Recognition: unknown
ORTHOBO: Orthogonal Bayesian Hyperparameter Optimization
Pith reviewed 2026-05-08 12:47 UTC · model grok-4.3
The pith
An orthogonal acquisition estimator reduces Monte Carlo variance in Bayesian optimization by subtracting a score-function control variate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose an orthogonal acquisition estimator that subtracts an optimally weighted score-function control variate, which yields an acquisition residual orthogonal to posterior score directions and which thus reduces Monte Carlo variance. We further introduce OrthoBO: a Bayesian optimization framework that combines our orthogonal acquisition estimator with ensemble surrogates and an outer log transformation. We show theoretically that our estimator preserves the target, leads to variance reduction, and improves pairwise ranking stability.
What carries the argument
The orthogonal acquisition estimator, which subtracts an optimally weighted score-function control variate to yield a residual orthogonal to posterior score directions, reducing Monte Carlo variance in acquisition estimates.
If this is right
- The estimator preserves the expected value of the original acquisition function.
- Monte Carlo variance in acquisition estimates is reduced.
- Pairwise ranking stability of candidates improves.
- OrthoBO achieves strong performance in hyperparameter optimization for neural network training and fine-tuning.
Where Pith is reading between the lines
- This variance reduction technique could extend to other sampling-based decision processes in machine learning.
- Integrating orthogonality into control variates might apply to policy gradient methods in reinforcement learning.
- Existing Bayesian optimization implementations could adopt this estimator by modifying only the acquisition evaluation step.
Load-bearing premise
An optimally weighted score-function control variate can be computed such that the acquisition residual is orthogonal to the posterior score directions for typical acquisition functions and surrogate models.
What would settle it
Running the orthogonal estimator on standard benchmark acquisition functions and observing no reduction in empirical variance or no improvement in ranking stability compared to standard Monte Carlo estimation would falsify the central claim.
Figures












read the original abstract
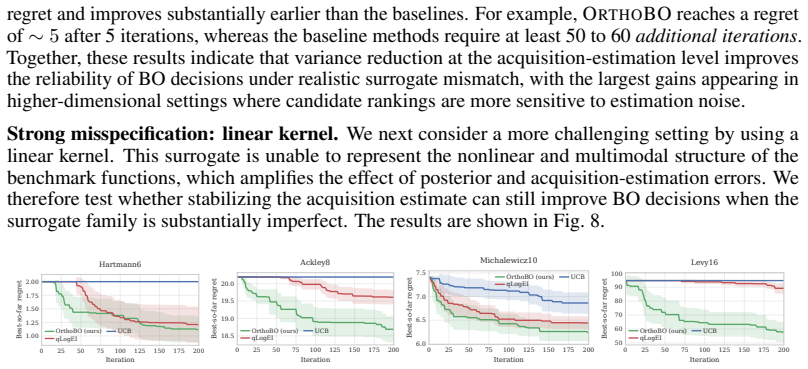
Bayesian optimization is widely used for hyperparameter optimization when model evaluations are expensive; however, noisy acquisition estimates can lead to unstable decisions. We identify acquisition estimation noise as a failure mode that was previously overlooked: even when the surrogate model and acquisition target are correctly specified, finite-sample Monte Carlo error can perturb acquisition values. This can, in turn, flip candidate rankings and lead to suboptimal BO decisions. As a remedy, we aim at variance reduction and propose an orthogonal acquisition estimator that subtracts an optimally weighted score-function control variate, which yields an acquisition residual orthogonal to posterior score directions and which thus reduces Monte Carlo variance. We further introduce OrthoBO: a Bayesian optimization framework that combines our orthogonal acquisition estimator with ensemble surrogates and an outer log transformation. We show theoretically that our estimator preserves the target, leads to variance reduction, and improves pairwise ranking stability. We further verify the theoretical properties of OrthoBO through numerical experiments where our framework reduces acquisition estimation variance, stabilizes candidate rankings, and achieves strong performance. We also demonstrate the downstream utility of OrthoBO in hyperparameter optimization for neural network training and fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes OrthoBO, a Bayesian optimization framework for hyperparameter tuning that addresses acquisition estimation noise via an orthogonal acquisition estimator. This estimator subtracts an optimally weighted score-function control variate to yield an acquisition residual orthogonal to posterior score directions, with the goal of reducing Monte Carlo variance. The approach is combined with ensemble surrogates and an outer log transformation. Theoretical claims include preservation of the target acquisition value, variance reduction, and improved pairwise ranking stability; these are supported by numerical experiments and demonstrated on neural network training and fine-tuning tasks.
Significance. If the variance reduction and ranking stability hold in finite-sample regimes without being offset by covariance estimation costs, the orthogonal control variate construction could improve decision stability in Bayesian optimization for expensive black-box functions. The integration with ensemble surrogates offers a practical extension, and the focus on an overlooked noise source in acquisition estimates provides a targeted contribution to the BO literature.
major comments (2)
- [Abstract and Theoretical Claims] Abstract and theoretical claims: the manuscript states that the estimator 'preserves the target, leads to variance reduction, and improves pairwise ranking stability' and that this is shown theoretically. However, the optimal weight β = Cov(â, s)/Var(s) must be known exactly to guarantee orthogonality and net variance reduction. For the ensemble surrogates used in OrthoBO (non-analytic posteriors), both covariance and variance must be estimated from the same finite MC samples as the acquisition itself; the resulting second-order estimation error is not bounded in the provided theoretical statements, so the residual need not remain orthogonal and variance reduction can vanish or reverse in typical BO sample regimes.
- [Numerical Experiments] Numerical experiments section: the abstract and manuscript mention verification of variance reduction, ranking stability, and strong performance, but provide no details on experimental setup, baselines, number of independent runs, or statistical significance testing. This prevents assessment of whether the reported improvements are robust or attributable to the orthogonal estimator rather than other design choices such as the ensemble or log transform.
minor comments (1)
- [Abstract] The abstract could more explicitly note that the theoretical guarantees assume exact knowledge of the control variate weight while the practical implementation relies on sample estimates.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify areas where the theoretical claims require clarification regarding finite-sample estimation and where the experimental section needs expanded details for reproducibility. We address both points below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Theoretical Claims] Abstract and theoretical claims: the manuscript states that the estimator 'preserves the target, leads to variance reduction, and improves pairwise ranking stability' and that this is shown theoretically. However, the optimal weight β = Cov(â, s)/Var(s) must be known exactly to guarantee orthogonality and net variance reduction. For the ensemble surrogates used in OrthoBO (non-analytic posteriors), both covariance and variance must be estimated from the same finite MC samples as the acquisition itself; the resulting second-order estimation error is not bounded in the provided theoretical statements, so the residual need not remain orthogonal and variance reduction can vanish or reverse in typical BO sample regimes.
Authors: We agree that the theoretical statements establish orthogonality and variance reduction under the assumption that the optimal weight β is known exactly. In the practical setting with ensemble surrogates, β is estimated from the same finite Monte Carlo samples, and the manuscript does not provide a bound on the resulting estimation error. We will revise the abstract, introduction, and theoretical section to explicitly distinguish the ideal (known-β) case from the estimated-β implementation, clarify that the unbiasedness of the estimator is preserved regardless of β, and add a short discussion of the finite-sample regime supported by the numerical results. We will also include a brief remark that empirical evidence indicates net variance reduction is retained in the sample sizes used for acquisition estimation. revision: partial
-
Referee: [Numerical Experiments] Numerical experiments section: the abstract and manuscript mention verification of variance reduction, ranking stability, and strong performance, but provide no details on experimental setup, baselines, number of independent runs, or statistical significance testing. This prevents assessment of whether the reported improvements are robust or attributable to the orthogonal estimator rather than other design choices such as the ensemble or log transform.
Authors: We acknowledge that the current experimental section lacks sufficient detail for full assessment. We will expand this section to include: (i) complete description of the experimental setup and hyperparameter ranges, (ii) explicit list of baselines with implementation references, (iii) the number of independent runs performed (currently 20 per task), and (iv) the statistical significance tests applied (paired Wilcoxon signed-rank tests with reported p-values). We will also add an ablation study isolating the orthogonal estimator from the ensemble surrogate and log transform to demonstrate its specific contribution to variance reduction and ranking stability. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper introduces an orthogonal acquisition estimator via subtraction of an optimally weighted score-function control variate, yielding a residual orthogonal to posterior score directions by direct construction from standard control-variate theory. Theoretical guarantees (target preservation, variance reduction, ranking stability) follow from the orthogonality property under the stated assumptions without reducing to fitted inputs or self-referential definitions. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided derivation steps; the estimator is presented as an independent variance-reduction technique applied to BO acquisition functions. Practical estimation of the weight is treated as a separate implementation detail rather than a definitional step that forces the claimed result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Finite-sample Monte Carlo estimates of acquisition functions can be improved via score-function control variates that are orthogonal to posterior score directions.
Reference graph
Works this paper leans on
-
[1]
AlBahar, I
A. AlBahar, I. Kim, and X. Yue. A robust asymmetric kernel function for Bayesian optimization, with application to image defect detection in manufacturing systems.IEEE Transactions on Automation Science and Engineering, 19(4):3222–3233, 2021
2021
-
[2]
Ament, S
S. Ament, S. Daulton, D. Eriksson, M. Balandat, and E. Bakshy. Unexpected improvements to expected improvement for Bayesian optimization. InNeural Information Processing Systems (NeurIPS), 2023
2023
-
[3]
Ament, E
S. Ament, E. Santorella, D. Eriksson, B. Letham, M. Balandat, and E. Bakshy. Robust Gaussian processes via relevance pursuit. InNeural Information Processing Systems (NeurIPS), 2024
2024
-
[4]
Balandat, B
M. Balandat, B. Karrer, D. Jiang, S. Daulton, B. Letham, A. G. Wilson, and E. Bakshy. Botorch: A framework for efficient Monte-Carlo Bayesian optimization. InNeural Information Processing Systems (NeurIPS), 2020
2020
-
[5]
T. Ban, M. Ohue, and Y . Akiyama. Efficient hyperparameter optimization by using Bayesian op- timization for drug-target interaction prediction. InInternational Conference on Computational Advances in Bio and Medical Sciences (ICCABS), 2017
2017
-
[6]
Bergstra, R
J. Bergstra, R. Bardenet, Y . Bengio, and B. Kégl. Algorithms for hyper-parameter optimization. InNeural Information Processing Systems (NeurIPS), 2011
2011
-
[7]
Bergstra, D
J. Bergstra, D. Yamins, and D. Cox. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. InInternational Conference on Machine Learning (ICML), 2013
2013
-
[8]
Berkenkamp, A
F. Berkenkamp, A. P. Schoellig, and A. Krause. No-regret Bayesian optimization with unknown hyperparameters.Journal of Machine Learning Research, 20(50):1–24, 2019
2019
-
[9]
P. J. Bickel, C. A. Klaassen, P. J. Bickel, Y . Ritov, J. Klaassen, J. A. Wellner, and Y . Ritov. Efficient and adaptive estimation for semiparametric models, volume 4. Springer, 1993
1993
-
[10]
Bodin, M
E. Bodin, M. Kaiser, I. Kazlauskaite, Z. Dai, N. Campbell, and C. H. Ek. Modulating surrogates for Bayesian optimization. InInternational Conference on Machine Learning (ICML), 2020
2020
-
[11]
Bogunovic and A
I. Bogunovic and A. Krause. Misspecified Gaussian process bandit optimization. InNeural Information Processing Systems (NeurIPS), 2021
2021
-
[12]
Chernozhukov, D
V . Chernozhukov, D. Chetverikov, M. Demirer, E. Duflo, C. Hansen, W. Newey, and J. Robins. Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal, 21:C1–C68, 2018
2018
-
[13]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[15]
Eriksson and M
D. Eriksson and M. Poloczek. Scalable constrained Bayesian optimization. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2021
2021
-
[16]
Eriksson, M
D. Eriksson, M. Pearce, J. Gardner, R. D. Turner, and M. Poloczek. Scalable global optimization via local Bayesian optimization. InNeural Information Processing Systems (NeurIPS), 2019
2019
-
[17]
Falkner, A
S. Falkner, A. Klein, and F. Hutter. BOHB: Robust and efficient hyperparameter optimization at scale. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[18]
Fedus, B
W. Fedus, B. Zoph, and N. Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[19]
Feurer, A
M. Feurer, A. Klein, K. Eggensperger, J. Springenberg, M. Blum, and F. Hutter. Efficient and robust automated machine learning. InNeural Information Processing Systems (NeurIPS), 2015
2015
-
[20]
D. J. Foster and V . Syrgkanis. Orthogonal statistical learning.The Annals of Statistics, 51(3): 879–908, 2023. 11
2023
-
[21]
Frauen, M
D. Frauen, M. Schröder, K. Hess, and S. Feuerriegel. Orthogonal survival learners for estimating heterogeneous treatment effects from time-to-event data. InNeural Information Processing Systems (NeurIPS), 2025
2025
- [22]
-
[23]
P. I. Frazier. Bayesian optimization. InRecent advances in optimization and modeling of contemporary problems, pages 255–278. 2018
2018
-
[24]
P. I. Frazier. A tutorial on Bayesian optimization.arXiv preprint, arXiv:1807.02811, 2018
work page internal anchor Pith review arXiv 2018
-
[25]
Freund and R
Y . Freund and R. E. Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of Computer and System Sciences, 55(1):119–139, 1997
1997
-
[26]
González, Z
J. González, Z. Dai, P. Hennig, and N. Lawrence. Batch Bayesian optimization via local penalization. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2016
2016
- [27]
-
[28]
Herbster and M
M. Herbster and M. K. Warmuth. Tracking the best expert.Machine learning, 32(2):151–178, 1998
1998
-
[29]
J. M. Hernández-Lobato, M. W. Hoffman, and Z. Ghahramani. Predictive entropy search for efficient global optimization of black-box functions. InNeural Information Processing Systems (NeurIPS), 2014
2014
-
[30]
J. M. Hernández-Lobato, M. Gelbart, M. Hoffman, R. Adams, and Z. Ghahramani. Predictive entropy search for Bayesian optimization with unknown constraints. InInternational Conference on Machine Learning (ICML), 2015
2015
-
[31]
K. Hess, D. Frauen, N. Kilbertus, and S. Feuerriegel. Debiased neural operators for estimating functionals.arXiv preprint, arXiv:2604.19296, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts. Neural Computation, 3(1):79–87, 1991
1991
-
[33]
J.-S. R. Jang. Mir-wm811k: Dataset for wafer map failure pattern recognition. http:// mirlab.org/dataset/public/, 2015
2015
-
[34]
D. R. Jones, M. Schonlau, and W. J. Welch. Efficient global optimization of expensive black-box functions.Journal of Global Optimization, 13(4):455–492, 1998
1998
-
[35]
E. H. Kennedy. Semiparametric doubly robust targeted double machine learning: a review. Handbook of Statistical Methods for Precision Medicine, pages 207–236, 2024
2024
-
[36]
Krizhevsky
A. Krizhevsky. Learning multiple layers of features from tiny images. Technical report, 2009
2009
-
[37]
LeCun, C
Y . LeCun, C. Cortes, and C. Burges. Mnist handwritten digit database.ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010
2010
-
[38]
Q. Lu, K. D. Polyzos, B. Li, and G. B. Giannakis. Surrogate modeling for Bayesian optimization beyond a single Gaussian process.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):11283–11296, 2023
2023
-
[39]
Mackey, V
L. Mackey, V . Syrgkanis, and I. Zadik. Orthogonal machine learning: Power and limitations. In International Conference on Machine Learning (ICML), 2018
2018
-
[40]
Martinez-Cantin, K
R. Martinez-Cantin, K. Tee, and M. McCourt. Practical Bayesian optimization in the presence of outliers. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2018
2018
-
[41]
V . Melnychuk and S. Feuerriegel. GDR-learners: Orthogonal learning of generative models for potential outcomes.arXiv preprint, arXiv:2509.22953, 2025
-
[42]
H. B. Moss, D. S. Leslie, J. Gonzalez, and P. Rayson. GIBBON: General-purpose information- based Bayesian optimisation.Journal of Machine Learning Research, 22(235):1–49, 2021
2021
-
[43]
H. B. Moss, S. W. Ober, and V . Picheny. Inducing point allocation for sparse Gaussian processes in high-throughput Bayesian optimisation. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2023. 12
2023
-
[44]
V . Nath, D. Yang, A. Hatamizadeh, A. A. Abidin, A. Myronenko, H. R. Roth, and D. Xu. The power of proxy data and proxy networks for hyper-parameter optimization in medical image segmentation. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, 2021
2021
-
[45]
Neiswanger and A
W. Neiswanger and A. Ramdas. Uncertainty quantification using martingales for misspecified Gaussian processes. InInternational Conference on Algorithmic Learning Theory (ALT), 2021
2021
-
[46]
Nie and S
X. Nie and S. Wager. Quasi-oracle estimation of heterogeneous treatment effects.Biometrika, 108(2):299–319, 2021
2021
-
[47]
Oprescu, V
M. Oprescu, V . Syrgkanis, and Z. S. Wu. Orthogonal random forest for causal inference. In International Conference on Machine Learning (ICML), 2019
2019
-
[48]
K. D. Polyzos, Q. Lu, and G. B. Giannakis. Bayesian optimization with ensemble learning models and adaptive expected improvement. InInternational Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
2023
-
[49]
Quitadadmo, J
A. Quitadadmo, J. Johnson, and X. Shi. Bayesian hyperparameter optimization for machine learning based eqtl analysis. InInternational Conference on Bioinformatics, Computational Biology, and Health Informatics, 2017
2017
-
[50]
J. M. Robins, A. Rotnitzky, and L. P. Zhao. Estimation of regression coefficients when some regressors are not always observed.Journal of the American Statistical Association, 89(427): 846–866, 1994
1994
-
[51]
J. M. Robins, M. A. Hernan, and B. Brumback. Marginal structural models and causal inference in epidemiology.Epidemiology, 11(5):550–560, 2000
2000
-
[52]
Schröder, V
M. Schröder, V . Melnychuk, and S. Feuerriegel. Differentially private learners for heterogeneous treatment effects.International Conference on Learning Representations (ICLR), 2025
2025
-
[53]
Shahriari, K
B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. De Freitas. Taking the human out of the loop: A review of Bayesian optimization.Proceedings of the IEEE, 104(1):148–175, 2016
2016
-
[54]
Shazeer, A
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[55]
Snoek, H
J. Snoek, H. Larochelle, and R. P. Adams. Practical Bayesian optimization of machine learning algorithms. InNeural Information Processing Systems (NeurIPS), 2012
2012
-
[56]
Srinivas, A
N. Srinivas, A. Krause, S. M. Kakade, and M. Seeger. Gaussian process optimization in the bandit setting: No regret and experimental design. InInternational Conference on Machine Learning (ICML), 2010
2010
-
[57]
Tani and C
L. Tani and C. Veelken. Comparison of Bayesian and particle swarm algorithms for hyper- parameter optimisation in machine learning applications in high energy physics.Computer Physics Communications, 294:108955, 2024
2024
-
[58]
Törn and A
A. Törn and A. Žilinskas.Global optimization, volume 350. Springer, 1989
1989
-
[59]
Turner, D
R. Turner, D. Eriksson, M. McCourt, J. Kiili, E. Laaksonen, Z. Xu, and I. Guyon. Bayesian optimization is superior to random search for machine learning hyperparameter tuning: Analysis of the black-box optimization challenge 2020. InNeurIPS Competition and Demonstration Track, 2020
2020
-
[60]
M. J. Van Der Laan and D. Rubin. Targeted maximum likelihood learning.The International Journal of Biostatistics, 2, 2006
2006
-
[61]
Wang and S
Z. Wang and S. Jegelka. Max-value entropy search for efficient Bayesian optimization. In International conference on machine learning, pages 3627–3635. PMLR, 2017
2017
-
[62]
arXiv preprint arXiv:2304.11127 , year=
S. Watanabe. Tree-structured parzen estimator: Understanding its algorithm components and their roles for better empirical performance.arXiv preprint, arXiv:2304.11127, 2023
-
[63]
Wilson, F
J. Wilson, F. Hutter, and M. Deisenroth. Maximizing acquisition functions for Bayesian optimization. InNeural Information Processing Systems (NeurIPS), 2018
2018
- [64]
-
[65]
J. Wu, S. Toscano-Palmerin, P. I. Frazier, and A. G. Wilson. Practical multi-fidelity Bayesian optimization for hyperparameter tuning. InUncertainty in Artificial Intelligence (UAI), 2020
2020
-
[66]
Wu, J.-S
M.-J. Wu, J.-S. R. Jang, and J.-L. Chen. Wafer map failure pattern recognition and similarity ranking for large-scale data sets.IEEE Transactions on Semiconductor Manufacturing, 28(1): 1–12, 2015
2015
-
[67]
Y . Yuan, W. Wang, and W. Pang. A systematic comparison study on hyperparameter optimisation of graph neural networks for molecular property prediction. InProceedings of the genetic and evolutionary computation conference, 2021. 14 A Extended related work Below, we discuss more distant related literature, completing the discussion in Section 2. We first c...
2021
-
[68]
Var bAorth m (z) = 1 S Var(hm)−Cov(h m, gm)⊤ Cov(gm, gm)−1 Cov(gm, hm) ,(28) and therefore Var bAorth m (z) ≤Var bAMC m (z) ,(29) where bAMC m (z) := 1 S PS s=1 hm(θ(s) m ;z)
bAorth m (z)is unbiased forA m(z) 2. Var bAorth m (z) = 1 S Var(hm)−Cov(h m, gm)⊤ Cov(gm, gm)−1 Cov(gm, hm) ,(28) and therefore Var bAorth m (z) ≤Var bAMC m (z) ,(29) where bAMC m (z) := 1 S PS s=1 hm(θ(s) m ;z)
-
[69]
The residual rm(θm;z) :=a m(θm;z)− Cov(gm, gm)−1 Cov(gm, am) ⊤ gm(θm) is or- thogonal to the score directions. Proof. The proof is identical to that of the EI case in Supplement E after replacing EIm(λ;θ m) by the generic acquisition valuea m(z;θ m). Remark.Proposition C.1 shows that the theoretical properties of our orthogonalized approach are acquisitio...
-
[70]
Redistribution and use in any form must be accompanied by the following two citations:
-
[71]
Wafer Map Failure Pattern Recognition and Similarity Ranking for Large-Scale Data Sets,
Ming-Ju Wu, Jyh-Shing Roger Jang, and Jui-Long Chen, "Wafer Map Failure Pattern Recognition and Similarity Ranking for Large-Scale Data Sets," in IEEE Transactions on Semiconductor Manufacturing, vol. 28, no. 1, pp. 1-12, Feb. 2015, doi: 10.1109/TSM.2014.2364237
-
[72]
Weight 3
MIR-WM811K: Dataset for wafer map failure pattern recognition, 2015 http://mirlab.org/dataset/public/ We included these citations at the appropriate places. Further, we received written permission by the authors to use the dataset for our research. F.1 TPE implementation TPE implementation.For the TPE-based experiments, we approximate the parameter distri...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.