Beyond Retrieval: A Multitask Benchmark and Model for Code Search
Pith reviewed 2026-05-11 01:21 UTC · model grok-4.3
The pith
A fine-tuned reranker delivers consistent gains across text-to-code, code-to-text, and code-to-code tasks where prior models do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a reranker fine-tuned on the CoREB multitask data becomes the first model to achieve consistent gains across text-to-code, code-to-text, and code-to-code tasks, while code-specialized embeddings dominate only code-to-code retrieval and off-the-shelf rerankers remain task-asymmetric with no baseline that helps on all three.
What carries the argument
The CoREB benchmark, built from counterfactually rewritten LiveCodeBench problems with timed releases and graded relevance judgments, together with the CoREB-Reranker fine-tuned on its multitask retrieval and reranking data.
If this is right
- Code-specialized embedding models achieve roughly twice the performance of general encoders on code-to-code retrieval.
- Short keyword queries, the format closest to actual developer use, drive every model to near-zero nDCG@10.
- Off-the-shelf rerankers exhibit large task asymmetry, with up to 12-point swings and no net-positive result across all tasks.
- Fine-tuning a reranker on the multitask benchmark overcomes the task-specific limitations seen in prior models.
Where Pith is reading between the lines
- Timed benchmark releases could allow repeated testing while tracking contamination over time.
- Counterfactual rewriting of problems might be used to create cleaner benchmarks for other retrieval or generation tasks.
- Embedding multitask rerankers into search tools could raise the quality of code suggestions that developers actually encounter.
Load-bearing premise
The counterfactually rewritten problems produce graded relevance judgments that stay free of label noise and match original developer intent without new biases.
What would settle it
A new model or reranker that shows no improvement over strong baselines when tested on independently collected real developer code search queries with fresh relevance labels would falsify the claim of consistent gains.
Figures












read the original abstract
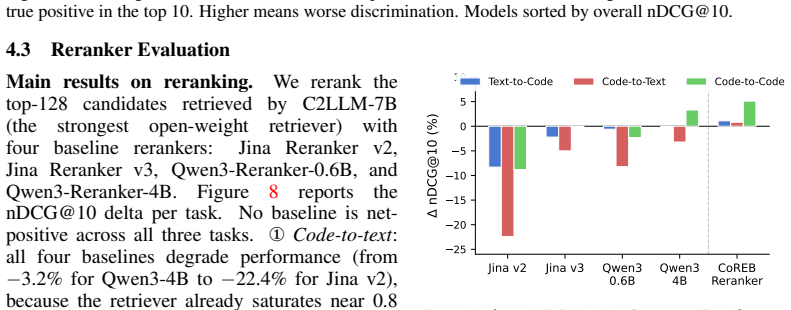
Code search has usually been evaluated as first-stage retrieval, even though production systems rely on broader pipelines with reranking and developer-style queries. Existing benchmarks also suffer from data contamination, label noise, and degenerate binary relevance. In this paper, we introduce \textsc{CoREB}, a contamination-limited, multitask \underline{co}de \underline{r}etrieval and r\underline{e}ranking \underline{b}enchmark, together with a fine-tuned code reranker, that goes beyond retrieval to cover the full code search pipeline. \textsc{CoREB} is built from counterfactually rewritten LiveCodeBench problems in five programming languages and delivered as timed releases with graded relevance judgments. We benchmark eleven embedding models and five rerankers across three tasks: text-to-code, code-to-text, and code-to-code. Our experiments reveal that: \circone code-specialised embeddings dominate code-to-code retrieval (${\sim}2{\times}$ over general encoders), yet no single model wins all three tasks; \circtwo short keyword queries, the format closest to real developer search, collapse every model to near-zero nDCG@10; \circthree off-the-shelf rerankers are task-asymmetric, with a 12-point swing on code-to-code and no baseline net-positive across all tasks; \circfour our fine-tuned \textsc{CoREB-Reranker} is the first to achieve consistent gains across all three tasks. The data and model are released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoREB, a contamination-limited multitask benchmark for code retrieval and reranking constructed from counterfactually rewritten LiveCodeBench problems across five languages with graded relevance judgments. It evaluates 11 embedding models and 5 rerankers on text-to-code, code-to-text, and code-to-code tasks, highlighting asymmetries in model performance (e.g., code-specialized embeddings excelling on code-to-code but no universal winner) and query format effects, while proposing a fine-tuned CoREB-Reranker that achieves the first consistent nDCG@10 gains across all three tasks. Data and model are released.
Significance. If the benchmark construction and graded labels prove robust, this advances code search evaluation by moving beyond first-stage retrieval to full pipelines, addressing data contamination, binary relevance, and label noise in prior benchmarks. The multitask design, empirical findings on short-keyword query collapse and reranker task-asymmetry, plus artifact release, provide a useful foundation for more realistic code search research.
major comments (3)
- [§3] §3 (Benchmark Construction): The counterfactual rewriting of LiveCodeBench problems to generate graded relevance judgments lacks explicit validation (e.g., human review of intent preservation or semantic equivalence checks). This is load-bearing for all reported nDCG@10 results and the headline claim of consistent reranker gains, as any intent drift or label noise from edits to control flow, variables, or edge cases could artifactually inflate the observed 12-point swings.
- [§5.3–5.4] §5.3–5.4 (Experiments and Results): The claim that CoREB-Reranker is the first to achieve net-positive gains across all three tasks is presented without statistical significance tests, confidence intervals, or multiple-run variance for the nDCG@10 differences. This weakens attribution of improvements to the model rather than benchmark-specific effects.
- [Table 3] Table 3 (or equivalent performance tables): No ablation compares results on original LiveCodeBench problems versus the rewritten versions, making it impossible to isolate whether the multitask gains stem from the reranker or from properties introduced by the rewriting process itself.
minor comments (2)
- [Abstract / §1] The abstract and §1 should clarify the exact timing and versioning mechanism for the 'timed releases' to support reproducibility claims.
- [§3.2] Notation for graded relevance (e.g., how 0–3 or similar scales map to nDCG computation) could be stated more explicitly in §3.2 to avoid ambiguity in replication.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will incorporate revisions to strengthen the manuscript's claims regarding benchmark validity, statistical rigor, and ablation analysis.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The counterfactual rewriting of LiveCodeBench problems to generate graded relevance judgments lacks explicit validation (e.g., human review of intent preservation or semantic equivalence checks). This is load-bearing for all reported nDCG@10 results and the headline claim of consistent reranker gains, as any intent drift or label noise from edits to control flow, variables, or edge cases could artifactually inflate the observed 12-point swings.
Authors: We appreciate this observation on the robustness of our benchmark construction. The rewriting process in §3 followed a structured protocol to preserve core problem intent, functionality, and semantics while introducing controlled counterfactual variations (e.g., variable renaming and control-flow adjustments that do not alter expected outputs). However, we acknowledge that a formal human validation study was not reported in the initial submission. In the revised manuscript, we will expand §3 with the full rewriting guidelines and include results from a targeted human evaluation (on a sample of problems across languages) confirming intent preservation and low label noise. This directly addresses concerns about potential artifacts in the nDCG@10 gains. revision: yes
-
Referee: [§5.3–5.4] §5.3–5.4 (Experiments and Results): The claim that CoREB-Reranker is the first to achieve net-positive gains across all three tasks is presented without statistical significance tests, confidence intervals, or multiple-run variance for the nDCG@10 differences. This weakens attribution of improvements to the model rather than benchmark-specific effects.
Authors: We agree that the absence of statistical analysis limits the strength of our attribution claims. The original experiments used single-run evaluations on the fixed CoREB splits. In the revised version, we will add bootstrap confidence intervals (with 1000 resamples) for all nDCG@10 scores and apply paired non-parametric tests (Wilcoxon signed-rank) to evaluate whether CoREB-Reranker's improvements over baselines are statistically significant across the three tasks. This will better isolate model contributions from benchmark-specific variance. revision: yes
-
Referee: [Table 3] Table 3 (or equivalent performance tables): No ablation compares results on original LiveCodeBench problems versus the rewritten versions, making it impossible to isolate whether the multitask gains stem from the reranker or from properties introduced by the rewriting process itself.
Authors: This is a valid methodological concern. While CoREB is designed as a contamination-limited benchmark with timed releases, we did not include a direct comparison to the original LiveCodeBench problems in the submitted manuscript. We will add this ablation in the revised paper: we will evaluate the same embedding models and rerankers on the subset of original LiveCodeBench problems that overlap with our rewritten set (where feasible) and report the delta in nDCG@10. This will help clarify the contribution of the rewriting process versus the reranker itself. revision: yes
Circularity Check
No circularity: purely empirical benchmark and model evaluation on released data
full rationale
The paper constructs CoREB from counterfactually rewritten LiveCodeBench problems, releases the data and fine-tuned CoREB-Reranker, then reports empirical nDCG@10 results across three tasks for eleven embeddings and five rerankers. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim of consistent gains is an empirical observation on the new benchmark rather than a reduction to prior inputs by construction. The study is self-contained against external benchmarks and released artifacts.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our experiments reveal that: ① code-specialised embeddings dominate code-to-code retrieval (~2× over general encoders), yet no single model wins all three tasks; ② short keyword queries... collapse every model to near-zero nDCG@10; ③ off-the-shelf rerankers are task-asymmetric...; ④ our fine-tuned CoREB-Reranker is the first to achieve consistent gains across all three tasks.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
COREB is built from counterfactually rewritten LiveCodeBench problems... with graded relevance judgments... relevance=2 to true positives, relevance=1 to same-problem hard negatives
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Provide ONLY executable source code−−no comments, no markdown, no explanations
-
[2]
Implement a ‘main()‘ function that: −reads all input from stdin, −computes the answer, −writes the result to stdout
-
[3]
Add any necessary helper functions (without comments)
-
[4]
Call ‘main()‘ at the bottom of the file
-
[5]
Do not modify the supplied starter skeleton: {{starter code}} Output Format −−−−−−−−−−−−− Wrap the final program in XML−style tags: <code> ...your code... </code> Generate the COMPLETE solution. Do not stop mid−function. Listing 1: Prompt template for code generation. Counterfactual Rewriting.To reduce surface-level contamination, each problem is passed t...
-
[6]
For purely numerical test cases (containing only numbers, basic operators, and data structures): −DO NOT MODIFY them at all−keep them exactly as they are −Example: Leave "[1, 2, 3]−>6" or "5 + 10 = 15" unchanged
-
[7]
For non−numerical test cases (containing domain−specific terms): −Make MINIMAL changes necessary to match your transformed problem context −PRESERVE the exact same algorithmic structure and complexity −Maintain the same input/output patterns and edge cases −Example: If you changed "count books on shelf" to "count tools in box", then "books=[’novel’,’textb...
-
[8]
ALL test cases must: −Remain syntactically correct in the target language −Test exactly the same edge cases and functionality −Have the same expected outputs for equivalent inputs ## Your Counterfactual Version Given the original problem: Title:{{question title}} Content: {{question content}} Starter Code: {{starter code}} 15 Public Test Cases: {{public t...
-
[9]
Operation-type change. Alter the fundamental operation the algorithm must perform (e.g., re- place a “remove / delete” goal with a “select / construct / merge” goal) so that the core algorithmic action is different, not merely renamed
-
[10]
Optimization-objective change. Invert or replace the optimization criterion (e.g., change “maxi- mize” to “minimize” or “count distinct”) so that what the algorithm optimizes for changes struc- turally
-
[11]
Algorithmic-approach change. Replace the algorithmic paradigm required to solve the problem (e.g., subsequence reasoning→contiguous-array or graph problems; greedy→dynamic pro- gramming; two-pointer→binary search) so that the required solution strategy is qualitatively different
-
[12]
Problem-domain change. Alter input data types and the problem context (e.g., strings→graphs, arrays→trees), producing a structurally distinct problem that shares no obvious surface mapping to the original. Generated texts are post-processed with a regular-expression pass to strip LLM-produced markdown headers and formatting artifacts (e.g., “Modified Prob...
work page 2076
-
[13]
The maximum sequence length is 4,096 tokens, with right-side truncation and left padding. We train the reranker on 8 NVIDIA A100 GPUs. Checkpoint merging.The released COREB-RERANKERcheckpoint is theuniform model soup(Wortsman et al., 2022) of two independently fine-tuned LoRA variants. Both variants share the same base model, LoRA configuration, optimizer...
work page 2022
-
[14]
found that aggressive quality filtering retains only 25.6% of CodeSearchNet-style repository- scraped data, and reports 15–25% test/train near-duplication. Because CodeSearchNet has served as public training data since 2019, models evaluated on it face severe contamination risk (Allamanis, 2019; Hernandez Lopez et al., 2024). B.12.4 CodeSearchNet-CCR: Str...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.