Recognition: unknown
Causal Reinforcement Learning for Complex Card Games: A Magic The Gathering Benchmark
Pith reviewed 2026-05-08 13:54 UTC · model grok-4.3
The pith
Coupling Magic the Gathering with an explicit causal model creates a testbed for causal reinforcement learning questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
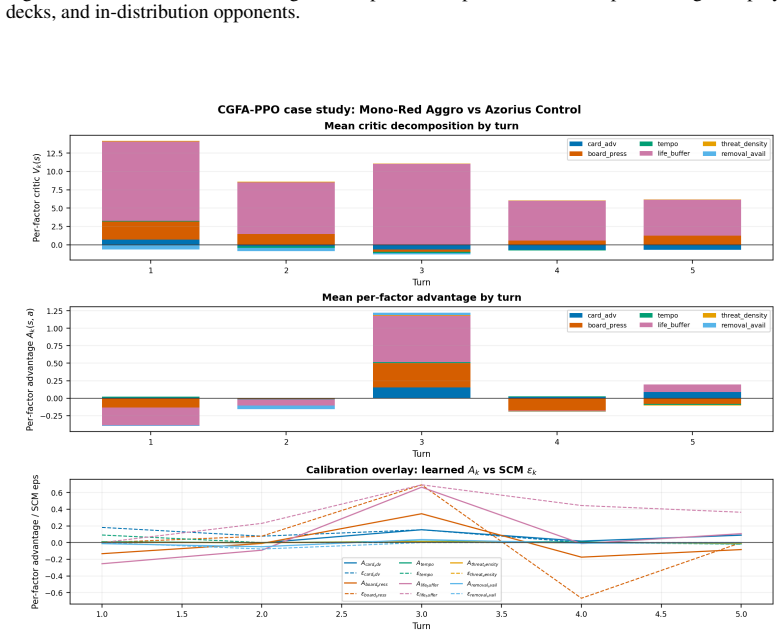
The authors present MTG-Causal-RL as an open benchmark that couples a complex, partially observed card game with an explicit structural causal model over strategic variables. Every episode supplies the causal variables, the SCM-predicted intervention effects, and per-factor credit traces. They adapt standard baselines and introduce CGFA-PPO, which aligns critic targets to the SCM parents of win probability and adds an intervention-calibration loss. Statistical comparisons with paired seeds, bootstrap intervals, and multiplicity correction show that causal metrics reveal diagnostic structure that win rate alone does not capture.
What carries the argument
The hand-specified Structural Causal Model over strategic variables, which supplies predicted intervention effects and per-factor credit traces so that policies can be audited and transferred on causal rather than scalar grounds.
If this is right
- Causal credit assignment becomes directly measurable under masked action spaces via the supplied per-factor traces.
- Leave-one-out transfer gaps across archetypes become a standard diagnostic for structural generalization.
- Policy auditability is supported by SCM-grounded decomposition of contributions to win probability.
- Reference baselines and the pre-registered statistical protocol establish comparable performance floors for new causal agents.
Where Pith is reading between the lines
- Agents trained with the causal interface may show more stable transfer when game rules or card pools change.
- The benchmark could serve as a concrete test for whether language-model agents improve when given access to explicit causal structure.
- Replacing the hand-specified model with one learned from data would be a natural next measurement of how much the current results depend on expert causal knowledge.
- Similar causal interfaces could be added to other partially observed strategy domains to enable the same class of diagnostics.
Load-bearing premise
The hand-specified structural causal model accurately captures the true causal relationships among strategic variables in the game.
What would settle it
Force a specific strategic variable to a new value in a set of episodes, then check whether the observed change in win rate matches the effect size predicted by the SCM within the reported confidence intervals.
Figures







read the original abstract
Causal reinforcement learning (RL) lacks benchmarks for complex systems that combine sequential decision making, hidden information, large masked action spaces, and explicit causal structure. We introduce MTG-Causal-RL, a Gymnasium benchmark built on Magic: The Gathering with a 3,077-dimensional partial observation, a 478-action masked discrete action space, five competitive Standard archetypes, three reward schemes, and a hand-specified Structural Causal Model (SCM) over strategic variables. Every episode exposes causal variables, SCM-predicted intervention effects, and per-factor credit traces, making causal credit assignment, leave-one-out cross-archetype transfer, and policy auditability first-class metrics. We adapt a panel of reference baselines: random, heuristic, masked PPO, a causal-world-model PPO variant, and an architecture-matched scalar control. We propose Causal Graph-Factored Advantage PPO (CGFA-PPO) as a reference causal agent that uses SCM parents of win probability as factor-aligned critic targets with an intervention-calibration loss. All comparisons use paired seeds, paired-bootstrap confidence intervals, and Holm-Bonferroni correction within pre-registered families. Masked PPO and CGFA-PPO reach competitive in-distribution win rates and exceed the random baseline; per-factor calibration trajectories and leave-one-out transfer gaps expose diagnostic structure that scalar win rate alone cannot. We release the benchmark, reference-baseline results, and full evaluation protocol openly. By coupling a strategically rich, partially observed domain with an explicit causal interface and statistical protocol, MTG-Causal-RL gives causal-RL, world-model, and LLM-agent research a shared testbed for questions current benchmarks cannot pose together: causal credit assignment under masked action spaces, structural transfer across archetypes, and SCM-grounded policy auditability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MTG-Causal-RL, a Gymnasium benchmark for causal RL built on Magic: The Gathering. It features 3,077-dimensional partial observations, a 478-action masked discrete space, five Standard archetypes, three reward schemes, and a hand-specified SCM over strategic variables that exposes causal variables, SCM-predicted intervention effects, and per-factor credit traces per episode. The authors adapt baselines (random, heuristic, masked PPO, causal-world-model PPO, scalar control), propose CGFA-PPO (which uses SCM parents of win probability as factor-aligned critic targets plus an intervention-calibration loss), and evaluate all agents with paired seeds, paired-bootstrap CIs, and Holm-Bonferroni correction. They report that masked PPO and CGFA-PPO exceed random baselines in win rate while per-factor calibration and leave-one-out transfer gaps reveal diagnostic structure; the benchmark, results, and protocol are released openly.
Significance. If the hand-specified SCM is shown to be faithful to the simulator, the benchmark would supply a shared, statistically controlled testbed for causal credit assignment under masked actions, structural transfer across archetypes, and SCM-grounded policy auditability—questions that simpler RL or causal-RL suites cannot pose together. The open release of artifacts and the pre-registered statistical protocol are concrete strengths that lower the barrier for follow-on work.
major comments (2)
- [SCM description and evaluation protocol] The manuscript provides no empirical validation that the hand-specified SCM's predicted intervention effects match the actual effects of the corresponding do-interventions inside the MTG simulator (see the SCM specification and the description of per-factor credit traces). This is load-bearing for the central claim that the benchmark supplies a usable 'causal interface' for credit assignment and auditability; without such validation the supplied traces and effects remain unanchored to the true game dynamics.
- [Results and baselines] Table of results (or equivalent): the claim that CGFA-PPO and masked PPO are 'competitive' is supported only by win-rate comparisons to random; no quantitative comparison to the heuristic or causal-world-model PPO baselines is reported with the same statistical controls, weakening the assertion that the causal components confer a measurable advantage.
minor comments (2)
- [Abstract and benchmark interface] The abstract states that 'every episode exposes causal variables, SCM-predicted intervention effects, and per-factor credit traces' but the precise mapping from game state to these quantities is not summarized in a single table or figure; a compact reference table would improve usability.
- [CGFA-PPO method] Notation for the intervention-calibration loss in CGFA-PPO is introduced without an explicit equation number; cross-referencing it to the SCM parents would clarify the factor-aligned critic construction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments identify key areas where the manuscript can be strengthened to better support the benchmark's claims. We address each major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [SCM description and evaluation protocol] The manuscript provides no empirical validation that the hand-specified SCM's predicted intervention effects match the actual effects of the corresponding do-interventions inside the MTG simulator (see the SCM specification and the description of per-factor credit traces). This is load-bearing for the central claim that the benchmark supplies a usable 'causal interface' for credit assignment and auditability; without such validation the supplied traces and effects remain unanchored to the true game dynamics.
Authors: We agree that explicit empirical validation of the hand-specified SCM's intervention predictions against the MTG simulator is necessary to anchor the causal interface. The current manuscript relies on expert hand-specification and internal consistency but does not report direct do-intervention experiments comparing SCM outputs to simulator outcomes. We will add a dedicated validation subsection in the revised manuscript that includes quantitative comparisons (e.g., effect size agreement and calibration metrics) for representative interventions on strategic variables. revision: yes
-
Referee: [Results and baselines] Table of results (or equivalent): the claim that CGFA-PPO and masked PPO are 'competitive' is supported only by win-rate comparisons to random; no quantitative comparison to the heuristic or causal-world-model PPO baselines is reported with the same statistical controls, weakening the assertion that the causal components confer a measurable advantage.
Authors: The manuscript describes the full panel of baselines (random, heuristic, masked PPO, causal-world-model PPO, and scalar control) and applies the pre-registered statistical protocol (paired seeds, bootstrap CIs, Holm-Bonferroni) to the reported comparisons. However, the primary tables and figures emphasize results versus the random baseline. We will expand the results section to present the complete set of statistical comparisons across all baselines using the same controls, and we will clarify the performance increments attributable to the causal components of CGFA-PPO. revision: yes
Circularity Check
No significant circularity; benchmark supplies explicit SCM as input rather than deriving results from it
full rationale
The paper defines MTG-Causal-RL as a Gymnasium environment that ships with a hand-specified SCM; all reported metrics (win rates, leave-one-out transfer gaps, per-factor calibration) are obtained from direct game rollouts under paired seeds and statistical corrections. CGFA-PPO incorporates SCM-derived targets into its critic and calibration loss, yet these quantities are not fitted to the evaluation episodes and the performance numbers do not reduce to SCM outputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to close the central argument, leaving the derivation chain as an explicit benchmark specification rather than a self-referential prediction.
Axiom & Free-Parameter Ledger
free parameters (2)
- five competitive Standard archetypes
- three reward schemes
axioms (1)
- domain assumption The hand-specified Structural Causal Model correctly encodes the causal parents of win probability and intervention effects.
invented entities (1)
-
CGFA-PPO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2009 , edition=
Causality: Models, Reasoning, and Inference , author=. 2009 , edition=
2009
-
[2]
Communications of the ACM , volume=
The Seven Tools of Causal Inference, with Reflections on Machine Learning , author=. Communications of the ACM , volume=. 2019 , publisher=
2019
-
[3]
2018 , edition=
Reinforcement Learning: An Introduction , author=. 2018 , edition=
2018
-
[4]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review arXiv
-
[5]
International Conference on Learning Representations , year=
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author=. International Conference on Learning Representations , year=
-
[6]
Machine Learning , volume=
Learning to Predict by the Methods of Temporal Differences , author=. Machine Learning , volume=. 1988 , publisher=
1988
-
[7]
The International FLAIRS Conference Proceedings , volume=
A Closer Look at Invalid Action Masking in Policy Gradient Algorithms , author=. The International FLAIRS Conference Proceedings , volume=
-
[8]
Raffin, Antonin and Hill, Ashley and Gleave, Adam and Kanervisto, Anssi and Ernestus, Maximilian and Dormann, Noah , journal=. Stable-
-
[9]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Towers, Mark and Kwiatkowski, Ariel and Terry, Jordan and Balis, John U. and De Cola, Gianluca and Deleu, Tristan and Goul. arXiv preprint arXiv:2407.17032 , year=
work page internal anchor Pith review arXiv
-
[10]
International Conference on Machine Learning , pages=
Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping , author=. International Conference on Machine Learning , pages=
-
[11]
Potential-Based Reward Shaping for Finite Horizon Online
Eck, Adam and Soh, Leen-Kiat and Devlin, Sam and Kudenko, Daniel , journal=. Potential-Based Reward Shaping for Finite Horizon Online. 2016 , publisher=
2016
-
[12]
Advances in Neural Information Processing Systems , volume=
Hybrid Reward Architecture for Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
International Conference on Autonomous Agents and Multiagent Systems , pages=
Horde: A Scalable Real-Time Architecture for Learning Knowledge from Unsupervised Sensorimotor Interaction , author=. International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[14]
International Conference on Learning Representations , year=
Reinforcement Learning with Unsupervised Auxiliary Tasks , author=. International Conference on Learning Representations , year=
-
[15]
AAAI Conference on Artificial Intelligence , year=
The Option-Critic Architecture , author=. AAAI Conference on Artificial Intelligence , year=
-
[16]
International Conference on Learning Representations , year=
Dream to Control: Learning Behaviors by Latent Imagination , author=. International Conference on Learning Representations , year=
-
[17]
Mastering
Hafner, Danijar and Lillicrap, Timothy and Norouzi, Mohammad and Ba, Jimmy , booktitle=. Mastering
-
[18]
Mastering
Schrittwieser, Julian and Antonoglou, Ioannis and Hubert, Thomas and Simonyan, Karen and Sifre, Laurent and Schmitt, Simon and Guez, Arthur and Lockhart, Edward and Hassabis, Demis and Graepel, Thore and Lillicrap, Timothy and Silver, David , journal=. Mastering
-
[19]
Nature , volume=
Human-Level Control through Deep Reinforcement Learning , author=. Nature , volume=. 2015 , publisher=
2015
-
[20]
and Guez, Arthur and Sifre, Laurent and Van Den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and others , journal=
Silver, David and Huang, Aja and Maddison, Chris J. and Guez, Arthur and Sifre, Laurent and Van Den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and others , journal=. Mastering the Game of. 2016 , publisher=
2016
-
[21]
Mastering the Game of
Silver, David and Schrittwieser, Julian and Simonyan, Karen and Antonoglou, Ioannis and Huang, Aja and Guez, Arthur and Hubert, Thomas and Baker, Lucas and Lai, Matthew and Bolton, Adrian and others , journal=. Mastering the Game of. 2017 , publisher=
2017
-
[22]
A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and
Silver, David and Hubert, Thomas and Schrittwieser, Julian and Antonoglou, Ioannis and Lai, Matthew and Guez, Arthur and Lanctot, Marc and Sifre, Laurent and Kumaran, Dharshan and Graepel, Thore and Lillicrap, Timothy and Simonyan, Karen and Hassabis, Demis , journal=. A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and. 2018 , publisher=
2018
-
[23]
Superhuman
Brown, Noam and Sandholm, Tuomas , journal=. Superhuman. 2018 , publisher=
2018
-
[24]
Superhuman
Brown, Noam and Sandholm, Tuomas , journal=. Superhuman. 2019 , publisher=
2019
-
[25]
Zha, Daochen and Xie, Jingru and Ma, Wenye and Zhang, Sheng and Lian, Xiangru and Hu, Xia and Liu, Ji , booktitle=
-
[26]
and Togelius, Julian and Lee, Scott and de Mesentier Silva, Fernando , journal=
Hoover, Amy K. and Togelius, Julian and Lee, Scott and de Mesentier Silva, Fernando , journal=. The Many. 2020 , publisher=
2020
-
[27]
Summarizing Strategy Card Game
Kowalski, Jakub and Miernik, Rados. Summarizing Strategy Card Game. IEEE Conference on Games , year=
-
[28]
Santos, Andr. Monte. IEEE Conference on Computational Intelligence and Games , pages=
-
[29]
and Powley, Edward J
Cowling, Peter I. and Powley, Edward J. and Whitehouse, Daniel , journal=. Information Set. 2012 , publisher=
2012
-
[30]
and Cowling, Peter I
Ward, Colin D. and Cowling, Peter I. , booktitle=. Monte
-
[31]
Magic: The Gathering is
Churchill, Alex and Biderman, Stella and Herrick, Austin , journal=. Magic: The Gathering is
-
[32]
The Pocket Players' Guide for
Garfield, Richard and Redman, Rich and Doohan, Eric , year=. The Pocket Players' Guide for
-
[33]
Todorov, Emanuel and Erez, Tom and Tassa, Yuval , booktitle=
-
[34]
Tassa, Yuval and Doron, Yotam and Muldal, Alistair and Erez, Tom and Li, Yazhe and de Las Casas, Diego and Budden, David and Abdolmaleki, Abbas and Merel, Josh and Lefrancq, Andrew and Lillicrap, Timothy and Riedmiller, Martin , journal=
-
[35]
and Naddaf, Yavar and Veness, Joel and Bowling, Michael , journal=
Bellemare, Marc G. and Naddaf, Yavar and Veness, Joel and Bowling, Michael , journal=. The
-
[36]
International Conference on Machine Learning , pages=
Leveraging Procedural Generation to Benchmark Reinforcement Learning , author=. International Conference on Machine Learning , pages=
-
[37]
K. The. Advances in Neural Information Processing Systems , volume=
-
[38]
European Conference on Artificial Intelligence , year=
Automatic Bridge Bidding Using Deep Reinforcement Learning , author=. European Conference on Artificial Intelligence , year=
-
[39]
arXiv preprint arXiv:2302.05209 , year=
A Survey on Causal Reinforcement Learning , author=. arXiv preprint arXiv:2302.05209 , year=
-
[40]
Proceedings of the IEEE , volume=
Toward Causal Representation Learning , author=. Proceedings of the IEEE , volume=
- [41]
-
[42]
Toyer, Sam and Shah, Rohin and Critch, Andrew and Russell, Stuart , booktitle=. The
-
[43]
Advances in Neural Information Processing Systems , volume=
Causal Imitation Learning with Unobserved Confounders , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Deconfounding Reinforcement Learning in Observational Settings
Deconfounding Reinforcement Learning in Observational Settings , author=. arXiv preprint arXiv:1812.10576 , year=
-
[45]
arXiv preprint arXiv:1811.06272 , year=
Woulda, Coulda, Shoulda: Counterfactually-Guided Policy Search , author=. arXiv preprint arXiv:1811.06272 , year=
-
[46]
International Conference on Machine Learning , pages=
Counterfactual Data-Fusion for Online Reinforcement Learners , author=. International Conference on Machine Learning , pages=
-
[47]
International Conference on Machine Learning , pages=
Causal Dynamics Learning for Task-Independent State Abstraction , author=. International Conference on Machine Learning , pages=
-
[48]
Invariant Causal Prediction for Block
Zhang, Amy and Lyle, Clare and Sodhani, Shagun and Filos, Angelos and Kwiatkowska, Marta and Pineau, Joelle and Gal, Yarin and Precup, Doina , booktitle=. Invariant Causal Prediction for Block
-
[49]
Advances in Neural Information Processing Systems , volume=
Bandits with Unobserved Confounders: A Causal Approach , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
Huang, Biwei and Feng, Fan and Lu, Chaochao and Magliacane, Sara and Zhang, Kun , booktitle=
-
[51]
International Conference on Learning Representations , year=
Robust Agents Learn Causal World Models , author=. International Conference on Learning Representations , year=
-
[52]
Journal of Artificial Intelligence Research , volume=
A Survey of Zero-Shot Generalisation in Deep Reinforcement Learning , author=. Journal of Artificial Intelligence Research , volume=
-
[53]
International Conference on Machine Learning , pages=
Quantifying Generalization in Reinforcement Learning , author=. International Conference on Machine Learning , pages=
-
[54]
Costarelli, Anthony and Allen, Mat and Hauksson, Roman and Sodunke, Grace and Hariharan, Suhas and Cheng, Carlson and Li, Wenjie and Clymer, Joshua and Yadav, Arjun , journal=
-
[55]
Duan, Jinhao and Zhang, Renming and Diffenderfer, James and Kailkhura, Bhavya and Sun, Lichao and Stengel-Eskin, Elias and Bansal, Mohit and Chen, Tianlong and Xu, Kaidi , journal=
-
[56]
Journal of the American Statistical Association , volume=
Probable Inference, the Law of Succession, and Statistical Inference , author=. Journal of the American Statistical Association , volume=. 1927 , publisher=
1927
-
[57]
, journal=
Welch, Bernard L. , journal=. The Generalization of `. 1947 , publisher=
1947
-
[58]
Biometrics Bulletin , volume=
Individual Comparisons by Ranking Methods , author=. Biometrics Bulletin , volume=. 1945 , publisher=
1945
-
[59]
Annals of Mathematical Statistics , volume=
Estimates of Location Based on Rank Tests , author=. Annals of Mathematical Statistics , volume=
-
[60]
Scandinavian Journal of Statistics , volume=
A Simple Sequentially Rejective Multiple Test Procedure , author=. Scandinavian Journal of Statistics , volume=. 1979 , publisher=
1979
-
[61]
1993 , publisher=
An Introduction to the Bootstrap , author=. 1993 , publisher=
1993
-
[62]
Proceedings of the Royal Society of London , volume=
Note on Regression and Inheritance in the Case of Two Parents , author=. Proceedings of the Royal Society of London , volume=. 1895 , publisher=
-
[63]
AAAI Conference on Artificial Intelligence , year=
Deep Reinforcement Learning that Matters , author=. AAAI Conference on Artificial Intelligence , year=
-
[64]
Advances in Neural Information Processing Systems , volume=
Deep Reinforcement Learning at the Edge of the Statistical Precipice , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
2024 , howpublished=
Magic: The Gathering Comprehensive Rules , author=. 2024 , howpublished=
2024
-
[66]
2024 , howpublished=
Standard Format , author=. 2024 , howpublished=
2024
-
[67]
2024 , howpublished=
Metagame Mentor: Winners and Losers from Standard Rotation , author=. 2024 , howpublished=
2024
-
[68]
2024 , howpublished=
Standard Metagame , author=. 2024 , howpublished=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.