Recognition: unknown
Teaching LLMs Program Semantics via Symbolic Execution Traces
Pith reviewed 2026-05-08 08:51 UTC · model grok-4.3
The pith
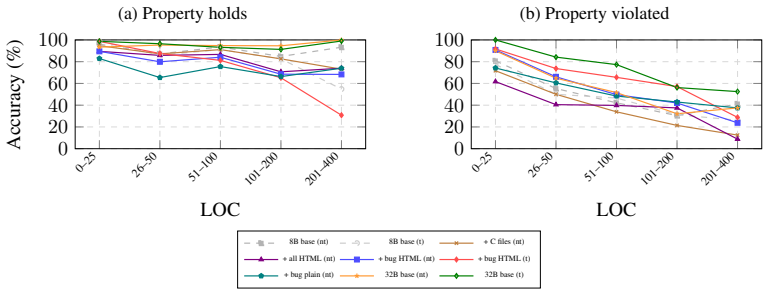
Training an 8B LLM on 3,000 symbolic execution traces from C code, paired with chain-of-thought reasoning, raises violation detection accuracy by more than 17 points and lets it surpass a 32B model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Continued pretraining of Qwen3-8B on symbolic execution traces that record paths to property violations in C code, followed by chain-of-thought reasoning at inference time, produces superadditive improvements in violation detection. The resulting model achieves one of the most balanced accuracy profiles across confirmation and violation tasks and outperforms the larger Qwen3-32B model on violation detection while approaching it overall. These gains arise from the semantics captured in the traces rather than from additional code exposure alone.
What carries the argument
Symbolic execution traces produced by running the Soteria engine on generic open-source C code; these traces encode concrete execution paths and states leading to violations and are used for continued pretraining.
If this is right
- Violation detection gains transfer across all five property types even when the training traces target only some of them.
- The combination of trace-based training and chain-of-thought reasoning at inference produces larger improvements than either component alone.
- Performance improvements depend on the curation and format of the traces rather than the sheer volume of code seen during training.
- Smaller models can reach or exceed larger models on this task after targeted trace training.
Where Pith is reading between the lines
- Similar trace-based training might help LLMs with other formal reasoning tasks such as theorem proving if analogous execution artifacts can be generated.
- The approach could be tested on codebases from different domains to check whether the learned semantics generalize beyond the open-source C programs used for training.
- Integrating these traces into retrieval-augmented generation pipelines might further boost performance on long programs where base models degrade.
Load-bearing premise
The symbolic traces from generic open-source C code convey general program semantics that transfer to the SV-COMP benchmark tasks rather than superficial statistical patterns specific to the training distribution.
What would settle it
Running the trained model on a new set of C programs with violation patterns or lengths that differ systematically from both the trace generation corpus and the SV-COMP tasks, then measuring whether the 17-point violation detection gain disappears.
Figures







read the original abstract
We introduce an evaluation framework of 500 C verification tasks across five property types (memory safety, overflow, termination, reachability, data races) built on SV-COMP 2025, and evaluate 14 models across six families. We find that high overall accuracy masks a critical weakness: while most models reliably confirm properties hold, violation detection varies widely and degrades sharply with program length. To close this gap, we train on formal verification artifacts: running the Soteria symbolic execution engine on generic open-source C code and using the resulting traces for continued pretraining of Qwen3-8B. Just ${\sim}$3,000 bug traces combined with chain-of-thought reasoning at inference time improve violation detection by over 17 percentage points, producing one of the most balanced accuracy profiles among evaluated models. On violation detection, the trained 8B model outperforms the 4$\times$ larger Qwen3-32B without thinking and approaches it in overall accuracy. The interaction between trace training and chain-of-thought is superadditive: neither alone provides meaningful gains, but their combination does. Improvements transfer across all five property types, including ones the training traces do not target. Our 28 configurations confirm the gains stem from trace semantics, not code volume, and that trace curation and format matter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a 500-task C verification benchmark across five properties (memory safety, overflow, termination, reachability, data races) derived from SV-COMP 2025. It shows that LLMs generally confirm properties but struggle with violation detection, especially on longer programs. The authors generate ~3,000 symbolic execution traces via Soteria on generic open-source C code and use them for continued pretraining of Qwen3-8B. Combined with chain-of-thought reasoning at inference, this yields >17pp gains in violation detection; the trained 8B model outperforms 4x larger Qwen3-32B on violations and approaches it overall. Gains are superadditive (traces + CoT), transfer to all five properties (including untargeted ones), and are attributed to trace semantics via 28 controlled configurations rather than code volume alone.
Significance. If the central result holds, the work demonstrates a practical way to inject formal program semantics into LLMs via symbolic traces, producing more balanced verification performance and superadditive benefits with CoT. The multi-property benchmark, cross-property transfer, and explicit ablation of 28 configurations (ruling out volume) are notable strengths that support falsifiable claims about semantic learning. This approach could meaningfully advance LLM-assisted program analysis in software engineering.
major comments (2)
- [Experiments / Ablation study (around the 28-configuration results)] The manuscript states that 28 configurations confirm gains stem from trace semantics rather than code volume, yet does not describe an explicit control isolating semantic content (e.g., randomized trace order, format-only inputs without executable semantics, or syntax-shuffled variants). Without such a condition, it remains possible that improvements reflect learning of trace syntax or SV-COMP-style signatures rather than transferable program semantics; this directly bears on the generalization claims to longer programs and untargeted properties.
- [Data / Corpus construction] No explicit check or statement is provided confirming zero overlap between the generic open-source C corpus used for Soteria trace generation and the SV-COMP-derived 500-task test set. Given that both involve C code, any shared programs or similar constructs could inflate the reported transfer and violation-detection gains.
minor comments (2)
- [Abstract and Results] The abstract claims transfer 'across all five property types, including ones the training traces do not target,' but the main text should explicitly list which properties appear in the Soteria traces versus which are purely zero-shot transfer.
- [Evaluation framework] Reproducibility would benefit from additional detail on task selection/filtering criteria from SV-COMP 2025 and the exact prompt templates used for CoT inference.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and additional controls.
read point-by-point responses
-
Referee: [Experiments / Ablation study (around the 28-configuration results)] The manuscript states that 28 configurations confirm gains stem from trace semantics rather than code volume, yet does not describe an explicit control isolating semantic content (e.g., randomized trace order, format-only inputs without executable semantics, or syntax-shuffled variants). Without such a condition, it remains possible that improvements reflect learning of trace syntax or SV-COMP-style signatures rather than transferable program semantics; this directly bears on the generalization claims to longer programs and untargeted properties.
Authors: We agree that the current description of the 28 configurations focuses primarily on volume controls and format variations but does not include explicit semantic-isolation ablations such as randomized trace ordering or syntax-shuffled variants. Our existing results show that equivalent volumes of raw code (without traces) produce no gains and that trace curation matters, but to more rigorously rule out syntax or signature learning, we will add these specific controls in the revised manuscript. This will provide stronger support for the semantic-learning interpretation and the observed transfer to longer programs and untargeted properties. revision: yes
-
Referee: [Data / Corpus construction] No explicit check or statement is provided confirming zero overlap between the generic open-source C corpus used for Soteria trace generation and the SV-COMP-derived 500-task test set. Given that both involve C code, any shared programs or similar constructs could inflate the reported transfer and violation-detection gains.
Authors: This is a fair concern. We have verified the sources and confirm there is no overlap: the open-source C corpus for trace generation draws from public repositories unrelated to SV-COMP, while the 500-task test set is derived exclusively from SV-COMP 2025 benchmarks with no shared programs or direct constructs. We will add an explicit statement and brief description of this verification to the data-construction section of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical training and external benchmark evaluation
full rationale
The paper reports an empirical study: continued pretraining of Qwen3-8B on ~3,000 Soteria symbolic traces from generic open-source C code, followed by evaluation on a 500-task SV-COMP-derived benchmark across five property classes. No equations, derivations, or self-referential definitions appear in the provided text. The 28 configurations are ablation experiments that compare trace semantics against code volume controls; they do not reduce any reported gain to a fitted parameter or self-citation by construction. The central claim (superadditive lift from traces + CoT) is measured against an external benchmark with no overlap or format-only controls stated as load-bearing. This is a standard self-contained empirical result with no reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Symbolic execution traces from Soteria capture the relevant semantics for detecting violations across memory safety, overflow, termination, reachability, and data races.
Reference graph
Works this paper leans on
-
[1]
Aristotle: IMO-level Automated Theorem Proving
Achim, T., Best, A., Bietti, A., Der, K., Fédérico, M., Gukov, S., Halpern-Leistner, D., Hen- ningsgard, K., Kudryashov, Y ., Meiburg, A., et al. Aristotle: Imo-level automated theorem proving.arXiv preprint arXiv:2510.01346, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Kani rust verifier
Amazon Web Services. Kani rust verifier. https://github.com/model-checking/kani. Accessed February 2026
2026
-
[3]
H., Seeker, V ., Cummins, C., Kambadur, M., O’Boyle, M
Armengol-Estapé, J., Carbonneaux, Q., Zhang, T., Markosyan, A. H., Seeker, V ., Cummins, C., Kambadur, M., O’Boyle, M. F., Wang, S., Synnaeve, G., et al. What i cannot execute, i do not understand: Training and evaluating llms on program execution traces.arXiv preprint arXiv:2503.05703, 2025
-
[4]
Soteria: Efficient Symbolic Execution as a Functional Library
Ayoun, S.-É., Sjöstedt, O., and Raad, A. Soteria: Efficient symbolic execution as a functional library.arXiv preprint arXiv:2511.08729, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
and Strejˇcek, J
Beyer, D. and Strejˇcek, J. Improvements in software verification and witness validation: SV- COMP 2025. InInternational Conference on Tools and Algorithms for the Construction and Analysis of Systems, pp. 151–186. Springer, 2025
2025
-
[7]
arXiv preprint arXiv:2509.22908 , year=
Bursuc, S., Ehrenborg, T., Lin, S., Astefanoaei, L., Chiosa, I. E., Kukovec, J., Singh, A., Butterley, O., Bizid, A., Dougherty, Q., et al. A benchmark for vericoding: formally verified program synthesis.arXiv preprint arXiv:2509.22908, 2025
-
[8]
Moving fast with software verification
Calcagno, C., Distefano, D., Dubreil, J., Gabi, D., Hooimeijer, P., Luca, M., O’Hearn, P., Papakonstantinou, I., Purbrick, J., and Rodriguez, D. Moving fast with software verification. In NASA Formal Methods Symposium, pp. 3–11. Springer, 2015
2015
-
[9]
Leonardo de Moura and Sebastian Ullrich
Chen, L., Gu, J., Huang, L., Huang, W., Jiang, Z., Jie, A., Jin, X., Jin, X., Li, C., Ma, K., et al. Seed-prover: Deep and broad reasoning for automated theorem proving.arXiv preprint arXiv:2507.23726, 2025
-
[10]
Chen, N., Li, Z., Bao, K., Lin, J., and Liu, D. Chain of execution supervision promotes general reasoning in large language models.arXiv preprint arXiv:2510.23629, 2025
- [11]
-
[12]
Github code dataset
CodeParrot. Github code dataset. https://huggingface.co/datasets/codeparrot/ github-code. Accessed: February 2026
2026
-
[13]
Cwm: An open-weights llm for research on code generation with world models
Copet, J., Carbonneaux, Q., Cohen, G., Gehring, J., Kahn, J., Kossen, J., Kreuk, F., McMilin, E., Meyer, M., Wei, Y ., et al. CWM: An open-weights LLM for research on code generation with world models.arXiv preprint arXiv:2510.02387, 2025
-
[14]
CBMC regression tests
Diffblue. CBMC regression tests. https://github.com/diffblue/cbmc/tree/develop/ regression/cbmc. Accessed: February 2026
2026
-
[15]
A., Horvát, K
Dubniczky, R. A., Horvát, K. Z., Bisztray, T., Ferrag, M. A., Cordeiro, L. C., and Tihanyi, N. CASTLE: Benchmarking dataset for static code analyzers and LLMs towards CWE detection,
- [16]
-
[17]
and Akiba, T
Eguchi, K. and Akiba, T. Making LLMs program interpreters via execution trace chain of thought. InICML 2025 Workshop on Programmatic Representations for Agent Learning
2025
-
[18]
I., Gehr, T., and Vechev, M
Fedoseev, T., Dimitrov, D. I., Gehr, T., and Vechev, M. Constraint-based synthetic data generation for llm mathematical reasoning. InThe 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24, 2024
2024
-
[19]
Gu, A., Rozière, B., Leather, H., Solar-Lezama, A., Synnaeve, G., and Wang, S. I. CruxEval: A benchmark for code reasoning, understanding and execution.arXiv preprint arXiv:2401.03065, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
Ultimate automizer and the search for perfect interpolants: (competition contribution)
Heizmann, M., Chen, Y .-F., Dietsch, D., Greitschus, M., Hoenicke, J., Li, Y ., Nutz, A., Musa, B., Schilling, C., Schindler, T., et al. Ultimate automizer and the search for perfect interpolants: (competition contribution). InInternational Conference on Tools and Algorithms for the Construction and Analysis of Systems, pp. 447–451. Springer, 2018
2018
-
[21]
Z., Žuži ´c, G., Wieser, E., Huang, A., Schrit- twieser, J., Schroecker, Y ., Masoom, H., et al
Hubert, T., Mehta, R., Sartran, L., Horváth, M. Z., Žuži ´c, G., Wieser, E., Huang, A., Schrit- twieser, J., Schroecker, Y ., Masoom, H., et al. Olympiad-level formal mathematical reasoning with reinforcement learning.Nature, pp. 1–3, 2025
2025
-
[22]
and Tautschnig, M
Kroening, D. and Tautschnig, M. CBMC–C bounded model checker: (competition contribution). InInternational Conference on Tools and Algorithms for the Construction and Analysis of Systems, pp. 389–391. Springer, 2014
2014
-
[23]
Li, Y ., Li, X., Wu, H., Xu, M., Zhang, Y ., Cheng, X., Xu, F., and Zhong, S. Everything you wanted to know about LLM-based vulnerability detection but were afraid to ask.arXiv preprint arXiv:2504.13474, 2025
-
[24]
arXiv preprint arXiv:2305.05383 , year=
Liu, C., Lu, S., Chen, W., Jiang, D., Svyatkovskiy, A., Fu, S., Sundaresan, N., and Duan, N. Code execution with pre-trained language models.arXiv preprint arXiv:2305.05383, 2023
-
[25]
Maaz, M., DeV oe, L., Hatfield-Dodds, Z., and Carlini, N. Agentic property-based testing: Finding bugs across the python ecosystem.arXiv preprint arXiv:2510.09907, 2025
-
[26]
Mächtle, F., Loose, N., Schulz, T., Sieck, F., Serr, J.-N., Möller, R., and Eisenbarth, T. Trace gadgets: Minimizing code context for machine learning-based vulnerability prediction.arXiv preprint arXiv:2504.13676, 2025
-
[27]
M., Aleithan, R., Harzevili, N
Mohajer, M. M., Aleithan, R., Harzevili, N. S., Wei, M., Belle, A. B., Pham, H. V ., and Wang, S. SkipAnalyzer: A tool for static code analysis with large language models.arXiv preprint arXiv:2310.18532, 2023
-
[28]
Moura, L. d. and Ullrich, S. The Lean 4 theorem prover and programming language. In International Conference on Automated Deduction, pp. 625–635. Springer, 2021
2021
-
[29]
arXiv preprint arXiv:2404.14662 , year=
Ni, A., Allamanis, M., Cohan, A., Deng, Y ., Shi, K., Sutton, C., and Yin, P. NExT: Teaching large language models to reason about code execution.arXiv preprint arXiv:2404.14662, 2024
-
[30]
Qiu, J., Liu, Z., Liu, Z., Murthy, R., Zhang, J., Chen, H., Wang, S., Zhu, M., Yang, L., Tan, J., et al. LocoBench: A benchmark for long-context large language models in complex software engineering.arXiv preprint arXiv:2509.09614, 2025
-
[31]
Ren, Z., Shao, Z., Song, J., Xin, H., Wang, H., Zhao, W., Zhang, L., Fu, Z., Zhu, Q., Yang, D., et al. DeepSeek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
Sakharova, M., Anand, A., and Mezini, M. Integrating symbolic execution into the fine-tuning of code-generating llms.arXiv preprint arXiv:2504.15210, 2025
-
[33]
Llms versus the halting problem: Revisiting program termination prediction
Sultan, O., Armengol-Estape, J., Kesseli, P., Vanegue, J., Shahaf, D., Adi, Y ., and O’Hearn, P. LLMs versus the halting problem: Revisiting program termination prediction.arXiv preprint arXiv:2601.18987, 2026. 11
-
[34]
Thakur, A., Lee, J., Tsoukalas, G., Sistla, M., Zhao, M., Zetzsche, S., Durrett, G., Yue, Y ., and Chaudhuri, S. Clever: A curated benchmark for formally verified code generation.arXiv preprint arXiv:2505.13938, 2025
-
[35]
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Wang, H., Unsal, M., Lin, X., Baksys, M., Liu, J., Santos, M. D., Sung, F., Vinyes, M., Ying, Z., Zhu, Z., et al. Kimina-prover preview: Towards large formal reasoning models with reinforcement learning.arXiv preprint arXiv:2504.11354, 2025
-
[36]
Wei, A., Suresh, T., Sun, T., Wu, H., Wang, K., and Aiken, A. InvBench: Can LLMs accelerate program verification with invariant synthesis?arXiv preprint arXiv:2509.21629, 2025
-
[37]
Lemur: Integrating large language models in automated program verification
Wu, H., Barrett, C., and Narodytska, N. Lemur: Integrating large language models in automated program verification. InInternational Conference on Learning Representations, 2024
2024
-
[38]
Xie, D., Zheng, M., Liu, X., Wang, J., Wang, C., Tan, L., and Zhang, X. CoRe: Bench- marking LLMs code reasoning capabilities through static analysis tasks.arXiv preprint arXiv:2507.05269, 2025
-
[39]
SatLM: Satisfiability-aided language models using declarative prompting.Advances in Neural Information Processing Systems, 36:45548–45580, 2023
Ye, X., Chen, Q., Dillig, I., and Durrett, G. SatLM: Satisfiability-aided language models using declarative prompting.Advances in Neural Information Processing Systems, 36:45548–45580, 2023
2023
-
[40]
Verina: Benchmarking verifiable code generation.arXiv preprint arXiv:2505.23135, 2025
Ye, Z., Yan, Z., He, J., Kasriel, T., Yang, K., and Song, D. Verina: Benchmarking verifiable code generation.arXiv preprint arXiv:2505.23135, 2025. A CBMC Regression Tests We initially evaluated models on the CBMC regression tests [ 14], a collection of approximately 1,000 self-contained C files where ground truth is established by the CBMC verifier. We c...
-
[41]
‘x ‘ is d ec la red as ‘ un si gne d int ‘ and i n i t i a l i z e d to ‘0 ‘
-
[42]
Then we hit the loop : 24 while ( x < N ) { x += 2; } The loop c o n d i t i o n co mpa re s ‘x ‘ ( which is ‘0 ‘) against ‘N ‘ , but ‘N ‘ has never been as sig ne d any value
‘N ‘ is d ec la red as ‘ un si gne d short ‘ but ** never i n i t i a l i z e d ** -- it holds an i n d e t e r m i n a t e value . Then we hit the loop : 24 while ( x < N ) { x += 2; } The loop c o n d i t i o n co mpa re s ‘x ‘ ( which is ‘0 ‘) against ‘N ‘ , but ‘N ‘ has never been as sig ne d any value . Reading ‘N ‘ here is a c c e s s i n g u n i n ...
-
[43]
** U n i n i t i a l i z e d read of ‘N ‘** -- u n d e f i n e d be hav io r at the loop c o n d i t i o n
-
[44]
The r e a c h a b i l i t y of the error is g u a r a n t e e d r e g a r d l e s s of the value of ‘N ‘
** A s s e r t i o n v i o l a t i o n ** -- even ig no rin g the UB , ‘x ‘ is always even , so ‘x % 2 ‘ is always ‘0 ‘ , and the a s s e r t i o n will always fail . The r e a c h a b i l i t y of the error is g u a r a n t e e d r e g a r d l e s s of the value of ‘N ‘. The informalized trace presents the analysis in natural language with explicit reaso...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.