Recognition: no theorem link
Visual Text Compression as Measure Transport
Pith reviewed 2026-05-11 01:14 UTC · model grok-4.3
The pith
Visual text compression loses information in ways that can be measured as transport costs between token measures without needing task labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Treating text and visual tokens as empirical probability measures, the ViT patch encoder induces a push-forward map whose transport cost decomposes into a precision cost from within-patch aggregation and a coverage cost from cross-patch fragmentation. Both terms are estimable from downstream-label-free probes. This yields a label-free routing criterion that selects the visual path when costs indicate low loss and a foveation mechanism that re-encodes high-cost regions at higher resolution.
What carries the argument
The push-forward map induced by the ViT patch encoder on empirical text and visual token measures, whose cost decomposes into precision and coverage components that quantify information loss.
If this is right
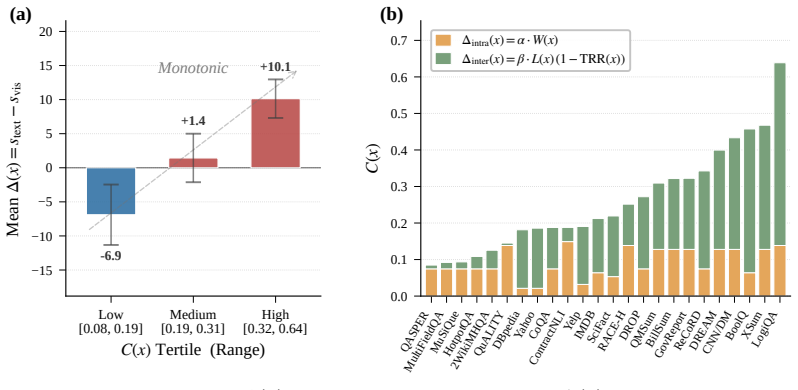
- Label-free routing selects the visual path and matches the per-dataset oracle on 17 out of 24 NLP datasets.
- Using the criterion improves average task score by 3.3 percent while reducing tokens by 10.3 percent compared to always using the text path.
- The transport costs can guide a foveation mechanism to re-encode high-cost regions at higher resolution.
- Downstream utility can be predicted from the decomposed costs without access to task labels or fine-tuning.
Where Pith is reading between the lines
- If the cost estimates correlate with performance, similar transport decompositions might apply to other compression methods such as quantization or pruning in language models.
- The approach opens the possibility of optimizing the vision encoder itself to minimize the precision and coverage costs for text inputs.
- Extending the probes to streaming or very long contexts could allow dynamic switching during generation.
Load-bearing premise
The decomposed transport costs from label-free probes are sufficiently predictive of downstream task utility to guide reliable routing across different NLP datasets and models.
What would settle it
The claim would be falsified if, on new benchmarks, the label-free routing rule selects the inferior path on more than half the datasets or if the estimated costs show no correlation with actual performance differences between visual and text paths.
Figures











read the original abstract
Visual text compression (VTC) promises efficient long-context processing by rendering text into an image and re-encoding it with a vision-language model, often producing $3$--$20\times$ fewer decoder tokens than subword tokenization. Yet token savings do not translate predictably into downstream utility: on some tasks the visual path matches or exceeds the text path, on others it collapses, and the compression ratio itself does not predict which regime will occur. The missing quantity is therefore not another summary of efficiency, but a principled measure of task-relevant information loss induced by visual encoding. We address this problem by formulating VTC in the language of measure transport. Treating text and visual tokens as empirical probability measures, we show that the ViT patch encoder induces a push-forward map whose transport cost decomposes into a precision cost from within-patch aggregation and a coverage cost from cross-patch fragmentation. Both terms are estimable from downstream-label-free probes. This formulation yields two operational consequences: a downstream-label-free routing criterion that selects whether to use the visual path for a given input or benchmark instance, and a transport-informed foveation mechanism that re-encodes high-cost regions at higher resolution. Across $24$ NLP datasets at Qwen3-4B, our label-free rule matches the per-dataset oracle on $17/24$ datasets ($70.8\%$), and improves the average task score by $+3.3\%$ with $-10.3\%$ average tokens relative to a pure-LLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames visual text compression (VTC) as an optimal transport problem between empirical measures induced by text tokens and ViT-encoded visual patches. It claims that the ViT patch encoder defines a push-forward map whose transport cost decomposes into a precision term (arising from within-patch aggregation) and a coverage term (arising from cross-patch fragmentation), both of which can be estimated from downstream-label-free probes. These estimates are then used to derive a routing rule that decides per-instance or per-dataset whether to route through the visual path and a foveation mechanism that re-encodes high-cost regions at higher resolution. On 24 NLP datasets with Qwen3-4B, the resulting label-free router matches the per-dataset oracle on 17/24 cases (70.8 %) and delivers +3.3 % average task score at –10.3 % average token count relative to a pure-LLM baseline.
Significance. If the decomposition is rigorously derived and the probe estimates are shown to track per-instance task utility, the work supplies a principled, label-free criterion for deciding when visual encoding preserves (or loses) task-relevant information. This would be a concrete advance for long-context VLM efficiency, moving beyond heuristic compression ratios. The reported oracle-match rate and token savings are operationally attractive, but their attribution to the transport analysis remains to be demonstrated.
major comments (3)
- [§3 (transport formulation)] The abstract and introduction assert that the transport cost decomposes into precision and coverage terms that are estimable from label-free probes, yet the manuscript provides neither the explicit ground metric (e.g., the cost function inside the Wasserstein or MMD distance) nor the algebraic steps showing how the push-forward map yields the two additive terms. Without these definitions it is impossible to verify that the probe statistics actually recover the claimed decomposition or that they are independent of downstream labels.
- [§5 (routing experiments)] The central operational claim is that the probe-derived costs predict when the visual path preserves task utility. However, no correlation (Pearson, Spearman, or rank) is reported between the estimated precision/coverage costs and the observed per-instance performance delta between visual and text paths on the same held-out examples. The 70.8 % oracle match on 24 datasets therefore does not yet establish that the routing rule succeeds because of the measure-transport decomposition rather than for orthogonal reasons.
- [§4.2 (foveation)] The foveation mechanism is presented as a direct consequence of the transport cost, yet the paper does not specify how the per-region cost is computed from the same probes or how the higher-resolution re-encoding is integrated into the ViT forward pass. This leaves the claimed “transport-informed” property of foveation unverified.
minor comments (3)
- [§3] The notation for empirical measures, push-forward maps, and the two cost functionals should be introduced with numbered equations rather than prose descriptions only.
- [§5] Table 1 (or equivalent) would benefit from an additional column or supplementary figure that reports the estimated precision and coverage values alongside the visual/text scores for each dataset.
- [§4.1] The manuscript should clarify whether the probes operate on the same ViT features used by the downstream VLM or on a separate probe network; the current description leaves this ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving the mathematical clarity and empirical grounding of the measure-transport formulation. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3 (transport formulation)] The abstract and introduction assert that the transport cost decomposes into precision and coverage terms that are estimable from label-free probes, yet the manuscript provides neither the explicit ground metric (e.g., the cost function inside the Wasserstein or MMD distance) nor the algebraic steps showing how the push-forward map yields the two additive terms. Without these definitions it is impossible to verify that the probe statistics actually recover the claimed decomposition or that they are independent of downstream labels.
Authors: We thank the referee for this observation. Section 3 defines the ground metric as the squared Euclidean distance in the shared ViT embedding space between text tokens and visual patches. The decomposition of the Wasserstein-2 transport cost under the push-forward map induced by patch aggregation is derived by separating the expectation into intra-patch variance (precision) and inter-patch dispersion (coverage). The probe statistics are constructed to be label-free by design. We will add an explicit lemma with the full algebraic expansion and proof in a revised §3.2 to make the steps self-contained and verifiable. revision: yes
-
Referee: [§5 (routing experiments)] The central operational claim is that the probe-derived costs predict when the visual path preserves task utility. However, no correlation (Pearson, Spearman, or rank) is reported between the estimated precision/coverage costs and the observed per-instance performance delta between visual and text paths on the same held-out examples. The 70.8 % oracle match on 24 datasets therefore does not yet establish that the routing rule succeeds because of the measure-transport decomposition rather than for orthogonal reasons.
Authors: The referee correctly identifies the need for direct evidence of attribution. While the 70.8% oracle match and token savings demonstrate operational value, we agree that reporting correlations would better link the routing decisions to the decomposed costs. In the revision we will add a new analysis in §5 computing Pearson and Spearman correlations between the per-instance precision/coverage estimates and the observed performance deltas on held-out examples across the 24 datasets. revision: yes
-
Referee: [§4.2 (foveation)] The foveation mechanism is presented as a direct consequence of the transport cost, yet the paper does not specify how the per-region cost is computed from the same probes or how the higher-resolution re-encoding is integrated into the ViT forward pass. This leaves the claimed “transport-informed” property of foveation unverified.
Authors: We agree that the implementation details require expansion. The per-region cost localizes the coverage term by computing patch-neighborhood statistics (activation entropy and reconstruction error) from the same label-free probes. High-cost regions trigger an additional ViT forward pass at doubled resolution, with the resulting embeddings concatenated into the primary sequence before the LLM decoder. We will revise §4.2 to include the exact per-region formula, pseudocode for the process, and a figure illustrating the integration into the ViT pipeline. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper frames visual text compression via measure transport, defining text and visual tokens as empirical probability measures and deriving a decomposition of the ViT-induced push-forward map's transport cost into precision (within-patch) and coverage (cross-patch) terms. This step follows directly from the mathematical definition of push-forward maps and optimal transport costs without reducing to fitted parameters, self-citations, or ansatzes smuggled from prior work. The label-free probes are introduced as estimators of these decomposed costs, and the routing criterion is constructed from them without reference to task labels or downstream performance. Evaluation on 24 held-out NLP datasets tests the criterion's practical utility but does not enter the derivation chain itself; success on 17/24 datasets is an external check rather than a definitional equivalence. No load-bearing self-citation, uniqueness theorem, or renaming of known results appears in the provided chain. The result is therefore not equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Text and visual tokens can be treated as empirical probability measures on a common space.
- domain assumption The ViT patch encoder defines a measurable push-forward map between these measures.
Reference graph
Works this paper leans on
-
[1]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
work page 2025
-
[2]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding. InACL (1), pages 3119–3137. Association for Computational Linguistics, 2024
work page 2024
-
[3]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Jeffrey Hsu, Mimansa Jaiswal, Wilson Y . Lee, Haonan Li, Charles Lovering, Niklas Muennighoff, Ellie Pavlick...
-
[4]
PLOT: prompt learning with optimal transport for vision-language models
Guangyi Chen, Weiran Yao, Xiangchen Song, Xinyue Li, Yongming Rao, and Kun Zhang. PLOT: prompt learning with optimal transport for vision-language models. InICLR. OpenReview.net, 2023
work page 2023
-
[5]
Information bottleneck revisited: Posterior probability perspective with optimal transport
Lingyi Chen, Shitong Wu, Wenhao Ye, Huihui Wu, Hao Wu, Wenyi Zhang, Bo Bai, and Yining Sun. Information bottleneck revisited: Posterior probability perspective with optimal transport. In2023 IEEE International Symposium on Information Theory (ISIT), pages 1490–1495. IEEE, 2023
work page 2023
-
[6]
Graph optimal transport for cross-domain alignment
Liqun Chen, Zhe Gan, Yu Cheng, Linjie Li, Lawrence Carin, and Jingjing Liu. Graph optimal transport for cross-domain alignment. InICML, Proceedings of Machine Learning Research, pages 1542–1553. PMLR, 2020
work page 2020
-
[7]
Xiaoshu Chen, Sihang Zhou, Ke Liang, Taichun Zhou, and Xinwang Liu. Imgcot: Compressing long chain of thought into compact visual tokens for efficient reasoning of large language model.CoRR, abs/2601.22730, 2026
-
[8]
OTPrune: Distribution-aligned visual token pruning via optimal transport
Xiwen Chen, Wenhui Zhu, Gen Li, Xuanzhao Dong, Yujian Xiong, Hao Wang, Peijie Qiu, Qingquan Song, Zhipeng Wang, Shao Tang, et al. Otprune: Distribution-aligned visual token pruning via optimal transport. arXiv preprint arXiv:2602.20205, 2026
-
[9]
arXiv preprint arXiv:2510.17800 (2025) 11
Jiale Cheng, Yusen Liu, Xinyu Zhang, Yulin Fei, Wenyi Hong, Ruiliang Lyu, Weihan Wang, Zhe Su, Xiaotao Gu, Xiao Liu, Yushi Bai, Jie Tang, Hongning Wang, and Minlie Huang. Glyph: Scaling context windows via visual-text compression.CoRR, abs/2510.17800, 2025
-
[10]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InNAACL-HLT (1), pages 2924–2936. Association for Computational Linguistics, 2019
work page 2019
-
[11]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. InNAACL-HLT, pages 4599–4610. Association for Computational Linguistics, 2021
work page 2021
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR. OpenReview.net, 2021
work page 2021
-
[13]
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InNAACL-HLT (1), pages 2368–2378. Association for Computational Linguistics, 2019
work page 2019
-
[14]
Lang Feng, Fuchao Yang, Feng Chen, Xin Cheng, Haiyang Xu, Zhenglin Wan, Ming Yan, and Bo An. Agentocr: Reimagining agent history via optical self-compression.CoRR, abs/2601.04786, 2026
-
[15]
Teaching machines to read and comprehend
Karl Moritz Hermann, Tomás Kociský, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. InNeurIPS, pages 1693–1701, 2015
work page 2015
-
[16]
Constructing A multi-hop QA dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing A multi-hop QA dataset for comprehensive evaluation of reasoning steps. InCOLING, pages 6609–6625. International Committee on Computational Linguistics, 2020. 10
work page 2020
-
[17]
Efficient attentions for long document summarization
Luyang Huang, Shuyang Cao, Nikolaus Nova Parulian, Heng Ji, and Lu Wang. Efficient attentions for long document summarization. InNAACL-HLT, pages 1419–1436. Association for Computational Linguistics, 2021
work page 2021
-
[18]
Global context compression with interleaved vision-text transformation.CoRR, abs/2601.10378, 2026
Dian Jiao, Jiaxin Duan, Shuai Zhao, Jiabing Leng, Yiran Zhang, and Feng Huang. Global context compression with interleaved vision-text transformation.CoRR, abs/2601.10378, 2026
-
[19]
Yuta Koreeda and Christopher D. Manning. Contractnli: A dataset for document-level natural language inference for contracts. InEMNLP (Findings), Findings of ACL, pages 1907–1919. Association for Computational Linguistics, 2021
work page 1907
-
[20]
Billsum: A corpus for automatic summarization of US legislation
Anastassia Kornilova and Vlad Eidelman. Billsum: A corpus for automatic summarization of US legislation. CoRR, abs/1910.00523, 2019
-
[21]
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard H. Hovy. RACE: large-scale reading comprehension dataset from examinations. InEMNLP, pages 785–794. Association for Computational Linguistics, 2017
work page 2017
-
[22]
Optical Context Compression Is Just (Bad) Autoencoding
Ivan Yee Lee, Cheng Yang, and Taylor Berg-Kirkpatrick. Optical context compression is just (bad) autoencoding.CoRR, abs/2512.03643, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Yanhong Li, Zixuan Lan, and Jiawei Zhou. Text or pixels? it takes half: On the token efficiency of visual text inputs in multimodal llms.CoRR, abs/2510.18279, 2025
-
[24]
Visual merit or linguistic crutch? A close look at deepseek-ocr.CoRR, abs/2601.03714, 2026
Yunhao Liang, Ruixuan Ying, Bo Li, Hong Li, Kai Yan, Qingwen Li, Min Yang, Okamoto Satoshi, Zhe Cui, and Shiwen Ni. Visual merit or linguistic crutch? A close look at deepseek-ocr.CoRR, abs/2601.03714, 2026
-
[25]
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning
Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: A challenge dataset for machine reading comprehension with logical reasoning. InIJCAI, pages 3622–3628. ijcai.org, 2020
work page 2020
-
[26]
arXiv preprint arXiv:2401.15969 , year=
Tianlin Liu, Mathieu Blondel, Carlos Riquelme, and Joan Puigcerver. Routers in vision mixture of experts: An empirical study.arXiv preprint arXiv:2401.15969, 2024
-
[27]
Cross-modal alignment with optimal transport for ctc-based ASR
Xugang Lu, Peng Shen, Yu Tsao, and Hisashi Kawai. Cross-modal alignment with optimal transport for ctc-based ASR. InASRU, pages 1–7. IEEE, 2023
work page 2023
-
[28]
Eckstein, and William Yang Wang
Yujie Lu, Xiujun Li, Tsu-Jui Fu, Miguel P. Eckstein, and William Yang Wang. From text to pixel: Advancing long-context understanding in mllms.CoRR, abs/2405.14213, 2024
-
[29]
Pixelworld: How far are we from perceiving everything as pixels?CoRR, abs/2501.19339, 2025
Zhiheng Lyu, Xueguang Ma, and Wenhu Chen. Pixelworld: How far are we from perceiving everything as pixels?CoRR, abs/2501.19339, 2025
-
[30]
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y . Ng, and Christopher Potts. Learning word vectors for sentiment analysis. InACL, pages 142–150. The Association for Computer Linguistics, 2011
work page 2011
-
[31]
Joint wasserstein autoencoders for aligning multimodal embeddings
Shweta Mahajan, Teresa Botschen, Iryna Gurevych, and Stefan Roth. Joint wasserstein autoencoders for aligning multimodal embeddings. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 0–0, 2019
work page 2019
-
[32]
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. InEMNLP, pages 1797–1807. Association for Computational Linguistics, 2018
work page 2018
-
[33]
Duc Anh Nguyen, Huu Binh Ta, Nhuan Le Duc, Tan M Nguyen, and Toan Tran. Selective sinkhorn routing for improved sparse mixture of experts.arXiv preprint arXiv:2511.08972, 2025
-
[34]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, and Samuel R. Bowman. Quality: Question answering with long input texts, yes! InNAACL-HLT, pages 5336–5358. Association for Computational Linguistics, 2022
work page 2022
-
[35]
Computational optimal transport.Found
Gabriel Peyré and Marco Cuturi. Computational optimal transport.Found. Trends Mach. Learn., 11(5-6): 355–607, 2019
work page 2019
-
[36]
Siva Reddy, Danqi Chen, and Christopher D. Manning. Coqa: A conversational question answering challenge.Trans. Assoc. Comput. Linguistics, 7:249–266, 2019. 11
work page 2019
-
[37]
Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389, 2009
work page 2009
-
[38]
Sidak Pal Singh and Martin Jaggi. Model fusion via optimal transport.Advances in Neural Information Processing Systems, 33:22045–22055, 2020
work page 2020
-
[39]
Kai Sun, Dian Yu, Jianshu Chen, Dong Yu, Yejin Choi, and Claire Cardie. Dream: A challenge data set and models for dialogue-based reading comprehension.Transactions of the Association for Computational Linguistics, 7:217–231, 2019
work page 2019
-
[40]
Qwen Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Musique: Multihop questions via single-hop question composition.Trans
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Trans. Assoc. Comput. Linguistics, 10:539–554, 2022
work page 2022
- [42]
-
[43]
Fact or fiction: Verifying scientific claims
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims. InEMNLP (1), pages 7534–7550. Association for Computational Linguistics, 2020
work page 2020
-
[44]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, JingJing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Hou,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
Yifan Wang, Shiyu Li, Peiming Li, Xiaochen Yang, Yang Tang, and Zheng Wei. Render-of-thought: Rendering textual chain-of-thought as images for visual latent reasoning.CoRR, abs/2601.14750, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression.CoRR, abs/2510.18234, 2025
work page internal anchor Pith review arXiv 2025
-
[47]
See the text: From tokenization to visual reading.CoRR, abs/2510.18840, 2025
Ling Xing, Alex Jinpeng Wang, Rui Yan, Hongyu Qu, Zechao Li, and Jinhui Tang. See the text: From tokenization to visual reading.CoRR, abs/2510.18840, 2025
-
[48]
Vision-centric token compression in large language model.arXiv preprint arXiv:2502.00791,
Ling Xing, Alex Jinpeng Wang, Rui Yan, and Jinhui Tang. Vision-centric token compression in large language model.CoRR, abs/2502.00791, 2025
-
[49]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In EMNLP, pages 2369–2380. Association for Computational Linguistics, 2018
work page 2018
-
[50]
ReCoRD: Bridging the Gap between Human and Machine Commonsense Reading Comprehension
Sheng Zhang, Xiaodong Liu, Jingjing Liu, Jianfeng Gao, Kevin Duh, and Benjamin Van Durme. Record: Bridging the gap between human and machine commonsense reading comprehension.CoRR, abs/1810.12885, 2018
work page Pith review arXiv 2018
-
[51]
Character-level convolutional networks for text classification
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun. Character-level convolutional networks for text classification. InNeurIPS, pages 649–657, 2015
work page 2015
-
[52]
Hongbo Zhao, Meng Wang, Fei Zhu, Wenzhuo Liu, Bolin Ni, Fanhu Zeng, Gaofeng Meng, and Zhaoxiang Zhang. Vtcbench: Can vision-language models understand long context with vision-text compression? CoRR, abs/2512.15649, 2025
-
[53]
Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, and Dragomir R. Radev. Qmsum: A new benchmark for query-based multi-domain meeting summarization. InNAACL-HLT, pages 5905–5921. Association for Computational Linguistics, 2021
work page 2021
-
[54]
Xingyu Zhu, Beier Zhu, Shuo Wang, Kesen Zhao, and Hanwang Zhang. Enhancing clip robustness via cross-modality alignment.arXiv preprint arXiv:2510.24038, 2025. 12 A Overview of Supplementary Experiments and Analyses The purpose of this section:This section provides a roadmap for the appendix. The main paper presents the transport-cost framework, the label-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.