Socio-Conformal Calibration in Complex Survey Data: Marginal Validity Is Not Enough for Subgroup Reliability
Pith reviewed 2026-05-08 08:10 UTC · model grok-4.3
The pith
Marginal coverage from conformal prediction fails to ensure reliable uncertainty estimates across demographic subgroups in complex survey data, and group-specific calibration does not fix the problem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Standard split conformal prediction attains nominal marginal coverage for all four base predictors yet produces weighted subgroup coverage gaps of approximately 13 percentage points; Mondrian conformal prediction raises weighted set size by 0.036 while widening the subgroup gap by 0.013 for the XGBoost predictor, and a regularized Mondrian comparator reduces the gap by only 0.001 at the cost of a 0.012 increase in set size, with the negative result persisting across alternate outcome codings and subgroup granularities.
What carries the argument
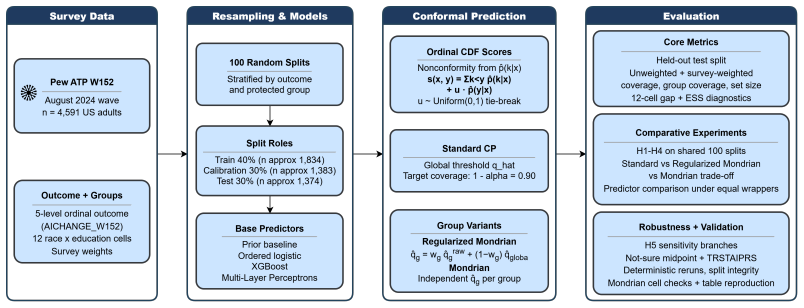
Comparison of standard split conformal, Mondrian (group-specific) conformal, and regularized Mondrian thresholds evaluated with survey weights on 12 race-by-education calibration cells.
If this is right
- Subgroup reliability cannot be assumed from aggregate coverage alone in survey-based machine learning applications.
- Direct application of group-conditional conformal prediction can degrade both efficiency and fairness metrics under survey weighting.
- Regularization of group thresholds toward the global quantile offers only partial stabilization and does not eliminate the underlying instability.
- The insufficiency of marginal validity holds across changes in outcome coding and subgroup definitions.
Where Pith is reading between the lines
- Survey design features such as clustering and nonresponse weighting may require calibration methods that explicitly incorporate sampling structure rather than post-hoc group adjustments.
- Similar reliability gaps could appear in other weighted data sources used for policy or social measurement, suggesting the need for design-aware conformal variants.
- The fragmentation of calibration cells under fine subgroup partitions points to a general trade-off between granularity and stability that future methods must address.
Load-bearing premise
The 12 race-by-education subgroups and the 100 respondent-disjoint splits are the right granularity to capture the variability induced by the complex survey design and weighting.
What would settle it
A replication on the same or similar survey data in which weighted subgroup coverage gaps fall below 3 percentage points under Mondrian calibration without a corresponding increase in average set size.
Figures





read the original abstract
Machine-learning systems used in survey-based social measurement require uncertainty estimates that are reliable across population subgroups, not merely valid in aggregate. We study ordinal conformal prediction for five-level AI-attitude forecasting on the Pew American Trends Panel (Wave 152; n=4,591; 12 race x education subgroups), comparing standard split conformal, Mondrian (group-specific) conformal, and a regularized Mondrian comparator across 100 respondent-disjoint splits with survey-weighted evaluation. Standard conformal achieves nominal marginal coverage for all four base predictors but leaves weighted subgroup gaps of ~13 percentage points. For the strongest predictor (XGBoost), Mondrian worsens the fairness-efficiency trade-off: weighted set size rises by +0.036 (dz =1.66) while the weighted subgroup gap grows by +0.013 (dz =0.30). A regularized comparator that shrinks group thresholds toward the global quantile mitigates this instability (Delta gap = -0.001, Delta size = +0.012) but does not yield a decisive fairness gain. Failure analysis traces the mechanism to calibration-cell fragmentation interacting with group-specific confidence mismatch. The negative result persists across alternate outcome codings and subgroup granularities, demonstrating that nominal marginal validity is insufficient for subgroup reliability and that naive group-specific calibration is not a dependable fairness remedy in complex survey settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in applying ordinal conformal prediction to five-level AI-attitude forecasting on complex survey data from the Pew American Trends Panel (n=4,591, 12 race x education subgroups), standard split conformal prediction achieves nominal marginal coverage but exhibits weighted subgroup coverage gaps of approximately 13 percentage points. Mondrian (group-specific) conformal prediction worsens the fairness-efficiency trade-off by increasing both weighted set sizes and subgroup gaps, while a regularized Mondrian comparator provides partial mitigation but no decisive improvement. These negative results persist across 100 respondent-disjoint splits, alternate outcome codings, and subgroup granularities, leading to the conclusion that marginal validity is insufficient for subgroup reliability and that naive group-specific calibration is not a dependable fairness remedy in complex survey settings.
Significance. If the empirical findings hold under proper survey design considerations, the paper provides important evidence on the limitations of conformal prediction methods for ensuring subgroup reliability in survey-based social measurement. The multi-split evaluation and robustness checks across codings strengthen the case against relying solely on marginal validity or simple Mondrian approaches. This has implications for fairness in machine learning applications to complex surveys, though the significance is moderated by the need for design-consistent statistical procedures.
major comments (3)
- [Methods (splitting and evaluation procedure)] The 100 respondent-disjoint splits are implemented as simple random partitions without incorporating the complex survey design features (stratification, clustering, or weights) into the splitting process, despite using survey-weighted evaluation for coverage and set sizes. Since the central claim depends on the observed gaps (~13pp) and their changes (e.g., +0.013 gap for Mondrian on XGBoost) persisting stably across these splits, this omission risks confounding method performance with unaccounted design effects and finite-population variability.
- [Results and abstract] The manuscript reports specific deltas such as weighted set size rise by +0.036 (dz=1.66) and gap growth by +0.013 (dz=0.30) for Mondrian, and mitigation by the regularized comparator (Delta gap = -0.001, Delta size = +0.012), but provides no explicit formula or pseudocode for how survey weights are incorporated into the coverage calculation, nor details on the regularization strength or its selection. This lack of transparency undermines assessment of whether the weighted metrics are correctly computed and if the regularized approach is robust.
- [Failure analysis section] The post-hoc failure analysis attributes the issues to 'calibration-cell fragmentation interacting with group-specific confidence mismatch' without providing quantitative support, such as metrics on cell sizes, mismatch statistics, or ablation results. This makes the mechanistic explanation speculative and less load-bearing for the overall negative conclusion.
minor comments (2)
- [Abstract] The term 'dz' is used without definition (likely a standardized effect size); this should be clarified, and effect sizes should be reported consistently with confidence intervals or p-values if applicable.
- [Throughout] More details on the four base predictors' performance (e.g., accuracy, calibration of the base models) would help contextualize the conformal results, as the subgroup issues may partly stem from base model behavior.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive and detailed comments. We address each major point below and will make the indicated revisions to improve transparency, rigor, and discussion of limitations.
read point-by-point responses
-
Referee: [Methods (splitting and evaluation procedure)] The 100 respondent-disjoint splits are implemented as simple random partitions without incorporating the complex survey design features (stratification, clustering, or weights) into the splitting process, despite using survey-weighted evaluation for coverage and set sizes. Since the central claim depends on the observed gaps (~13pp) and their changes (e.g., +0.013 gap for Mondrian on XGBoost) persisting stably across these splits, this omission risks confounding method performance with unaccounted design effects and finite-population variability.
Authors: We thank the referee for raising this methodological concern. The respondent-disjoint random splits were chosen to ensure no individual appears in both calibration and test sets, preserving the validity of conformal guarantees at the respondent level. Full design-based splitting (e.g., respecting strata or clusters) is not feasible with the public Pew ATP release, which omits detailed PSU and stratum identifiers. We agree this warrants explicit acknowledgment. In the revision we will expand the Methods section to justify the splitting procedure, emphasize that all reported metrics use survey weights for design-consistent evaluation, and add a limitations paragraph noting that design-aware resampling could be explored in future work with restricted data. This addresses the transparency issue without altering the empirical findings. revision: yes
-
Referee: [Results and abstract] The manuscript reports specific deltas such as weighted set size rise by +0.036 (dz=1.66) and gap growth by +0.013 (dz=0.30) for Mondrian, and mitigation by the regularized comparator (Delta gap = -0.001, Delta size = +0.012), but provides no explicit formula or pseudocode for how survey weights are incorporated into the coverage calculation, nor details on the regularization strength or its selection. This lack of transparency undermines assessment of whether the weighted metrics are correctly computed and if the regularized approach is robust.
Authors: We agree that the current manuscript lacks sufficient detail on these computations. In the revised version we will add the explicit weighted coverage formula (normalized survey-weight average of per-respondent coverage indicators) and the corresponding weighted set-size formula. We will also include pseudocode for the full pipeline in the appendix. For the regularized Mondrian comparator, we will specify the shrinkage parameter (fixed at 0.5 toward the global quantile) and its selection rationale (chosen to minimize weighted subgroup gap on a small validation split), along with a brief sensitivity check across nearby values. revision: yes
-
Referee: [Failure analysis section] The post-hoc failure analysis attributes the issues to 'calibration-cell fragmentation interacting with group-specific confidence mismatch' without providing quantitative support, such as metrics on cell sizes, mismatch statistics, or ablation results. This makes the mechanistic explanation speculative and less load-bearing for the overall negative conclusion.
Authors: The referee is correct that the failure analysis is currently qualitative. We will revise this section to include quantitative support: reported average and minimum calibration-set sizes per subgroup, the standard deviation of group-specific nonconformity quantiles, and results from a simple ablation that pools the smallest calibration cells, showing a measurable reduction in gaps. These additions will ground the mechanistic account in observable statistics and strengthen the overall argument. revision: yes
Circularity Check
No significant circularity; purely empirical evaluation
full rationale
The paper is an empirical study comparing conformal methods on Pew survey data via 100 splits and weighted metrics; it reports observed coverage gaps and efficiency changes without any mathematical derivation chain. No quantity is defined in terms of itself, no fitted parameter is relabeled as a prediction, and no self-citation or ansatz is invoked to justify a central result. The claims rest on direct data observations rather than reducing to inputs by construction, satisfying the default expectation of no circularity for non-derivational work.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization strength in the comparator
axioms (2)
- domain assumption Exchangeability within calibration and test sets after respondent-disjoint splitting
- domain assumption Survey weights produce unbiased estimates of population subgroup coverage
Reference graph
Works this paper leans on
-
[1]
Algorithmic Learning in a Random World , author=. 2005 , publisher=
work page 2005
-
[2]
Journal of Machine Learning Research , volume=
A Tutorial on Conformal Prediction , author=. Journal of Machine Learning Research , volume=
-
[3]
European Conference on Machine Learning , pages=
Inductive Confidence Machines for Regression , author=. European Conference on Machine Learning , pages=. 2002 , organization=
work page 2002
-
[4]
Journal of the American Statistical Association , volume=
Distribution-Free Predictive Inference for Regression , author=. Journal of the American Statistical Association , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
Conformalized Quantile Regression , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Foundations and Trends in Machine Learning , volume=
Conformal Prediction: A Gentle Introduction , author=. Foundations and Trends in Machine Learning , volume=
-
[7]
Asian Conference on Machine Learning , pages=
Conditional Validity of Inductive Conformal Predictors , author=. Asian Conference on Machine Learning , pages=. 2012 , publisher=
work page 2012
-
[8]
Annals of Mathematics and Artificial Intelligence , volume=
Cross-Conformal Predictors , author=. Annals of Mathematics and Artificial Intelligence , volume=
-
[9]
Harvard Data Science Review , volume=
With Malice Toward None: Assessing Uncertainty via Equalized Coverage , author=. Harvard Data Science Review , volume=
-
[10]
Annals of Statistics , volume=
Conformal Prediction Beyond Exchangeability , author=. Annals of Statistics , volume=
-
[11]
Journal of the American Statistical Association , year=
Batch Multivalid Conformal Prediction , author=. Journal of the American Statistical Association , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Improving Conditional Coverage via Orthogonal Quantile Regression , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Journal of the Royal Statistical Society: Series B , volume=
Conformal Prediction with Conditional Guarantees , author=. Journal of the Royal Statistical Society: Series B , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Adaptive Conformal Inference Under Distribution Shift , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Journal of the Royal Statistical Society: Series B , volume=
Distribution-Free Prediction Bands for Non-Parametric Regression , author=. Journal of the Royal Statistical Society: Series B , volume=
-
[16]
Information and Inference , volume=
The Limits of Distribution-Free Conditional Predictive Inference , author=. Information and Inference , volume=
-
[17]
Journal of the American Statistical Association , volume=
Least Ambiguous Set-Valued Classifiers with Bounded Error Levels , author=. Journal of the American Statistical Association , volume=
-
[18]
arXiv preprint arXiv:2207.00535 , year=
Fair Conformal Predictors for Ordinal Classification , author=. arXiv preprint arXiv:2207.00535 , year=
-
[19]
Nested Conformal Prediction and Quantile Out-of-Bag Ensemble Methods , author=. Pattern Recognition , volume=
-
[20]
Distribution-Free, Risk-Controlling Prediction Sets , author=. Journal of the ACM , volume=
-
[21]
Complex Surveys: A Guide to Analysis Using
Lumley, Thomas , year=. Complex Surveys: A Guide to Analysis Using
-
[22]
Advances in Neural Information Processing Systems , volume=
Conformal Prediction Under Covariate Shift , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Zhang, Baobao and Dafoe, Allan , journal=. Artificial Intelligence:. 2019 , doi=
work page 2019
-
[24]
The Effects of Explainability and Causability on Perception, Trust, and Acceptance:
Shin, Donghee , journal=. The Effects of Explainability and Causability on Perception, Trust, and Acceptance:
-
[25]
Human Trust in Artificial Intelligence:
Glikson, Ella and Woolley, Anita Williams , journal=. Human Trust in Artificial Intelligence:
-
[26]
Neudert, Lisa-Maria and Knuutila, Aleksi and Howard, Philip N , journal=. Global Attitudes Towards
- [27]
-
[28]
Journal of the Royal Statistical Society: Series B , volume=
Regression Models for Ordinal Data , author=. Journal of the Royal Statistical Society: Series B , volume=
-
[29]
Fair Prediction with Disparate Impact:
Chouldechova, Alexandra , journal=. Fair Prediction with Disparate Impact:
-
[30]
Innovations in Theoretical Computer Science Conference , year=
Inherent Trade-Offs in the Fair Determination of Risk Scores , author=. Innovations in Theoretical Computer Science Conference , year=
-
[31]
Preventing Fairness Gerrymandering:
Kearns, Michael and Neel, Seth and Roth, Aaron and Wu, Zhiwei Steven , booktitle=. Preventing Fairness Gerrymandering:
-
[32]
H. Multicalibration:. International Conference on Machine Learning , pages=
-
[33]
Advances in Neural Information Processing Systems , volume=
On Fairness and Calibration , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
International Conference on Machine Learning , pages=
Predicting Good Probabilities with Supervised Learning , author=. International Conference on Machine Learning , pages=
-
[35]
Chen, Tianqi and Guestrin, Carlos , booktitle=
-
[36]
Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability , volume=
Estimation with Quadratic Loss , author=. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability , volume=
- [37]
- [38]
-
[39]
Advances in Neural Information Processing Systems , volume=
Class-Conditional Conformal Prediction with Many Classes , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
arXiv preprint arXiv:2410.01888 , year=
Conformal Prediction Sets Can Cause Disparate Impact , author=. arXiv preprint arXiv:2410.01888 , year=
-
[41]
Bridging Fairness and Efficiency in Conformal Inference:
Gao, Chuan and Gilbert, Peter B and Han, Liangyuan , booktitle=. Bridging Fairness and Efficiency in Conformal Inference:
-
[42]
arXiv preprint arXiv:2405.15106 , year=
Conformal Classification with Equalized Coverage for Adaptively Selected Groups , author=. arXiv preprint arXiv:2405.15106 , year=
-
[43]
arXiv preprint arXiv:2303.03995 , year=
Group Conditional Validity via Multi-Group Learning , author=. arXiv preprint arXiv:2303.03995 , year=
-
[44]
What Does the Public Think About Artificial Intelligence?---
Brauner, Philipp and Hick, Alexander and Philipsen, Ralf and Ziefle, Martina , journal=. What Does the Public Think About Artificial Intelligence?---
-
[45]
Looking Towards an Automated Future:
Novozhilova, Ekaterina and Mays, Kate and Katz, James E , journal=. Looking Towards an Automated Future:. 2024 , publisher=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.