Recognition: unknown
DataDignity: Training Data Attribution for Large Language Models
Pith reviewed 2026-05-08 11:48 UTC · model grok-4.3
The pith
A supervised contrastive ranker identifies which documents support an LLM response more reliably than retrieval baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a supervised contrastive provenance ranker, ScoringModel, maps response and document features into a shared space and is trained with InfoNCE using in-batch, retrieval-mined, and anti-document negatives; this produces substantially better ranking of documents that truly support an LLM response than either pure retrieval baselines or a training-free activation-steering fusion method called SteerFuse. On the FakeWiki benchmark the model improves mean Recall@10 from 35.0 to 52.2 across nine LLMs and five conditions, wins 41 of 45 cells, and delivers an average 15.7-point gain on jailbreak-inspired transformed queries. The work concludes that robust training-data-attrib
What carries the argument
The ScoringModel, a supervised contrastive ranker that projects response and document features into one embedding space and is optimized with InfoNCE loss on mixed negatives.
If this is right
- ScoringModel wins 41 of 45 model-by-condition cells without any inference-time fusion.
- On jailbreak-inspired transformed queries the model improves Recall@10 by 15.7 points on average over the strongest baseline.
- SteerFuse, which requires no supervised training, is usually second-best and shows that activation-space signals can complement text retrieval.
- Effective attribution demands benchmarks that separate true answer support from topical or lexical resemblance.
- The gains hold across nine different open-weight instruction-tuned LLMs.
Where Pith is reading between the lines
- If the gains transfer to production training sets, provenance auditing could become a standard post-training check for deployed models.
- The same contrastive embedding approach might be adapted to attribute other model outputs such as code or structured data.
- Real-world use would require scaling the negative-mining strategy to corpora orders of magnitude larger than FakeWiki.
- The benchmark design suggests a general template for testing attribution methods on any domain where lexical shortcuts must be blocked.
Load-bearing premise
The synthetic FakeWiki articles and their jailbreak-style transformations are representative of the provenance challenges that appear in real training corpora.
What would settle it
Running the same ScoringModel on a real LLM training corpus with known source documents and measuring whether the reported recall gains over retrieval baselines still appear would directly test the central claim.
Figures




read the original abstract
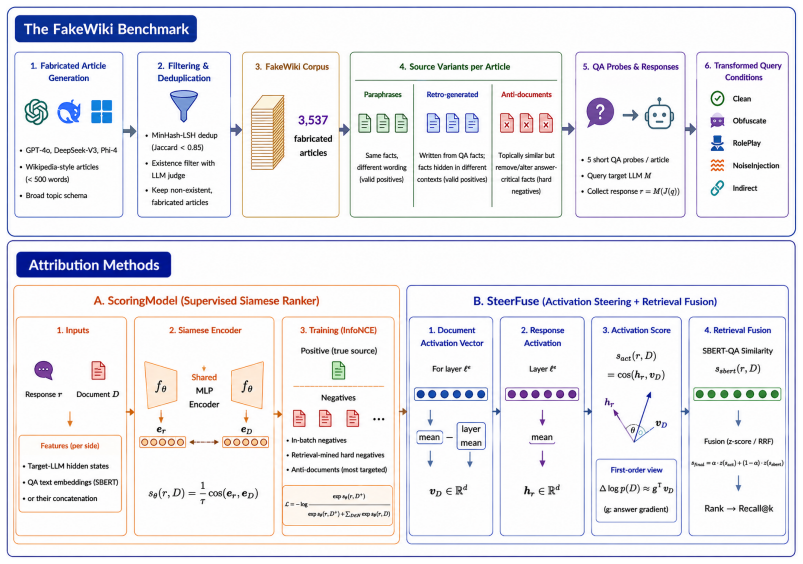
Auditing language-model outputs often requires more than judging correctness: an auditor may need to identify which source document most likely supports the knowledge expressed in a response. We study this as pinpoint provenance: given a prompt, a target-model response, and a candidate corpus, rank the documents that best support the response. We introduce FakeWiki, a controlled benchmark of 3,537 fabricated Wikipedia-style articles designed to preserve ground-truth provenance while weakening lexical shortcuts. FakeWiki includes QA probes, source-preserving paraphrases, retro-generated variants, hard anti-documents that remain topically similar while removing answer-critical facts, and five query conditions: clean prompting plus four jailbreak-inspired transformations. We evaluate seven retrieval baselines, a training-free activation-steering retrieval-fusion method, SteerFuse, and a supervised contrastive provenance ranker, ScoringModel. ScoringModel maps response and document features into a shared space and is trained with InfoNCE using in-batch, retrieval-mined, and anti-document negatives. Across nine open-weight instruction-tuned LLMs and five query conditions, ScoringModel improves mean Recall@10 from 35.0 for the strongest retrieval baseline to 52.2, without inference-time fusion, and wins 41/45 model-by-condition cells. SteerFuse is usually second-best despite requiring no supervised training, showing that activation-space evidence can efficiently complement text retrieval. On jailbreak-inspired transformed queries, ScoringModel improves Recall@10 by 15.7 points on average over the best baseline. Overall, our work shows that robust training data attribution requires evaluation settings that separate true answer support from topical or lexical resemblance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces pinpoint provenance: ranking documents from a candidate corpus that best support a given LLM response to a prompt. It presents FakeWiki, a synthetic benchmark of 3,537 fabricated Wikipedia-style articles equipped with QA probes, source-preserving paraphrases, retro-generated variants, hard anti-documents (topically similar but lacking answer-critical facts), and five query conditions (clean plus four jailbreak-inspired transformations). Seven retrieval baselines, the training-free activation-steering fusion method SteerFuse, and the supervised contrastive ScoringModel (trained with InfoNCE on in-batch, retrieval-mined, and anti-document negatives) are evaluated across nine open-weight instruction-tuned LLMs. The central empirical claim is that ScoringModel raises mean Recall@10 from 35.0 (strongest baseline) to 52.2, wins 41/45 model-by-condition cells, and improves by 15.7 points on transformed queries, without requiring inference-time fusion.
Significance. If the results hold, the work is significant because it supplies a controlled benchmark that deliberately weakens lexical and topical shortcuts while preserving ground-truth provenance labels, enabling clearer isolation of true support signals. The demonstration that a supervised contrastive ranker can outperform both standard retrieval and a training-free activation-space method (SteerFuse) on this benchmark, with particularly large gains under jailbreak-style query shifts, suggests a practical path toward more reliable training-data attribution for LLM auditing. The benchmark itself, together with the multi-condition evaluation protocol, provides a reusable testbed that future provenance methods can be measured against.
major comments (3)
- [Experiments / Results tables] Experiments / Results (tables reporting Recall@10): the headline improvements (mean 35.0 → 52.2, 41/45 wins, +15.7 on transformed queries) are stated without error bars, standard deviations across the nine models, or any statistical significance tests. Because the central claim rests on the consistency and magnitude of these gains, the absence of variance estimates or hypothesis testing makes it impossible to judge whether the reported superiority is robust or could be explained by benchmark-specific variance.
- [FakeWiki benchmark construction] FakeWiki benchmark construction (section describing anti-documents and negatives): anti-documents are generated by hand-removing answer-critical facts from the same fabricated articles used for positives, and ScoringModel is trained with InfoNCE using in-batch, retrieval-mined, and these anti-document negatives drawn exclusively from the synthetic distribution. This design risks the model learning to detect the artificial presence/absence of specific facts or the engineered structure of the anti-documents rather than general provenance cues that would appear in noisy, real-scale training corpora; no ablation isolating this possibility is reported.
- [Evaluation protocol / Abstract] Evaluation protocol (all reported results): every quantitative claim is confined to the 3,537-article synthetic FakeWiki corpus. No transfer experiments, real-corpus proxies, or cross-benchmark validation are provided, yet the abstract concludes that the work shows “robust training data attribution requires evaluation settings that separate true answer support from topical or lexical resemblance.” The generalization step from synthetic gains to this broader claim is therefore load-bearing but unsupported.
minor comments (2)
- [Abstract / Experiments] The nine LLMs used are referred to only as “open-weight instruction-tuned LLMs” in the abstract and results summary; an explicit list or table with model names, sizes, and training details would improve reproducibility.
- [Methods] Notation for the contrastive loss (InfoNCE temperature or margin) is mentioned in passing but not given an equation number or explicit hyper-parameter table; readers cannot reproduce the exact training objective without additional details.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback, which highlights important aspects of our experimental reporting, benchmark design, and the scope of our claims. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Experiments / Results tables: the headline improvements (mean 35.0 → 52.2, 41/45 wins, +15.7 on transformed queries) are stated without error bars, standard deviations across the nine models, or any statistical significance tests. Because the central claim rests on the consistency and magnitude of these gains, the absence of variance estimates or hypothesis testing makes it impossible to judge whether the reported superiority is robust or could be explained by benchmark-specific variance.
Authors: We agree that variance estimates and significance testing would improve the robustness assessment of our results. In the revised manuscript, we will report standard deviations of Recall@10 across the nine LLMs for all methods and conditions, add error bars to tables and figures, and include paired t-tests (with p-values) comparing ScoringModel to the strongest baseline, including for the +15.7 point gain on transformed queries. revision: yes
-
Referee: FakeWiki benchmark construction (section describing anti-documents and negatives): anti-documents are generated by hand-removing answer-critical facts from the same fabricated articles used for positives, and ScoringModel is trained with InfoNCE using in-batch, retrieval-mined, and these anti-document negatives drawn exclusively from the synthetic distribution. This design risks the model learning to detect the artificial presence/absence of specific facts or the engineered structure of the anti-documents rather than general provenance cues that would appear in noisy, real-scale training corpora; no ablation isolating this possibility is reported.
Authors: We acknowledge the risk that anti-documents could introduce synthetic artifacts. However, the benchmark's inclusion of paraphrases, retro-generated variants, and jailbreak transformations, combined with consistent gains across conditions, indicates the model learns broader support signals. In revision, we will add an ablation training ScoringModel without anti-document negatives to quantify their contribution and expand the limitations discussion to address synthetic data concerns and the need for real-corpus validation. revision: partial
-
Referee: Evaluation protocol (all reported results): every quantitative claim is confined to the 3,537-article synthetic FakeWiki corpus. No transfer experiments, real-corpus proxies, or cross-benchmark validation are provided, yet the abstract concludes that the work shows “robust training data attribution requires evaluation settings that separate true answer support from topical or lexical resemblance.” The generalization step from synthetic gains to this broader claim is therefore load-bearing but unsupported.
Authors: The synthetic design of FakeWiki is intentional to provide controllable ground-truth labels unavailable in real corpora, enabling isolation of true support from topical or lexical cues. The abstract statement underscores the value of such evaluation settings rather than claiming direct transfer to real data. We will revise the abstract and conclusion to clarify this scope, explicitly note the controlled synthetic nature of results, and add discussion on real-data evaluation challenges and future directions. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs the FakeWiki benchmark independently, defines ScoringModel as a supervised contrastive ranker trained with standard InfoNCE on in-batch/retrieval/anti-document negatives, and reports Recall@10 as an empirical metric on the benchmark (with baselines evaluated identically). No equations appear that reduce the reported performance numbers to a fitted quantity defined by the same data, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming reduces the central claim to its inputs by construction. The derivation is self-contained standard ML evaluation on a held-out test distribution from the authors' benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- InfoNCE temperature or margin
axioms (1)
- domain assumption FakeWiki preserves ground-truth provenance while weakening lexical shortcuts
Reference graph
Works this paper leans on
-
[1]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review arXiv
-
[2]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review arXiv
-
[3]
Phi-4 technical report , author=. arXiv preprint arXiv:2412.08905 , year=
work page internal anchor Pith review arXiv
-
[4]
arXiv preprint arXiv:2410.16454 , year=
Catastrophic failure of llm unlearning via quantization , author=. arXiv preprint arXiv:2410.16454 , year=
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Selection of LLM Fine-Tuning Data Based on Orthogonal Rules , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[6]
arXiv preprint arXiv:2505.11413 , year=
Cares: Comprehensive evaluation of safety and adversarial robustness in medical llms , author=. arXiv preprint arXiv:2505.11413 , year=
-
[7]
When thinking fails: The pitfalls of reasoning for instruction-following in llms, 2025
When thinking fails: The pitfalls of reasoning for instruction-following in llms , author=. arXiv preprint arXiv:2505.11423 , year=
-
[8]
International Conference on Machine Learning , pages=
TRAK: Attributing Model Behavior at Scale , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[9]
2024 , eprint=
TRACE: TRansformer-based Attribution using Contrastive Embeddings in LLMs , author=. 2024 , eprint=
2024
-
[10]
arXiv preprint arXiv:2504.07096 , year=
OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens , author=. arXiv preprint arXiv:2504.07096 , year=
-
[11]
arXiv preprint arXiv:2404.01019 , year=
Source-aware training enables knowledge attribution in language models , author=. arXiv preprint arXiv:2404.01019 , year=
-
[12]
arXiv preprint arXiv:2012.13255 , year=
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. arXiv preprint arXiv:2012.13255 , year=
-
[13]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
On the feasibility of in-context probing for data attribution , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[14]
arXiv preprint arXiv:2408.11852 , year=
Fast training dataset attribution via in-context learning , author=. arXiv preprint arXiv:2408.11852 , year=
-
[15]
arXiv preprint arXiv:2310.00902 , year=
Datainf: Efficiently estimating data influence in lora-tuned llms and diffusion models , author=. arXiv preprint arXiv:2310.00902 , year=
-
[16]
arXiv preprint arXiv:2205.11482 , year=
Towards tracing factual knowledge in language models back to the training data , author=. arXiv preprint arXiv:2205.11482 , year=
-
[17]
Nist Special Publication Sp , volume=
Okapi at TREC-3 , author=. Nist Special Publication Sp , volume=. 1995 , publisher=
1995
-
[18]
International Conference on Artificial Intelligence and Statistics , pages=
Relatif: Identifying explanatory training samples via relative influence , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[19]
Advances in Neural Information Processing Systems , volume=
Estimating training data influence by tracing gradient descent , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2110.03212 , year=
Influence tuning: Demoting spurious correlations via instance attribution and instance-driven updates , author=. arXiv preprint arXiv:2110.03212 , year=
-
[21]
arXiv preprint arXiv:1906.02361 , year=
Explain yourself! leveraging language models for commonsense reasoning , author=. arXiv preprint arXiv:1906.02361 , year=
-
[22]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review arXiv
-
[23]
2023 , eprint=
Attention Sorting Combats Recency Bias In Long Context Language Models , author=. 2023 , eprint=
2023
-
[24]
Proceedings of Compression and Complexity of Sequences , pages=
On the Resemblance and Containment of Documents , author=. Proceedings of Compression and Complexity of Sequences , pages=. 1997 , organization=
1997
-
[25]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages=
2019
-
[26]
Transactions on Machine Learning Research , year=
Unsupervised Dense Information Retrieval with Contrastive Learning , author=. Transactions on Machine Learning Research , year=
-
[27]
Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
C-pack: Packed resources for general chinese embeddings , author=. Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[28]
arXiv preprint arXiv:2205.05124 , year=
Extracting Latent Steering Vectors from Pretrained Language Models , author=. arXiv preprint arXiv:2205.05124 , year=
-
[29]
Steering Language Models With Activation Engineering
Steering Language Models With Activation Engineering , author=. arXiv preprint arXiv:2308.10248 , year=
work page internal anchor Pith review arXiv
-
[30]
Steering Llama 2 via Contrastive Activation Addition
Steering Llama 2 via Contrastive Activation Addition , author=. arXiv preprint arXiv:2312.06681 , year=
work page internal anchor Pith review arXiv
-
[31]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation Engineering: A Top-Down Approach to AI Transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review arXiv
-
[32]
Advances in Neural Information Processing Systems , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Advances in Neural Information Processing Systems , year=
-
[33]
International Conference on Learning Representations , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.