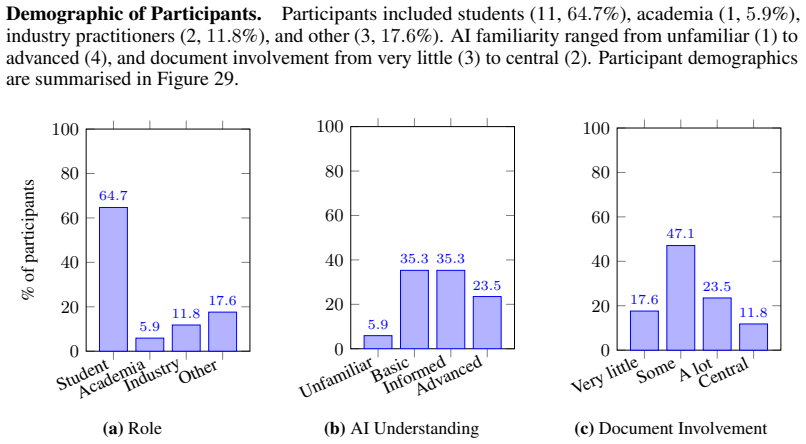
Towards Self-Explainable Document Visual Question Answering with Chain-of-Explanation Predictions
Pith reviewed 2026-05-08 14:05 UTC · model grok-4.3
The pith
CoExVQA forces DocVQA models to localize answer regions before decoding to create self-explainable predictions with improved accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
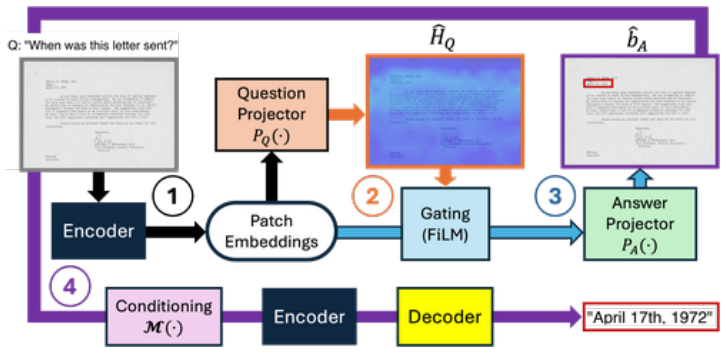
CoExVQA implements a grounded reasoning process by first identifying question-relevant evidence, then explicitly localizing the answer region, and finally decoding the answer exclusively from the grounded region. This chain-of-explanation design enables direct inspection and verification of the reasoning process across modalities, achieving state-of-the-art explainable DocVQA performance on PFL-DocVQA with a 12% improvement in ANLS over current explainable baselines.
What carries the argument
The chain-of-explanation design, which sequences evidence identification, answer localization, and grounded answer decoding to enforce transparency.
If this is right
- Predictions can be verified by checking the identified evidence and localized region against the question.
- Accuracy improves because decoding is restricted to relevant visual evidence rather than the entire page.
- The framework provides transparent and verifiable predictions suitable for applications requiring accountability.
- It disentangles evidence identification from answer generation, reducing black-box behavior in vision-language models.
Where Pith is reading between the lines
- This method might generalize to other multimodal tasks where grounding is important, such as visual question answering on images or videos.
- By constraining the model to visual evidence, it could help mitigate issues like hallucination in language model outputs.
- Testing the approach on additional DocVQA datasets would help establish its robustness beyond PFL-DocVQA.
Load-bearing premise
That requiring the model to localize the answer region before decoding will increase both accuracy and explainability without causing loss of necessary context or errors from incorrect localizations.
What would settle it
A direct counterexample would be if experiments on PFL-DocVQA showed that the chain-of-explanation model performs worse than or equal to non-grounded baselines in ANLS score, or if human evaluators find the localized regions do not match the actual answer locations used by the model.
Figures
























read the original abstract
Document Visual Question Answering (DocVQA) requires vision-language models to reason not only about what information in a document is relevant to a question, but also where the answer is grounded on the page. Existing DocVQA models entangle question-relevant evidence and answer localization and operate largely as black boxes, offering limited means to verify how predictions depend on visual evidence. We propose CoExVQA, a self-explainable DocVQA framework with a grounded reasoning process through a chain-of-explanation design. CoExVQA first identifies question-relevant evidence, then explicitly localizes the answer region, and finally decodes the answer exclusively from the grounded region. Prediction via CoExVQA's chain-of-explanation enables direct inspection and verification of the reasoning process across modalities. Empirical results show that restricting decoding to grounded evidence achieves SotA explainable DocVQA performance on PFL-DocVQA, improving ANLS by 12% over the current explainable baselines while providing transparent and verifiable predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoExVQA, a self-explainable DocVQA framework employing a chain-of-explanation design: first identifying question-relevant evidence, then explicitly localizing the answer region on the page, and finally decoding the answer exclusively from that grounded region. The central empirical claim is that this restriction to grounded evidence yields state-of-the-art performance among explainable DocVQA models on the PFL-DocVQA dataset, delivering a 12% ANLS improvement over current explainable baselines while enabling direct inspection and verification of the multimodal reasoning process.
Significance. If the empirical results and the localization-explainability link are substantiated, the work would meaningfully advance explainable document understanding by disentangling evidence localization from answer generation and making the reasoning chain inspectable. This addresses a recognized limitation of black-box vision-language models in DocVQA and could support higher-trust applications in document analysis. The design also offers a concrete mechanism for verifiable predictions, which is a strength relative to purely post-hoc explanation methods.
major comments (2)
- Abstract: the claim of a 12% ANLS improvement and SotA explainable performance is presented without any description of the experimental setup, baselines, ablations, or error analysis of the localization module. This is load-bearing for the central claim, as the skeptic correctly notes that no verification is given that the localization step is accurate enough to avoid discarding useful context or introducing errors that would negate the reported gain.
- Abstract: the weakest assumption—that forcing exclusive decoding from a single localized region simultaneously improves accuracy and genuine explainability—is not tested. No ablation removing the restriction, no breakdown of multi-region questions, and no analysis of localization error rates on PFL-DocVQA are provided, leaving open the possibility that the observed improvement stems from other unstated factors rather than the chain-of-explanation design.
minor comments (2)
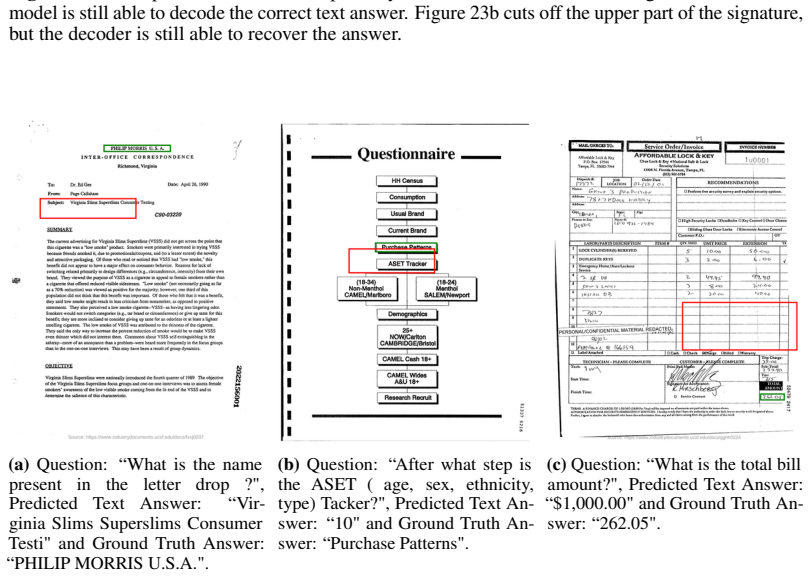
- Abstract: the phrase 'transparent and verifiable predictions' should be accompanied by a concrete example or figure showing how a user would inspect the chain (evidence identification, bounding box, and answer) to make the benefit explicit.
- The manuscript would benefit from a dedicated section or diagram illustrating the three-stage pipeline with input/output examples from PFL-DocVQA.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address each major comment below and will make revisions to strengthen the manuscript, particularly by enhancing the abstract and adding requested analyses.
read point-by-point responses
-
Referee: Abstract: the claim of a 12% ANLS improvement and SotA explainable performance is presented without any description of the experimental setup, baselines, ablations, or error analysis of the localization module. This is load-bearing for the central claim, as the skeptic correctly notes that no verification is given that the localization step is accurate enough to avoid discarding useful context or introducing errors that would negate the reported gain.
Authors: We agree that the abstract would benefit from additional context to support the central empirical claim. In the revised manuscript, we will expand the abstract to briefly describe the PFL-DocVQA dataset, mention the explainable baselines compared against, and note that detailed ablations and localization error analysis will be added to the Experiments section to substantiate the reported gain. revision: yes
-
Referee: Abstract: the weakest assumption—that forcing exclusive decoding from a single localized region simultaneously improves accuracy and genuine explainability—is not tested. No ablation removing the restriction, no breakdown of multi-region questions, and no analysis of localization error rates on PFL-DocVQA are provided, leaving open the possibility that the observed improvement stems from other unstated factors rather than the chain-of-explanation design.
Authors: We acknowledge the importance of directly testing this core assumption. The manuscript does not currently include an ablation removing the exclusive decoding restriction. We will add this ablation in the revised version, along with a breakdown of multi-region questions and localization error rate analysis on PFL-DocVQA, to confirm that the improvements stem from the chain-of-explanation design. revision: yes
Circularity Check
No circularity: framework design and empirical gains are independent of inputs
full rationale
The paper introduces CoExVQA as an architectural framework (localize then decode exclusively from grounded region) whose claimed ANLS improvement is presented as an empirical outcome on PFL-DocVQA rather than a quantity derived by construction from fitted parameters or prior self-citations. No equations, uniqueness theorems, or ansatzes are shown that reduce the prediction or the performance delta to the model's own inputs. The chain-of-explanation is a procedural design choice whose correctness is left to external validation on the benchmark, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sajid Ali, Tamer Abuhmed, Shaker El-Sappagh, Khan Muhammad, Jose M Alonso-Moral, Roberto Confalonieri, Riccardo Guidotti, Javier Del Ser, Natalia Díaz-Rodríguez, and Francisco Herrera. Explainable artificial intelligence (xai): What we know and what is left to attain trustworthy artificial intelligence.Information Fusion, 99:101805, 2023
work page 2023
-
[2]
Pierre-Daniel Arsenault, Shengrui Wang, and Jean-Marc Patenaude. A survey of explainable artificial intelligence (xai) in financial time series forecasting.ACM Computing Surveys, 57(10):1–37, 2025
work page 2025
-
[3]
Self-driving cars: A survey.Expert systems with applications, 165:113816, 2021
Claudine Badue, Rânik Guidolini, Raphael Vivacqua Carneiro, Pedro Azevedo, Vinicius B Cardoso, Avelino Forechi, Luan Jesus, Rodrigo Berriel, Thiago M Paixao, Filipe Mutz, et al. Self-driving cars: A survey.Expert systems with applications, 165:113816, 2021
work page 2021
-
[4]
Survey on question answering over visually rich documents: Methods, challenges, and trends, 2025
Camille Barboule, Benjamin Piwowarski, and Yoan Chabot. Survey on question answering over visually rich documents: Methods, challenges, and trends, 2025
work page 2025
-
[5]
Rajendran, Biplob Debnath, Konstantinos Karydis, Amit K
Sarosij Bose, Ravi K. Rajendran, Biplob Debnath, Konstantinos Karydis, Amit K. Roy- Chowdhury, and Srimat Chakradhar. Visual alignment of medical vision-language models for grounded radiology report generation, 2025
work page 2025
-
[6]
Longbing Cao. Ai in finance: challenges, techniques, and opportunities.ACM Computing Surveys (CSUR), 55(3):1–38, 2022
work page 2022
-
[7]
Shikra: Unleashing multimodal llm’s referential dialogue magic, 2023
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic, 2023
work page 2023
-
[8]
Fouhey, Joyce Chai, and Shengyi Qian
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Jianing Yang, David F. Fouhey, Joyce Chai, and Shengyi Qian. Multi-object hallucination in vision language models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 44393–44418. Curran Associates,...
work page 2024
-
[9]
Changkyu Choi, Shujian Yu, Michael Kampffmeyer, Arnt-Børre Salberg, Nils Olav Handegard, and Robert Jenssen. DIB-X: Formulating explainability principles for a self-explainable model through information theoretic learning. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7170–7174. IEEE, 2024
work page 2024
-
[10]
Paddleocr 3.0 technical report, 2025
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. Paddleocr 3.0 technical report, 2025
work page 2025
-
[11]
Attention grounded enhancement for visual document retrieval, 2025
Wanqing Cui, Wei Huang, Yazhi Guo, Yibo Hu, Meiguang Jin, Junfeng Ma, and Keping Bi. Attention grounded enhancement for visual document retrieval, 2025
work page 2025
-
[12]
Pp-ocr: A practical ultra lightweight ocr system, 2020
Yuning Du, Chenxia Li, Ruoyu Guo, Xiaoting Yin, Weiwei Liu, Jun Zhou, Yifan Bai, Zilin Yu, Yehua Yang, Qingqing Dang, and Haoshuang Wang. Pp-ocr: A practical ultra lightweight ocr system, 2020. 10
work page 2020
-
[13]
Colpali: Efficient document retrieval with vision language models, 2025
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models, 2025
work page 2025
-
[14]
Safe artificial intelligence in finance.Finance Research Letters, 56:104088, 2023
Paolo Giudici and Emanuela Raffinetti. Safe artificial intelligence in finance.Finance Research Letters, 56:104088, 2023
work page 2023
-
[15]
Michal Golovanevsky, William Rudman, Vedant Palit, Ritambhara Singh, and Carsten Eickhoff. What do vlms notice? a mechanistic interpretability pipeline for gaussian-noise-free text-image corruption and evaluation, 2025
work page 2025
-
[16]
Abhishek Gupta, Alagan Anpalagan, Ling Guan, and Ahmed Shaharyar Khwaja. Deep learning for object detection and scene perception in self-driving cars: Survey, challenges, and open issues.Array, 10:100057, 2021
work page 2021
-
[17]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, June 2016
work page 2016
-
[18]
Iterative answer prediction with pointer-augmented multimodal transformers for textvqa
Ronghang Hu, Amanpreet Singh, Trevor Darrell, and Marcus Rohrbach. Iterative answer prediction with pointer-augmented multimodal transformers for textvqa. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9992–10002, 2020
work page 2020
-
[19]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, p...
work page 2024
-
[20]
Layoutlmv3: Pre-training for document ai with unified text and image masking
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. Layoutlmv3: Pre-training for document ai with unified text and image masking. InProceedings of the 30th ACM international conference on multimedia, pages 4083–4091, 2022
work page 2022
-
[21]
Towards self-explainable document visual question answering through infor- mation theoretic learning
Kjetil Indrehus. Towards self-explainable document visual question answering through infor- mation theoretic learning. Msc thesis, informatics: Programming and systems architecture, University of Oslo, 2026. Submitted
work page 2026
-
[22]
A survey on vision-language-action models for autonomous driving, 2025
Sicong Jiang, Zilin Huang, Kangan Qian, Ziang Luo, Tianze Zhu, Yang Zhong, Yihong Tang, Menglin Kong, Yunlong Wang, Siwen Jiao, Hao Ye, Zihao Sheng, Xin Zhao, Tuopu Wen, Zheng Fu, Sikai Chen, Kun Jiang, Diange Yang, Seongjin Choi, and Lijun Sun. A survey on vision-language-action models for autonomous driving, 2025
work page 2025
-
[23]
Explainability and vision foundation models: A survey.Information Fusion, 122:103184, 2025
Rémi Kazmierczak, Eloïse Berthier, Goran Frehse, and Gianni Franchi. Explainability and vision foundation models: A survey.Information Fusion, 122:103184, 2025
work page 2025
-
[24]
Colbert: Efficient and effective passage search via contextual- ized late interaction over bert
Omar Khattab and Matei Zaharia. Colbert: Efficient and effective passage search via contextual- ized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48, 2020
work page 2020
-
[25]
Ocr-free document understanding transformer
Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. InComputer Vision – ECCV 2022, pages 498–517, Cham, 2022. Springer Nature Switzerland
work page 2022
-
[26]
Jaeseung Lee and Jehyeok Rew. Vision-language model-based local interpretable model- agnostic explanations analysis for explainable in-vehicle controller area network intrusion detection.Sensors, 25(10), 2025
work page 2025
-
[27]
Pix2struct: Screenshot parsing as pretraining for visual language understanding
Kenton Lee, Mandar Joshi, Iulia Raluca Turc, Hexiang Hu, Fangyu Liu, Julian Martin Eisensch- los, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. Pix2struct: Screenshot parsing as pretraining for visual language understanding. InInternational Confer- ence on Machine Learning, pages 18893–18912. PMLR, 2023
work page 2023
-
[28]
Yolov13: Real-time object detection with hypergraph-enhanced adaptive visual perception
Mengqi Lei, Siqi Li, Yihong Wu, and others. Yolov13: Real-time object detection with hypergraph-enhanced adaptive visual perception.arXiv preprint arXiv:2506.17733, 2025. 11
-
[29]
V . I. Levenshtein. Binary coodes capable of correcting deletions, insertions, and reversals. In Soviet physics-doklady, volume 10, 1966
work page 1966
-
[30]
Luca Longo, Mario Brcic, Federico Cabitza, Jaesik Choi, Roberto Confalonieri, Javier Del Ser, Riccardo Guidotti, Yoichi Hayashi, Francisco Herrera, Andreas Holzinger, et al. Explainable artificial intelligence (xai) 2.0: A manifesto of open challenges and interdisciplinary research directions.Information Fusion, 106:102301, 2024
work page 2024
-
[31]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[32]
Learning visual question answering by bootstrapping hard attention
Mateusz Malinowski, Carl Doersch, Adam Santoro, and Peter Battaglia. Learning visual question answering by bootstrapping hard attention. InProceedings of the European Conference on Computer Vision (ECCV), September 2018
work page 2018
-
[33]
ColMate: Contrastive late interaction and masked text for multimodal document retrieval
Ahmed Masry, Megh Thakkar, Patrice Bechard, Sathwik Tejaswi Madhusudhan, Rabiul Awal, Shambhavi Mishra, Akshay Kalkunte Suresh, Srivatsava Daruru, Enamul Hoque, Spandana Gella, Torsten Scholak, and Sai Rajeswar. ColMate: Contrastive late interaction and masked text for multimodal document retrieval. In Saloni Potdar, Lina Rojas-Barahona, and Sebastien Mon...
work page 2025
-
[34]
Minesh Mathew, Dimosthenis Karatzas, and C.V . Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2200–2209, January 2021
work page 2021
-
[35]
Sajid Nazir, Diane M Dickson, and Muhammad Usman Akram. Survey of explainable artificial intelligence techniques for biomedical imaging with deep neural networks.Computers in Biology and Medicine, 156:106668, 2023
work page 2023
-
[36]
Hoang T. N. Nguyen, Dong Nie, Taivanbat Badamdorj, Yujie Liu, Yingying Zhu, Jason Truong, and Li Cheng. Automated generation of accurate & fluent medical x-ray reports, 2021
work page 2021
-
[37]
Multimodal explanations: Justifying decisions and pointing to the evidence
Dong Huk Park, Lisa Anne Hendricks, Zeynep Akata, Anna Rohrbach, Bernt Schiele, Trevor Darrell, and Marcus Rohrbach. Multimodal explanations: Justifying decisions and pointing to the evidence. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8779–8788, 2018
work page 2018
-
[38]
Kosmos-2: Grounding multimodal large language models to the world, 2023
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world, 2023
work page 2023
-
[39]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[40]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
work page 2016
-
[41]
Generalized intersection over union: A metric and a loss for bounding box regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
work page 2019
-
[42]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. "why should i trust you?" explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144, 2016. 12
work page 2016
-
[43]
Privacy-aware document visual question answering
Tito Rubèn, Khanh Nguyen, Marlon Tobabon, Raouf Kerkouche, Mohamed Ali Souibgui, Kangsoo Jung, Joonas Jälkö, Vincent Poulain d’Andecy, Aurelie Joseph, Lei Kang, et al. Privacy-aware document visual question answering. InInternational Conference on Document Analysis and Recognition, 2024
work page 2024
-
[44]
Waddah Saeed and Christian Omlin. Explainable ai (xai): A systematic meta-survey of current challenges and future opportunities.Knowledge-Based Systems, 263:110273, 2023
work page 2023
-
[45]
Deepti Saraswat, Pronaya Bhattacharya, Ashwin Verma, Vivek Kumar Prasad, Sudeep Tanwar, Gulshan Sharma, Pitshou N. Bokoro, and Ravi Sharma. Explainable ai for healthcare 5.0: Opportunities and challenges.IEEE Access, 10:84486–84517, 2022
work page 2022
-
[46]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 10 2017
work page 2017
-
[47]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning. In A. Globerson, L. Mackey, D. Bel- grave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Proc...
work page 2024
-
[48]
Docvxqa: Context-aware visual explanations for document question answering
Mohamed Ali Souibgui, Changkyu Choi, Andrey Barsky, Kangsoo Jung, Ernest Valveny, and Dimosthenis Karatzas. Docvxqa: Context-aware visual explanations for document question answering. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[49]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
work page 2023
-
[50]
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning, 2025
work page 2025
-
[51]
On the faithfulness of vision transformer explanations
Junyi Wu, Weitai Kang, Hao Tang, Yuan Hong, and Yan Yan. On the faithfulness of vision transformer explanations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10936–10945, 2024
work page 2024
-
[52]
Layoutxlm: Multimodal pre-training for multilingual visually-rich document understanding, 2021
Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, and Furu Wei. Layoutxlm: Multimodal pre-training for multilingual visually-rich document understanding, 2021
work page 2021
-
[53]
Wenli Yang, Yuchen Wei, Hanyu Wei, Yanyu Chen, Guan Huang, Xiang Li, Renjie Li, Naimeng Yao, Xinyi Wang, Xiaotong Gu, Muhammad Bilal Amin, and Byeong Kang. Survey on ex- plainable AI: From approaches, limitations and applications aspects.Human-Centric Intelligent Systems, 3:161–188, 2023
work page 2023
-
[54]
Yue Yang, Artemis Panagopoulou, Shenghao Zhou, Daniel Jin, Chris Callison-Burch, and Mark Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19187–19197, 6 2023
work page 2023
-
[55]
Tap: Text-aware pre-training for text-vqa and text-caption
Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Florencio, Lijuan Wang, Cha Zhang, Lei Zhang, and Jiebo Luo. Tap: Text-aware pre-training for text-vqa and text-caption. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8751–8761, 2021
work page 2021
-
[56]
Wenlong Yu, Qilong Wang, Chuang Liu, Dong Li, and Qinghua Hu. Coe: Chain-of-explanation via automatic visual concept circuit description and polysemanticity quantification. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4364–4374, June 2025. 13
work page 2025
-
[57]
Yongxin Zhu, Zhen Liu, Yukang Liang, Xin Li, Hao Liu, Changcun Bao, and Linli Xu. Locate then generate: Bridging vision and language with bounding box for scene-text vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 11479–11487, 2023. 14 Appendix The appendix contains the following supplementary material: • Appendix A...
work page 2023
-
[58]
Use Amazon Textract OCR to collect line texts with bounding boxes
-
[59]
For each OCR line ti, compute norm(ti) and dig(ti) and compare them to the answer a. We select the first matching line according to the priority: (1) exact match on norm, (2) exact match on dig, (3) substring match on norm, (4) substring match on dig, (5) fuzzy match onnorm(score≥τ text), and (6) fuzzy match ondig(score≥τ dig)
-
[60]
If this also fails, set the prior toNone
If no acceptable match is found, run PaddleOCR and repeat step 2. If this also fails, set the prior toNone
-
[61]
B". The example was marked as “partial
Convert the selected box to normalized coordinates [x1, y1, x2, y2]∈[0,1] 4, expand it by +10%inxand+15%iny, and clip to[0,1]. 2https://aws.amazon.com/textract/ 3NFKC, lowercasing, and replacing non-alphanumeric characters with white-space. 18 To better understand how the pipeline behaves in practice, we record which rule in Step 2 produced the selected m...
work page 1939
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.