Recognition: unknown
Sparkle: Realizing Lively Instruction-Guided Video Background Replacement via Decoupled Guidance
Pith reviewed 2026-05-08 12:29 UTC · model grok-4.3
The pith
A decoupled pipeline for generating foreground and background guidance enables high-quality datasets for instruction-guided video background replacement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
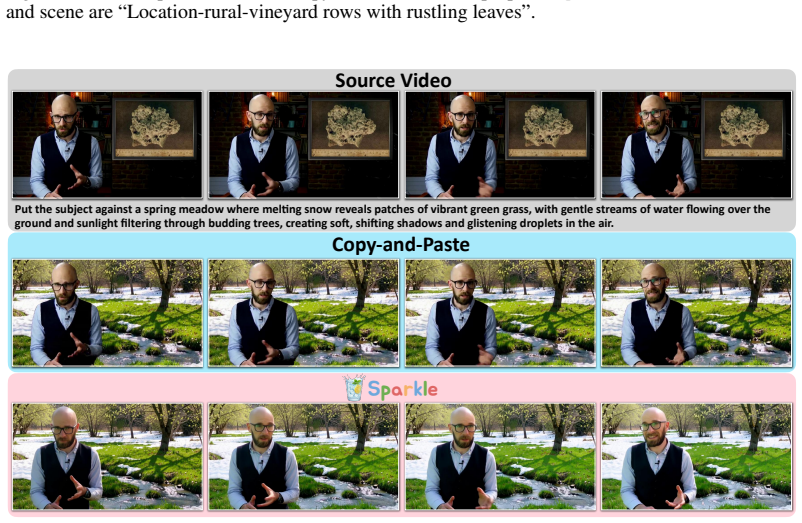
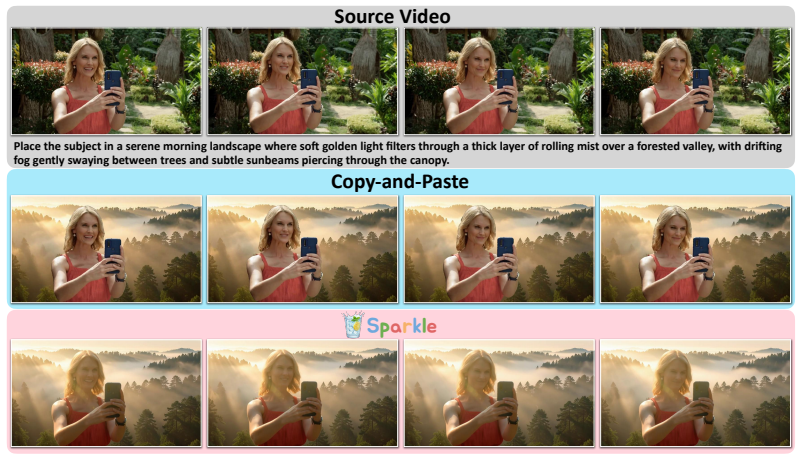
The lack of precise background guidance in data synthesis causes state-of-the-art models to generate static, unnatural backgrounds in replacement tasks. A scalable pipeline that creates foreground and background guidance in a decoupled manner with strict quality filtering addresses this issue. Building on the pipeline yields a dataset of about 140,000 video pairs covering five common background-change themes and a dedicated evaluation benchmark for the task. Models trained using this dataset substantially outperform existing baselines on both prior and new benchmarks.
What carries the argument
Decoupled generation of foreground and background guidance combined with strict quality filtering in the data synthesis pipeline.
Load-bearing premise
That insufficient precise background guidance during data synthesis is the main reason for unnatural outputs in previous models, and that decoupling the guidance will produce better data without new problems.
What would settle it
Observing that models trained on the new dataset continue to generate static backgrounds on test cases with dynamic scene requirements would indicate the approach has not resolved the core issue.
Figures

























read the original abstract
In recent years, open-source efforts like Senorita-2M have propelled video editing toward natural language instruction. However, current publicly available datasets predominantly focus on local editing or style transfer, which largely preserve the original scene structure and are easier to scale. In contrast, Background Replacement, a task central to creative applications such as film production and advertising, requires synthesizing entirely new, temporally consistent scenes while maintaining accurate foreground-background interactions, making large-scale data generation significantly more challenging. Consequently, this complex task remains largely underexplored due to a scarcity of high-quality training data. This gap is evident in poorly performing state-of-the-art models, e.g., Kiwi-Edit, because the primary open-source dataset that contains this task, i.e., OpenVE-3M, frequently produces static, unnatural backgrounds. In this paper, we trace this quality degradation to a lack of precise background guidance during data synthesis. Accordingly, we design a scalable pipeline that generates foreground and background guidance in a decoupled manner with strict quality filtering. Building on this pipeline, we introduce Sparkle, a dataset of ~140K video pairs spanning five common background-change themes, alongside Sparkle-Bench, the largest evaluation benchmark tailored for background replacement to date. Experiments demonstrate that our dataset and the model trained on it achieve substantially better performance than all existing baselines on both OpenVE-Bench and Sparkle-Bench. Our proposed dataset, benchmark, and model are fully open-sourced at https://showlab.github.io/Sparkle/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sparkle, a dataset of ~140K video pairs for instruction-guided video background replacement, generated via a decoupled pipeline that produces foreground and background guidance separately followed by strict quality filtering. It also releases Sparkle-Bench, the largest benchmark for this task, and reports that a model trained on Sparkle substantially outperforms baselines including Kiwi-Edit on both OpenVE-Bench and Sparkle-Bench.
Significance. If the quantitative gains hold, the work meaningfully addresses the data scarcity for complex, temporally consistent background replacement in video editing—an underexplored task relevant to film production and advertising. The open-sourcing of the dataset, benchmark, and model, together with the provision of dataset statistics, qualitative results, and comparative tables, supports reproducibility and further progress in the area.
minor comments (3)
- The abstract asserts substantially better performance without any numerical metrics or error bars; adding one or two key quantitative highlights would better support the central claim for readers who stop at the abstract.
- In the experiments section, the tables comparing against baselines (including retrained Kiwi-Edit) are informative, but the paper should explicitly state the number of evaluation runs, random seeds, and any statistical testing used to establish that the observed gains are reliable.
- The description of the quality-filtering criteria in the data-generation pipeline is central; a short table or paragraph listing the exact thresholds or rejection rates applied at each stage would improve clarity and allow easier replication.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its significance in addressing data scarcity for instruction-guided video background replacement, and the recommendation for minor revision. The report correctly highlights the contributions of the Sparkle dataset, Sparkle-Bench, and the performance improvements over baselines such as Kiwi-Edit.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is an empirical ML contribution focused on dataset construction via a decoupled guidance pipeline, quality filtering, and benchmark evaluation of a trained model. No mathematical derivations, equations, or predictions are present that reduce by construction to fitted parameters, self-definitions, or self-citation chains. Performance claims rest on independent comparisons against baselines on OpenVE-Bench and the new Sparkle-Bench, with no load-bearing steps that import uniqueness theorems or rename known results as novel derivations. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The quality degradation observed in models such as Kiwi-Edit is primarily caused by a lack of precise background guidance during data synthesis in datasets like OpenVE-3M.
Reference graph
Works this paper leans on
-
[1]
Qingyan Bai, Qiuyu Wang, Hao Ouyang, Yue Yu, Hanlin Wang, Wen Wang, Ka Leong Cheng, Shuailei Ma, Yanhong Zeng, Zichen Liu, et al. Scaling instruction-based video editing with a high-quality synthetic dataset.arXiv preprint arXiv:2510.15742, 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
FLUX.2-klein-9B
Black Forest Labs. FLUX.2-klein-9B. https://huggingface.co/black-forest-labs/ FLUX.2-klein-9B, 2026
2026
-
[4]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Learning to generate line drawings that convey geometry and semantics
Caroline Chan, Frédo Durand, and Phillip Isola. Learning to generate line drawings that convey geometry and semantics. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7915–7925, 2022
2022
-
[6]
Lightx2v: Light video generation inference framework
LightX2V Contributors. Lightx2v: Light video generation inference framework. https: //github.com/ModelTC/lightx2v, 2025
2025
-
[7]
Lucy edit: Open-weight text-guided video editing
DecartAI Team. Lucy edit: Open-weight text-guided video editing. 2025. URL https://d2drjpuinn46lb.cloudfront.net/Lucy_Edit__High_Fidelity_Text_ Guided_Video_Editing.pdf
2025
-
[8]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981
1981
-
[9]
Haoyang He, Jie Wang, Jiangning Zhang, Zhucun Xue, Xingyuan Bu, Qiangpeng Yang, Shilei Wen, and Lei Xie. Openve-3m: A large-scale high-quality dataset for instruction-guided video editing.arXiv preprint arXiv:2512.07826, 2025
-
[10]
Vace: All-in- one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in- one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17191–17202, 2025
2025
-
[11]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
arXiv preprint arXiv:2501.10018 (2025) 4, 10, 3
Xiaowen Li, Haolan Xue, Peiran Ren, and Liefeng Bo. Diffueraser: A diffusion model for video inpainting.arXiv preprint arXiv:2501.10018, 2025
-
[13]
Xinyao Liao, Xianfang Zeng, Ziye Song, Zhoujie Fu, Gang Yu, and Guosheng Lin. In- context learning with unpaired clips for instruction-based video editing.arXiv preprint arXiv:2510.14648, 2025
-
[14]
Yiqi Lin, Guoqiang Liang, Ziyun Zeng, Zechen Bai, Yanzhe Chen, and Mike Zheng Shou. Kiwi-edit: Versatile video editing via instruction and reference guidance.arXiv preprint arXiv:2603.02175, 2026
work page internal anchor Pith review arXiv 2026
-
[15]
arXiv preprint arXiv:2509.23909 (2025)
Xin Luo, Jiahao Wang, Chenyuan Wu, Shitao Xiao, Xiyan Jiang, Defu Lian, Jiajun Zhang, Dong Liu, et al. Editscore: Unlocking online rl for image editing via high-fidelity reward modeling.arXiv preprint arXiv:2509.23909, 2025
-
[16]
Instructx: Towards unified visual editing with mllm guidance.arXiv preprint arXiv:2510.08485, 2025
Chong Mou, Qichao Sun, Yanze Wu, Pengze Zhang, Xinghui Li, Fulong Ye, Songtao Zhao, and Qian He. Instructx: Towards unified visual editing with mllm guidance.arXiv preprint arXiv:2510.08485, 2025. 10
-
[17]
ChatGPT Images 2.0 System Card, 2026
OpenAI. ChatGPT Images 2.0 System Card, 2026. URL https://deploymentsafety. openai.com/chatgpt-images-2-0/introduction
2026
-
[18]
Nano Banana 2: Combining Pro Capabilities with Lightning-Fast Speed
Naina Raisinghani. Nano Banana 2: Combining Pro Capabilities with Lightning-Fast Speed. https://blog.google/innovation-and-ai/technology/ai/nano-banana-2, 2026
2026
-
[19]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
Introducing runway aleph
Runway. Introducing runway aleph. https://runwayml.com/research/ introducing-runway-aleph, 2025. Runway Research blog
2025
-
[21]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Cong Wei, Quande Liu, Zixuan Ye, Qiulin Wang, Xintao Wang, Pengfei Wan, Kun Gai, and Wenhu Chen. Univideo: Unified understanding, generation, and editing for videos.arXiv preprint arXiv:2510.08377, 2025
-
[23]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
arXiv preprint arXiv:2509.26346 (2025)
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editre- ward: A human-aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025
-
[25]
Insvie-1m: Effective instruction-based video editing with elaborate dataset construction
Yuhui Wu, Liyi Chen, Ruibin Li, Shihao Wang, Chenxi Xie, and Lei Zhang. Insvie-1m: Effective instruction-based video editing with elaborate dataset construction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16692–16701, 2025
2025
-
[26]
Unifying flow, stereo and depth estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):13941–13958, 2023
Haofei Xu, Jing Zhang, Jianfei Cai, Hamid Rezatofighi, Fisher Yu, Dacheng Tao, and Andreas Geiger. Unifying flow, stereo and depth estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):13941–13958, 2023
2023
-
[27]
Hao Yang, Zhiyu Tan, Jia Gong, Luozheng Qin, Hesen Chen, Xiaomeng Yang, Yuqing Sun, Yuetan Lin, Mengping Yang, and Hao Li. Omni-video 2: Scaling mllm-conditioned diffusion for unified video generation and editing.arXiv preprint arXiv:2602.08820, 2026
-
[28]
Zhongwei Zhang, Fuchen Long, Wei Li, Zhaofan Qiu, Wu Liu, Ting Yao, and Tao Mei. Region- constraint in-context generation for instructional video editing.arXiv preprint arXiv:2512.17650, 2025
-
[29]
Bojia Zi, Penghui Ruan, Marco Chen, Xianbiao Qi, Shaozhe Hao, Shihao Zhao, Youze Huang, Bin Liang, Rong Xiao, and Kam-Fai Wong. Se\˜ norita-2m: A high-quality instruction-based dataset for general video editing by video specialists.arXiv preprint arXiv:2502.06734, 2025. 11 A Coarse Camera Movement Filtering Since processing a large volume of source videos...
-
[30]
No change, or background entirely unrelated to the prompt, or foreground also replaced/distorted such that the edit fails as a whole
-
[31]
Background only partially matches prompt content or style; major requested elements wrong or missing; or foreground noticeably altered
-
[32]
Main background concept matches but with missing/extra elements, wrong sub-style, or partial spill onto the subject
-
[33]
Requested background fully present and consistent with the prompt; only minor mismatches in tone, detail, or atmosphere
-
[34]
Overall Visual Quality.This dimension covers global image quality AND foreground-background harmonization
Background exactly matches the prompt in content, style, mood, and any specified dynamics; fore- ground untouched. Overall Visual Quality.This dimension covers global image quality AND foreground-background harmonization. The lighting, color temperature, and shadows on the foreground must match the new background environment. For example, when the prompt ...
-
[35]
brightly lit subject against a night scene, conflicting light directions, no shadow adaptation)
Severe artefacts throughout (tearing, posterisation, color banding, heavy flicker), OR foreground lighting is grossly inconsistent with the new background (e.g. brightly lit subject against a night scene, conflicting light directions, no shadow adaptation). 12
-
[36]
Clear visual degradation (persistent blur, noise, unstable colors), OR obvious lighting / color- temperature mismatch between foreground and background visible at first glance
-
[37]
Watchable but with visible flaws on closer look: occasional flicker, mild compression artefacts, soft regions, OR partial harmonization where the foreground tone is in the right direction but not fully matched to the background
-
[38]
Clean output with only minor issues when zoomed in or paused; foreground lighting and color grading are well aligned with the background, with only subtle discrepancies
-
[39]
Foreground Integrity
Indistinguishable from real captured footage: sharp, stable, well-graded across the entire clip, with foreground lighting, color temperature, and shadows fully harmonized with the new background environment. Foreground Integrity
-
[40]
Foreground severely damaged: missing limbs/parts, large holes, replaced with a different subject, or shape collapsed
-
[41]
Noticeable foreground damage: partial erosion by background, distorted contours, identity drift across frames
-
[42]
Foreground mostly preserved but with visible defects: edge halos, slight shape deformation, occasional color bleed
-
[43]
Foreground well preserved with only minute edge artefacts; shape and identity stable throughout
-
[44]
Foreground Motion Consistency
Foreground perfectly preserved: every pixel of shape, texture, and identity intact across all frames. Foreground Motion Consistency
-
[45]
Foreground motion completely different from source: actions replaced, frozen, looped, or temporally scrambled
-
[46]
Major motion deviations: different gestures, dropped actions, or strong temporal jitter not present in source
-
[47]
Same general action is recognizable but with timing drift, trajectory shifts, or inconsistent speed versus source
-
[48]
Motion closely tracks the source with only minor temporal misalignment or subtle smoothing
-
[49]
gentle swaying grass
Foreground motion is identical to the source video in trajectory, timing, and articulation, frame by frame. Background Dynamics (Liveness).This dimension measures whether the background motion matches the intensity and character implied by the prompt. The bar is appropriateness to the prompt, not absolute amount of motion. A “gentle swaying grass” prompt ...
-
[50]
crashing waves rendered as a still pond)
Background motion contradicts the prompt: completely static when the prompt implies any motion, or wrong type/direction of motion (e.g. crashing waves rendered as a still pond)
-
[51]
rushing river
Motion intensity is far below what the prompt implies (e.g. a “rushing river” rendered as barely moving water), or required dynamics are largely absent
-
[52]
Motion type is in the right direction but noticeably under- or over-rendered, OR motion exists but feels stiff and unnatural
-
[53]
Motion intensity and character are well matched to the prompt, with only minor stiffness, small frozen patches, or slight over/under rendering
-
[54]
still photo
Background motion perfectly matches the prompt in both intensity and character, rendered naturally and continuously throughout the clip — gentle prompts receive gentle motion, energetic prompts receive energetic motion. Special case:if the prompt explicitly asks for a static background (e.g. “still photo”, “frozen scene”, “no motion”), a faithfully static...
-
[55]
Background severely degraded: melting structures, broken geometry, heavy blur, or incoherent textures
-
[56]
Clear distortion or blur in major background regions; structures wobble or warp over time
-
[57]
Acceptable background with visible imperfections: soft textures, mild geometric inconsistency, minor temporal warping
-
[58]
High-quality background with only minor issues on close inspection; geometry and textures stable. 13
-
[59]
Location-rural-vineyard rows with rustling leaves
Background is sharp, geometrically coherent, and temporally stable; on par with real footage. Constraints.The scores for Overall Visual Quality, Foreground Integrity, Foreground Motion Consis- tency, Background Dynamics, and Background Visual Quality must not exceed the score for Instruction Compliance. Example Response Format. – Brief reasoning: No more ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.