state estimation: Kalman, H-infinity, and nonlinea r approaches
Dan Simon. Optimal state estimation: Kalman, H-infinity, and nonlinea r approaches. John Wiley & Sons, 2006
2006
-
[3]
Luenberger
David G. Luenberger. Observing the state of a linear syst em. IEEE Transactions on Military Electronics, 8(2):74–80, 1964
1964
-
[4]
Online control with adversarial disturbances
Naman Agarwal, Brian Bullins, Elad Hazan, Sham Kakade, a nd Karan Singh. Online control with adversarial disturbances. In International Conference on Machine Learning , pages 111–
-
[5]
Improper le arning for non-stochastic control
Max Simchowitz, Karan Singh, and Elad Hazan. Improper le arning for non-stochastic control. In Conference on Learning Theory , pages 3320–3436. PMLR, 2020
2020
-
[6]
Introduction to Online Control
Elad Hazan and Karan Singh. Introduction to online nonst ochastic control. arXiv preprint arXiv:2211.09619, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Learning linea r dynamical systems via spectral filtering
Elad Hazan, Karan Singh, and Cyril Zhang. Learning linea r dynamical systems via spectral filtering. Advances in Neural Information Processing Systems , 30, 2017
2017
-
[8]
Spectral filtering for general linear dynamical systems
Elad Hazan, Holden Lee, Karan Singh, Cyril Zhang, and Yi Z hang. Spectral filtering for general linear dynamical systems. Advances in Neural Information Processing Systems , 31, 2018
2018
-
[9]
On-line learning of linear dynamical systems: Exponential forgetting in Kalma n filters
Mark Kozdoba, Jakub Marecek, Tigran Tchrakian, and Shie Mannor. On-line learning of linear dynamical systems: Exponential forgetting in Kalma n filters. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 33, pages 4098–4105, 2019
2019
-
[10]
No-regret prediction in marginally stable systems
Udaya Ghai, Holden Lee, Karan Singh, Cyril Zhang, and Yi Zhang. No-regret prediction in marginally stable systems. In Conference on Learning Theory , pages 1714–1757. PMLR, 2020
2020
-
[11]
Online learnin g of the Kalman filter with logarithmic regret
Anastasios Tsiamis and George J Pappas. Online learnin g of the Kalman filter with logarithmic regret. IEEE Transactions on Automatic Control, 68(5):2774–2789, 2022
2022
-
[12]
SLIP: Learning to predict in unknown dy- namical systems with long-term memory
Paria Rashidinejad, Jiantao Jiao, and Stuart Russell. SLIP: Learning to predict in unknown dy- namical systems with long-term memory. Advances in Neural Information Processing Systems, 33:5716–5728, 2020
2020
-
[13]
Model-free online learnin g for the Kalman filter: Forgetting factor and logarithmic regret
Jiachen Qian and Y ang Zheng. Model-free online learnin g for the Kalman filter: Forgetting factor and logarithmic regret. arXiv preprint arXiv:2505.08982 , 2025
-
[14]
Logarithmic regret and pol ynomial scaling in online multi-step- ahead prediction
Jiachen Qian and Y ang Zheng. Logarithmic regret and pol ynomial scaling in online multi-step- ahead prediction. IEEE Control Systems Letters, 9:2981–2986, 2025
2025
-
[15]
Logarithmi c regret for online control
Naman Agarwal, Elad Hazan, and Karan Singh. Logarithmi c regret for online control. Ad- vances in Neural Information Processing Systems , 32, 2019
2019
-
[16]
Logarithmic regret fo r adversarial online control
Dylan Foster and Max Simchowitz. Logarithmic regret fo r adversarial online control. In International Conference on Machine Learning , pages 3211–3221. PMLR, 2020
2020
-
[17]
Online linear quadratic control
Alon Cohen, Avinatan Hasidim, Tomer Koren, Nevena Lazi c, Yishay Mansour, and Kunal Talwar. Online linear quadratic control. In International Conference on Machine Learning , pages 1029–1038. PMLR, 2018
2018
-
[18]
Logarithmic r egret for learning linear quadratic regulators efficiently
Asaf Cassel, Alon Cohen, and Tomer Koren. Logarithmic r egret for learning linear quadratic regulators efficiently. In International Conference on Machine Learning , pages 1328–1337. PMLR, 2020
2020
-
[19]
Naive exploration is o ptimal for online lqr
Max Simchowitz and Dylan Foster. Naive exploration is o ptimal for online lqr. In International Conference on Machine Learning , pages 8937–8948. PMLR, 2020. 11
2020
-
[20]
Logarithmic regret algorithms for online convex optimization
Elad Hazan, Amit Agarwal, and Satyen Kale. Logarithmic regret algorithms for online convex optimization. Machine Learning, 69(2):169–192, 2007
2007
-
[21]
Introduction to online convex optimizatio n
Elad Hazan. Introduction to online convex optimizatio n. F oundations and Trends in Optimiza- tion, 2(3-4):157–325, 2016
2016
-
[22]
A Modern Introduction to Online Learning
Francesco Orabona. A modern introduction to online lea rning. arXiv preprint arXiv:1912.13213, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[23]
Prediction, learning, and games
Nicolo Cesa-Bianchi and Gábor Lugosi. Prediction, learning, and games . Cambridge Univer- sity Press, 2006
2006
-
[24]
Competitive on-line statistics
V olodya V ovk. Competitive on-line statistics. International Statistical Review, 69(2):213–248, 2001
2001
-
[25]
Relative loss bound s for on-line density estimation with the exponential family of distributions
Katy S Azoury and Manfred K Warmuth. Relative loss bound s for on-line density estimation with the exponential family of distributions. Machine learning, 43(3):211–246, 2001
2001
-
[26]
Online learn ing with predictable sequences
Alexander Rakhlin and Karthik Sridharan. Online learn ing with predictable sequences. In Conference on Learning Theory , pages 993–1019. PMLR, 2013
2013
-
[27]
Optimization, le arning, and games with predictable sequences
Sasha Rakhlin and Karthik Sridharan. Optimization, le arning, and games with predictable sequences. Advances in Neural Information Processing Systems , 26, 2013
2013
-
[28]
Online linear regr ession in dynamic environments via discounting
Andrew Jacobsen and Ashok Cutkosky. Online linear regr ession in dynamic environments via discounting. arXiv preprint arXiv:2405.19175 , 2024
-
[29]
Learn ing linear dynamical systems with semi-parametric least squares
Max Simchowitz, Ross Boczar, and Benjamin Recht. Learn ing linear dynamical systems with semi-parametric least squares. In Conference on Learning Theory , pages 2714–2802. PMLR, 2019
2019
-
[30]
Annie Marsden and Elad Hazan. Universal sequence preco nditioning. arXiv preprint arXiv:2502.06545, 2025
-
[31]
Time series analysis: forecasting and control
George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and G reta M Ljung. Time series analysis: forecasting and control . John Wiley & Sons, 2015
2015
-
[32]
A generalized online mirror descent with applications to classification and regression
Francesco Orabona, Koby Crammer, and Nicolo Cesa-Bian chi. A generalized online mirror descent with applications to classification and regression . Machine Learning, 99(3):411–435, 2015. 12 Contents 1 Introduction 1 2 Problem Formulation 3 3 Predictive Online Least Squares for LDS 4 3.1 Online Least Squares with Predictive Hints . . . . . . . . . . . . . ....
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.