Recognition: unknown
Ratio-based Loss Functions
Pith reviewed 2026-05-08 05:29 UTC · model grok-4.3
The pith
Ratio-based loss functions depend on the ratio of target to prediction and satisfy general properties of continuity, convexity, and differentiability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ratio-based loss functions are losses that take the ratio y_i / f(x_i) as their argument, in contrast to the more common margin-based or distance-based losses. The paper provides a systematic survey of their general properties, including continuity, Lipschitz continuity, convexity, and differentiability, and proposes a small number of new ratio-based losses. These properties are examined because they are central to the behavior of optimization routines in machine learning, independent of any specific choice of hypothesis space or probability measure.
What carries the argument
Ratio-based loss functions, which are scalar functions of the ratio between the target value and the model's prediction, designed to capture multiplicative rather than additive error structures.
If this is right
- Optimization algorithms can safely use gradient-based methods on any convex and differentiable ratio-based loss without additional safeguards.
- Researchers can select or design losses according to whether they need bounded Lipschitz constants for stability arguments.
- Newly proposed ratio-based losses inherit the same general properties as the surveyed ones and can be substituted into existing frameworks.
- Theoretical guarantees developed for one ratio-based loss may transfer to others that share the same continuity or convexity class.
- The separation of ratio-based losses from distance-based losses clarifies when relative-error modeling is mathematically well-behaved.
Where Pith is reading between the lines
- These losses could be especially useful in domains where measurement noise scales with signal magnitude, such as count data or positive quantities.
- Hybrid losses that blend a ratio term with a small distance term might combine robustness to relative errors with protection near zero predictions.
- The listed properties could guide the construction of surrogate losses that approximate non-convex ratio-based objectives while preserving convexity.
- Extension of the same ratio construction to classification margins would require careful handling of sign changes and zero crossings.
Load-bearing premise
The assumption that examining continuity, convexity, and differentiability in isolation will be sufficient to support later proofs of consistency or stability for algorithms that use these losses.
What would settle it
A concrete ratio-based loss that is discontinuous or non-convex at the points where predictions equal zero yet still produces stable empirical risk minimization in practice would weaken the rationale for prioritizing those properties.
Figures











read the original abstract
Algorithms in machine learning and AI do critically depend on at least three key components: (i) the risk function, which is the expectation of the loss function, (ii) the function space, which is often called the hypothesis space, and (iii) the set of probability measures, which are allowed for the specified algorithm. This paper gives a survey of a certain class of loss functions, which we call ratio-based. In supervised learning, margin-based loss functions for classification tasks depending on the product of the output values $y_i$ and the predictions $f(x_i)$ as well as distance-based loss functions depending on the difference of $y_i$ and $f(x_i)$ for regression are common. Distance-based loss functions are in particular useful, if an additive model assumption seems plausible, i.e. the common signal plus noise assumption. However, in the literature, several loss functions proposed for regression purposes have a multiplicative error structure in mind and pay attention to relative errors, i.e. to the ratio of $y_i$ and $f(x_i)$. In this survey article, we systematically investigate such ratio-based loss functions and propose a few new losses, which may be interesting for future research. We concentrate on investigating general properties of ratio-based loss functions like continuity, Lipschitz-continuity, convexity, and differentiability, because these properties play a central role in most machine learning algorithms. Therefore, we do not focus on some specific machine learning algorithm to derive universal consistency, learning rates, or stability results. Instead, we want to enable future research in this direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript surveys ratio-based loss functions (those depending on the ratio y/f(x)) for supervised learning, contrasting them with margin-based and distance-based losses. It reviews existing examples motivated by multiplicative error structures, proposes a few new ratio-based losses, and systematically derives their analytic properties including continuity, Lipschitz-continuity, convexity, and differentiability. The authors explicitly limit scope to these general properties and state that they do not derive consistency, learning rates, or stability results for any concrete algorithm, instead positioning the catalog as a foundation for future work.
Significance. If the property derivations hold, the paper supplies a useful reference catalog for loss functions suited to relative-error regression settings. Credit is given for the systematic treatment of standard properties (continuity, convexity, differentiability) that are load-bearing for optimization and for the constructive proposal of new losses. This modest but focused survey can facilitate subsequent research on algorithmic guarantees without claiming those guarantees itself.
minor comments (2)
- Abstract: the phrase 'propose a few new losses' is not accompanied by even a brief indication of their functional forms; adding one sentence would improve reader orientation without lengthening the abstract unduly.
- The manuscript should ensure uniform notation for the ratio argument (e.g., consistently using r = y/f(x) or an equivalent) when stating the new losses and their properties.
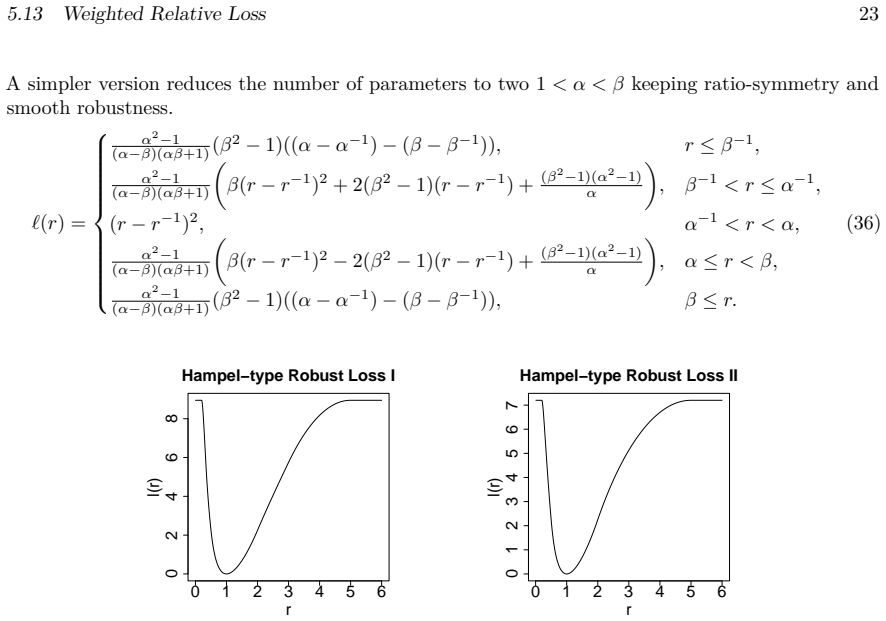
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of our survey on ratio-based loss functions. The recommendation for minor revision is noted, but no specific major comments or requested changes were provided in the report. We therefore have no points to address point-by-point and no revisions to incorporate at this stage.
Circularity Check
No significant circularity: survey of standard properties
full rationale
The paper is a survey that catalogs existing and proposes new ratio-based loss functions (depending on y/f(x)) and derives their basic analytic properties—continuity, Lipschitz continuity, convexity, differentiability—directly from standard real-analysis definitions. No load-bearing step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or ansatz smuggled from prior author work. The central premise explicitly disclaims deriving consistency, learning rates, or stability for any algorithm and instead positions the catalog as enabling future work. All derivations are therefore self-contained against external mathematical benchmarks and exhibit no self-definitional, fitted-input, or renaming circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard definitions of continuity, Lipschitz continuity, convexity, and differentiability for real-valued functions of one variable.
Reference graph
Works this paper leans on
-
[1]
LINEXLossFunctionswithApplicationstoDetermining the Optimum Process Parameters
[CH07] Yen-ChangChangandWen-LiangHung:“LINEXLossFunctionswithApplicationstoDetermining the Optimum Process Parameters”. In:Quality & Quantity41 (2007), pp. 291–301. [Che+10] Kani Chen, Shaojun Guo, Yuanyuan Lin, and Zhiliang Ying: “Least Absolute Relative Error Estimation”. In:Journal of the American Statistical Association105.491 (2010), pp. 1104–1112. [...
2007
-
[2]
arXiv:2301.05579 [cs.LG]. [Cla+98] Francis H. Clarke, Yuri S. Ledyaev, Ronald J. Stern, and Peter R. Wolenski:Nonsmooth Analysis and Control Theory. New York, Berlin, Heidelberg: Springer,
-
[3]
Elastic-net regularization in learning theory
[DDR09] Christine De Mol, Ernestor De Vito, and Lorenzo Rosasco: “Elastic-net regularization in learning theory”. In:Journal of Complexity25 (2009), pp. 201–230. [Dud02] Richard M. Dudley:Real Analysis and Probability. 2nd ed. Cambridge: Cambridge University Press,
2009
-
[4]
Generalized robust loss functions for machine learning
[Fu+24] Saiji Fu, Xiaoxiao Wang, Jingjing Tang, Shulin Lan, and Yingjie Tian: “Generalized robust loss functions for machine learning”. In:Neural Networks171 (2024), pp. 200–214. [Ham+86] Frank R. Hampel, Elvezio M. Ronchetti, Peter J. Rousseeuw, and Werner A. Stahel:Robust Statistics: The Approach Based on Influence Functions. Wiley series in probability...
2024
-
[5]
Robust Kernel Density Estimation
arXiv:2211.02989 [cs.LG]. [KS12] JooSeuk Kim and Clayton D. Scott: “Robust Kernel Density Estimation”. In:Journal of Machine Learning Research13 (2012), pp. 2529–2565. [Koe05] Roger Koenker:Quantile Regression. Cambridge: Cambridge University Press,
-
[6]
Regression quantiles
[KB78] Roger W. Koenker and Gilbert W. Bassett: “Regression quantiles”. In:Econometrica46 (1978), pp. 33–50. [Kön04] Konrad Königsberger:Analysis
1978
-
[7]
A Survey of Loss Functions in Deep Learning
[LLL25] Caiyi Li, Kaishuai Liu, and Shuai Liu: “A Survey of Loss Functions in Deep Learning”. In: Mathematics13.15 (2025). [LS17] Eckhard Limpert and Werner A. Stahel: “The log-normal distribution”. In:Significance14.1 (2017), pp. 8–9. [LSA01] Eckhard Limpert, Werner A. Stahel, and Markus Abbt: “Log-normal Distributions across the Sciences: Keys and Clues...
2025
-
[8]
L0-regularized high-dimensional sparse multiplicative models
[MYX25] Hao Ming, Hu Yang, and Xiaochao Xia: “L0-regularized high-dimensional sparse multiplicative models”. In:Statistical Theory and Related Fields9.1 (2025), pp. 59–83. [Roc97] Ralph T. Rockafellar:Convex Analysis. Princeton, Chichester: Princeton University Press,
2025
-
[9]
Nonparametric Sparsity and Regularization
[Ros+13] Lorenzo Rosasco, Silvia Villa, Sofia Mosci, Matteo Santoro, and Alessandro Verri: “Nonparametric Sparsity and Regularization”. In:Journal of Machine Learning Research14.52 (2013), pp. 1665–
2013
-
[10]
A tutorial on support vector regression
A PROOFS 32 [SS04] Alex J. Smola and Bernhard Schölkopf: “A tutorial on support vector regression”. In:Statistics and Computing14 (2004), pp. 199–222. [Ste07] Ingo Steinwart: “How to Compare Different Loss Functions and Their Risks”. In:Constructive Approximation26 (2007), pp. 225–287. [SC08] Ingo Steinwart and Andreas Christmann:Support Vector Machines. ...
2004
-
[11]
Estimating conditional quantiles with the help of the pinball loss
[SC11] Ingo Steinwart and Andreas Christmann: “Estimating conditional quantiles with the help of the pinball loss”. In:Bernoulli17.1 (2011), pp. 211–225. [Tan+21] Jingjing Tang, Jiahui Li, Weiqi Xu, Yingjie Tian, Xuchan Ju, and Jie Zhang: “Robust cost- sensitive kernel method with Blinex loss and its applications in credit risk evaluation”. In:Neural Netw...
2011
-
[12]
A penalized least product relative error loss function based on wavelet decomposition for non-parametric multiplicative additive models
[Yan+23] Fan Yang, Zhanyang Li, Yushan Xue, and Yuehan Yang: “A penalized least product relative error loss function based on wavelet decomposition for non-parametric multiplicative additive models”. In:Journal of Computational and Applied Mathematics432 (2023), p. 115299. [Ye07] Jianming Ye: “Price Models and the Value Relevance of Accounting Information...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.