Recognition: 2 theorem links
· Lean TheoremRegion Seeding via Pre-Activation Regularization: A Geometric View of Piecewise Affine Neural Networks
Pith reviewed 2026-05-12 01:55 UTC · model grok-4.3
The pith
Bringing neuron switching surfaces close to data points strictly increases the local affine region count in piecewise affine networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our theory provides a sufficient condition under which bringing neuron switching surfaces sufficiently close to data points ensures their intersection with local neighborhoods, which in turn implies a strict increase in the local affine-region count, yielding a principled training-time handle for seeding data-relevant partitions early in optimization. Guided by these results, we propose a plug-and-play region-seeding regularizer that encourages early partitioning while allowing task-driven refinement to dominate later in training.
What carries the argument
The sufficient condition that links proximity of neuron switching surfaces to data points with guaranteed intersection in local neighborhoods, realized by a pre-activation regularizer.
Load-bearing premise
The pre-activation regularizer can be tuned to raise local region count without substantially harming the primary task objective or causing optimization instability.
What would settle it
Applying the regularizer on a dataset where local neighborhoods can be exhaustively enumerated yet producing no measurable increase in realized affine regions, or a large drop in final task performance relative to the unregularized baseline.
Figures



































read the original abstract
Deep networks with continuous piecewise affine activations induce polyhedral partitions of the input space, making the number of realized affine regions a natural measure of expressive capacity and a key determinant of how well the model can approximate nonlinear target functions. In practice, standard training realizes far fewer region refinements in data-visited neighborhoods than the architecture could in principle support, while existing region-count theory is primarily architectural and offers little guidance on how optimization shapes the realized partition near the data. Our theory provides a sufficient condition under which bringing neuron switching surfaces sufficiently close to data points ensures their intersection with local neighborhoods, which in turn implies a strict increase in the local affine-region count, yielding a principled training-time handle for seeding data-relevant partitions early in optimization. Guided by these results, we propose a plug-and-play region-seeding regularizer that encourages early partitioning while allowing task-driven refinement to dominate later in training. Experiments show that the regularizer increases the number of realized affine regions via exact enumeration and improves overall performance on toy datasets, while also improving early-stage accuracy and achieving comparable (or slightly improved) final accuracy on ImageNet-1k for classical models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives a geometric sufficient condition under which positioning neuron switching surfaces sufficiently close to data points guarantees their intersection with local neighborhoods, thereby strictly increasing the local affine-region count in piecewise-affine networks. Guided by this condition, it introduces a plug-and-play pre-activation regularizer intended to seed data-relevant partitions early in training while permitting later task-driven refinement. Experiments report increased exact-enumerated region counts on toy datasets together with improved early-stage and final accuracy on ImageNet-1k for standard architectures.
Significance. If the regularizer can be shown to enforce the derived closeness threshold without destabilizing the primary objective, the work supplies a concrete, training-time mechanism for shaping the data-dependent expressive capacity of deep networks, moving beyond purely architectural region-count bounds and offering a falsifiable handle on partition refinement.
major comments (3)
- [§3] §3 (sufficient condition): The geometric argument establishes that closeness of switching surfaces to data points implies local region increase, yet the manuscript never derives that the proposed pre-activation regularizer (Eq. (8) or equivalent) enforces the required distance threshold; the theory-to-practice link is therefore asserted rather than proven.
- [§5] §5 (experiments): Exact enumeration of affine regions on toy data is reported to increase, but no description of the enumeration algorithm, its computational limits, or controls that isolate the regularizer from generic smoothing effects is supplied; this leaves open whether the observed gain is mechanistically tied to the sufficient condition.
- [§4] §4 (regularizer): The claim that the method is 'plug-and-play' and allows task-driven refinement to dominate later is not supported by any analysis or ablation showing that the regularization coefficient can be scheduled without harming convergence or final performance on large-scale models.
minor comments (2)
- [§2-3] Notation for the local neighborhood radius and the switching-surface distance is introduced without a single consolidated definition table, making cross-references between the geometric condition and the regularizer loss cumbersome.
- [Figures] Figure captions for the toy-data visualizations do not state the precise value of the regularization coefficient used or whether the plotted partitions correspond to the same training epoch across panels.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped strengthen the presentation of our work. We address each major comment point by point below, indicating revisions where the manuscript will be updated in the next version.
read point-by-point responses
-
Referee: [§3] §3 (sufficient condition): The geometric argument establishes that closeness of switching surfaces to data points implies local region increase, yet the manuscript never derives that the proposed pre-activation regularizer (Eq. (8) or equivalent) enforces the required distance threshold; the theory-to-practice link is therefore asserted rather than proven.
Authors: We agree that the link is motivational rather than a formal derivation of enforcement. Section 3 provides a sufficient geometric condition: if neuron switching surfaces lie sufficiently close to data points, they intersect local neighborhoods and strictly increase the local affine-region count. The pre-activation regularizer (Eq. 8) is introduced as a practical, plug-and-play penalty that encourages small pre-activations on data samples, thereby pushing surfaces toward data in an optimization-friendly manner. We do not claim or prove that the regularizer always enforces the exact distance threshold, given the non-convex training dynamics. In the revised manuscript we have updated Section 3 to explicitly label the regularizer as guided by the sufficient condition and added a clarifying remark on its heuristic character, removing any implication of strict enforcement. revision: partial
-
Referee: [§5] §5 (experiments): Exact enumeration of affine regions on toy data is reported to increase, but no description of the enumeration algorithm, its computational limits, or controls that isolate the regularizer from generic smoothing effects is supplied; this leaves open whether the observed gain is mechanistically tied to the sufficient condition.
Authors: The referee correctly identifies missing methodological details. In the revised experimental section we now describe the exact enumeration procedure (recursive traversal of the hyperplane arrangement induced by the neuron decision boundaries, feasible only for low-dimensional toy inputs), its computational limits (exponential in the number of hyperplanes, hence restricted to small networks and input dimensions), and control experiments that compare against generic smoothing baselines such as weight decay. These controls demonstrate that the reported increase in enumerated regions is attributable to the pre-activation mechanism rather than generic regularization effects, thereby strengthening the connection to the sufficient condition in Section 3. revision: yes
-
Referee: [§4] §4 (regularizer): The claim that the method is 'plug-and-play' and allows task-driven refinement to dominate later is not supported by any analysis or ablation showing that the regularization coefficient can be scheduled without harming convergence or final performance on large-scale models.
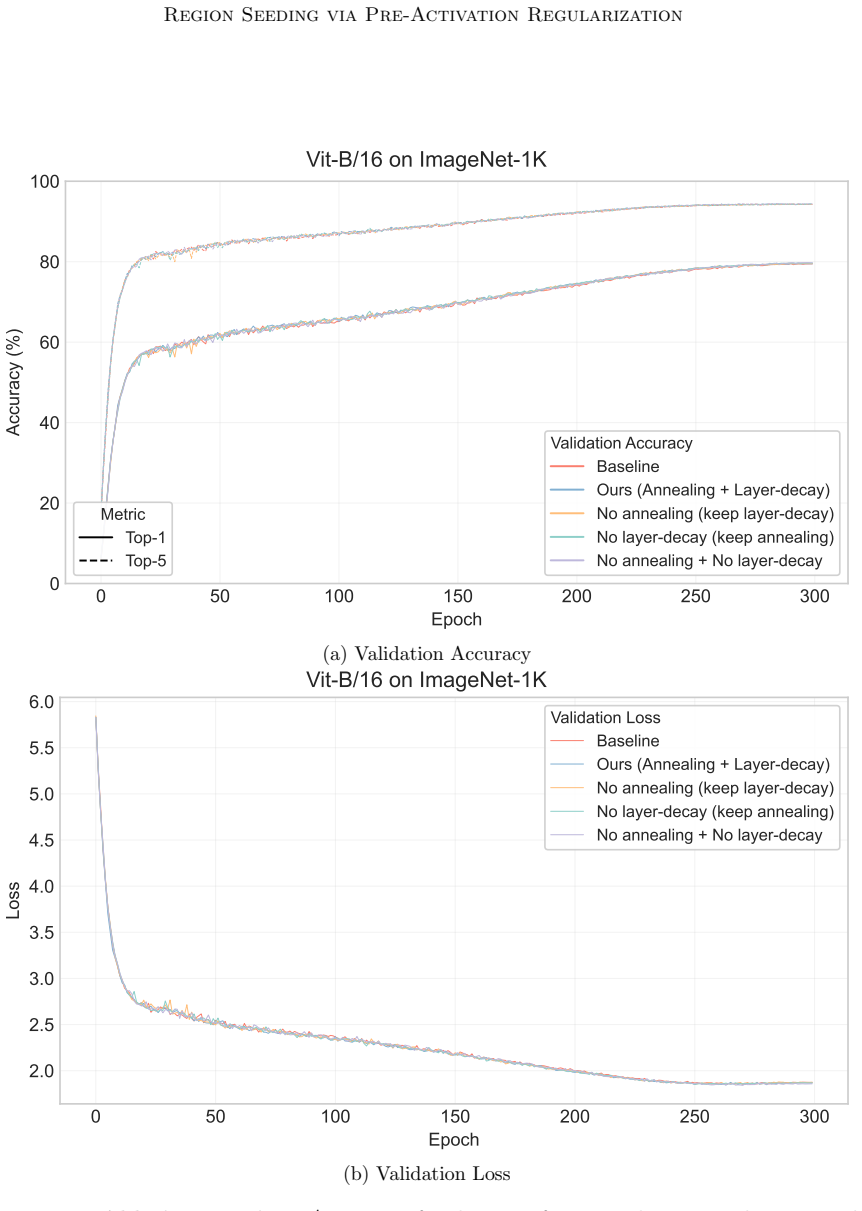
Authors: We acknowledge that the original manuscript lacked explicit scheduling ablations on large-scale models. The 'plug-and-play' claim refers to the regularizer being a simple additive term to any existing loss without architectural modification. In the revised manuscript we have added an ablation study (Section 4 and appendix) on ImageNet-1k that examines linear annealing of the regularization coefficient to zero after the first 20–30 epochs. The results show that convergence speed and final top-1 accuracy remain comparable to or slightly better than the unregularized baseline, supporting that task-driven refinement can dominate in later stages without destabilization. This provides the requested empirical support for schedulability. revision: yes
Circularity Check
Geometric sufficient condition derived independently; no reduction to inputs by construction
full rationale
The paper's core derivation supplies a sufficient geometric condition (switching surfaces near data points imply local neighborhood intersection and strict increase in affine-region count) that stands on its own as a mathematical statement about piecewise-affine partitions. The pre-activation regularizer is introduced afterward as a practical, plug-and-play implementation guided by the condition, not as a redefinition or fitted proxy of the region-count target itself. No equations equate the regularizer objective to the derived count by construction, no self-citations bear the central premise, and no parameter fitted to data is later relabeled a prediction. The theory-to-practice link remains empirical, but the derivation chain itself is self-contained and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization coefficient
axioms (1)
- domain assumption Networks with continuous piecewise affine activations induce polyhedral partitions of the input space.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Local region growth from additional zero-set intersections) … N_ε(x;J) ≥ 1 + I_ε(x;J)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 … |z_ℓ,i(x)| < δ_ε(x; a_ℓ,i) ‖a_ℓ,i‖ implies Z_ℓ,i ∩ int(P_ε(x)) ≠ ∅
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On the Number of Linear Regions of Deep Neural Networks , booktitle =
Guido Mont. On the Number of Linear Regions of Deep Neural Networks , booktitle =
-
[2]
Advances in Neural Information Processing Systems , volume =
Boris Hanin and David Rolnick , title =. Advances in Neural Information Processing Systems , volume =
-
[3]
Randall Balestriero and Richard G. Baraniuk , title =. Proc. Int. Conf. Mach. Learn. (. 2018 , publisher =
work page 2018
-
[4]
Advances in Neural Information Processing Systems , year=
The Computational Complexity of Counting Linear Regions in ReLU Neural Networks , author=. Advances in Neural Information Processing Systems , year=
-
[5]
Proceedings of the 27th international conference on machine learning (ICML-10) , pages=
Rectified linear units improve restricted boltzmann machines , author=. Proceedings of the 27th international conference on machine learning (ICML-10) , pages=
-
[6]
Andrew L. Maas and Awni Y. Hannun and Andrew Y. Ng , title =. Proc. 2013 , address =
work page 2013
-
[7]
Gaussian Error Linear Units (GELUs)
Gaussian Error Linear Units (Gelus) , author=. arXiv preprint arXiv:1606.08415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
On the Expected Complexity of Maxout Networks , booktitle =
Hanna Tseran and Guido Mont. On the Expected Complexity of Maxout Networks , booktitle =
-
[9]
Arturs Berzins , title =. Proc. Int. Conf. Mach. Learn. (. 2023 , publisher =
work page 2023
-
[10]
Ahmed Imtiaz Humayun and Randall Balestriero and Guha Balakrishnan and Richard G. Baraniuk , title =. Proc. 2023 , publisher =
work page 2023
-
[11]
Hao Chen and Yu Guang Wang and Huan Xiong , title =. Neural Networks , volume =. 2023 , doi =
work page 2023
-
[12]
Huan Xiong and Lei Huang and Wenston J. T. Zang and Xiantong Zhen and Guo-Sen Xie and Bin Gu and Le Song , title =. 2024 , doi =
work page 2024
-
[13]
Pawel Piwek and Adam Klukowski and Tianyang Hu , title =. Proc. Conf. Uncertainty in Artificial Intelligence (. 2023 , publisher =
work page 2023
-
[14]
On the Local Complexity of Linear Regions in Deep
Niket Patel and Guido Mont. On the Local Complexity of Linear Regions in Deep. Proc. Int. Conf. Mach. Learn. (. 2025 , publisher =
work page 2025
-
[15]
Advances in Neural Information Processing Systems , volume =
Setareh Cohan and Nam Hee Kim and David Rolnick and Michiel van de Panne , title =. Advances in Neural Information Processing Systems , volume =
-
[16]
Elisenda Grigsby and Kathryn Lindsey , title =
J. Elisenda Grigsby and Kathryn Lindsey , title =. 2022 , doi =
work page 2022
-
[17]
Alexis Goujon and Arian Etemadi and Michael Unser , title =. J. Comput. Appl. Math. , volume =. 2024 , doi =
work page 2024
-
[18]
Jeong and David Rolnick , title =
Boris Hanin and Ryan S. Jeong and David Rolnick , title =. Proc. Int. Conf. Learn. Represent. (. 2022 , publisher =
work page 2022
-
[19]
Yuan Wang , title =. Proc. Int. Joint Conf. Artif. Intell. (. 2022 , publisher =
work page 2022
-
[20]
Advances in Neural Information Processing Systems , volume =
Saket Tiwari and George Konidaris , title =. Advances in Neural Information Processing Systems , volume =
-
[21]
David Rolnick and Konrad P. Kording , title =. Proc. Int. Conf. Mach. Learn. (. 2020 , publisher =
work page 2020
-
[22]
Xiao Zhang and Dongrui Wu , title =. Proc. Int. Conf. Learn. Represent. (. 2020 , publisher =
work page 2020
-
[23]
Martin Trimmel and Henning Petzka and Cristian Sminchisescu , title =. Proc. Int. Conf. Learn. Represent. (. 2021 , publisher =
work page 2021
-
[24]
Journal of Computational Mathematics , volume =
Juncai He and Lin Li and Jinchao Xu and Chunyue Zheng , title =. Journal of Computational Mathematics , volume =. 2020 , doi =
work page 2020
-
[25]
Christoph Hertrich and Amitabh Basu and Marco Di Summa and Martin Skutella , title =. 2023 , doi =
work page 2023
-
[26]
Kuan-Lin Chen and Harinath Garudadri and Bhaskar D. Rao , title =. Advances in Neural Information Processing Systems , volume =
-
[27]
Christian Haase and Christoph Hertrich and Georg Loho , title =. Proc. Int. Conf. Learn. Represent. (. 2023 , publisher =
work page 2023
-
[28]
Gennadiy Averkov and Christopher Hojny and Maximilian Merkert , title =. Proc. Int. Conf. Learn. Represent. (. 2025 , publisher =
work page 2025
-
[29]
Qiang Hu and Hao Zhang and Feifei Gao and Chengwen Xing and Jianping An , title =. 2022 , doi =
work page 2022
-
[30]
Max Milkert and David Hyde and Forrest J. Laine , title =. Proc. Int. Conf. Mach. Learn. (. 2025 , publisher =
work page 2025
-
[31]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[32]
International conference on machine learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[33]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
work page 2009
-
[34]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Very deep convolutional networks for large-scale image recognition , author=. arXiv preprint arXiv:1409.1556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [36]
- [37]
-
[38]
the Journal of machine Learning research , volume=
Scikit-learn: Machine learning in Python , author=. the Journal of machine Learning research , volume=. 2011 , publisher=
work page 2011
-
[39]
International Conference on Neural Information Processing , pages=
Comparative analysis of the linear regions in ReLU and LeakyReLU networks , author=. International Conference on Neural Information Processing , pages=. 2023 , organization=
work page 2023
-
[40]
International Conference on Artificial Neural Networks , pages=
Empirical Study on the Effect of Residual Networks on the Expressiveness of Linear Regions , author=. International Conference on Artificial Neural Networks , pages=. 2023 , organization=
work page 2023
-
[41]
arXiv preprint arXiv:2310.18725 , year=
The Evolution of the Interplay Between Input Distributions and Linear Regions in Networks , author=. arXiv preprint arXiv:2310.18725 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.