Recognition: unknown
OPSD Compresses What RLVR Teaches: A Post-RL Compaction Stage for Reasoning Models
Pith reviewed 2026-05-08 10:15 UTC · model grok-4.3
The pith
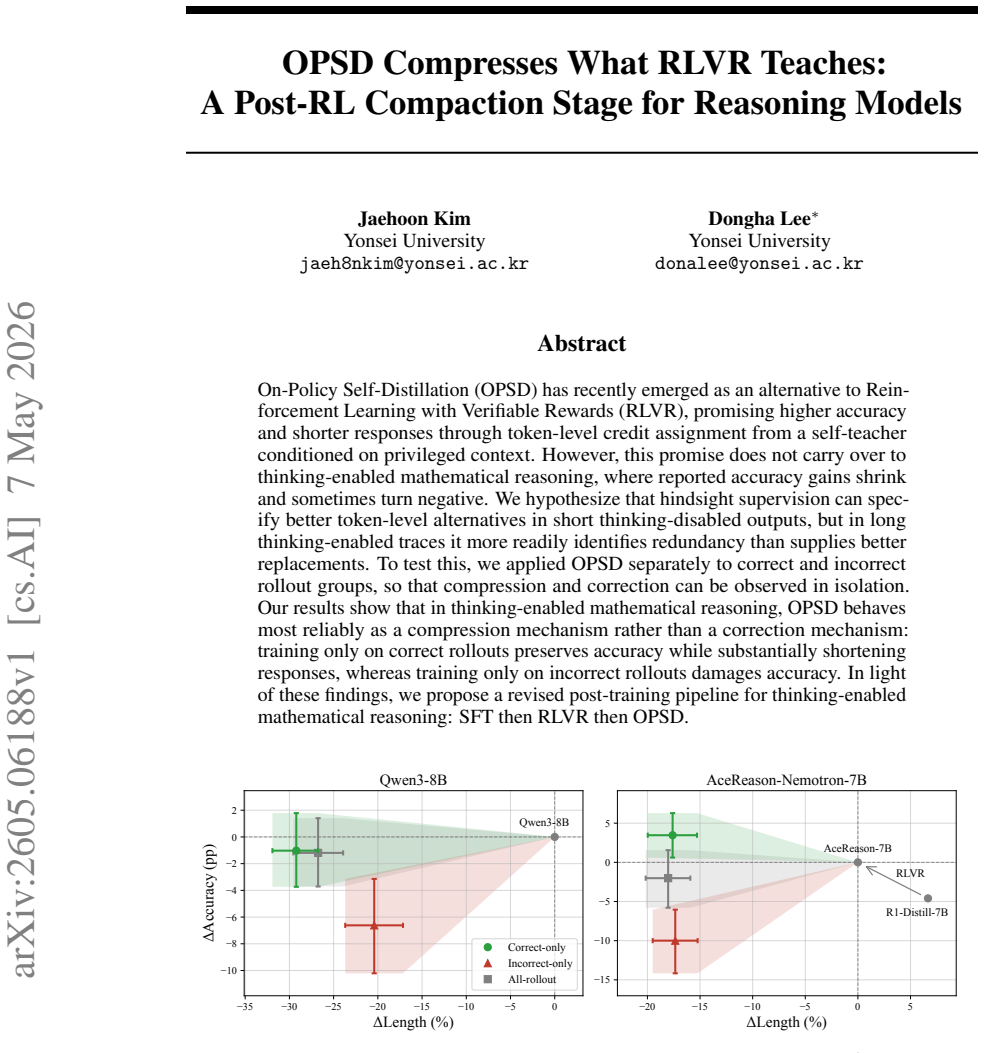
OPSD acts primarily as a compression tool for long reasoning traces in mathematical tasks after RLVR training, preserving accuracy when using only correct outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In thinking-enabled mathematical reasoning, OPSD behaves most reliably as a compression mechanism rather than a correction mechanism: training only on correct rollouts preserves accuracy while substantially shortening responses, whereas training only on incorrect rollouts damages accuracy. This supports a revised post-training pipeline of SFT then RLVR then OPSD.
What carries the argument
On-Policy Self-Distillation (OPSD) applied selectively to correct rollouts after RLVR, which identifies redundant tokens in long thinking traces through hindsight supervision.
If this is right
- Training on correct rollouts with OPSD shortens responses substantially without accuracy loss.
- Training on incorrect rollouts with OPSD leads to accuracy degradation.
- The proposed pipeline SFT then RLVR then OPSD provides a way to achieve both high performance and efficient inference in reasoning models.
- OPSD identifies redundancy more readily than better token alternatives in long traces.
Where Pith is reading between the lines
- Such compaction could enable running larger models under fixed compute budgets during deployment.
- Similar separation of compression and correction effects might benefit other self-distillation methods in long-horizon tasks.
- Further iterations of OPSD on the already compressed outputs could yield additional length reductions if the pattern holds.
Load-bearing premise
The separation of correct and incorrect rollouts cleanly isolates the compression effect from any correction effect in the OPSD training process.
What would settle it
If applying OPSD to correct rollouts after RLVR results in either no significant shortening of responses or a drop in accuracy on math benchmarks, the claim that it acts as a reliable compression mechanism would be falsified.
Figures



read the original abstract
On-Policy Self-Distillation (OPSD) has recently emerged as an alternative to Reinforcement Learning with Verifiable Rewards (RLVR), promising higher accuracy and shorter responses through token-level credit assignment from a self-teacher conditioned on privileged context. However, this promise does not carry over to thinking-enabled mathematical reasoning, where reported accuracy gains shrink and sometimes turn negative. We hypothesize that hindsight supervision can specify better token-level alternatives in short thinking-disabled outputs, but in long thinking-enabled traces it more readily identifies redundancy than supplies better replacements. To test this, we applied OPSD separately to correct and incorrect rollout groups, so that compression and correction can be observed in isolation. Our results show that in thinking-enabled mathematical reasoning, OPSD behaves most reliably as a compression mechanism rather than a correction mechanism: training only on correct rollouts preserves accuracy while substantially shortening responses, whereas training only on incorrect rollouts damages accuracy. In light of these findings, we propose a revised post-training pipeline for thinking-enabled mathematical reasoning: SFT then RLVR then OPSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that On-Policy Self-Distillation (OPSD) in thinking-enabled mathematical reasoning primarily acts as a compression mechanism rather than a correction mechanism. By isolating OPSD training on correct versus incorrect RLVR rollouts, the authors show that training only on correct rollouts preserves accuracy while substantially shortening responses, whereas training only on incorrect rollouts damages accuracy. They hypothesize that hindsight supervision in long traces favors redundancy removal over error correction and propose a revised pipeline of SFT then RLVR then OPSD.
Significance. If the results hold, this work provides a clear empirical distinction between compression and correction effects of OPSD in long reasoning traces, with the isolated rollout-group design offering a direct test of the hypothesis. The finding that post-RLVR OPSD on correct traces shortens outputs without accuracy loss could support more efficient post-training pipelines for reasoning models. The absence of free parameters or circular derivations in the core test is a strength.
major comments (1)
- [Abstract / Results] The abstract and results description report directional outcomes consistent with the hypothesis but provide no details on baselines, statistical significance testing, model sizes, or data volumes used in the split-rollout experiments. This information is load-bearing for assessing whether the accuracy preservation and shortening effects are robust.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and the recommendation for minor revision. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract / Results] The abstract and results description report directional outcomes consistent with the hypothesis but provide no details on baselines, statistical significance testing, model sizes, or data volumes used in the split-rollout experiments. This information is load-bearing for assessing whether the accuracy preservation and shortening effects are robust.
Authors: We agree that including these details would strengthen the presentation and allow for better assessment of robustness. We will revise the abstract and results sections to include information on the baselines used, any statistical significance testing performed, the model sizes, and the data volumes in the split-rollout experiments. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances an empirical hypothesis about OPSD's role in thinking-enabled reasoning by isolating training on correct versus incorrect RLVR rollouts and directly measuring accuracy and length outcomes against the RLVR baseline. No equations, fitted parameters, or derivations are presented that reduce the reported results to the inputs by construction. The proposed pipeline (SFT then RLVR then OPSD) follows from the experimental observations rather than from any self-referential definition or self-citation chain. The work is self-contained against external benchmarks via controlled ablation of rollout groups.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In long thinking-enabled traces, hindsight supervision more readily identifies redundancy than supplies better replacements
Reference graph
Works this paper leans on
-
[14]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Rep- resentations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openrev...
2024
-
[25]
Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and Wenjie Li. Tokenskip: Controllable chain-of-thought compression in LLMs. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3351–3363, Suzhou, China, November 2025. As...
-
[29]
Qian Wan, Ziao Xu, Luona Wei, Xiaoxuan Shen, and Jianwen Sun. Mitigating overthinking in large reasoning models via difficulty-aware reinforcement learning.CoRR, abs/2601.21418,
-
[38]
Long Li, Zhijian Zhou, Jiaran Hao, Jason Klein Liu, Yanting Miao, Wei Pang, Xiaoyu Tan, Wei Chu, Zhe Wang, Shirui Pan, Chao Qu, and Yuan Qi. The choice of divergence: A neglected key to mitigating diversity collapse in reinforcement learning with verifiable reward.CoRR, abs/2509.07430, 2025. doi: 10.48550/ARXIV .2509.07430. URL https://doi.org/10. 48550/a...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[39]
**Rewrite bases:** Convert $4^5$ into $2^{10}$ to create a common factor with $5^{13}$
-
[40]
**Pair exponents:** Combine $2^{10} \cdot 5^{10} = 10^{10}$ and leave $5^3$ as a separate factor
-
[41]
**Simplify:** Multiply $10^{10} \cdot 125$ to get $125$ followed by ten zeros
-
[42]
**Patterns to Recognize:** - **Pair 2s and 5s:** Whenever a product involves $2^n \cdot 5^m$, pairing $2^k \cdot 5^k = 10^k$ simplifies the problem
**Count digits:** Recognize that $125$ (3 digits) plus ten zeros yields a total of **13 digits**. **Patterns to Recognize:** - **Pair 2s and 5s:** Whenever a product involves $2^n \cdot 5^m$, pairing $2^k \cdot 5^k = 10^k$ simplifies the problem. - **Logarithmic verification:** For larger exponents, using $\lfloor \log_{10} N \rfloor + 1$ ensures accuracy...
-
[43]
**Challenge**: Identical bags (no ordering) and the possibility of empty bags complicate the usual distribution methods (e.g., permutations or combinations with labeled containers )
-
[44]
- Use **Stirling numbers of the second kind**, summing $ S(4, 1) + S(4, 2) + S(4, 3) $ to account for all groupings
**Solution Strategy**: - Recognize that even with empty bags allowed, the task reduces to counting all **set partitions** of the 4 items into 1, 2, or 3 subsets (since there are 3 bags). - Use **Stirling numbers of the second kind**, summing $ S(4, 1) + S(4, 2) + S(4, 3) $ to account for all groupings. --- ### **Structural Features to Recognize** - **Iden...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.