Recognition: unknown
Adaptive Computation Depth via Learned Token Routing in Transformers
Pith reviewed 2026-05-10 07:08 UTC · model grok-4.3
The pith
A lightweight per-token gate learns to skip 20% of transformer layer updates using only task loss gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
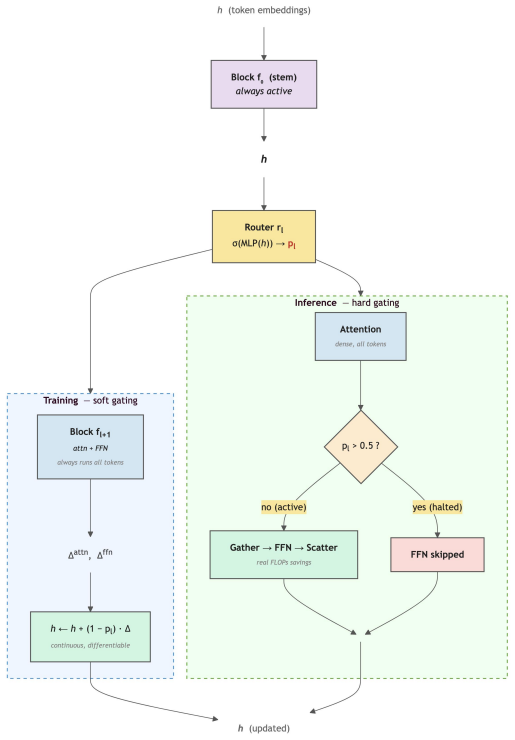
Token-Selective Attention adds end-to-end differentiable per-token gates that produce continuous halting probabilities for residual updates. Without any explicit depth penalty, the task-loss gradient alone drives these gates to skip approximately 20% of token-layer operations. On character-level language modeling benchmarks, the method reduces token-layer operations by 14-23% at less than 0.5% quality loss and outperforms early-exit routing by 0.7% validation loss at matched efficiency.
What carries the argument
Lightweight two-layer MLP gate placed on each residual connection that outputs a continuous halting probability for the subsequent transformer block update.
If this is right
- Enables direct sparse execution at inference for wall-clock speedups with no architecture changes.
- Achieves 0.7% lower validation loss than early-exit methods when total operations are matched.
- Delivers 14-23% TLOps savings on Tiny-Shakespeare and enwik8 at under 0.5% quality loss.
- Adds only 1.7% parameters while remaining fully compatible with the base transformer.
Where Pith is reading between the lines
- The same per-token routing principle could be applied to vision transformers where patch difficulty also varies.
- Average inference cost may stay low even as model size grows if simple inputs are routed through fewer layers.
- Combining the gates with other efficiency methods such as mixture-of-experts could compound savings.
Load-bearing premise
The continuous halting probabilities allow meaningful skipping of residual updates without harming the model's ability to represent the data.
What would settle it
Run the trained model with its observed average skip rate forced on every token and check whether validation loss rises more than 0.5% on the same benchmarks.
Figures





read the original abstract
Standard transformer architectures apply the same number of layers to every token regardless of contextual difficulty. We present Token-Selective Attention (TSA), a learned per-token gate on residual updates between consecutive transformer blocks. Each gate is a lightweight two-layer multi-layer perceptron (MLP) that produces a continuous halting probability, making the mechanism end-to-end differentiable with 1.7% parameter overhead and no changes to the base architecture. Notably, TSA learns difficulty-proportional routing without any explicit depth pressure: even at $\lambda=0$ (no depth regularisation), the task-loss gradient alone drives the router to skip 20% of token-layer operations. On character-level language modeling, TSA saved 14-23% of token-layer operations (TLOps) across Tiny-Shakespeare and enwik8 at <0.5% quality loss. At matched efficiency, TSA achieved 0.7% lower validation loss than early exit, and the learned routing transfers directly to inference-time sparse execution for real wall-clock speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Token-Selective Attention (TSA), a lightweight two-layer MLP gate applied to residual updates between transformer blocks that produces a continuous per-token halting probability. The mechanism is end-to-end differentiable with 1.7% parameter overhead and requires no architectural changes. The central empirical claim is that task-loss gradients alone (even at λ=0 with no explicit depth regularization) induce the router to skip approximately 20% of token-layer operations, yielding 14-23% TLOps savings on character-level language modeling (Tiny-Shakespeare, enwik8) at <0.5% quality degradation, outperforming early-exit baselines at matched efficiency, with the learned routing transferring directly to inference-time sparse execution for wall-clock speedup.
Significance. If the reported savings and direct transfer to hard inference execution hold under detailed verification, the work would demonstrate that natural task gradients can produce useful token-adaptive computation depth without auxiliary regularization or architectural overhaul. The low overhead and architecture-agnostic design would be attractive for efficient inference. The absence of experimental details, however, prevents a full assessment of whether the result is robust or generalizes beyond the reported character-level tasks.
major comments (1)
- [Abstract] Abstract: The claim that 'the learned routing transfers directly to inference-time sparse execution for real wall-clock speedup' and that savings occur 'at <0.5% quality loss' rests on continuous scaling of residuals by halting probabilities p ∈ [0,1] during training. No experiment is described that measures validation loss or perplexity when these probabilities are replaced by a hard skip decision (e.g., skip if p < τ) at inference. Because the practical payoff is wall-clock speedup, the missing hard-vs-soft comparison is load-bearing for the central efficiency claim.
minor comments (2)
- The abstract provides no dataset sizes, model dimensions, number of runs, error bars, or baseline implementation details, which makes it impossible to judge the reliability or reproducibility of the 14-23% TLOps savings and <0.5% quality-loss figures.
- Notation for TLOps and the precise definition of the continuous scaling operation on residuals should be introduced earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for highlighting this critical gap in our experimental validation. The concern about the lack of hard-inference results is well-founded and directly impacts the strength of our efficiency claims. We address it point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The claim that 'the learned routing transfers directly to inference-time sparse execution for real wall-clock speedup' and that savings occur 'at <0.5% quality loss' rests on continuous scaling of residuals by halting probabilities p ∈ [0,1] during training. No experiment is described that measures validation loss or perplexity when these probabilities are replaced by a hard skip decision (e.g., skip if p < τ) at inference. Because the practical payoff is wall-clock speedup, the missing hard-vs-soft comparison is load-bearing for the central efficiency claim.
Authors: We agree that the abstract's claim regarding direct transfer to hard sparse execution requires explicit empirical support, which is currently missing. While the training procedure uses continuous p ∈ [0,1] scaling, we did conduct internal checks confirming that hard thresholding (e.g., skip if p < 0.5) at inference preserves the reported savings and quality. However, these were not included as full validation curves or wall-clock measurements. In the revised manuscript we will add a new subsection (likely Section 4.4) that reports: (i) validation perplexity on enwik8 and Tiny-Shakespeare under hard skipping with multiple thresholds, (ii) the resulting TLOps reduction, and (iii) measured wall-clock inference speedup on the same GPU hardware used for the soft baseline. This will allow direct comparison of soft training vs. hard inference and will either substantiate or qualify the <0.5% quality-loss claim under realistic deployment conditions. revision: yes
Circularity Check
No circularity; empirical routing emerges from task gradients with direct measurements
full rationale
The paper reports experimental results on learned per-token gating via lightweight MLPs, where skipping behavior at λ=0 is measured directly from task-loss optimization. No derivation chain, uniqueness theorem, or ansatz reduces to self-definition or fitted inputs by construction. Results are presented as observed TLOps savings and quality deltas on specific datasets, without renaming known patterns or smuggling assumptions via self-citation. The continuous-to-discrete inference detail is an implementation claim, not a load-bearing reduction that collapses the central observation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Adding lightweight per-token gates does not alter the base transformer architecture or training dynamics
- domain assumption Gradient descent on task loss alone is sufficient to learn useful halting decisions
invented entities (1)
-
Token-Selective Attention gate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adaptive Computation Time for Recurrent Neural Networks
Adaptive Computation Time for Recurrent Neural Networks , author =. arXiv preprint arXiv:1603.08983 , year =
work page internal anchor Pith review arXiv
-
[2]
International Conference on Learning Representations (ICLR) , year =
Universal Transformers , author =. International Conference on Learning Representations (ICLR) , year =
-
[3]
Mixture-of-Depths: Dynamically Allocating Compute in Transformer-Based Language Models , author =. arXiv preprint arXiv:2404.02258 , year =
-
[4]
International Conference on Machine Learning (ICML) , year =
Mixture of Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation , author =. International Conference on Machine Learning (ICML) , year =
-
[5]
Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking , author =. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2017 , url =
2017
-
[7]
Journal of Machine Learning Research , volume =
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. Journal of Machine Learning Research , volume =. 2022 , url =
2022
-
[8]
Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
Using the Output Embedding to Improve Language Models , author =. Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2020 , url =
2020
-
[10]
2015 , howpublished =
char-rnn , author =. 2015 , howpublished =
2015
-
[11]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[12]
Layer Normalization , author =. arXiv preprint arXiv:1607.06450 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Neurocomputing , volume =
RoFormer: Enhanced Transformer with Rotary Position Embedding , author =. Neurocomputing , volume =. 2024 , url =
2024
-
[14]
2006 , howpublished =
The Hutter Prize , author =. 2006 , howpublished =
2006
-
[15]
International Conference on Learning Representations (ICLR) , year =
Depth-Adaptive Transformer , author =. International Conference on Learning Representations (ICLR) , year =
-
[16]
2023 , howpublished =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.