Algospeak, Hiding in the Open: The Trade-off Between Legible Meaning and Detection Avoidance
Pith reviewed 2026-05-08 09:59 UTC · model grok-4.3
The pith
Algospeak creates a trade-off where more evasion lowers both detection risk and human comprehension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
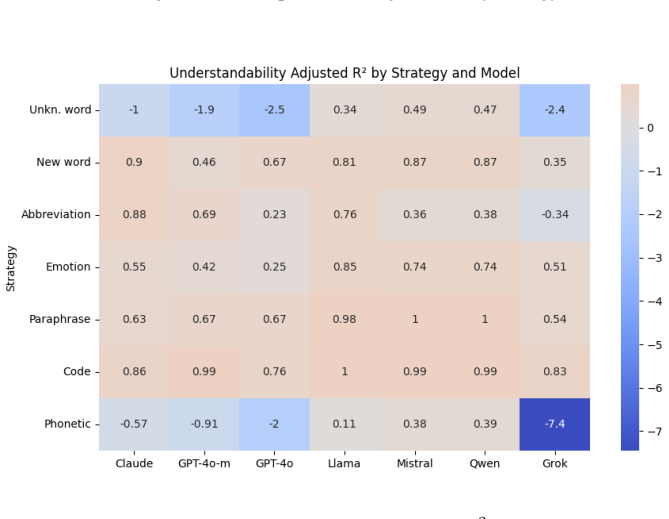
In a joint action model of evasion and detection, increases in Algospeak reduce both detectability and understandability. Majority Understandable Modulation is the modulation level at which additional evasive alteration increases detector evasion but loses comprehension for the majority of recipients. Evaluations on a dataset of modulated COVID-19 disinformation items confirm these relationships through meaning recovery and classification tasks across language models.
What carries the argument
Majority Understandable Modulation (MUM), the modulation threshold that marks the point of maximum detector evasion before majority comprehension collapses.
If this is right
- Evasion strategies will concentrate near the MUM threshold to balance reach and safety.
- Content detectors must incorporate meaning-preservation checks to avoid over-moderating understandable messages.
- The tunable framework enables sensitivity testing of different evasion strategies against various models.
- The same approach can map trade-offs in other disinformation domains beyond COVID-19.
Where Pith is reading between the lines
- Platform rules may evolve toward targeting content near or beyond the MUM point rather than all altered language.
- The trade-off implies that complete detection of evasive content will inevitably reduce the reach of legitimate discourse that uses similar modulations.
- Extending the evaluations to non-English languages or live platform data would test whether MUM estimates hold outside the tested setting.
Load-bearing premise
The modulation framework produces variants that genuinely preserve core meaning at lower levels and that LLM performance on meaning recovery and classification tasks serves as a valid proxy for human comprehension and real-world detector behavior.
What would settle it
A direct comparison showing whether actual human readers retain high understanding at the modulation levels where the LLM models predict majority comprehension loss, or whether deployed detectors exhibit the predicted rise in evasion without corresponding meaning collapse.
Figures







read the original abstract
As large language models (LLMs) increasingly mediate both content generation and moderation, linguistic evasion strategies known as Algospeak have intensified the coevolution between evaders and detectors. This research formalizes the underlying dynamics grounded in a joint action model: when Algospeak increases, detectability and understandability decrease. Further, the concept of Majority Understandable Modulation (MUM) is introduced and defined as the modulation level at which additional evasive alteration increases detector evasion but loses comprehension for the majority of recipients. To empirically probe this trade-off, we introduce a reproducible framework that can be used to create meaning-preserving, Algospeak-style variants, based on an existing taxonomy and with tunable modulation levels. Using COVID-19 disinformation as a first proof-by-example setting, we construct a reference dataset of 700 modulated items, drawn from twenty base sentences across five modulation levels and seven strategies. We then run two linked evaluations with seven different language models: one testing for interpretation through meaning recovery and one for disinformation detection through classification. Curve fitting over modulation levels yields an estimate of the Majority Understandable Modulation threshold and enables sensitivity analyses across strategies and models, see Figure 1. Results reveal the characteristic relationships between understandability and modulation. This study lays the groundwork for understanding the dynamics behind Algospeak and provides the framework, dataset, and experimental setups described.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Algospeak modulation creates a monotonic trade-off in which higher levels of evasive alteration simultaneously decrease detectability and understandability. It introduces the Majority Understandable Modulation (MUM) threshold, defined as the modulation level at which further evasion improves detector avoidance but causes the majority of recipients to lose core meaning. The claim is investigated via a reproducible generation framework applied to COVID-19 disinformation: a 700-item dataset is built from 20 base sentences using five modulation levels and seven strategies; two LLM-based evaluations (meaning recovery and disinformation classification) are run across seven models; and curve fitting on the resulting performance curves is used to estimate MUM values and conduct sensitivity analyses.
Significance. If the central trade-off and MUM estimates hold under stronger validation, the work supplies a reusable dataset, generation framework, and experimental protocol that could support systematic study of linguistic evasion in LLM-mediated moderation. The multi-model, multi-strategy design permits sensitivity checks, and the explicit reproducibility emphasis is a clear strength. The practical significance remains limited, however, by the exclusive reliance on LLM proxies whose fidelity to human readers and deployed detectors is untested.
major comments (2)
- [Abstract and Experimental Setup] Abstract and Experimental Setup: The MUM definition and the claimed trade-off are defined in terms of 'majority of recipients' losing comprehension and real detector evasion, yet both quantities are measured exclusively via LLM meaning-recovery and classification accuracy. No human-subject validation, inter-annotator agreement with humans, or comparison against non-LLM moderation systems is reported; this proxy assumption is load-bearing for the central empirical claims.
- [Results and Curve Fitting] Results and Curve Fitting: The abstract states that curve fitting over modulation levels yields MUM estimates, but the manuscript provides no error bars, confidence intervals, goodness-of-fit statistics, or tests for robustness to functional form. Without these, it is impossible to assess whether the reported inflection points are statistically distinguishable from noise or sensitive to modeling choices.
minor comments (2)
- The generation framework would be easier to replicate if the main text included one or two concrete examples of base sentences transformed at each modulation level.
- [Abstract] The abstract's reference to 'Figure 1' and sensitivity analyses would benefit from a brief textual summary of the key patterns observed across the seven models and seven strategies.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the proxy measures and statistical reporting in our work. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Experimental Setup] The MUM definition and the claimed trade-off are defined in terms of 'majority of recipients' losing comprehension and real detector evasion, yet both quantities are measured exclusively via LLM meaning-recovery and classification accuracy. No human-subject validation, inter-annotator agreement with humans, or comparison against non-LLM moderation systems is reported; this proxy assumption is load-bearing for the central empirical claims.
Authors: We acknowledge that the MUM threshold and trade-off claims rest on LLM proxies for both meaning recovery and disinformation classification. The study is explicitly framed as a reproducible, LLM-centric proof-of-concept in the setting of LLM-mediated moderation, where such models serve as both generators and potential detectors. We agree that direct human validation would strengthen ecological validity. In the revised manuscript we will add an explicit limitations subsection that discusses the proxy assumption, notes the absence of human inter-annotator agreement or comparisons to non-LLM systems, and outlines future work needed to confirm MUM estimates with human recipients. revision: yes
-
Referee: [Results and Curve Fitting] The abstract states that curve fitting over modulation levels yields MUM estimates, but the manuscript provides no error bars, confidence intervals, goodness-of-fit statistics, or tests for robustness to functional form. Without these, it is impossible to assess whether the reported inflection points are statistically distinguishable from noise or sensitive to modeling choices.
Authors: We agree that the curve-fitting results require additional statistical detail for proper evaluation. The current version does not report error bars, confidence intervals, or goodness-of-fit metrics. In the revision we will update the results section and Figure 1 to include (i) error bars showing standard error across the seven models, (ii) 95% confidence intervals on the estimated MUM parameters, (iii) R² and residual diagnostics for the fitted curves, and (iv) a brief sensitivity check across alternative functional forms (linear, logistic, and piecewise) to demonstrate robustness of the inflection points. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces a joint action model and defines MUM conceptually as the modulation level where further evasion trades off against majority comprehension. It then generates a 700-item dataset via a tunable framework, measures understandability and detectability through LLM tasks, and estimates the MUM threshold by curve fitting. These steps constitute an empirical observation of the trade-off rather than any reduction of the claimed relationships to fitted parameters or self-referential definitions by construction. No equations, self-citations, or imported uniqueness results are shown to make the central results tautological with the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- modulation levels
axioms (2)
- domain assumption Algospeak strategies drawn from an existing taxonomy can be applied at graduated levels while preserving core meaning
- domain assumption LLM performance on meaning recovery and disinformation classification tasks reflects human comprehension and detector behavior
invented entities (1)
-
Majority Understandable Modulation (MUM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Next-generation phishing: How llm agents empower cyber attackers
Khalifa Afane, Wenqi Wei, Ying Mao, Junaid Farooq, and Juntao Chen. Next-generation phishing: How llm agents empower cyber attackers. In2024 IEEE International Conference on Big Data (BigData), pages 2558–2567, 2024. 11 Figure 7: Heatmap detection adjustedR 2 by strategy and model. Figure 8: Heatmap understanding adjustedR 2 by strategy and model
work page 2024
-
[2]
Sarah Kreps, R Miles McCain, and Miles Brundage. All the news that’s fit to fabricate: Ai- generated text as a tool of media misinformation.Journal of experimental political science, 9(1):104–117, 2022
work page 2022
-
[3]
Automating power: Social bot interference in global politics.First Monday, 2016
Samuel C Woolley. Automating power: Social bot interference in global politics.First Monday, 2016
work page 2016
-
[4]
Franziska B Keller, David Schoch, Sebastian Stier, and JungHwan Yang. Political astroturfing on twitter: How to coordinate a disinformation campaign.Political communication, 37(2):256–280, 2020. 12 Table 5: Estimated thresholdx 0 (IMUM@0.5, detection) by strategy and model Strategy Claude GPT-4o mini GPT-4o Llama Mistral Qwen xAI Unknown word 5.09988 5.10...
work page 2020
- [5]
-
[6]
Sophie Curtis. How tiktok is changing the way we speak: Phrases like “barbiecore”, “quiet quitting” and “le dollar bean” that originated on the social media app have crossed over into the mainstream - so how many do you know?, Sep 2022
work page 2022
-
[7]
Leg booty? panoramic? seggs? how tiktok is changing language, Nov 2022
Melina Delkic. Leg booty? panoramic? seggs? how tiktok is changing language, Nov 2022
work page 2022
-
[8]
Tiktok: Wie gartenzwerge die grenzen des sagbaren ver- schieben, Nov 2023
Una Titz and Theresa Lehmann. Tiktok: Wie gartenzwerge die grenzen des sagbaren ver- schieben, Nov 2023
work page 2023
-
[9]
Ella Steen, Kathryn Yurechko, and Daniel Klug. You can (not) say what you want: Using algospeak to contest and evade algorithmic content moderation on tiktok.Social Media + Society, 9(3):20563051231194586, 2023
work page 2023
-
[10]
How algorithm awareness impacts algospeak use on tiktok
Daniel Klug, Ella Steen, and Kathryn Yurechko. How algorithm awareness impacts algospeak use on tiktok. InCompanion Proceedings of the ACM Web Conference 2023, WWW ’23 Companion, page 234–237, New York, NY , USA, 2023. Association for Computing Machinery
work page 2023
-
[11]
Simple llm based approach to counter algospeak
Jan Fillies and Adrian Paschke. Simple llm based approach to counter algospeak. InProceedings of the 8th Workshop on Online Abuse and Harms (WOAH 2024), pages 136–145, 2024
work page 2024
-
[12]
Kalika Bali, Jatin Sharma, Monojit Choudhury, and Yogarshi Vyas. “I am borrowing ya mixing ?” an analysis of English-Hindi code mixing in Facebook. In Mona Diab, Julia Hirschberg, Pascale Fung, and Thamar Solorio, editors,Proceedings of the First Workshop on Computational Approaches to Code Switching, pages 116–126, Doha, Qatar, October 2014. Association ...
work page 2014
-
[13]
Code mixing: A challenge for language identification in the language of social media
Utsab Barman, Amitava Das, Joachim Wagner, and Jennifer Foster. Code mixing: A challenge for language identification in the language of social media. In Mona T. Diab, Julia Hirschberg, Pascale Fung, and Thamar Solorio, editors,Proceedings of the First Workshop on Computational Approaches to Code Switching@EMNLP 2014, Doha, Qatar , October 25, 2014, pages ...
work page 2014
-
[14]
Detecting offensive tweets in Hindi-English code-switched language
Puneet Mathur, Rajiv Shah, Ramit Sawhney, and Debanjan Mahata. Detecting offensive tweets in Hindi-English code-switched language. In Lun-Wei Ku and Cheng-Te Li, editors,Proceedings of the Sixth International Workshop on Natural Language Processing for Social Media, pages 18–26, Melbourne, Australia, July 2018. Association for Computational Linguistics. 13
work page 2018
-
[15]
A dataset of Hindi-English code-mixed social media text for hate speech detection
Aditya Bohra, Deepanshu Vijay, Vinay Singh, Syed Sarfaraz Akhtar, and Manish Shrivastava. A dataset of Hindi-English code-mixed social media text for hate speech detection. In Malvina Nissim, Viviana Patti, Barbara Plank, and Claudia Wagner, editors,Proceedings of the Second Workshop on Computational Modeling of People’s Opinions, Personality, and Emotion...
work page 2018
-
[16]
Mixed-code text analysis for the detection of online hidden propaganda
Andrea Tundis, Gaurav Mukherjee, and Max Mühlhäuser. Mixed-code text analysis for the detection of online hidden propaganda. InProceedings of the 15th International Conference on Availability, Reliability and Security, ARES ’20, New York, NY , USA, 2020. Association for Computing Machinery
work page 2020
-
[17]
Deobfuscating leetspeak with deep learning to improve spam filtering
Iñaki Vélez de Mendizabal, Xabier Vidriales Mazorriaga, Iñigo Ezpeleta, and Urko Zurutuza. Deobfuscating leetspeak with deep learning to improve spam filtering. 2023
work page 2023
-
[18]
Bae: Bert-based adversarial examples for text classification
Siddhant Garg and Goutham Ramakrishnan. Bae: Bert-based adversarial examples for text classification. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6174–6181, 2020
work page 2020
-
[19]
Humanizing machine-generated content: evading ai-text detection through adversarial attack
Ying Zhou, Ben He, and Le Sun. Humanizing machine-generated content: evading ai-text detection through adversarial attack. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 8427–8437, 2024
work page 2024
-
[20]
Brennan (1991) grounding in communication
Herbert H Clark. Brennan (1991) grounding in communication. 1991
work page 1991
-
[21]
Cambridge university press, 1996
Herbert H Clark.Using language. Cambridge university press, 1996
work page 1996
-
[22]
Referring as a collaborative process.Cognition, 22(1):1–39, 1986
Herbert H Clark and Deanna Wilkes-Gibbs. Referring as a collaborative process.Cognition, 22(1):1–39, 1986
work page 1986
-
[23]
How readability shapes social media engagement.Journal of consumer psychology, 29(2):262–270, 2019
Ethan Pancer, Vincent Chandler, Maxwell Poole, and Theodore J Noseworthy. How readability shapes social media engagement.Journal of consumer psychology, 29(2):262–270, 2019
work page 2019
-
[24]
Felix A Wichmann and N Jeremy Hill. The psychometric function: I. fitting, sampling, and goodness of fit.Perception & psychophysics, 63(8):1293–1313, 2001. 14 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: The abstract ...
work page 2001
-
[25]
All experiments used LLMs only
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.