Recognition: 2 theorem links
· Lean TheoremNeural Co-state Policies: Structuring Hidden States in Recurrent Reinforcement Learning
Pith reviewed 2026-05-12 02:49 UTC · model grok-4.3
The pith
Recurrent reinforcement learning policies can have their hidden states aligned with co-states from optimal control by adding a dedicated loss term.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
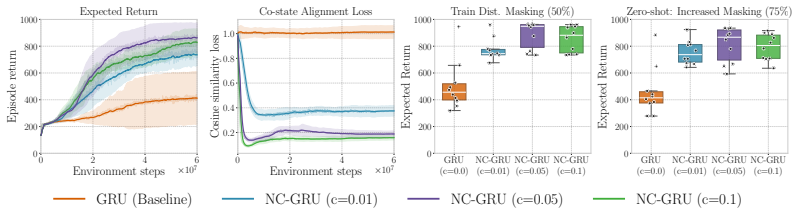
For standard recurrent architectures, latent representations map directly to PMP co-states, which allows the readout layer to be interpreted as performing Hamiltonian minimization. Because standard reward maximization does not naturally discover this alignment, a PMP-derived co-state loss is introduced to explicitly structure the internal dynamics. This approach matches or improves performance on partially observable DMControl tasks and remains effective under zero-shot out-of-distribution sensor masking.
What carries the argument
The co-state loss, which forces the evolution of recurrent hidden states to satisfy the co-state equations of the Pontryagin minimum principle so that the readout performs Hamiltonian minimization.
If this is right
- The structured policies achieve performance that matches or exceeds standard recurrent agents on partially observable continuous control benchmarks.
- Policies retain effectiveness when observation channels are masked in ways never encountered during training.
- Recurrent networks can be treated as dynamical systems whose evolution is governed by the minimum principle.
- Continuous control policies gain both robustness and a degree of interpretability through the enforced co-state structure.
Where Pith is reading between the lines
- Similar loss terms could be used to impose control-theoretic structure on memory states in non-recurrent or hybrid architectures.
- The co-state interpretation may let engineers inspect a trained policy by comparing its internal trajectories to those of an analytic optimal controller on the same task.
- Testing the same loss on real robotic hardware with actual sensor dropouts would show whether the simulated robustness carries over to physical systems.
Load-bearing premise
Standard reward maximization does not naturally produce an alignment between latent states and the co-state trajectories required by optimal control, so an explicit loss term is needed to enforce it.
What would settle it
Train identical recurrent policies on the same partially observable tasks with and without the co-state loss, then check whether the hidden states satisfy the co-state differential equations and whether performance stays stable under sensor masking; no measurable difference in alignment or robustness would indicate that the loss is not doing the claimed work.
Figures




read the original abstract
A key capability of intelligent agents is operating under partial observability: reasoning and acting effectively despite missing or incomplete state observations. While recurrent (memory-based) policies learned via reinforcement learning address this by encoding history into latent state representations, their internal dynamics remain uninterpretable black boxes. This paper establishes a formal link between these hidden states and the Pontryagin minimum principle (PMP) from optimal control. We demonstrate that for standard recurrent architectures, latent representations map directly to PMP co-states, which allows the readout layer to be interpreted as performing Hamiltonian minimization. Because standard reward maximization does not naturally discover this alignment, we introduce a PMP-derived co-state loss to explicitly structure the internal dynamics. Empirically, this approach matches or improves performance on partially observable DMControl tasks, and is robust against zero-shot out-of-distribution sensor masking. By framing recurrent networks as dynamic processes governed by the minimum principle, we provide a principled approach to designing robust continuous control policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a formal link between hidden states in standard recurrent RL policies and co-states from the Pontryagin Minimum Principle (PMP), such that the readout layer performs Hamiltonian minimization. It asserts that this alignment does not arise under standard reward maximization, so a PMP-derived co-state loss is introduced to structure the latent dynamics. Empirical evaluation on partially observable DMControl tasks shows performance matching or exceeding baselines, with added robustness to zero-shot sensor masking.
Significance. If the claimed mapping can be shown to hold independently of the auxiliary loss and the empirical gains prove robust with proper controls, the work would offer a principled control-theoretic interpretation of recurrent policies, potentially guiding more interpretable and robust designs for partial-observability settings. The absence of a parameter-free derivation or machine-checked proof, however, limits the immediate theoretical impact.
major comments (3)
- [Abstract] Abstract: The claim that 'for standard recurrent architectures, latent representations map directly to PMP co-states' is undercut by the subsequent statement that 'standard reward maximization does not naturally discover this alignment' and therefore requires an explicit co-state loss. If the loss is necessary to induce the reported alignment, the mapping is not an intrinsic property of standard RNN dynamics under reward maximization but an artifact of the auxiliary objective; this makes the Hamiltonian-minimization interpretation conditional rather than general.
- [Abstract] Abstract and §3 (presumed derivation section): No derivation steps, error bounds, or explicit proof are visible in the abstract, and the reader's report notes their absence. The central claim that the readout performs Hamiltonian minimization therefore cannot be verified as an independent consequence of the architecture versus a consequence of the PMP-derived loss definition.
- [Empirical evaluation] Empirical section (presumed §5): The abstract reports that the method 'matches or improves performance' and is 'robust against zero-shot out-of-distribution sensor masking,' yet provides no error bars, number of seeds, or statistical tests. Without these, it is impossible to assess whether the reported gains are reliable or whether the robustness claim holds under the same conditions as the baselines.
minor comments (2)
- Notation for the co-state loss and Hamiltonian should be introduced with explicit equations early in the paper to allow readers to check the claimed alignment without ambiguity.
- The abstract mentions 'partially observable DMControl tasks' but does not list the specific environments or observation masking protocols; these details belong in the main text or a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which have helped us clarify the manuscript's contributions and strengthen its presentation. We provide point-by-point responses to the major comments below. Revisions have been made to address concerns about clarity, empirical reporting, and the scope of the theoretical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'for standard recurrent architectures, latent representations map directly to PMP co-states' is undercut by the subsequent statement that 'standard reward maximization does not naturally discover this alignment' and therefore requires an explicit co-state loss. If the loss is necessary to induce the reported alignment, the mapping is not an intrinsic property of standard RNN dynamics under reward maximization but an artifact of the auxiliary objective; this makes the Hamiltonian-minimization interpretation conditional rather than general.
Authors: We agree that the original abstract wording could suggest an automatic mapping under any training regime. The manuscript's core insight is that the RNN architecture structurally permits hidden states to correspond to PMP co-states (via the co-state dynamics equation), enabling the readout to be interpreted as Hamiltonian minimization; however, standard reward maximization does not enforce the necessary alignment between latent trajectories and co-state trajectories. The PMP-derived loss is introduced precisely to induce this alignment in standard architectures. We have revised the abstract to state that the co-state alignment is achieved through the auxiliary loss, making the Hamiltonian interpretation conditional on this structuring but still applicable to standard recurrent policies. revision: yes
-
Referee: [Abstract] Abstract and §3 (presumed derivation section): No derivation steps, error bounds, or explicit proof are visible in the abstract, and the reader's report notes their absence. The central claim that the readout performs Hamiltonian minimization therefore cannot be verified as an independent consequence of the architecture versus a consequence of the PMP-derived loss definition.
Authors: Section 3 contains the derivation showing how the RNN hidden-state update can be aligned with co-state dynamics and why the readout then minimizes the Hamiltonian. The abstract omits these steps due to length constraints. To improve verifiability, we have expanded Section 3 with additional intermediate steps in the derivation, explicit conditions for the interpretation to hold, and a discussion of how the loss definition interacts with the architecture. We acknowledge that this remains a mathematical derivation rather than a machine-checked formal proof or one with explicit error bounds; the latter would require a different formal-methods approach outside the paper's scope. revision: partial
-
Referee: [Empirical evaluation] Empirical section (presumed §5): The abstract reports that the method 'matches or improves performance' and is 'robust against zero-shot out-of-distribution sensor masking,' yet provides no error bars, number of seeds, or statistical tests. Without these, it is impossible to assess whether the reported gains are reliable or whether the robustness claim holds under the same conditions as the baselines.
Authors: We agree that the empirical evaluation requires more statistical detail for reliable assessment. The revised manuscript now reports results over 10 random seeds with error bars (mean ± standard deviation), includes the exact seed count in the experimental setup, and adds pairwise t-tests with p-values to compare our method against baselines on both performance and robustness metrics. These additions confirm that the reported gains and zero-shot masking robustness are statistically significant under the evaluated conditions. revision: yes
Circularity Check
Claimed direct mapping of latents to PMP co-states is induced by auxiliary co-state loss rather than intrinsic to standard recurrent policies
specific steps
-
fitted input called prediction
[Abstract]
"We demonstrate that for standard recurrent architectures, latent representations map directly to PMP co-states, which allows the readout layer to be interpreted as performing Hamiltonian minimization. Because standard reward maximization does not naturally discover this alignment, we introduce a PMP-derived co-state loss to explicitly structure the internal dynamics."
The paper presents the latent-to-co-state mapping as a property of standard recurrent architectures under RL, yet acknowledges that ordinary reward maximization fails to produce the alignment and must be supplemented by a custom co-state loss. The reported mapping is therefore produced by construction of the auxiliary objective; the Hamiltonian-minimization reading is conditional on that loss rather than an intrinsic or independently derived fact about the networks.
full rationale
The paper asserts that latent states in standard recurrent architectures map directly to PMP co-states, enabling a Hamiltonian-minimization interpretation of the readout. However, it simultaneously states that this alignment is not discovered under standard reward maximization and therefore requires an explicit PMP-derived co-state loss to structure the dynamics. The mapping and resulting interpretation are therefore enforced by the custom loss term; without it the claimed alignment does not hold. This reduces the central 'demonstration' to a fitted consequence of the training objective rather than an independent derivation from the architecture or PMP itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pontryagin minimum principle can be directly applied to structure the hidden states of recurrent policies in reinforcement learning
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel contradicts?
contradictsCONTRADICTS: the theorem conflicts with this paper passage, or marks a claim that would need revision before publication.
Because standard reward maximization does not naturally discover this alignment, we introduce a PMP-derived co-state loss to explicitly structure the internal dynamics.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
u⋆ = argmin_u∈U H(x⋆, λ⋆, u) ... h(t) should act as a high-dimensional neural embedding of the theoretically optimal co-state λ⋆(t)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Moon, F. C. and Holmes, P. J. , title =. Journal of Sound and Vibration , year =. doi:10.1016/0022-460X(79)90520-0 , abstract =
-
[2]
Optimal Control Theory: An Introduction , author=. 2004 , publisher=
work page 2004
-
[3]
LXXXVIII. On “relaxation-oscillations” , author=. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science , volume=. 1926 , publisher=
work page 1926
-
[4]
First International Conference on Informatics in Control, Automation and Robotics , volume=
Iterative linear quadratic regulator design for nonlinear biological movement systems , author=. First International Conference on Informatics in Control, Automation and Robotics , volume=. 2004 , organization=
work page 2004
-
[5]
Diederik P. Kingma and Jimmy Ba , title =. Proceedings of the 3rd International Conference on Learning Representations (ICLR) , year =
- [6]
- [7]
-
[8]
L. S. Pontryagin , title =. 1987 , publisher =
work page 1987
-
[9]
Advances in Neural Information Processing Systems , volume=
Pontryagin differentiable programming: An end-to-end learning and control framework , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Efficient exploration in continuous-time model-based reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Mitter, S. K. , title =. Automatica , volume =. 1966 , issn =
work page 1966
-
[12]
Dormand, John R and Prince, Peter J , journal=. A family of embedded. 1980 , publisher=
work page 1980
-
[13]
H-infinity Optimal Control and Related Minimax Design Problems: A Dynamic Game Approach , author=. 2008 , publisher=
work page 2008
-
[14]
Kelly, Matthew , title =. SIAM Review , year =. doi:10.1137/16M1062569 , eprint =
-
[15]
Approximate Dynamic Programming: Solving the Curses of Dimensionality , author=. 2011 , publisher=
work page 2011
-
[16]
Physical Review Letters , volume=
Linear theory for control of nonlinear stochastic systems , author=. Physical Review Letters , volume=. 2005 , publisher=
work page 2005
-
[17]
Foundations and Trends in Machine Learning , volume=
Bayesian Reinforcement Learning: A Survey , author=. Foundations and Trends in Machine Learning , volume=. 2015 , publisher=
work page 2015
-
[18]
Proceedings of the 28th International Conference on machine learning , pages=
PILCO: A model-based and data-efficient approach to policy search , author=. Proceedings of the 28th International Conference on machine learning , pages=
-
[19]
International Conference on Artificial Intelligence and Statistics , pages=
Data-efficient reinforcement learning with probabilistic model predictive control , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2018 , organization=
work page 2018
-
[20]
Advances in Neural Information Processing Systems , volume=
Deep reinforcement learning in a handful of trials using probabilistic dynamics models , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Neural ordinary differential equations , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
International Conference on Machine Learning , pages=
Continuous-time Model-based Reinforcement Learning , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[23]
Applied Optimal Control: Optimization, Estimation, and Control , author=. 1975 , publisher=
work page 1975
- [24]
-
[25]
Schroeder, M. , journal=. Synthesis of low-peak-factor signals and binary sequences with low autocorrelation (Corresp.) , year=
-
[26]
Proceedings of the 2020 Conference on Robot Learning , pages =
Sample-efficient Cross-Entropy Method for Real-time Planning , author =. Proceedings of the 2020 Conference on Robot Learning , pages =. 2021 , editor =
work page 2020
-
[27]
Hybrid monte carlo , author=. Physics letters B , volume=. 1987 , publisher=
work page 1987
-
[28]
SIAM Journal on control and optimization , volume=
A general stochastic maximum principle for optimal control problems , author=. SIAM Journal on control and optimization , volume=. 1990 , publisher=
work page 1990
-
[29]
ESAIM: Control, Optimisation and Calculus of Variations , volume=
Optimal control of ensembles of dynamical systems , author=. ESAIM: Control, Optimisation and Calculus of Variations , volume=. 2023 , publisher=
work page 2023
-
[30]
Necessary optimality conditions for average cost minimization problems , journal =. 2019 , issn =. doi:10.3934/dcdsb.2019086 , url =
-
[31]
Mathematics of Control, Signals, and Systems , volume=
Convergence results for an averaged LQR problem with applications to reinforcement learning , author=. Mathematics of Control, Signals, and Systems , volume=. 2021 , publisher=
work page 2021
-
[32]
On the dynamics of small continuous-time recurrent neural networks , author=. Adaptive Behavior , volume=. 1995 , publisher=
work page 1995
-
[33]
Optimal Control of Probabilistic Dynamics Models via Mean
Leeftink, David and Yildiz, Cagatay and Ridderbusch, Steffen and Hinne, Max and Van Gerven, Marcel , booktitle=. Optimal Control of Probabilistic Dynamics Models via Mean. 2025 , volume=
work page 2025
-
[34]
SIAM Journal on Control , volume=
Necessary conditions for continuous parameter stochastic optimization problems , author=. SIAM Journal on Control , volume=. 1972 , publisher=
work page 1972
-
[35]
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
work page 1992
-
[36]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[38]
2020 , month=sep # " 15", publisher=
Continuous control with deep reinforcement learning , author=. 2020 , month=sep # " 15", publisher=
work page 2020
-
[39]
A mathematical theory of the functional dynamics of cortical and thalamic nervous tissue , author=. Kybernetik , volume=. 1973 , publisher=
work page 1973
-
[40]
Central pattern generators and the control of rhythmic movements , author=. Current biology , volume=. 2001 , publisher=
work page 2001
-
[41]
Logic Journal of IGPL , volume=
Recurrent policy gradients , author=. Logic Journal of IGPL , volume=. 2010 , publisher=
work page 2010
-
[42]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Empirical evaluation of gated recurrent neural networks on sequence modeling , author=. arXiv preprint arXiv:1412.3555 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Calculus of variations and optimal control theory: a concise introduction , author=. 2011 , publisher=
work page 2011
-
[44]
International Journal of Systems Science , volume=
Every good regulator of a system must be a model of that system , author=. International Journal of Systems Science , volume=. 1970 , publisher=
work page 1970
-
[45]
The internal model principle of control theory , author=. Automatica , volume=. 1976 , publisher=
work page 1976
-
[46]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
High-dimensional continuous control using generalized advantage estimation , author=. arXiv preprint arXiv:1506.02438 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Artificial intelligence , volume=
Planning and acting in partially observable stochastic domains , author=. Artificial intelligence , volume=. 1998 , publisher=
work page 1998
- [48]
-
[49]
1986 25th IEEE Conference on Decision and Control , pages=
Is the costate variable the state derivative of the value function? , author=. 1986 25th IEEE Conference on Decision and Control , pages=. 1986 , organization=
work page 1986
-
[50]
Dynamic programming , author=. Science , volume=. 1966 , publisher=
work page 1966
-
[51]
Frontiers in Computational Neuroscience , volume=
Artificial neural networks as models of neural information processing , author=. Frontiers in Computational Neuroscience , volume=. 2017 , publisher=
work page 2017
-
[52]
Linking connectivity, dynamics, and computations in low-rank recurrent neural networks , author=. Neuron , volume=. 2018 , publisher=
work page 2018
-
[53]
Learning for Dynamics and Control , pages=
Robust deep learning as optimal control: Insights and convergence guarantees , author=. Learning for Dynamics and Control , pages=. 2020 , organization=
work page 2020
-
[54]
Advances in neural information processing systems , volume=
Hamiltonian neural networks , author=. Advances in neural information processing systems , volume=
-
[55]
arXiv preprint arXiv:1907.04490 , year=
Deep Lagrangian networks: Using physics as model prior for deep learning , author=. arXiv preprint arXiv:1907.04490 , year=
-
[56]
Proceedings of the National Academy of Sciences , volume=
Cerebellar contributions to action and cognition: Prediction, timescale, and continuity , author=. Proceedings of the National Academy of Sciences , volume=. 2026 , publisher=
work page 2026
-
[57]
arXiv preprint arXiv:2212.14566 , year=
Pontryagin optimal control via neural networks , author=. arXiv preprint arXiv:2212.14566 , year=
-
[58]
Efficiently Modeling Long Sequences with Structured State Spaces
Efficiently modeling long sequences with structured state spaces , author=. arXiv preprint arXiv:2111.00396 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Coupled oscillatory recurrent neural network (
Rusch, T Konstantin and Mishra, Siddhartha , journal=. Coupled oscillatory recurrent neural network (
-
[60]
Proceedings of the Seventh Annual Learning for Dynamics & Control Conference , pages =
A Pontryagin Perspective on Reinforcement Learning , author =. Proceedings of the Seventh Annual Learning for Dynamics & Control Conference , pages =. 2025 , series =
work page 2025
-
[61]
arXiv preprint arXiv:2206.10313 , year=
Active inference for robotic manipulation , author=. arXiv preprint arXiv:2206.10313 , year=
-
[62]
DeepMind Control Suite. arXiv e-prints , keywords =. doi:10.48550/arXiv.1801.00690 , archivePrefix =. 1801.00690 , primaryClass =
work page internal anchor Pith review doi:10.48550/arxiv.1801.00690
-
[63]
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
work page 1997
-
[64]
Timothy P. Lillicrap and Jonathan J. Hunt and Alexander Pritzel and Nicolas Heess and Tom Erez and Yuval Tassa and David Silver and Daan Wierstra , title =. 4th International Conference on Learning Representations,. 2016 , address =
work page 2016
-
[65]
arXiv preprint arXiv:2106.13281 , year=
Brax--a differentiable physics engine for large scale rigid body simulation , author=. arXiv preprint arXiv:2106.13281 , year=
-
[66]
International Conference on Machine Learning , pages=
Dynamic game theoretic neural optimizer , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[67]
SIAM Journal on Numerical Analysis , volume=
Value-gradient based formulation of optimal control problem and machine learning algorithm , author=. SIAM Journal on Numerical Analysis , volume=. 2023 , publisher=
work page 2023
-
[68]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Yash Katariya and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[69]
The ICLR Blog Track 2023 , year=
The 37 implementation details of proximal policy optimization , author=. The ICLR Blog Track 2023 , year=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.