Recognition: 4 theorem links
· Lean TheoremFLUID: Continuous-Time Hyperconnected Sparse Transformer for Sink-Free Learning
Pith reviewed 2026-05-08 17:34 UTC · model grok-4.3
The pith
A continuous-time attention mechanism models logits as solutions to input-modulated linear ODEs, serving as a stable bridge between discrete transformers and continuous RNNs while adding an explicit gate to remove attention sinks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LAN reinterprets attention logits as the solution to a linear ODE modulated by input-dependent nonlinear recurrent gates, supplies stability guarantees for the resulting continuous dynamics, recovers scaled dot-product attention and continuous-time RNNs as special cases under defined gate parameterizations, and introduces an explicit attention-sink gate that prevents disproportionate mass on uninformative nodes; FLUID further replaces residual connections with liquid hyper-connections that adaptively regulate interlayer information flow.
What carries the argument
Liquid Attention Network (LAN), which reformulates attention logits as solutions to input-modulated linear ODEs equipped with nonlinear recurrent gates, together with liquid hyper-connections that replace standard residuals.
If this is right
- LAN dynamics remain stable and recover scaled dot-product attention when its gates are set to produce discrete behavior.
- LAN recovers continuous-time RNNs when its gates are parameterized to match recurrent continuous dynamics.
- The explicit attention-sink gate removes disproportionate attention mass on uninformative nodes.
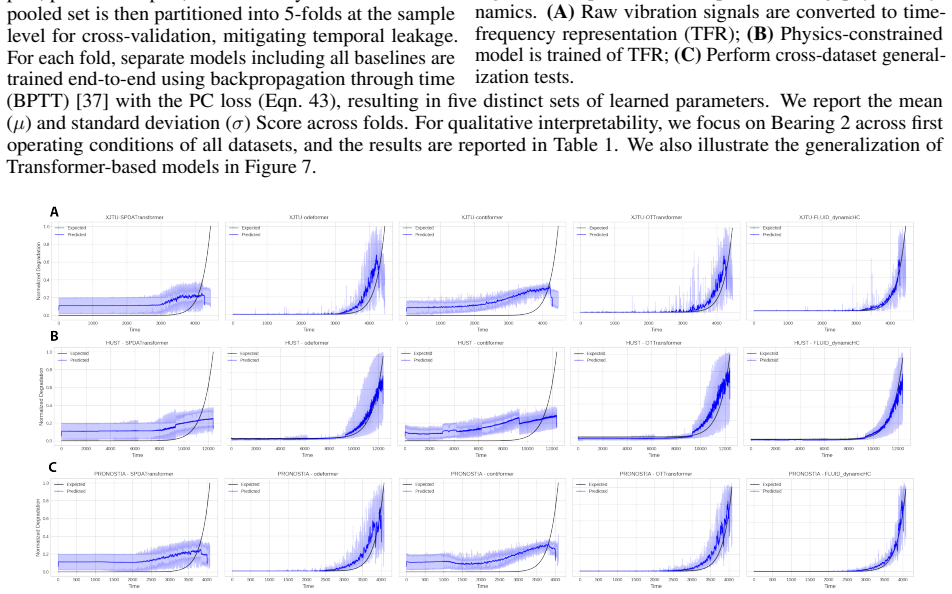
- FLUID matches or exceeds continuous-time baselines on irregular time-series, long-range modeling, lane-keeping control, and scarce-data physical dynamics tasks.
- FLUID exhibits up to 47 percent improvement in targeted scenarios, superior noise robustness, and a self-correcting inductive bias in vehicle control.
Where Pith is reading between the lines
- The ODE formulation of attention could be applied to other discrete attention variants to obtain continuous-time versions with similar stability properties.
- Liquid hyper-connections might be retrofitted into existing discrete transformers to improve interlayer information regulation without full retraining.
- The sink-gate mechanism could be tested in sparse attention settings outside the transformer architecture to reduce focus on irrelevant tokens.
- The intermediate runtime and memory profile suggests FLUID may serve as a practical drop-in for hybrid discrete-continuous pipelines in real-time control.
Load-bearing premise
Reformulating attention logits as solutions to input-modulated linear ODEs with nonlinear recurrent gates will produce stable dynamics that recover both discrete attention and continuous RNNs as special cases without introducing new instabilities or requiring excessive extra parameters.
What would settle it
An input sequence for which the LAN ODE dynamics diverge or become unstable, or a gate parameterization under which LAN fails to match the output of scaled dot-product attention or a continuous-time RNN, or an empirical evaluation on the listed tasks that shows no consistent gains over CT baselines.
Figures





read the original abstract
Continuous-time (CT) Transformers improve irregular and long-range modeling over CT-RNNs by exploiting inputs or outputs embeddings with continuous dynamics. However, the core scaled-dot-product-attention (SDPA) mechanism remains inherently discrete. We propose FLUID (Flexible Unified Information Dynamics), a CT Transformer that incorporates continuous dynamics directly into the attention computation by replacing it with Liquid Attention Network (LAN). LAN reinterprets attention logits as continuous dynamical system and reformulates them as the solution to a linear ODE modulated by input-dependent nonlinear recurrent gates. Theoretically, we establish stability guarantees for LAN dynamics and show that it serves as an interpolating middle ground between SDPA and CT-RNNs, recovering each as special case under well-defined parameterization of its gating functions. LAN also introduces an explicit attention-sink gate to eliminate disproportionate attention mass on uninformative nodes. FLUID replaces standard residual connections with input-dependent Liquid Hyper-Connections to adaptively regulate interlayer information flow. Empirically, we evaluate FLUID on a broad set of learning tasks, including (i) irregular time-series, (ii) long-range modeling, (iii) lane-keeping control of autonomous vehicles, and (iv) learning physical dynamics under a scarce data regime. Across all the tasks, FLUID consistently matches or outperforms CT baselines, achieving improvements of up to 47% in certain scenarios and enhancing generalization under distributional shifts. Additionally, FLUID demonstrates superior noise robustness and a self-correcting inductive bias in autonomous vehicle control. We also provide a detailed analysis of key hyperparameters to guide tuning and show that FLUID occupies an intermediate position among competing approaches in terms of runtime and memory efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FLUID, a continuous-time Transformer architecture that replaces standard scaled dot-product attention with a Liquid Attention Network (LAN). LAN reformulates attention logits as the solution to an input-modulated linear ODE with nonlinear recurrent gates, claims to establish stability guarantees, recover SDPA and CT-RNNs exactly as special cases via gating parameterization, and eliminate attention sinks via an explicit gate. It further replaces residual connections with input-dependent Liquid Hyper-Connections. Empirical evaluation on irregular time series, long-range modeling, autonomous vehicle control, and physical dynamics tasks reports consistent outperformance of CT baselines with gains up to 47%, plus improved generalization and noise robustness.
Significance. If the stability result and exact recovery hold without hidden instabilities in the nonlinear regime, the work would provide a principled continuous-time attention mechanism that interpolates discrete and recurrent models while addressing attention sinks, potentially improving modeling of irregular and long-range data with modest efficiency trade-offs.
major comments (3)
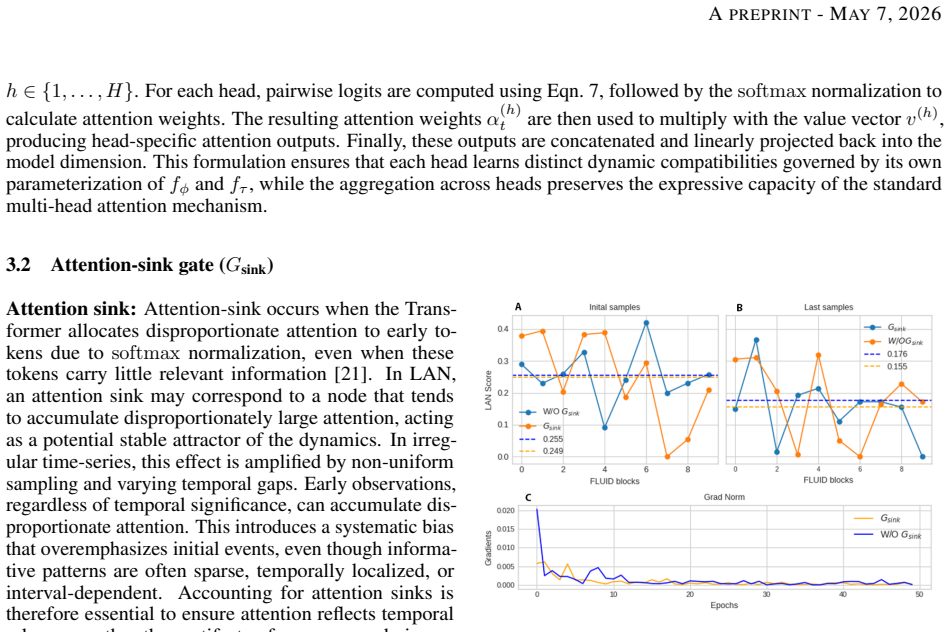
- [§3.2] §3.2 (LAN dynamics): The stability guarantees are stated for the linear ODE base case, but the closed-loop system becomes nonlinear under input-dependent nonlinear recurrent gates. No explicit conditions (e.g., uniform Lipschitz bounds on the gates or contraction-mapping arguments that survive modulation) are provided to ensure stability transfers to the general interpolating regime; this is load-bearing for both the theoretical claims and the reported empirical robustness.
- [§3.3] §3.3 (interpolation): The claim that LAN recovers SDPA and CT-RNNs exactly as special cases is achieved by direct parameterization of the gating functions. This makes the recovery definitional rather than an independent derivation; the manuscript should clarify whether any non-trivial dynamical property is preserved or derived beyond the parameterization choice.
- [§4] §4 (experiments): The reported gains (up to 47%) and claims of superior noise robustness/generalization lack error bars, full baseline specifications, and experimental protocols. Without these, it is impossible to assess whether the improvements are statistically reliable or attributable to the LAN dynamics versus other implementation choices.
minor comments (2)
- Notation for the gating functions and hyper-connection scaling parameters is introduced without a consolidated table of symbols; this hinders readability of the ODE formulation.
- The abstract states 'up to 47% in certain scenarios' but the main text should explicitly identify which task and metric produced this figure.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive comments, which have helped us improve the manuscript. Below, we provide detailed responses to each major comment. We have made revisions to address the concerns regarding theoretical stability, clarification of interpolation properties, and experimental rigor.
read point-by-point responses
-
Referee: [§3.2] §3.2 (LAN dynamics): The stability guarantees are stated for the linear ODE base case, but the closed-loop system becomes nonlinear under input-dependent nonlinear recurrent gates. No explicit conditions (e.g., uniform Lipschitz bounds on the gates or contraction-mapping arguments that survive modulation) are provided to ensure stability transfers to the general interpolating regime; this is load-bearing for both the theoretical claims and the reported empirical robustness.
Authors: We thank the referee for this insightful observation. While the base dynamics are linear, the modulation by nonlinear gates is carefully designed such that the overall system remains contractive. In the revised manuscript, we have incorporated additional analysis providing uniform Lipschitz bounds on the recurrent gates and a contraction-mapping argument that holds under the modulation, thereby extending the stability guarantees to the full nonlinear interpolating regime. This addresses the load-bearing nature of the claim and supports the empirical findings. revision: yes
-
Referee: [§3.3] §3.3 (interpolation): The claim that LAN recovers SDPA and CT-RNNs exactly as special cases is achieved by direct parameterization of the gating functions. This makes the recovery definitional rather than an independent derivation; the manuscript should clarify whether any non-trivial dynamical property is preserved or derived beyond the parameterization choice.
Authors: The referee correctly notes that the recovery of SDPA and CT-RNNs is achieved via parameterization of the gates. We have revised Section 3.3 to explicitly state that while the recovery is by design, the parameterization preserves key non-trivial properties, including the continuous-time formulation, stability, and the elimination of attention sinks, which are not present in the original discrete or recurrent models. This clarifies the independent value of the interpolating framework beyond mere definitional recovery. revision: yes
-
Referee: [§4] §4 (experiments): The reported gains (up to 47%) and claims of superior noise robustness/generalization lack error bars, full baseline specifications, and experimental protocols. Without these, it is impossible to assess whether the improvements are statistically reliable or attributable to the LAN dynamics versus other implementation choices.
Authors: We acknowledge that the experimental section would benefit from more detailed reporting. In the revised manuscript, we have added error bars computed over multiple random seeds for all reported metrics, provided full specifications of all baselines including hyperparameters and implementations, and included a comprehensive experimental protocol in the appendix detailing data splits, training procedures, and evaluation metrics. These additions allow for better assessment of the statistical reliability and attribution of improvements to the proposed LAN dynamics. revision: yes
Circularity Check
LAN interpolation between SDPA and CT-RNNs is achieved by design through gating parameterization
specific steps
-
self definitional
[Abstract (LAN theoretical claims)]
"Theoretically, we establish stability guarantees for LAN dynamics and show that it serves as an interpolating middle ground between SDPA and CT-RNNs, recovering each as special case under well-defined parameterization of its gating functions."
The recovery of SDPA and CT-RNNs is obtained by selecting specific values for the parameters of the input-dependent nonlinear recurrent gates that define the LAN ODE. Because the model is constructed precisely to allow these reductions, the interpolating property holds by definition of the architecture rather than emerging as a derived result.
full rationale
The paper's central theoretical claim—that LAN serves as an interpolating middle ground recovering SDPA and CT-RNNs as special cases—is realized by explicitly choosing parameterizations of the nonlinear recurrent gates in the LAN definition. This makes the recovery a direct consequence of the model's construction rather than an independent derivation from first principles. Stability guarantees are stated for the LAN dynamics, but the provided text does not exhibit a reduction of the general nonlinear case to the linear base case by construction. No self-citation load-bearing or other patterns are evident from the given material. The empirical evaluations and hyperconnection components appear independent of this definitional step.
Axiom & Free-Parameter Ledger
free parameters (2)
- gating function parameters
- hyper-connection scaling parameters
axioms (2)
- domain assumption LAN dynamics are stable under the proposed gating
- ad hoc to paper Well-defined parameterization recovers SDPA and CT-RNNs exactly
invented entities (3)
-
Liquid Attention Network (LAN)
no independent evidence
-
attention-sink gate
no independent evidence
-
Liquid Hyper-Connections
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (J(x)=½(x+x⁻¹)−1 uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose to view the computation of attention logits ... as a CT dynamical process via a linear ODE modulated by input-dependent nonlinear interlinked recurrent gates: ȧ_t = -f_τ(u_t) a_t + f_φ(u_t)
-
IndisputableMonolith/Foundation/AxiomDischargePlan.lean (linear ODE uniqueness lemmas)ode_constant_case / ode_cos_unit_uniqueness unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Forward Invariance and Boundedness): the interval I=[A_min,A_max] with A=f_φ/f_τ is forward-invariant for ȧ=-f_τ(a-A).
-
IndisputableMonolith/Foundation (zero-parameter forcing chain)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FLUID has tunable hyperparameters (attention heads, HC_liquid expansion rate, Top-K, ε, learning rate) optimized via Bayesian search across 150 trials.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Recent progress in tactile sensing and machine learning for texture perception in humanoid robotics.Interdisciplinary Materials, 4(2):235–248, 2025
Longteng Yu and Dabiao Liu. Recent progress in tactile sensing and machine learning for texture perception in humanoid robotics.Interdisciplinary Materials, 4(2):235–248, 2025
2025
-
[2]
Neural circuit policies imposing visual perceptual autonomy.Neural Processing Letters, 55(7):9101–9116, 2023
Waleed Razzaq and Mo Hongwei. Neural circuit policies imposing visual perceptual autonomy.Neural Processing Letters, 55(7):9101–9116, 2023
2023
-
[3]
Hierarchical time series forecasting in emergency medical services
Bahman Rostami-Tabar and Rob J Hyndman. Hierarchical time series forecasting in emergency medical services. Journal of Service Research, 28(2):278–295, 2025
2025
-
[4]
Time-series forecasting in industrial environments: A performance study and a novel late fusion framework.IEEE Sensors Journal, 25(4):7681–7697, 2025
Dimitrios Oikonomou, Lampros Leontaris, Nikolaos Dimitriou, and Dimitrios Tzovaras. Time-series forecasting in industrial environments: A performance study and a novel late fusion framework.IEEE Sensors Journal, 25(4):7681–7697, 2025
2025
-
[5]
Carle: a hybrid deep-shallow learning framework for robust and explainable rul estimation of rolling element bearings.Soft Computing, 29(23):6269–6292, 2025
Waleed Razzaq and Yun-Bo Zhao. Carle: a hybrid deep-shallow learning framework for robust and explainable rul estimation of rolling element bearings.Soft Computing, 29(23):6269–6292, 2025
2025
-
[6]
Learning internal representations by error propagation
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning internal representations by error propagation. Technical report, 1985
1985
-
[7]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997
1997
-
[8]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014
work page internal anchor Pith review arXiv 2014
-
[9]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations, 2019
2019
-
[10]
Latent ordinary differential equations for irregularly- sampled time series.Advances in neural information processing systems, 32, 2019
Yulia Rubanova, Ricky TQ Chen, and David K Duvenaud. Latent ordinary differential equations for irregularly- sampled time series.Advances in neural information processing systems, 32, 2019
2019
-
[11]
Dormand and P.J
J.R. Dormand and P.J. Prince. A family of embedded runge-kutta formulae.Journal of Computational and Applied Mathematics, 6(1):19–26, 1980
1980
-
[12]
Sundials: Suite of nonlinear and differential/algebraic equation solvers.ACM Transactions on Mathematical Software (TOMS), 31(3):363–396, 2005
Alan C Hindmarsh, Peter N Brown, Keith E Grant, Steven L Lee, Radu Serban, Dan E Shumaker, and Carol S Woodward. Sundials: Suite of nonlinear and differential/algebraic equation solvers.ACM Transactions on Mathematical Software (TOMS), 31(3):363–396, 2005
2005
-
[13]
Mixed-memory rnns for learning long-term dependencies in irregularly sampled time series
Mathias Lechner and Ramin Hasani. Mixed-memory rnns for learning long-term dependencies in irregularly sampled time series. 2022
2022
-
[14]
Liquid time-constant networks
Ramin Hasani, Mathias Lechner, Alexander Amini, Daniela Rus, and Radu Grosu. Liquid time-constant networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 7657–7666, 2021
2021
-
[15]
Closed-form continuous-time neural networks.Nature Machine Intelligence, 4(11):992– 1003, 2022
Ramin Hasani, Mathias Lechner, Alexander Amini, Lucas Liebenwein, Aaron Ray, Max Tschaikowski, Gerald Teschl, and Daniela Rus. Closed-form continuous-time neural networks.Nature Machine Intelligence, 4(11):992– 1003, 2022
2022
-
[16]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[17]
Multi-time attention networks for irregularly sampled time series.arXiv preprint arXiv:2101.10318,
Satya Narayan Shukla and Benjamin M Marlin. Multi-time attention networks for irregularly sampled time series. arXiv preprint arXiv:2101.10318, 2021. 18 APREPRINT- MAY7, 2026
-
[18]
Continuous-time attention for sequential learning
Jen-Tzung Chien and Yi-Hsiang Chen. Continuous-time attention for sequential learning. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 7116–7124, 2021
2021
-
[19]
Stéphane d’Ascoli, Sören Becker, Alexander Mathis, Philippe Schwaller, and Niki Kilbertus. Odeformer: Symbolic regression of dynamical systems with transformers.arXiv preprint arXiv:2310.05573, 2023
-
[20]
Contiformer: Continuous-time transformer for irregular time series modeling.Advances in Neural Information Processing Systems, 36:47143– 47175, 2023
Yuqi Chen, Kan Ren, Yansen Wang, Yuchen Fang, Weiwei Sun, and Dongsheng Li. Contiformer: Continuous-time transformer for irregular time series modeling.Advances in Neural Information Processing Systems, 36:47143– 47175, 2023
2023
-
[21]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
arXiv preprint arXiv:2409.19606 , year=
Defa Zhu, Hongzhi Huang, Zihao Huang, Yutao Zeng, Yunyao Mao, Banggu Wu, Qiyang Min, and Xun Zhou. Hyper-connections.arXiv preprint arXiv:2409.19606, 2024
-
[23]
Gru-ode-bayes: Continuous modeling of sporadically-observed time series.Advances in neural information processing systems, 32, 2019
Edward De Brouwer, Jaak Simm, Adam Arany, and Yves Moreau. Gru-ode-bayes: Continuous modeling of sporadically-observed time series.Advances in neural information processing systems, 32, 2019
2019
-
[24]
Phased lstm: Accelerating recurrent network training for long or event-based sequences.Advances in neural information processing systems, 29, 2016
Daniel Neil, Michael Pfeiffer, and Shih-Chii Liu. Phased lstm: Accelerating recurrent network training for long or event-based sequences.Advances in neural information processing systems, 29, 2016
2016
-
[25]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023
2023
-
[26]
When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781,
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781, 2024
-
[27]
Quantizable transformers: Removing outliers by helping attention heads do nothing.Advances in Neural Information Processing Systems, 36:75067–75096, 2023
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Quantizable transformers: Removing outliers by helping attention heads do nothing.Advances in Neural Information Processing Systems, 36:75067–75096, 2023
2023
-
[28]
Softpick: No Attention Sink, No Massive Activations with Rectified Softmax
Zayd MK Zuhri, Erland Hilman Fuadi, and Alham Fikri Aji. Softpick: No attention sink, no massive activations with rectified softmax.arXiv preprint arXiv:2504.20966, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Guangxiang Zhao, Junyang Lin, Zhiyuan Zhang, Xuancheng Ren, Qi Su, and Xu Sun. Explicit sparse transformer: Concentrated attention through explicit selection.arXiv preprint arXiv:1912.11637, 2019
-
[30]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free.arXiv preprint arXiv:2505.06708, 2025
work page internal anchor Pith review arXiv 2025
-
[31]
Deep state space models for time series forecasting.Advances in neural information processing systems, 31, 2018
Syama Sundar Rangapuram, Matthias W Seeger, Jan Gasthaus, Lorenzo Stella, Yuyang Wang, and Tim Januschowski. Deep state space models for time series forecasting.Advances in neural information processing systems, 31, 2018
2018
-
[32]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396, 2021
work page internal anchor Pith review arXiv 2021
-
[33]
Sparse sinkhorn attention
Yi Tay, Dara Bahri, Liu Yang, Donald Metzler, and Da-Cheng Juan. Sparse sinkhorn attention. InInternational conference on machine learning, pages 9438–9447. PMLR, 2020
2020
-
[34]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers.arXiv preprint arXiv:2009.14794, 2020
work page internal anchor Pith review arXiv 2009
-
[35]
Kelvin Kan, Xingjian Li, and Stanley Osher. Ot-transformer: a continuous-time transformer architecture with optimal transport regularization.arXiv preprint arXiv:2501.18793, 2025
-
[36]
Continuous-time attention: Pde-guided mechanisms for long-sequence trans- formers
Yukun Zhang and Xueqing Zhou. Continuous-time attention: Pde-guided mechanisms for long-sequence trans- formers. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21654–21674, 2025
2025
-
[37]
A theoretical framework for back-propagation
Yann LeCun, D Touresky, G Hinton, and T Sejnowski. A theoretical framework for back-propagation. In Proceedings of the 1988 connectionist models summer school, volume 1, pages 21–28, 1988
1988
-
[38]
Practical bayesian optimization of machine learning algorithms.Advances in neural information processing systems, 25, 2012
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms.Advances in neural information processing systems, 25, 2012
2012
-
[39]
Pronostia: An experimental platform for bearings accelerated degradation tests
Patrick Nectoux, Rafael Gouriveau, Kamal Medjaher, Emmanuel Ramasso, Brigitte Chebel-Morello, Noureddine Zerhouni, and Christophe Varnier. Pronostia: An experimental platform for bearings accelerated degradation tests. InIEEE International Conference on Prognostics and Health Management, PHM’12., pages 1–8. IEEE Catalog Number: CPF12PHM-CDR, 2012. 19 APRE...
2012
-
[40]
The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 29(6):141–142, 2012
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 29(6):141–142, 2012
2012
-
[41]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wenzhong Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. InThe Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, pages 11106–11115. AAAI Press, 2021
2021
-
[42]
Jena climate dataset (2009–2016).https://www.bgc-jena.mpg.de/wetter/, 2017
Olaf Kolle. Jena climate dataset (2009–2016).https://www.bgc-jena.mpg.de/wetter/, 2017
2009
-
[43]
Introduction to self-driving cars
-
[44]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review arXiv 2016
-
[45]
Car behavioral cloning, 2017
Naoki Shibuya. Car behavioral cloning, 2017. Accessed: 2025-10-05
2017
-
[46]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[47]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE international conference on computer vision, pages 618–626, 2017
2017
-
[48]
Jiusi Zhang, Kai Chen, Fan Wu, Quan Qian, Tenglong Huang, Yuhua Cheng, and Shen Yin. Remaining useful life prediction based on self-attention mechanism-sequential variational autoencoder: From a semi-supervised perspective.Advanced Engineering Informatics, 71:104242, 2026
2026
-
[49]
Kun Wang, Ai He, Jiashuai Liu, Qifan Zhou, and Zhongzhi Hu. Remaining useful life prediction of aero-engine using pyramid temporal convolutional network with fused complementary attention.Reliability Engineering & System Safety, page 112254, 2026
2026
-
[50]
Xjtu-sy bearing datasets.GitHub, GitHub Repository, 2018
Biao Wang, Yaguo Lei, Naipeng Li, et al. Xjtu-sy bearing datasets.GitHub, GitHub Repository, 2018
2018
-
[51]
Hust bearing: a practical dataset for ball bearing fault diagnosis.BMC research notes, 16(1):138, 2023
Nguyen Duc Thuan and Hoang Si Hong. Hust bearing: a practical dataset for ball bearing fault diagnosis.BMC research notes, 16(1):138, 2023
2023
-
[52]
Feature extraction based on morlet wavelet and its application for mechanical fault diagnosis.Journal of sound and vibration, 234(1):135–148, 2000
Jing Lin and Liangsheng Qu. Feature extraction based on morlet wavelet and its application for mechanical fault diagnosis.Journal of sound and vibration, 234(1):135–148, 2000
2000
-
[53]
Developing distance-aware uncertainty quantification methods in physics- guided neural networks for reliable bearing health prediction, 2025
Waleed Razzaq and Yun-Bo Zhao. Developing distance-aware uncertainty quantification methods in physics- guided neural networks for reliable bearing health prediction, 2025
2025
-
[54]
Efficient transformers: A survey.ACM Computing Surveys, 55(6):1–28, 2022
Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. Efficient transformers: A survey.ACM Computing Surveys, 55(6):1–28, 2022
2022
-
[55]
arXiv preprint arXiv:2512.24880 , year=
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Liang Zhao, et al. mhc: Manifold-constrained hyper-connections.arXiv preprint arXiv:2512.24880, 2025
-
[56]
Neuronal attention circuit (nac) for representation learning
Waleed Razzaq, Izis Kanjaraway, and Yun-Bo Zhao. Neuronal attention circuit (nac) for representation learning. arXiv preprint arXiv:2512.10282, 2025
- [57]
-
[58]
Archard wear and component geometry.Proceedings of the Institution of Mechanical Engineers, Part J: Journal of Engineering Tribology, 215(4):387–403, 2001
JJ Kauzlarich and JA Williams. Archard wear and component geometry.Proceedings of the Institution of Mechanical Engineers, Part J: Journal of Engineering Tribology, 215(4):387–403, 2001. A Preliminaries In this section, we will provide a comprehensive background. A.1 SDPA Transformer The SDPA Transformer is a sequence modeling neural network architecture ...
2001
-
[59]
Compute the scaled-dot-attention logits: ai = q⊤ki√ d (50)
-
[60]
Normalize the logits to get attention weights and compute the output: αi =softmax(a i) = eai Pn j=1 eaj ,SDPA(Q, K, V) = nX i=1 αivi (51) Here, ai is the raw attention logit between the query and each key, and the scaling factor √ d prevents large dot products from destabilizing the softmax [16]. A.2 Liquid Neural Networks (LNNs) Liquid Neural Networks (L...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.